[EXP] Active Exploitation of MDM and Enterprise Management Control Planes

Report Type:
EXP
Threat Category:
Active Exploitation of Enterprise Management Control-Plane Infrastructure
Assessment Date:
May 7, 2026
Amendment Date: June 11, 2026
Primary Impact Domain:
Enterprise Management Control-Plane Integrity
Secondary Impact Domains:
Administrative Access Control; Device Trust and Assurance; Policy Enforcement; Certificate, Token, and Connector Integrity; Logging and Visibility; Operational Continuity; Regulatory and Governance Exposure
Affected Asset Class:
MDM, EPMM, Endpoint-Management, Security-Management, and Enterprise Administration Platforms
Threat Objective Classification:
Unauthorized Administrative Access, Privileged Object Manipulation, Configuration or Policy Control Abuse, Visibility Reduction, Conditional Downstream Discovery, and Potential Enterprise Impact
Published by: CyberDax LLC
Author: Edward “Tony” Dolley
Role: Founder / Principal Threat Researcher, CyberDax LLC
Publication Date: June 11
Publication Type: Cybersecurity Research Report / White Paper
BLUF
[EXP] Active Exploitation of MDM and Enterprise Management Control Planes creates material enterprise risk by turning trusted device-management infrastructure into a potential path for administrative control-plane compromise. The risk is driven by active exploitation of Ivanti EPMM and comparable MDM, endpoint-management, security-management, and enterprise administration platforms that hold privileged authority over users, devices, policies, certificates, connectors, credentials, enrollment workflows, and downstream integrations. The threat posture is elevated because successful compromise of a management platform can affect more than the vulnerable server itself; it can create uncertainty around device trust, administrative integrity, policy enforcement, certificate distribution, integration security, and enterprise-wide control-plane reliability. Executive action is required to validate exposure, confirm remediation, preserve management-platform telemetry, review historical administrative activity, assess privileged object changes, validate connector and credential integrity, and confirm that response teams can identify suspicious administrative access, management-server misuse, abnormal outbound communication, privileged control-plane modification, and downstream device-management impact.
Executive Risk Translation
This threat shifts business risk from isolated vulnerability exposure to loss of confidence in a trusted enterprise administration layer. The primary concern is not only whether Ivanti EPMM, MDM, endpoint-management, or enterprise management systems were vulnerable, but whether exposed or high-trust management infrastructure allowed attackers to gain administrative influence before remediation. If compromise occurred, response may expand into management-server isolation, administrative account review, device-policy validation, certificate and token rotation, connector credential replacement, enrollment-profile review, downstream device scoping, identity and directory integration review, mobile-fleet assurance, legal review, customer or workforce communications, and executive incident governance. This creates financial, operational, regulatory, security-governance, workforce-productivity, and reputational exposure beyond the initially affected management platform.
S3 — Why This Matters Now
· Active exploitation of MDM and enterprise management control planes should be treated as a high-priority control-plane compromise risk, not as a routine patch-management issue.
· MDM and enterprise management platforms often hold privileged authority over device enrollment, device policy, certificates, administrative users, API tokens, connectors, identity integrations, security controls, and downstream operational workflows.
· Successful compromise can create uncertainty around whether device-management actions, enrollment changes, policy pushes, certificate updates, connector activity, and administrative actions remain trustworthy.
· Management infrastructure can provide broad operational reach across corporate devices, mobile fleets, endpoints, privileged services, identity-adjacent integrations, and security-management workflows.
· Patch status alone does not prove that exposed or vulnerable management systems were uncompromised before remediation.
· Historical compromise review is required for management-control-plane systems that were exposed, vulnerable, internet-facing, or reachable by untrusted paths before patch validation.
· Organizations must be prepared to assess suspicious administrative access, abnormal management-server behavior, privileged object changes, rare outbound communication, file staging, persistence activity, service instability, and downstream device-management impact.
· Exposure-only telemetry should support prioritization and hunting, but it must not be treated as confirmed compromise without stronger behavioral, administrative, endpoint, network, or application evidence.
· Organizations without reliable management-platform logs, administrative audit records, process telemetry, file activity, network visibility, connector mapping, certificate inventory, and device-policy change history face elevated risk of delayed detection and incomplete scoping.
· CISA’s addition of CVE-2026-10520, an Ivanti Sentry OS command injection vulnerability, to the Known Exploited Vulnerabilities Catalog confirms active-exploitation urgency for secure mobile gateway infrastructure and reinforces the need to treat Ivanti Sentry as part of the broader enterprise mobility and management-control-plane exposure surface.
S4 — Key Judgments
· Active exploitation of MDM and enterprise management control planes creates a high-priority enterprise compromise risk because affected platforms may control devices, policies, credentials, certificates, connectors, and administrative workflows.
· The primary business risk is loss of confidence in the management layer used to govern enterprise devices, enforce policy, support security controls, manage enrollment, and integrate with identity, directory, certificate, and endpoint ecosystems.
· Executive risk is highest when suspicious administrative access is followed by management-server misuse, privileged management-object changes, abnormal outbound communication, persistence activity, or downstream device-management impact.
· Vulnerable or exposed Ivanti EPMM, MDM, endpoint-management, security-management, and enterprise administration servers should drive emergency remediation and retrospective review, but exposure alone should not be treated as confirmed compromise.
· Management-server integrity is central because trusted management platforms should not behave like compromised application servers, unauthorized administrative surfaces, or adversary-controlled pivot points.
· Administrative audit records are required to determine whether administrator accounts, roles, certificates, connectors, enrollment profiles, API tokens, policies, integrations, or platform configuration objects were created, modified, or abused.
· Network visibility materially improves confidence by identifying unusual outbound communication, abnormal DNS activity, staged transfer behavior, and unexpected internal movement from trusted management servers.
· Cloud telemetry is relevant only where the management-control-plane infrastructure is hosted in AWS, Azure, or GCP, or where cloud identity, compute, audit, and network logs provide meaningful visibility into the affected management asset.
· Detection and response must remain behavior-led because exploit paths, payloads, attacker infrastructure, public indicators, and vendor-specific artifacts can change quickly.
· Executive risk reduction depends on exposed asset identification, remediation validation, log preservation, historical compromise review, administrative-object review, connector and credential assurance, device-policy validation, and verified coverage across management, endpoint, identity, application, network, and cloud telemetry where applicable.
S5 — Executive Risk Summary
Business Risk
MDM and enterprise management control-plane compromise can create severe operational, security-governance, workforce-productivity, and regulatory risk when attackers gain influence over platforms used to manage devices, policies, certificates, enrollment workflows, administrative roles, connectors, API tokens, and downstream integrations. Risk increases when affected systems support mobile-device fleets, privileged endpoint administration, security-management workflows, identity-adjacent connectors, certificate distribution, executive devices, regulated-user populations, production support teams, or high-value enterprise operations.
Technical Cause
The risk is driven by active exploitation or abuse of exposed or vulnerable management-control-plane infrastructure, including Ivanti EPMM and comparable MDM, endpoint-management, security-management, and enterprise administration systems. The enterprise response model should focus on administrative access anomalies, suspicious management-server behavior, privileged object changes, abnormal API or application activity, file staging, persistence behavior, rare outbound communication, unexpected internal movement, and downstream device-management impact.
Threat Posture
The threat posture is elevated because successful compromise can convert a trusted management platform into an adversary-controlled administrative surface or pivot point. The risk is amplified because management platforms may have broad authority over endpoints, mobile devices, policy enforcement, certificates, enrollment profiles, device actions, connectors, identity integrations, and security tooling. A compromise may therefore create uncertainty around both the affected server and the trustworthiness of actions issued through the platform.
Executive Decision Requirement
Executives must require immediate validation of affected management-platform inventory, exposure state, patch status, administrative access history, management-console activity, privileged object changes, connector integrity, certificate and token exposure, endpoint visibility, outbound communication, and downstream device-management impact. Response leadership should also confirm that remediated systems exposed before patch validation receive historical compromise review rather than being closed solely on remediation completion.
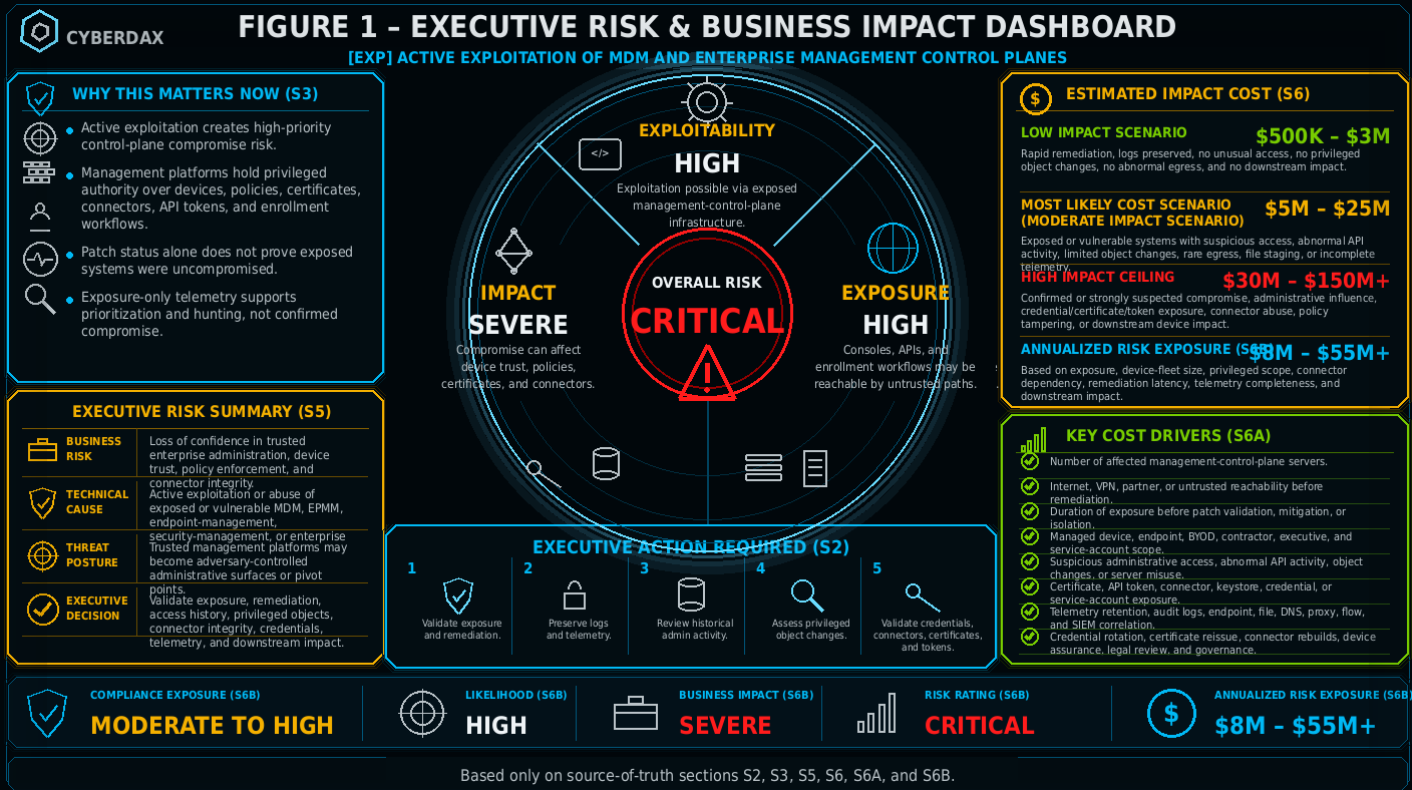
S6 — Executive Cost Summary
[EXP] Active Exploitation of MDM and Enterprise Management Control Planes creates financial exposure based on management-platform authority, device-fleet size, exposed-server count, exposure duration, privileged-object integrity, certificate and token scope, connector dependency, downstream device impact, identity and directory integration risk, remediation latency, telemetry completeness, and the degree to which compromised infrastructure may have affected device trust, policy enforcement, enrollment workflows, compliance state, security tooling, or enterprise administration.
Low Impact Scenario
Rapid assessment confirms that affected MDM, EPMM, endpoint-management, security-management, or enterprise administration systems were patched or mitigated quickly, were not reachable from untrusted networks, logs are preserved, no unusual administrative access is observed, no suspicious management-service behavior occurred, no privileged management objects were modified, no unexpected certificate, token, connector, enrollment-profile, or policy changes are identified, and no abnormal outbound communication or downstream device impact is linked to the exposure. Response still requires emergency inventory validation, patch confirmation, administrative-log review, limited endpoint and network hunting, connector validation, certificate and token assurance, and executive tracking because active exploitation conditions existed before remediation; estimated impact $500K to $3M.
Moderate Impact Scenario
One or more management-control-plane systems were exposed, vulnerable, internet-facing, or reachable through untrusted paths during the active exploitation window, and investigation identifies suspicious administrative access, abnormal API activity, management-server instability, rare egress, limited privileged object changes, file staging, or incomplete telemetry without confirmed large-scale device manipulation, broad credential exposure, certificate compromise, or sustained adversary control. Response requires incident-response mobilization, management-server isolation or controlled containment, endpoint and file-system review, administrative audit reconstruction, connector and integration validation, certificate and token review, targeted privileged account rotation, device-policy validation, mobile-fleet scoping, detection tuning, SOC surge support, legal assessment, executive coordination, and workforce or customer communications readiness; estimated impact $5M to $25M.
High Impact Scenario
Confirmed or strongly suspected compromise affects MDM, EPMM, endpoint-management, security-management, or enterprise administration infrastructure with evidence of unauthorized administrative control, suspicious management-service behavior, privileged role or account manipulation, certificate or API-token exposure, connector abuse, policy tampering, enrollment-profile modification, downstream device actions, lateral movement, abnormal egress, persistence activity, or incomplete historical telemetry. Response may require broad management-platform containment, emergency device-policy freezes, certificate revocation and reissuance, API-token and connector credential rotation, privileged account reset at scale, mobile-device and endpoint assurance campaigns, selective device re-enrollment, integration rebuilds, identity and directory review, downstream compromise hunting, server rebuild or migration, legal and regulatory review, cyber insurance engagement, workforce productivity coordination, customer assurance where applicable, and board-level incident governance; estimated impact $30M to $150M or higher.
S6A — Key Cost Drivers
· Number of affected Ivanti EPMM, MDM, endpoint-management, security-management, and enterprise administration servers.
· Whether affected management platforms were internet-facing, externally reachable, VPN-reachable, partner-reachable, or accessible through untrusted network paths before remediation.
· Duration of exposure before patch validation, mitigation, access restriction, or isolation.
· Number of enrolled mobile devices, managed endpoints, privileged user devices, executive devices, regulated-user devices, BYOD devices, contractor devices, and service accounts under the affected platform’s authority.
· Whether suspicious administrative access, abnormal session behavior, unusual API activity, or non-baseline administrator behavior occurred before remediation.
· Whether suspicious access was followed by management-server misuse, shell or script launch, file staging, archive creation, service modification, scheduled-task creation, or persistence-relevant activity.
· Whether administrator accounts, roles, permissions, certificates, connectors, API tokens, enrollment profiles, device-management profiles, compliance policies, security policies, integrations, or platform configuration objects were created, modified, disabled, rotated, exported, or abused.
· Whether device actions occurred after suspicious access, including policy pushes, device locks, device wipes, certificate distribution, profile changes, enrollment changes, compliance-state changes, application deployment, or configuration updates.
· Scope of certificate, API token, integration secret, database credential, connector credential, keystore, directory credential, or service-account exposure.
· Dependency on affected management platforms for mobile fleet operations, endpoint compliance, conditional access, device posture, certificate-based authentication, application deployment, remote support, security enforcement, or regulated workforce operations.
· Availability and retention of management-platform audit logs, administrative authentication logs, API logs, endpoint process telemetry, command-line capture, file telemetry, DNS logs, proxy logs, network flow data, cloud audit logs, and SIEM-normalized correlation.
· Ability to map management actions to affected devices, users, groups, policies, certificates, profiles, connectors, applications, and downstream business units.
· Need for certificate revocation, certificate reissuance, API-token rotation, connector rebuilds, service-account resets, administrator credential rotation, device re-enrollment, or policy rollback.
· Need to validate whether security controls managed by the platform were weakened, bypassed, disabled, misconfigured, or used to create unauthorized access.
· Need to distinguish legitimate administrator maintenance, vendor support, connector behavior, patching, certificate renewal, policy rollout, enrollment activity, and automation from adversary control-plane abuse.
· Need for downstream review across identity, endpoint, mobile-device, cloud, network, application, certificate, and directory telemetry.
· Degree to which incomplete telemetry forces broader containment, expanded device assurance, integration rebuilds, or executive incident governance.
· Need for workforce communications, customer assurance, legal review, regulatory assessment, cyber insurance reporting, contractual notification analysis, or board-level oversight.
Most Likely Scenario Justification
Moderate scenario is most likely when management-control-plane systems were exposed or vulnerable during the active exploitation window and require historical compromise review, but available evidence does not confirm broad device manipulation, large-scale certificate or token exposure, sustained adversary control, or enterprise-wide downstream compromise. The estimate moves toward the lower end when telemetry confirms rapid remediation, no suspicious administrative access, no management-service misuse, no privileged object changes, no rare egress, no connector abuse, and no downstream device impact. The estimate moves toward the upper end when affected systems manage large device fleets, support executive or regulated users, integrate with identity or certificate services, have incomplete telemetry, show suspicious administrative access, include privileged object changes, require certificate or token rotation, or force device-by-device assurance activity.
S6B — Compliance and Risk Context
Compliance Exposure Indicator
Moderate to High depending on whether unauthorized administrative access, device-policy manipulation, certificate exposure, API-token exposure, connector credential compromise, device wipe or lock activity, regulated-user device impact, downstream identity exposure, customer-impact uncertainty, or incomplete forensic scoping affected systems subject to regulatory, contractual, customer, insurance, privacy, workforce, or material business obligations.
Risk Register Entry
Risk Title
MDM and Enterprise Management Control-Plane Compromise from Active Exploitation
Risk Description
Adversaries may exploit or abuse exposed MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms to gain unauthorized administrative influence, modify privileged management objects, alter device policies, access certificates or API tokens, abuse connectors, manipulate enrollment workflows, stage post-exploitation activity, communicate externally from trusted management infrastructure, and expand impact across managed devices, users, identities, integrations, and downstream enterprise systems.
Likelihood
High.
Impact
Severe.
Risk Rating
Critical.
Annualized Risk Exposure
Estimated $8M to $55M or higher based on management-platform exposure, active exploitation conditions, device-fleet size, privileged administration scope, connector dependency, certificate and token footprint, remediation latency, telemetry completeness, administrative-object integrity, downstream device impact, credential rotation burden, containment complexity, workforce productivity exposure, customer assurance requirements, and legal or regulatory obligations.
S7 — Risk Drivers
· Active exploitation of MDM and enterprise management control-plane vulnerabilities increases near-term compromise likelihood.
· Affected platforms often hold privileged authority over devices, users, policies, certificates, enrollment workflows, connectors, API tokens, and downstream integrations.
· Exposed or internet-facing management consoles and APIs create direct administrative attack surface.
· Successful compromise may create uncertainty around whether device-management actions, policy changes, certificate distribution, and administrator activity remain trustworthy.
· Management-server compromise can support policy tampering, device-profile changes, certificate abuse, connector abuse, credential access, lateral movement, staging, persistence, and rare outbound communication.
· Large mobile-device and endpoint fleets increase blast-radius risk because one compromised management platform can affect many users, devices, business units, or regulated populations.
· Connector dependencies can expand impact into identity services, directory services, certificate authorities, mobile gateways, application deployment systems, logging platforms, security tools, and cloud-hosted infrastructure.
· Certificate or token exposure can force broad revocation, reissuance, application validation, device trust review, and authentication-flow assurance.
· Patch validation does not prove systems were uncompromised before remediation.
· Missing management-platform audit logs weaken analysis of administrative actions, object changes, API activity, and session behavior.
· Missing endpoint process telemetry weakens investigation of suspicious management-server behavior.
· Missing command-line visibility weakens analysis of shells, scripts, network utilities, archive tools, credential utilities, and persistence mechanisms.
· Missing file telemetry weakens discovery of script staging, web-accessible writes, archive creation, service modification, scheduled tasks, and sensitive configuration access.
· Missing DNS, proxy, firewall, NDR, or flow telemetry weakens discovery of rare egress, beacon-like communication, staged transfer activity, and unexpected east-west movement from management servers.
· Missing asset-role tagging weakens the ability to distinguish high-risk management-control-plane activity from ordinary server behavior.
· Missing baselines for administrator behavior, vendor update paths, connector dependencies, policy rollouts, certificate renewal, and maintenance windows increase false-positive risk and slow investigation.
· Legitimate vendor support, patching, connector synchronization, certificate renewal, policy deployment, device enrollment, backup operations, monitoring, and administrative automation can resemble compromise activity without strong operational context.
· Over-reliance on CVE strings, vendor-specific request paths, public proof-of-concept artifacts, scanner infrastructure, attacker IP addresses, or static indicators can miss evolved exploitation and post-access control-plane abuse.
S8 — Bottom Line for Executives
[EXP] Active Exploitation of MDM and Enterprise Management Control Planes should be treated as a high-priority enterprise control-plane trust risk because affected platforms may hold authority over devices, policies, certificates, connectors, enrollment workflows, and downstream administrative integrations. The key executive concern is not only whether affected management servers were patched, but whether attackers gained influence over trusted management functions before remediation. Risk reduction depends on exposed asset scoping, patch validation, log preservation, historical compromise review, administrative-object integrity review, connector and credential validation, certificate and token assurance, endpoint and network review, downstream device-impact scoping, and verified response readiness. Organizations should prioritize this report as a management-control-plane compromise issue because successful exploitation can create operational disruption, security-policy uncertainty, credential and certificate exposure, device-trust erosion, regulatory uncertainty, workforce impact, and board-level incident governance requirements.
S9 — Board-Level Takeaway
Active exploitation of MDM and enterprise management control planes turns trusted device-management infrastructure into a potential enterprise administrative compromise path. The board-level concern is that attackers may target the same platforms used to manage devices, enforce policies, distribute certificates, maintain compliance, support security operations, and integrate with identity or directory services. Leadership should require evidence that affected management platforms have been identified, exposure has been reduced, remediation has been validated, historical compromise review has been performed, privileged object integrity has been checked, connector and credential risk has been assessed, and downstream device impact can be scoped with confidence. This report supports governance decisions around control-plane integrity, device trust, exposure management, telemetry readiness, credential containment, certificate assurance, regulatory posture, and executive oversight of management-platform compromise risk.

Figure 2
S10 — Threat Overview
[EXP] Active Exploitation of MDM and Enterprise Management Control Planes involves active exploitation of high-trust management platforms that may control enterprise devices, policies, certificates, connectors, enrollment workflows, administrative roles, API tokens, and downstream integrations. The activity is centered on Ivanti EPMM and comparable MDM, endpoint-management, security-management, and enterprise administration infrastructure where successful compromise can affect the trusted control plane used to govern devices and enforce operational policy.
This activity should be assessed as enterprise management-control-plane exploitation rather than a conventional endpoint, user-workstation, or generic web-application compromise. The management platform is the target, the administrative authority layer, and the potential post-compromise operating position. This creates elevated business and operational risk because the same platform may manage device posture, distribute certificates, push policies, support security tooling, integrate with identity or directory services, and issue actions across large device populations.
The primary threat concern is that successful exploitation may allow adversaries to move from management-platform access into administrative influence, privileged object modification, certificate or token exposure, connector misuse, policy tampering, management-server misuse, abnormal outbound communication, or downstream device-management impact. Confirmed downstream compromise should not be assumed without evidence, but suspicious administrative access paired with management-server anomalies, privileged object changes, abnormal outbound communication, file staging, persistence behavior, or unusual downstream device actions should be treated as a high-priority control-plane integrity concern.
S11 — Threat Classification and Type
Threat Type
Active enterprise management-control-plane exploitation.
Threat Sub-Type
MDM, EPMM, endpoint-management, security-management, and enterprise administration compromise risk.
Operational Classification
Exploitation of trusted management infrastructure with potential administrative-control, device-management, connector, certificate, token, and downstream integration impact.
Primary Function
Create unauthorized access, influence, or operational control over affected management infrastructure, enabling potential administrative-object manipulation, device-policy tampering, certificate or token exposure, connector misuse, management-server misuse, abnormal outbound communication, or downstream device-management impact.
S12 — Campaign or Activity Overview
The observed activity is best characterized as active exploitation of MDM and enterprise management-control-plane infrastructure rather than a fully attributed campaign. Confirmed reporting establishes active-exploitation relevance for Ivanti EPMM, but the broader enterprise risk pattern is not limited to one vendor, one CVE, one request path, one exploit payload, or one confirmed intrusion set.
The exploitation pathway centers on management platforms that are exposed, vulnerable, internet-facing, reachable through untrusted paths, or positioned as high-trust infrastructure inside the enterprise. Attackers are likely to prioritize these systems because successful access can provide influence over device management, security policies, certificates, enrollment workflows, connectors, API tokens, administrative accounts, and downstream integrations.
Operationally, the activity should be handled as a management-control-plane trust event. The required investigation question is not only whether an affected platform was present or patched, but whether suspicious administrative access, privileged object changes, management-server misuse, abnormal outbound communication, file staging, persistence activity, connector misuse, or downstream device impact occurred before remediation.
No specific malware family or intrusion set is confirmed for this report. The responsible actor should be treated as unidentified unless future vendor, government, or incident-response reporting provides authoritative attribution.
S13 — Targets and Exposure Surface
The primary targets are Ivanti EPMM and comparable MDM, endpoint-management, security-management, and enterprise administration platforms that hold privileged authority over users, devices, certificates, policies, connectors, enrollment profiles, API tokens, administrative roles, and downstream integrations. Exposure is highest when management consoles, administrative APIs, enrollment workflows, or supporting application services are reachable from the public internet, cloud ingress, permissive routing, trusted or semi-trusted access paths, or other untrusted access paths.
Ivanti Sentry and comparable secure mobile gateway appliances, where those systems broker, protect, or relay access between mobile devices, backend enterprise services, identity dependencies, directory services, certificate infrastructure, connector workflows, or downstream administrative systems.
The exposure surface includes management web consoles, administrative APIs, enrollment workflows, connector services, identity or directory integrations, certificate services, device-policy engines, application servers, databases, service accounts, API tokens, keystores, management-server operating systems, and the network paths that allow interaction with those systems.
Risk increases where affected platforms manage large mobile-device fleets, privileged endpoint populations, executive devices, regulated-user devices, contractor or BYOD populations, remote workforce devices, security-management workflows, certificate-based authentication, conditional-access dependencies, identity-adjacent integrations, or high-value operational environments.
Exposure-only findings should drive urgent remediation and retrospective review. They should not be classified as confirmed compromise unless supported by suspicious administrative access, management-server misuse, privileged object changes, connector misuse, certificate or token exposure, abnormal outbound communication, downstream device actions, persistence activity, forensic evidence, or validated incident-response findings.
S14 — Sectors / Countries Affected
Sectors Affected
· Financial services and banking.
· Healthcare and life sciences.
· Technology, software, SaaS, and cloud-hosted enterprises.
· Telecommunications and mobile-enabled enterprises.
· Government and public-sector organizations.
· Defense industrial base and regulated contractors.
· Energy, utilities, and critical infrastructure operators.
· Manufacturing and industrial operations.
· Retail, ecommerce, and distributed workforce environments.
· Education and research institutions.
· Managed service providers, managed security providers, and IT operations providers.
· Enterprises with large mobile-device, BYOD, contractor-device, executive-device, or regulated-user device populations.
· Organizations that rely on MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms for device trust, policy enforcement, certificate distribution, connector workflows, identity-adjacent integrations, or downstream security operations.
Countries Affected
· Global.
· Exposure is not limited to a single country or region because MDM, EPMM, endpoint-management, and enterprise administration platforms are broadly deployed across enterprise, government, cloud, regulated, mobile, and distributed-workforce environments.
· Countries with large enterprise mobility programs, regulated industries, government operations, cloud adoption, mobile-workforce dependency, or mature endpoint-management ecosystems may face elevated operational exposure.
· Country-specific impact should be assessed by exposed management-platform presence, vulnerable product deployment, administrative-interface reachability, device-fleet size, connector dependency, certificate and token footprint, telemetry quality, remediation status, and incident-response readiness rather than geography alone.
S15 — Adversary Capability Profiling
Capability Level
Moderate to High.
The activity requires the ability to identify exposed or vulnerable enterprise management platforms, exploit management-control-plane services, and operate against systems with privileged administrative authority over devices, policies, certificates, connectors, and downstream integrations. Capability assessment should remain behavior-based because no single actor, toolkit, malware family, or intrusion set is confirmed.
Technical Sophistication
High.
Technical sophistication is elevated because the exploitation target is trusted management infrastructure rather than ordinary user endpoints. Post-exploitation activity, if present, may require knowledge of management-platform workflows, administrative roles, enrollment profiles, policy objects, certificates, API tokens, connectors, service accounts, identity integrations, device-control functions, and downstream operational dependencies.
Infrastructure Maturity
Moderate to High.
Attackers may use cloud-hosted infrastructure, scanning infrastructure, anonymized access paths, compromised intermediaries, VPN services, residential proxy paths, or rotating source infrastructure. Infrastructure maturity should be assessed from local telemetry because public reporting does not confirm a stable adversary infrastructure model for all affected environments.
Operational Scale
Opportunistic to targeted.
The activity should be treated as active and scalable because exposed management platforms can be identified through internet-facing services, vulnerable-version exposure, enterprise mobility footprint, and administrative-interface reachability. Opportunistic targeting is likely against broadly exposed systems, while higher-value organizations with large device fleets, regulated users, certificate dependencies, or identity-adjacent integrations may receive more targeted follow-on attention.
Escalation Likelihood
High for exposed, vulnerable, or insufficiently reviewed management-control-plane systems.
Escalation likelihood is highest when suspicious administrative access is followed by privileged object changes, management-server misuse, certificate or token exposure, connector misuse, abnormal outbound communication, file staging, persistence activity, or downstream device-management impact. Escalation likelihood is lower when exposure was restricted, remediation was completed quickly, telemetry confirms no suspicious access or post-access behavior, and device-policy, connector, certificate, and token integrity have been validated.
S16 — Targeting Probability Assessment
Overall Targeting Probability
High for exposed or vulnerable MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms reachable from the public internet or other untrusted paths.
Moderate for affected management platforms where exposure is uncertain, access is limited to restricted network paths, or telemetry is incomplete.
Low to Moderate for affected management platforms where administrative access was restricted to trusted networks before the active exploitation window, remediation was completed quickly, and telemetry confirms no suspicious administrative access, privileged object change, abnormal server behavior, or downstream device impact.
Targeting Drivers
· Internet or untrusted reachability of management consoles, administrative APIs, enrollment workflows, or supporting application services.
· Presence of affected Ivanti EPMM or comparable high-trust management platforms.
· Management authority over large mobile-device, endpoint, executive-device, contractor-device, BYOD, or regulated-user populations.
· Integration with identity services, directory services, certificate services, conditional access, mobile gateways, security tooling, or downstream administrative systems.
· Certificate, API-token, connector, keystore, database-credential, or service-account footprint.
· Limited management-platform logging, short retention, weak application audit visibility, or incomplete administrative-action records.
· Lack of confirmed remediation, mitigation, access restriction, or historical compromise review.
· Weak administrative-source restrictions or inconsistent administrative audit logging.
· Absence of reliable outbound communication baselines for management servers.
· Public or semi-trusted exposure through cloud ingress, load balancers, permissive firewall policy, unmanaged routing, partner access, VPN-adjacent access, or legacy management architecture.
Most Likely Targets
· Internet-facing Ivanti EPMM, MDM, endpoint-management, security-management, or enterprise administration servers.
· Management platforms supporting large mobile-device, endpoint, executive-device, contractor-device, BYOD, or regulated-user populations.
· Platforms integrated with identity services, directory services, certificate authorities, conditional-access workflows, mobile gateways, security tools, or cloud-hosted infrastructure.
· Management servers with incomplete application logs, weak administrative baselines, limited process telemetry, poor file visibility, or insufficient network monitoring.
· Organizations where management-platform compromise could enable policy manipulation, certificate or token exposure, connector misuse, device trust erosion, downstream access, or incident-response delay.
S17 — MITRE ATT&CK Chain Flow Mapping
Stage 1 — Exposure Identification and Target Selection
Adversaries identify exposed or vulnerable MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms. This stage may involve internet-scale discovery, targeted probing, vulnerable-version identification, or validation of untrusted access paths to management-control-plane services.
MITRE ATT&CK Mapping
T1595 — Active Scanning
Stage 2 — Initial Access Through Exposed Management Platform
Adversaries interact with exposed management-platform services and attempt to exploit vulnerable management-control-plane infrastructure where the service is externally reachable or otherwise accessible through an untrusted path. The core access path is exploitation of a public-facing or reachable management application or administrative service.
MITRE ATT&CK Mapping
T1190 — Exploit Public-Facing Application
Stage 3 — Conditional Privileged Management-Plane Modification
If exploitation produces access or administrative influence, adversaries may attempt to create, modify, or abuse administrator accounts, roles, certificates, API tokens, connectors, enrollment profiles, policies, integrations, or platform configuration objects. This stage should remain evidence-driven and should not be assumed without logs or validated incident-response findings.
MITRE ATT&CK Mapping
T1098 — Account Manipulation, conditional where administrator account, role, token, or privilege changes are observed.
T1562 — Impair Defenses, conditional where security policy, logging, monitoring, device-management controls, or visibility are weakened.
Stage 4 — Conditional Downstream Expansion or Internal Discovery
If the compromised management platform is used as a trusted operating position, downstream signals may include internal discovery, connector misuse, unexpected east-west communication, or unauthorized interaction with identity, directory, certificate, device, or endpoint-management dependencies. This stage is conditional and should require defensible linkage to suspected or confirmed management-control-plane compromise.
MITRE ATT&CK Mapping
T1046 — Network Service Discovery, conditional where downstream reconnaissance or service-discovery activity is observed.
S18 — Attack Path Narrative (Signal-Aligned Execution Flow)
The attack path begins with adversary identification of exposed or vulnerable MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms. The highest-risk exposure condition exists when management consoles, administrative APIs, enrollment workflows, or supporting application services are reachable from the public internet, cloud ingress, permissive routing paths, partner access paths, VPN-adjacent access, or other untrusted access routes.
After identifying a reachable management-control-plane asset, the adversary attempts exploitation against the exposed management platform. The initial objective is not ordinary endpoint compromise. The objective is to gain influence over a trusted administrative layer that may manage devices, policies, certificates, connectors, enrollment profiles, API tokens, service accounts, and downstream integrations.
If access is successful, the next observable phase may involve administrative-session anomalies, abnormal API behavior, management-server misuse, privileged object changes, connector misuse, certificate or token exposure, file staging, abnormal outbound communication, or persistence-relevant activity. These signals should be evaluated in sequence because the exploit attempt itself may not be visible in every environment.
A higher-risk execution flow occurs when suspicious administrative access is followed by management-server behavior that deviates from baseline. Examples include unexpected service-context execution, unusual file creation, script staging, archive creation, rare external egress, unexpected east-west communication, or changes to administrator accounts, roles, certificates, connectors, enrollment profiles, API tokens, device-management profiles, policies, integrations, or platform configuration objects.
The final risk stage occurs when the compromised or abused management platform creates downstream operational impact. This may include unauthorized policy changes, certificate distribution changes, connector misuse, device-profile modification, device-action bursts, enrollment changes, downstream authentication exposure, or interaction with identity, directory, certificate, endpoint, cloud, or security-management dependencies. Downstream compromise should not be assumed without evidence, but management-plane anomalies that affect device trust or administrative control should be treated as high-priority escalation conditions.
Signal-Aligned Execution Flow
· Exposed management-control-plane service is identified or probed.
· Vulnerable or reachable management platform is targeted.
· Suspicious administrative access, abnormal session behavior, or unusual API activity occurs.
· Management-server behavior deviates from baseline through execution, file activity, outbound communication, or internal movement.
· Privileged management-plane objects are created, modified, disabled, rotated, exported, or abused.
· Certificates, API tokens, connectors, enrollment profiles, policies, or platform configuration objects show suspicious activity.
· Downstream device, user, identity, directory, certificate, endpoint, cloud, or security-management dependencies are reviewed for impact.
· Confirmed compromise classification requires correlation across administrative, application, endpoint, file, network, identity, or configuration-change evidence.
S19 — Attack Chain Risk Amplification Summary
Risk amplification occurs because the affected platform may function as a trusted enterprise control plane rather than a single application server. A compromised management platform can create impact across devices, users, certificates, connectors, policies, security tooling, enrollment workflows, and downstream integrations.
The attack chain becomes more severe when the management platform has broad administrative authority, weak exposure controls, incomplete logging, poor asset-role tagging, limited process telemetry, limited file visibility, weak outbound baselines, or insufficient administrative-change monitoring. In those conditions, defenders may struggle to determine whether the platform was merely exposed, accessed, modified, or used to influence downstream systems.
The highest amplification occurs when suspicious administrative access is followed by privileged object changes, management-server misuse, certificate or token exposure, connector misuse, abnormal outbound communication, persistence-relevant activity, or downstream device-management impact. These conditions can turn a management-platform incident into an enterprise trust, device-assurance, credential-containment, and governance issue.
Primary Risk Amplifiers
· Exposed or vulnerable MDM, EPMM, endpoint-management, security-management, or enterprise administration infrastructure.
· Administrative interfaces reachable from public, cloud, partner, VPN-adjacent, or other untrusted paths.
· Large enrolled-device population under the affected platform’s authority.
· Management authority over executive devices, regulated-user devices, contractor devices, BYOD devices, privileged endpoints, or remote workforce devices.
· Integration with identity services, directory services, certificate authorities, mobile gateways, conditional-access workflows, cloud infrastructure, logging platforms, or security tools.
· Access to certificates, API tokens, connector credentials, keystores, database credentials, integration secrets, or service-account material.
· Limited management-platform audit logging or short retention.
· Missing process ancestry, command-line visibility, file telemetry, DNS logs, proxy logs, network flow data, or NDR visibility.
· Weak baselines for administrative users, access sources, vendor update paths, connector dependencies, certificate renewal, maintenance windows, and management-server communication.
· Incomplete ability to map management actions to affected users, devices, policies, profiles, certificates, connectors, applications, or business units.
· Delayed remediation, incomplete historical review, or closure based only on patch status.
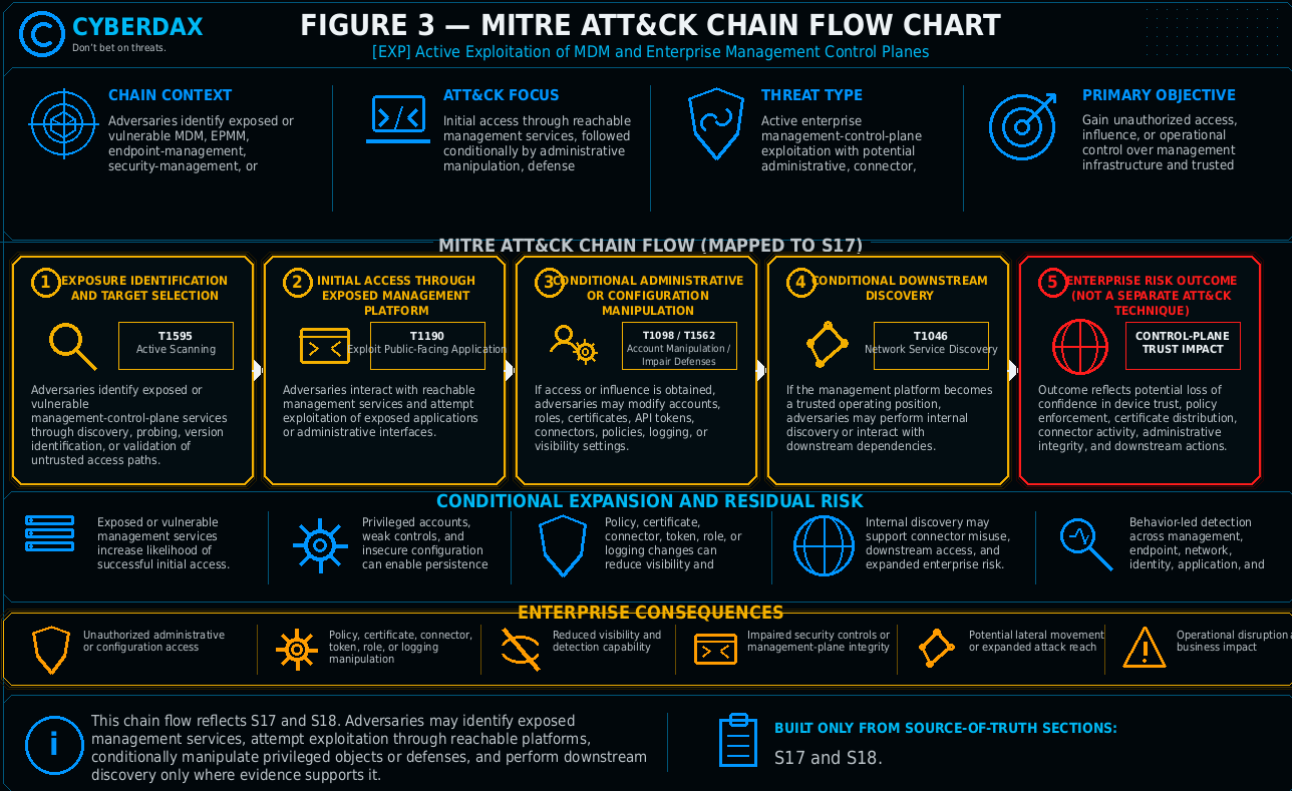
Figure 3
S20 — Tactics, Techniques, and Procedures
Reconnaissance
· Identify exposed management consoles, administrative APIs, enrollment workflows, or supporting application services.
· Validate vulnerable-version exposure, untrusted access paths, or externally reachable management-control-plane services.
· Treat scanning or probing as targeting activity unless paired with post-access behavior.
Initial Access
· Exploit a public-facing or otherwise reachable management application or administrative service.
· Prioritize risk where Ivanti EPMM or comparable management platforms are exposed, vulnerable, internet-facing, or reachable through untrusted paths.
· Evaluate access success through correlated administrative, application, endpoint, file, network, or configuration-change evidence.
Execution
· Trigger unexpected actions from management application services, vendor services, Java processes, Tomcat processes, web-service processes, application-server processes, shells, or scripting engines.
· Watch for shell launch, script execution, network utility use, archive creation, credential-utility use, service-control activity, or persistence-relevant tooling.
· Treat execution from management-service context as elevated risk because the host may have privileged operational reach.
Persistence
· Modify services, scheduled tasks, startup paths, cron entries, web-accessible files, scripts, or legitimate platform objects.
· Review administrator accounts, roles, API tokens, connectors, certificates, enrollment profiles, policies, and integrations for persistence-relevant control-plane changes.
Privilege Escalation and Account Manipulation
· Create, modify, enable, disable, rotate, export, or abuse administrator accounts, roles, tokens, certificates, service accounts, connectors, or privileged platform objects.
· Prioritize changes performed by unusual users, from unusual sources, outside change windows, or near abnormal management-server behavior.
Defense Evasion
· Weaken logging, monitoring, administrative visibility, device-management controls, security policies, connector visibility, or endpoint-management enforcement.
· Prioritize changes affecting logging, monitoring, policy enforcement, certificate distribution, enrollment behavior, or control-plane visibility.
Credential, Certificate, and Token Access
· Seek certificates, API tokens, connector credentials, database credentials, keystores, integration secrets, service-account credentials, or identity-adjacent material.
· Assess exposure through file access, configuration access, administrative export activity, unusual API use, connector changes, or downstream authentication anomalies.
Discovery and Lateral Movement
· Use management infrastructure to discover internal services, identity dependencies, directory services, databases, certificate systems, logging infrastructure, endpoints, or connected administrative systems.
· Prioritize unexpected east-west communication, administrative protocol use, connector misuse, or new internal connections outside established dependency baselines.
Command and Control / External Communication
· Use management servers for rare external egress, staged transfer behavior, beacon-like communication, payload retrieval, or communication with newly observed destinations.
· Evaluate external communication against vendor update paths, approved integrations, connector dependencies, monitoring systems, and maintenance workflows.
Impact
· Manipulate device policies, certificates, enrollment profiles, connectors, device actions, management-platform stability, or security controls.
· Prioritize impact assessment where large device fleets, regulated users, executive devices, certificate or token exposure, identity-adjacent integrations, or incomplete telemetry increase scoping uncertainty.
S20A — Adversary Tradecraft Summary
The tradecraft model for this report is behavior-led and control-plane focused. The durable concern is not a single exploit string, malware family, or static indicator. The durable concern is adversary use of exposed or vulnerable management infrastructure to gain influence over trusted administrative functions.
The most important tradecraft feature is the use of a high-trust management platform as the target and potential operating position. This differs from ordinary endpoint compromise because the platform may already possess authority over users, devices, policies, certificates, connectors, and downstream integrations.
Tradecraft assessment should focus on the relationship between access, management-server behavior, privileged object changes, and downstream impact. Isolated exposure, scanning, or administrative activity should not be treated as confirmed compromise without stronger evidence. The highest-confidence concern arises when administrative anomalies are followed by management-server misuse, privileged control-plane changes, abnormal outbound communication, persistence-relevant activity, or device-management impact.
Key Tradecraft Characteristics
· Targeting of high-trust MDM, EPMM, endpoint-management, security-management, or enterprise administration infrastructure.
· Use of exposed management consoles, APIs, enrollment workflows, or application services as access paths.
· Potential use of legitimate administrative workflows after initial access.
· Focus on administrator accounts, roles, certificates, API tokens, connectors, enrollment profiles, policies, integrations, and platform configuration objects.
· Possible management-service execution, file staging, archive creation, script use, or persistence-relevant activity from trusted management infrastructure.
· Possible rare egress, unexpected east-west communication, connector misuse, or dependency-deviation behavior from management servers.
· Potential downstream impact through device-policy changes, certificate distribution changes, enrollment-profile changes, device actions, or security-control weakening.
· Reliance on baseline deviation rather than stable public indicators for durable detection and investigation.
· Need for correlation across management-platform logs, administrative authentication, endpoint telemetry, file telemetry, network telemetry, identity context, and downstream device-management evidence.
S21 — Detection Strategy Overview
Detection Philosophy
Detection for this report must be behavior-led, correlation-driven, and resilient to exploit variation. The case trigger is active exploitation of an Ivanti EPMM vulnerability added to the CISA Known Exploited Vulnerabilities Catalog, but the detection strategy is not limited to a single CVE, vendor artifact, request path, payload marker, or exploit signature.
This report evaluates a broader adversary pattern: exploitation or abuse of MDM platforms and enterprise management control planes that hold privileged administrative authority, trusted network placement, device-management control, integration credentials, certificates, policy control, and downstream operational reach.
The detection objective is to identify when a trusted management platform begins behaving like a compromised application server, unauthorized administrative-control surface, or adversary-controlled pivot point.
Confirmed reporting establishes active-exploitation relevance. Detection engineering must focus on defensible behavioral signals associated with management-plane compromise, including anomalous administrative access, suspicious server-side execution, abnormal management-server network behavior, privileged configuration changes, and post-exploitation activity.
Primary Detection Anchors
Administrative Access Anomaly
Successful access to an MDM, EPMM, endpoint-management, security-management, or enterprise administration console from an unusual source, account, geography, ASN, device, time window, or authentication pattern.
Management-Server Execution Anomaly
Suspicious process execution from a vendor service, Java process, Tomcat process, web-service process, application-server process, or management-platform service account.
Management-Server Network Anomaly
Rare outbound communication, unexpected external egress, abnormal DNS activity, unusual file transfer, unexpected east-west movement, or beacon-like activity originating from a management server.
Privileged Control-Plane Change
Creation, modification, or abnormal use of administrative users, roles, certificates, connectors, enrollment profiles, API tokens, device-management profiles, policy objects, or integration settings.
Post-Exploitation Activity
Suspicious file writes, script execution, archive staging, service modification, scheduled-task creation, startup modification, credential-access behavior, webshell-like artifacts, or persistence-relevant activity on management infrastructure.
Detection Prioritization Model
Priority 1
Detect suspicious child-process execution from management-platform service context.
This is the highest-value detection category because management application services should not normally launch shells, scripting engines, network utilities, archive utilities, credential-access tools, or persistence mechanisms.
Priority 2
Detect unusual administrative access followed by abnormal host or network behavior.
This provides stronger fidelity than isolated login monitoring by requiring post-access activity consistent with compromise or unauthorized control-plane abuse.
Priority 3
Detect privileged management-plane object changes that deviate from administrative baseline.
This includes unusual administrator creation, role changes, connector modification, certificate changes, policy manipulation, enrollment-profile changes, or API-token activity.
Priority 4
Detect abnormal outbound or lateral communication from management servers.
This supports identification of staging, command-and-control, discovery, expansion, and adversary use of trusted infrastructure as a pivot point.
Priority 5
Detect cloud-hosted management-server anomalies only where AWS, Azure, or GCP telemetry is relevant to the deployed management-plane architecture.
Cloud detections are conditional and should not be forced into environments where management infrastructure is not cloud-hosted or where cloud telemetry does not provide meaningful visibility.
Correlation Strategy and Enforcement Requirements
Detection logic must enforce asset role, event sequence, and behavioral proximity.
The preferred detection chain is successful administrative access to a management-control-plane interface, followed by privileged administrative action, followed by suspicious host execution, file modification, outbound communication, persistence behavior, or abnormal east-west movement.
Single-event detection is acceptable only when the event is independently high-confidence, such as a management application process spawning a shell, scripting engine, credential utility, network utility, or persistence mechanism.
Rules must prioritize the management-server role. Similar activity on a standard workstation may be suspicious, but the same activity on an MDM or enterprise management server carries greater operational risk because the system may provide broad administrative reach across users, devices, policies, credentials, certificates, and integrations.
Correlation logic must support multiple detection paths. The exploit attempt itself may not be visible. Post-exploitation behavior may still be identifiable through service-context execution, management-object manipulation, abnormal egress, or baseline deviation from a high-trust control-plane asset.
Telemetry Prioritization
Endpoint telemetry should be prioritized for process ancestry, service-context execution, file activity, persistence behavior, and suspicious utility usage.
SIEM telemetry should be prioritized for correlation across administrative authentication, application events, identity events, endpoint events, proxy logs, network telemetry, and privileged configuration changes.
NDR telemetry should be prioritized for role-aware network anomaly detection, rare destination analysis, abnormal egress, unexpected east-west communication, baseline deviation, staged file-transfer behavior, and beacon-like communication from management infrastructure.
NDR must not be treated as a packet-signature replacement. Its value is behavioral visibility into trusted management infrastructure that communicates outside expected patterns.
Application and web telemetry should be prioritized where available for console access, API usage, administrative actions, account changes, role changes, policy modification, certificate changes, connector changes, enrollment-profile changes, and device-management configuration activity.
Cloud telemetry is conditional. AWS, Azure, and GCP telemetry should be used only when management-control-plane infrastructure is deployed in those environments or when cloud identity, compute, audit, and network logs provide meaningful visibility into the affected management server.
Detection Design Constraints
Detection logic must not assume unauthenticated exploitation unless confirmed by authoritative reporting.
Detection logic must not depend on a single vendor-specific URI, request parameter, packet artifact, payload value, toolmark, or exploit string unless confirmed by authoritative technical reporting.
Detection logic must not over-attribute activity to a named threat actor without authoritative attribution.
Detection logic must not treat all administrative access to MDM or enterprise management platforms as suspicious.
Detection logic must not force YARA coverage without a stable file artifact, malware sample, webshell pattern, memory artifact, payload structure, or confirmed malicious script.
Detection logic must not require uncommon telemetry unless the dependency is clearly marked as conditional.
Baseline and Deployment Requirements
Organizations must identify and tag MDM servers, EPMM servers, endpoint-management servers, security-management servers, identity-adjacent administration systems, and other high-trust enterprise control-plane assets.
Organizations must establish expected administrative access sources, expected administrator accounts, expected management-console behavior, expected outbound destinations, vendor update paths, connector dependencies, directory-service dependencies, and normal management-server communication patterns.
Baselines must support role-aware detection. Management infrastructure should not be evaluated with the same tolerance profile as ordinary endpoints or general-purpose server
Organizations must tag Ivanti Sentry and comparable secure mobile gateway appliances as enterprise mobility control-plane assets so detection logic applies the same elevated-risk interpretation used for MDM, EPMM, endpoint-management, security-management, and enterprise administration infrastructure.
Variant Resilience Requirements
Rules must remain effective across Ivanti EPMM and comparable MDM, endpoint-management, security-management, and enterprise administration platforms.
Rules must detect suspicious behavior when exploit paths change, public indicators rotate, attacker infrastructure changes, payload delivery varies, or adversaries rely on legitimate administrative functions.
Rules must detect compromised administrative use, not only direct exploit execution.
Rules must support externally exposed and internally restricted management-plane deployments.
Rules must account for adversary use of native operating-system utilities, trusted service accounts, legitimate connectors, expected administrative privileges, and normal management-platform tooling.
Operational Detection Model
Management servers must be treated as high-risk, high-trust infrastructure requiring elevated detection sensitivity.
A management server that initiates unusual outbound traffic, spawns command interpreters, writes unexpected executable or script content, modifies persistence mechanisms, performs abnormal lateral movement, or changes privileged management objects should receive higher triage priority than a standard server with similar telemetry.
Alerts should be enriched with asset role, internet exposure, patch status, administrative-account history, source reputation, maintenance-window status, recent configuration changes, vendor-support activity, and related vulnerability exposure.
SOC triage should determine whether activity reflects normal administrative maintenance, patching, vendor support, backup operations, connector behavior, or credible compromise.
The strongest detection outcomes will come from multi-signal correlation rather than isolated telemetry events.
S22 — Primary Detection Signals
Primary Detection Signals
· Administrative access anomaly involving successful access to an MDM, EPMM, endpoint-management, security-management, or enterprise management console from an unusual source, account, device, geography, ASN, time window, or authentication pattern.
· Management application process spawning a suspicious child process, including a shell, scripting engine, network utility, archive utility, credential-access tool, or persistence-related utility from a vendor service, Java process, Tomcat process, web-service process, application-server process, or management-platform service account.
· Management server rare egress to a newly observed, low-reputation, geographically unusual, or operationally inconsistent external destination.
· Privileged control-plane object change involving administrator accounts, roles, certificates, connectors, enrollment profiles, API tokens, device-management profiles, policy objects, integrations, or platform configuration objects.
· Management server file or persistence activity involving suspicious file creation, script staging, archive creation, service modification, scheduled-task creation, startup modification, web-accessible file writes, or other persistence-relevant changes.
· Ivanti Sentry or comparable secure mobile gateway service activity followed by shell or script execution, rare outbound communication, unexpected backend dependency access, suspicious file creation, connector or certificate access, service instability, or other appliance behavior inconsistent with the approved mobile gateway baseline.
Supporting Detection Signals
· Unusual administrator session pattern involving abnormal login frequency, rapid reauthentication, new device access, new network location, or activity inconsistent with prior account usage.
· Administrative action outside change window involving configuration, policy, connector, certificate, enrollment, role, or account changes outside known maintenance periods.
· Unexpected management API activity affecting privileged objects, device policies, enrollment workflows, connectors, tokens, or administrative roles.
· Unexpected service account activity involving interactive execution, unusual process ancestry, abnormal authentication, external communication, or access to sensitive configuration paths.
· Unusual error, fault, or instability pattern involving application errors, service restarts, crash events, repeated failed operations, or abnormal platform instability near suspicious access or execution activity.
· Unusual device or policy impact involving unexpected policy pushes, enrollment changes, device-profile modification, certificate distribution changes, connector updates, or management-action bursts affecting downstream devices or users.
Exploit Attempt and Instability Signals
· Application service instability involving unexpected restart, crash, fault, or abnormal service behavior affecting the management platform.
· Malformed or abnormal request pattern involving unusual request volume, abnormal request structure, repeated failed actions, or anomalous administrative workflow activity.
· Unexpected privileged workflow execution resulting in abnormal server-side behavior, including suspicious execution, file creation, configuration modification, or outbound communication.
· Authentication and session irregularity involving repeated failures, unusual session creation, session reuse from unfamiliar sources, new device access, or abrupt changes in administrator source patterns.
Outbound Communication Signals
· Rare external destination involving management server communication to a destination outside known vendor update paths, connector dependencies, identity services, directory services, or approved integrations.
· New DNS resolution pattern involving newly observed domains, unusual subdomains, dynamic infrastructure, uncommon top-level domains, or destinations inconsistent with baseline.
· Beacon-like communication involving periodic or repeated outbound communication from a management server to an external destination inconsistent with normal update, connector, or directory-service behavior.
· Unusual file-transfer behavior involving large, staged, compressed, repeated, or directionally unusual data transfer by a management server.
· Unexpected east-west communication involving management server communication to internal systems outside established MDM, identity, directory, connector, database, logging, or update architecture.
Persistence and Post-Exploitation Signals (Conditional)
· Service modification involving creation, modification, or abnormal restart behavior on the management server.
· Scheduled task or startup modification involving scheduled tasks, startup entries, cron jobs, launch agents, or comparable persistence mechanisms.
· Web-accessible file write involving creation or modification of files in application, web, upload, plugin, extension, temporary, or externally reachable directories.
· Suspicious script or archive staging involving scripts, archives, encoded content, compressed files, or temporary staging artifacts associated with the management application or service account.
· Credential or token access involving credential stores, configuration files, certificates, API tokens, integration secrets, database connection strings, keystores, or identity-related material.
Lateral Movement and Expansion Signals (Conditional)
· Management server initiating new internal connections to hosts, administrative services, file shares, identity infrastructure, databases, or endpoints outside the established baseline.
· Authentication from management server to unusual internal targets that do not normally receive management-platform authentication.
· Use of administrative protocols from management infrastructure, including unexpected SSH, RDP, SMB, WinRM, remote PowerShell, database protocols, directory protocols, or administrative APIs.
· Downstream policy or device-control abuse involving unusual policy deployment, device action, certificate distribution, enrollment-profile modification, or configuration push.
· Connector or integration abuse involving abnormal use of identity integrations, directory integrations, certificate services, mobile gateway integrations, or security-platform integrations.
Signal Usage Constraints
· Primary signals should be correlated by asset role, account behavior, event sequence, and baseline deviation.
· Management application child-process execution may justify high-confidence escalation as a single event when process ancestry and asset role are clear.
· Administrative login anomalies should not be treated as standalone compromise evidence unless paired with suspicious post-access activity or highly abnormal source characteristics.
· Network anomalies should be enriched with vendor update paths, connector dependencies, directory-service behavior, approved integrations, maintenance windows, and historical communication baselines.
· Application errors, failed requests, and service instability should be treated as supporting signals unless paired with suspicious access, execution, file activity, or outbound communication.
· Persistence and lateral movement signals should be evaluated when host, identity, network, or application telemetry indicates that management-server activity moved beyond initial administrative access or application-layer abuse.
S23 — Telemetry Requirements
Endpoint and Process Execution Telemetry
Endpoint telemetry is required to identify suspicious execution from MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
Telemetry requirements include, where available:
· Parent-child process relationships.
· Process command line.
· Process user and service-account context.
· Executable and script paths.
· Script interpreter usage.
· Network, archive, and credential-utility execution.
· Service creation or modification.
· Scheduled task, cron, startup, or launch-agent activity.
· Process-to-network connection mapping.
Priority should be given to telemetry that identifies management application processes launching unexpected child processes. This includes Java, Tomcat, web-service, vendor-service, application-server, and management-platform service processes spawning shells, scripting engines, network utilities, archive tools, credential-access tools, or persistence-related utilities.
Endpoint telemetry must support asset-role context. Activity from a management server should be evaluated differently than comparable activity from a standard workstation or general-purpose server because management systems carry elevated administrative authority and downstream operational reach.
Memory and Execution Telemetry
Memory and execution telemetry should be collected where available to support investigation of suspicious server-side execution, injected execution, abnormal child-process activity, and post-exploitation behavior.
Relevant telemetry includes:
· Script and interpreter execution.
· Encoded or obfuscated command execution.
· In-memory execution indicators.
· Suspicious module loading.
· Abnormal runtime behavior from application-server processes.
· EDR behavioral detections tied to exploitation, credential access, persistence, or defense evasion.
Memory telemetry is not the primary detection anchor for this report, but it can improve investigation quality when suspicious execution originates from a management-platform service context.
Crash and Fault Telemetry
Crash and fault telemetry is required where available to support detection of exploit-adjacent instability, failed exploitation, abnormal administrative workflows, or unexpected platform behavior.
Relevant telemetry includes:
· Application crashes.
· Service restarts.
· Fault events.
· Repeated failed operations.
· Abnormal application errors.
· Web-server or application-server error spikes.
· Unexpected management-platform instability.
Crash and fault signals should be treated as supporting evidence. They should not be used as standalone proof of compromise unless paired with suspicious administrative access, process execution, file activity, outbound communication, or privileged control-plane changes.
File and Persistence Telemetry
File and persistence telemetry is required to identify staging, payload placement, script creation, web-accessible writes, persistence attempts, and post-exploitation changes on management infrastructure.
Telemetry requirements include, where available:
· File creation, modification, deletion, and rename activity.
· File path, directory context, and file hash where available.
· Web-accessible directory writes.
· Upload, plugin, extension, temporary, and application-directory writes.
· Script, archive, encoded-content, or compressed-content creation.
· Service creation or modification.
· Scheduled task, startup, cron, or launch-agent modification.
Priority should be given to file and persistence events initiated by management-platform processes, vendor services, application-server processes, service accounts, or unusual administrative sessions.
File telemetry is most useful when correlated with management-console access, abnormal API activity, suspicious child-process execution, rare egress, or privileged configuration changes.
Network and Outbound Communication Telemetry
Network telemetry is required to detect abnormal egress, rare destinations, unexpected east-west communication, staging activity, beacon-like behavior, and management-server communication outside established baseline.
Relevant telemetry includes:
· Source and destination host.
· Destination IP, domain, and ASN where available.
· Port, protocol, and connection direction.
· Session timing and byte count.
· DNS queries.
· TLS/SNI where available.
· Proxy events where available.
· Flow records.
· Internal east-west traffic from management servers.
· External egress from management servers.
Network flow, DNS, proxy, firewall, and NDR telemetry for Ivanti Sentry source IPs, with baselines for approved vendor update paths, mobile access flows, backend dependency paths, connector destinations, identity services, directory services, certificate infrastructure, logging destinations, and monitoring systems.
NDR telemetry should support role-aware anomaly detection. The key requirement is not exploit-payload visibility. The key requirement is the ability to determine when trusted management infrastructure communicates in ways inconsistent with expected vendor, connector, identity, directory, update, logging, or administrative dependencies.
Network telemetry should be enriched with known vendor update paths, approved integrations, connector infrastructure, directory-service dependencies, maintenance windows, and normal management-server communication patterns.
Web and Application Telemetry (Conditional Availability)
Web and application telemetry is required where available because MDM and enterprise management platforms often expose critical administrative actions through web consoles, APIs, connectors, and platform-specific workflows.
Relevant telemetry includes:
· Administrative login and failure events.
· Session creation and session source.
· API calls.
· Administrative action logs.
· Account, role, policy, profile, certificate, connector, token, and integration changes.
· Upload or import actions.
· Application errors.
· Web request metadata.
· Reverse proxy or WAF logs where available.
· Ivanti Sentry appliance logs, gateway service logs, and syslog-forwarded events where available.
· Reverse proxy, WAF, load balancer, and ingress logs that capture access attempts, request metadata, administrative interface access, abnormal errors, or suspicious interaction with Sentry gateway services.
· Backend service logs for systems reachable through Ivanti Sentry, including identity, directory, certificate, connector, application, and administrative dependencies.
This telemetry is conditional because visibility varies by platform, deployment model, logging configuration, and customer environment. Where native application logs are unavailable, proxy, identity, endpoint, NDR, and SIEM telemetry should be used to approximate administrative access, platform usage, and post-access behavior.
Telemetry Availability Requirements
Minimum viable detection requires telemetry from at least one source that can identify suspicious management-server execution and one source that can identify administrative or network context.
Preferred telemetry coverage includes:
· Endpoint process telemetry from management servers.
· Administrative authentication logs.
· Application or API activity logs where available.
· Network flow, proxy, DNS, or NDR telemetry.
· File and persistence telemetry from management servers.
· SIEM correlation across identity, endpoint, application, and network sources.
High-confidence detection requires asset-role tagging for MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
High-confidence correlation requires baseline visibility into expected administrator behavior, management-console activity, outbound destinations, connector dependencies, directory-service dependencies, and internal communication patterns.
Cloud telemetry is required only when the management-control-plane asset is deployed in AWS, Azure, or GCP, or when cloud identity, compute, audit, and network logs provide meaningful visibility into the management server.
Telemetry Limitations and Gaps
Telemetry limitations may reduce the ability to distinguish normal administrative activity from adversary control-plane abuse.
Common telemetry gaps include:
· Lack of application-level administrative action logs.
· Incomplete API logging.
· Missing command-line or parent-child process telemetry.
· Missing service-account context.
· Limited file-write visibility on management servers.
· Incomplete network flow, DNS, proxy, or east-west visibility.
· Insufficient asset-role tagging.
· Weak baselines for administrator behavior.
· Unclear vendor update paths or connector dependencies.
· Limited visibility into cloud-hosted management infrastructure.
· Inconsistent log normalization across SIEM, EDR, NDR, and application sources.
Where telemetry is incomplete, detection should emphasize higher-confidence behavioral combinations rather than isolated events. Administrative access anomalies, rare egress, service instability, and application errors should be treated cautiously unless paired with suspicious execution, file activity, privileged object changes, or abnormal management-server communication.
Detection quality depends on the organization’s ability to identify which systems function as management control planes and to distinguish normal platform behavior from anomalous post-exploitation behavior.

Figure 4
S24 — Detection Opportunities and Gaps
Detection Opportunities
Management Application Execution Monitoring
High-value detection opportunity exists where endpoint telemetry can identify management application processes spawning unexpected child processes. This is the strongest detection opportunity for this report because MDM and enterprise management services should not normally launch shells, scripting engines, credential-access utilities, network utilities, archive tools, or persistence mechanisms.
Administrative Access-to-Execution Correlation
High-value detection opportunity exists where administrative login events can be correlated with suspicious server-side execution. This correlation is especially important for management platforms because adversaries may use valid administrative access, compromised credentials, or legitimate platform workflows to trigger unauthorized behavior.
Management-Server Rare Egress Detection
High-value detection opportunity exists where NDR, proxy, DNS, or flow telemetry can identify management servers communicating with destinations outside expected vendor, connector, identity, directory, update, logging, or administrative dependencies. Rare egress becomes higher fidelity when paired with suspicious execution, file staging, privileged object changes, or abnormal session behavior.
Privileged Control-Plane Change Monitoring
High-value detection opportunity exists where application, API, or administrative audit logs capture changes to administrator accounts, roles, certificates, connectors, enrollment profiles, API tokens, policy objects, device-management profiles, or integration settings. These changes can indicate adversary abuse of legitimate management-plane authority.
Management-Server File and Persistence Monitoring
High-value detection opportunity exists where file and persistence telemetry can identify suspicious file creation, script staging, archive creation, web-accessible writes, service modification, scheduled-task creation, startup modification, or persistence-relevant changes on management infrastructure.
Role-Aware Asset Detection
High-value detection opportunity exists where organizations can reliably tag MDM, EPMM, endpoint-management, security-management, and enterprise administration systems. Asset-role tagging improves detection fidelity by applying stricter interpretation to activity from high-trust control-plane systems than from ordinary endpoints or general-purpose servers.
Exploit-Adjacent Instability Correlation
Moderate-value detection opportunity exists where crash, fault, restart, application-error, or abnormal workflow telemetry can be correlated with suspicious administrative access, process execution, file activity, privileged object changes, or outbound communication. Instability alone is not sufficient for high-confidence detection, but it can strengthen a broader compromise pattern.
Conditional Cloud Visibility
Conditional detection opportunity exists where management-control-plane infrastructure is deployed in AWS, Azure, or GCP. Cloud audit, compute, identity, and network telemetry can provide supporting visibility into administrative access, instance behavior, network egress, and cloud-hosted management-server activity.
Detection Gaps
Limited Native Application Logging
Detection coverage is weakened when MDM or enterprise management platforms do not provide detailed administrative action logs, API logs, session source data, object-change records, or workflow execution events.
Missing Process Ancestry
Detection coverage is materially weakened when endpoint telemetry does not capture parent-child process relationships. Without process ancestry, it is difficult to determine whether suspicious execution originated from a management application process, service account, or unrelated administrator activity.
Missing Command-Line Visibility
Detection coverage is weakened when command-line capture is unavailable or incomplete. Command-line visibility is important for identifying shells, scripts, encoded commands, network utilities, archive tools, credential-access utilities, and suspicious administrative tooling.
Insufficient Asset-Role Tagging
Detection coverage is weakened when organizations cannot reliably identify which systems function as MDM, EPMM, endpoint-management, security-management, or enterprise administration control-plane assets.
Weak Administrative Baselines
Detection coverage is weakened when organizations lack baselines for administrator accounts, expected source networks, normal login windows, approved maintenance windows, routine management-console behavior, or expected privileged object changes.
Incomplete Network Baselines
Detection coverage is weakened when organizations lack baselines for vendor update paths, connector dependencies, identity services, directory services, logging infrastructure, cloud dependencies, approved integrations, and normal east-west communication patterns.
Limited East-West Visibility
Detection coverage is weakened when internal traffic from management servers is not monitored. This limits visibility into lateral movement, internal discovery, connector abuse, unauthorized access to adjacent infrastructure, and management-server pivot activity.
Incomplete File and Persistence Visibility
Detection coverage is weakened when organizations lack visibility into file creation, file modification, web-accessible directory writes, service creation, scheduled-task changes, startup modifications, cron activity, or launch-agent activity on management infrastructure.
Inconsistent Log Normalization
Detection coverage is weakened when SIEM, EDR, NDR, cloud, identity, proxy, and application logs are not normalized consistently. Inconsistent normalization limits correlation across administrative access, host execution, network communication, and privileged configuration changes.
Limited Cloud Context
Detection coverage is limited where management-control-plane assets are cloud-hosted but cloud audit, compute, identity, and network telemetry are unavailable, inconsistently ingested, or not tied back to the management-server asset role.
Detection Engineering Considerations
Correlation Over Isolation
Detection logic should emphasize correlated behavior rather than isolated events. Administrative login anomalies, rare egress, service instability, and application errors should be treated as supporting evidence unless paired with suspicious execution, file activity, privileged object changes, or abnormal management-server communication.
Asset Role as a Fidelity Multiplier
The same behavior carries higher risk when observed on an MDM or enterprise management server than on a standard endpoint. Rules should elevate activity based on the asset’s role as a trusted control-plane system.
Execution Context as a High-Value Anchor
Suspicious execution from a management application process, vendor service, Java process, Tomcat process, web-service process, application-server process, or management-platform service account should receive higher detection priority than generic administrator-initiated execution.
Baseline Dependency
Detection quality depends on baselines for administrator behavior, management-console activity, vendor communication paths, connector dependencies, directory-service communication, approved integrations, and normal management-server traffic patterns.
Conditional Signal Handling
Persistence, lateral movement, cloud-hosted infrastructure activity, crash telemetry, and application instability should be treated as conditional signals. They are valuable when paired with stronger indicators, but they should not be used as standalone proof of compromise.
Coverage Summary
The strongest detection coverage comes from environments that can correlate endpoint execution, administrative authentication, application activity, file activity, and network telemetry around tagged management-control-plane assets.
The highest-confidence detection opportunities are suspicious management-application child-process execution, unusual administrative access followed by abnormal server behavior, rare egress from management infrastructure, and privileged control-plane object changes followed by suspicious host or network activity.
The most significant detection gaps are missing process ancestry, incomplete command-line capture, limited application audit logging, weak asset-role tagging, insufficient administrative baselines, and poor visibility into management-server east-west communication.
S25 Ultra-Tuned Detection Engineering Rules
NDR / Network Behavioral Analytics
Detection Viability Assessment
NDR / Network Behavioral Analytics has three rules for this EXP report.
· NDR is viable for identifying anomalous network behavior from MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· NDR is strongest when management-control-plane assets are tagged and baseline visibility exists for expected vendor update paths, connector dependencies, identity services, directory-service communication, logging flows, monitoring systems, and approved administrative access sources.
· NDR is not intended to confirm the original exploit path, validate exploit payload delivery, or determine whether a specific CVE implementation was used.
· NDR is most valuable for identifying rare egress, abnormal east-west communication, staged transfer behavior, beacon-like activity, and suspicious network activity following administrative access or management-server behavior changes.
Rule 1
Management-Control Plane Administrative Access Followed by Rare Egress
Rule Format
NDR vendor-neutral detection pattern suitable for platform mapping after asset-role tagging, administrative-access validation, destination baselining, and environment-specific dependency tuning.
Detection Purpose
· Detect unusual administrative access to an MDM, EPMM, endpoint-management, security-management, or enterprise administration interface followed by rare or anomalous outbound communication from the management server.
· Identify management-control-plane behavior consistent with post-access staging, command-and-control preparation, unauthorized external communication, or adversary use of trusted infrastructure.
· Detect behavior without depending on CVE-specific request strings, exploit payloads, scanner names, attacker IP addresses, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or prove that the administrative session was unauthorized without supporting authentication, endpoint, application, file, or configuration-change evidence.
Detection Logic
· Identify administrative access to a tagged management-control-plane asset from an unusual source, account, geography, ASN, device, time window, or network location.
· Identify subsequent outbound communication from the same management server to a rare, newly observed, low-reputation, geographically unusual, or operationally inconsistent external destination.
· Prioritize events where rare egress follows administrative access, abnormal API activity, privileged object changes, suspicious process execution, file staging, service instability, or management-platform configuration changes.
· Treat the alert as higher confidence when the destination is not associated with known vendor update paths, connector dependencies, identity services, directory services, logging infrastructure, monitoring systems, approved integrations, or documented maintenance workflows.
· Do not classify the event as confirmed compromise without corroborating authentication, endpoint, application, file, or privileged configuration-change evidence.
Required Telemetry
· Management-control-plane asset inventory or asset-role tags.
· Administrative interface access telemetry from proxy, VPN, identity, application, or network sources.
· Source IP, source ASN, geography, user or account context where available.
· Network flow telemetry from management servers.
· DNS telemetry where available.
· Proxy telemetry where available.
· Destination IP, domain, ASN, port, protocol, and connection direction.
· Session timing and byte volume.
· Known vendor update destinations.
· Approved connector, identity, directory, logging, monitoring, backup, and integration destinations.
· Historical baseline for management-server outbound communication.
Engineering Implementation Instructions
· Scope the rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· Validate expected administrative access paths before deployment, including VPN, jump host, privileged access management, identity provider, reverse proxy, vendor-support, and approved administrative workflows.
· Establish baseline outbound destinations for vendor updates, connectors, identity services, directory services, logging systems, monitoring tools, certificate services, backups, and approved integrations.
· Tune destination-rarity logic to the organization’s management-server baseline rather than applying generic rarity thresholds across all servers.
· Increase severity when rare egress occurs after unusual administrative access, privileged object modification, suspicious endpoint execution, file staging, or application instability.
· Suppress known maintenance, patching, backup, monitoring, connector, vendor-support, and update workflows only when source, destination, timing, asset role, and change context are validated.
· Route alerts involving internet-exposed management servers or externally reachable administrative interfaces at higher priority.
· Use endpoint, application, authentication, and configuration-change telemetry as triage evidence rather than treating rare egress alone as confirmed compromise.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to management-server rare egress following suspicious administrative access rather than brittle exploit artifacts.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, payload formatting changes, or public proof-of-concept behavior varies.
· The score is supported by the rule’s focus on trusted management infrastructure communicating outside expected operational patterns.
· The score is constrained by legitimate vendor updates, connector behavior, support workflows, monitoring integrations, backup activity, and maintenance operations that may generate rare outbound destinations.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on asset-role tagging, administrative access visibility, destination baselining, DNS/proxy/flow telemetry, and known vendor or connector dependency mapping.
· Operational confidence is reduced where management-server baselines are weak, outbound destinations are poorly documented, or administrative access paths are not consistently logged.
· Full-telemetry confidence improves when NDR telemetry is enriched with authentication logs, application administrative activity, endpoint process telemetry, file activity, and privileged configuration-change records.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious management-server network behavior, not the original exploit request.
· Legitimate updates, connectors, monitoring systems, backup tools, cloud dependencies, support activity, and maintenance workflows may overlap with rare egress behavior.
· This rule requires asset-role tagging and destination baselining to remain reliable.
· Confirmation requires correlation with suspicious administrative access, endpoint execution, file activity, privileged object changes, service instability, or other compromise evidence.
Detection Query Pattern
NDR vendor-neutral detection pattern suitable for platform mapping. Field names and analytic operators must be mapped to the deployed NDR platform before production use.
MANAGEMENT_CONTROL_PLANE_ASSET
AND ADMINISTRATIVE_ACCESS_DEVIATION
AND OUTBOUND_CONNECTION_FROM_MANAGEMENT_SERVER
AND RARE_OR_UNUSUAL_EXTERNAL_DESTINATION
AND DESTINATION_NOT_IN_APPROVED_DEPENDENCY_BASELINE
AND ADMIN_ACCESS_TO_EGRESS_TIME_WINDOW_WITHIN_24_HOURS
Expanded vendor-neutral detection pattern:
AssetRole IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
AND AdministrativeAccessObserved = TRUE
AND AdministrativeAccessDeviation IN (
"New Source IP",
"New ASN",
"New Geography",
"New Device",
"Outside Administrative Window",
"Unusual Administrative Access Path"
)
AND OutboundConnectionObserved = TRUE
AND ExternalDestinationRarity IN (
"New For Asset",
"Rare For Asset",
"Rare For Management-Server Peer Group",
"Low Reputation",
"Unusual Geography",
"Unusual ASN"
)
AND DestinationBaselineCategory NOT IN (
"Approved Vendor Update",
"Approved Connector",
"Approved Identity Service",
"Approved Directory Service",
"Approved Logging",
"Approved Monitoring",
"Approved Backup",
"Approved Integration"
)
AND TimeWindow(
AdministrativeAccessObserved,
OutboundConnectionObserved
) <= 24 HOURS
Rule 2
Management Server Initiates Unexpected East-West or Dependency-Deviation Traffic
Rule Format
NDR vendor-neutral detection pattern suitable for platform mapping after management-server role tagging, internal dependency mapping, and baseline validation.
Detection Purpose
· Detect unexpected east-west communication from MDM, EPMM, endpoint-management, security-management, or enterprise administration servers.
· Identify possible post-exploitation discovery, lateral movement, connector abuse, unauthorized internal access, or adversary use of trusted management infrastructure.
· Detect suspicious internal network behavior without requiring endpoint process telemetry or exploit-payload visibility.
· This rule does not confirm compromise without supporting endpoint, authentication, application, file, or privileged configuration-change evidence.
Detection Logic
· Identify management servers initiating new or unusual connections to internal hosts, administrative services, file shares, databases, identity infrastructure, endpoints, or internal platforms outside the established dependency baseline.
· Prioritize communication involving administrative protocols, unusual ports, new internal destinations, uncommon timing, abnormal byte volume, repeated connection attempts, or directionality inconsistent with the management server’s role.
· Increase confidence when unexpected east-west communication follows suspicious administrative access, privileged object changes, application instability, file staging, endpoint execution alerts, or abnormal API activity.
· Treat communication to systems outside known MDM, identity, directory, database, connector, logging, update, monitoring, backup, and integration paths as higher risk.
· Do not classify communication as malicious without enrichment against approved architecture, maintenance activity, connector behavior, and known administrative workflows.
Required Telemetry
· Management-control-plane asset inventory or asset-role tags.
· Internal network flow telemetry.
· DNS telemetry where available.
· Proxy telemetry where applicable.
· Source and destination host identity.
· Destination host, IP, domain, port, and protocol.
· Connection direction and session timing.
· Byte volume and connection frequency.
· Known internal dependency map.
· Approved administrative, connector, update, logging, monitoring, backup, identity, directory, and database communication paths.
Engineering Implementation Instructions
· Scope the rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· Establish normal internal communication baselines for each management-server role.
· Include known dependencies such as identity providers, directory services, databases, logging systems, monitoring platforms, certificate services, connectors, backups, and approved integrations.
· Prioritize new internal destinations, administrative protocols, unexpected east-west communication, unusual internal service access, and repeated connection attempts outside the server’s baseline.
· Increase severity when unexpected east-west communication occurs near suspicious administrative access, endpoint execution alerts, file staging, application instability, or privileged configuration changes.
· Suppress expected maintenance, vulnerability scanning, backup, monitoring, support, connector, and administrative automation activity only when timing, source, destination, and operational context are validated.
· Use this rule as a post-access and internal expansion detector, not as a standalone exploit-confirmation mechanism.
DRI Assessment
DRI
7.5 / 10
· The rule is behaviorally anchored to abnormal east-west communication from high-trust management infrastructure.
· The rule remains useful across different exploit paths, payloads, attacker infrastructure, and management-platform vendors.
· The score is supported by the rule’s focus on internal communication that deviates from predictable management-server dependency patterns.
· The score is constrained by legitimate connector behavior, monitoring traffic, support activity, backup workflows, vulnerability scanning, administrative automation, and incomplete dependency mapping.
TCR Assessment
Operational TCR
6.5 / 10
Full-Telemetry TCR
8.0 / 10
· Operational confidence depends on east-west visibility, asset-role tagging, internal dependency mapping, management-server baselining, and administrative workflow context.
· Operational confidence is reduced where internal traffic is not monitored, management-server dependencies are poorly documented, or network telemetry lacks host identity.
· Full-telemetry confidence improves when NDR telemetry is correlated with endpoint process telemetry, administrative authentication logs, application logs, file activity, and privileged configuration changes.
· Even under full telemetry conditions, this rule should be treated as suspicious activity requiring investigation rather than confirmed compromise.
Limitations
· This rule detects abnormal internal communication from management infrastructure, not the initial exploitation event.
· Legitimate connectors, integrations, monitoring systems, backup tools, vulnerability scanners, support workflows, and administrative automation may overlap with this behavior.
· This rule requires asset-role tagging, dependency mapping, east-west visibility, and network baselining to remain reliable.
· Confirmation requires correlation with suspicious administrative access, endpoint execution, file activity, application instability, privileged object changes, or other supporting compromise evidence.
Detection Query Pattern
NDR vendor-neutral detection pattern suitable for platform mapping. Field names and analytic operators must be mapped to the deployed NDR platform before production use.
MANAGEMENT_CONTROL_PLANE_ASSET
AND INTERNAL_NETWORK_CONNECTION_FROM_MANAGEMENT_SERVER
AND NEW_OR_RARE_INTERNAL_DESTINATION
AND DESTINATION_NOT_IN_APPROVED_INTERNAL_DEPENDENCY_BASELINE
AND INTERNAL_COMMUNICATION_DEVIATION
AND SUPPORTING_CONTEXT_PRESENT
Expanded vendor-neutral detection pattern:
AssetRole IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
AND InternalNetworkConnectionObserved = TRUE
AND InternalDestinationDeviation IN (
"New Internal Destination",
"Rare Internal Destination For Asset",
"Rare Port For Asset",
"Rare Protocol For Asset",
"Unexpected Directionality",
"Unusual Session Timing",
"Abnormal Byte Volume",
"Repeated Failed Internal Connection Attempts"
)
AND InternalDestinationCategory NOT IN (
"Approved Identity Service",
"Approved Directory Service",
"Approved Database",
"Approved Logging",
"Approved Monitoring",
"Approved Backup",
"Approved Connector",
"Approved Integration"
)
AND (
AdministrativeAccessAnomalyObserved = TRUE
OR PrivilegedObjectChangeObserved = TRUE
OR EndpointExecutionAlertObserved = TRUE
OR FileStagingObserved = TRUE
OR ApplicationInstabilityObserved = TRUE
)
Rule 3
Ivanti Sentry Gateway Rare Egress or Backend Dependency Deviation
Rule Format
NDR vendor-neutral detection pattern suitable for platform mapping after Ivanti Sentry asset-role tagging, secure mobile gateway dependency baselining, approved-destination validation, supporting-context enrichment validation, and environment-specific network tuning.
Detection Purpose
· Detect rare outbound communication or unexpected backend dependency access from Ivanti Sentry or comparable secure mobile gateway appliances.
· Identify behavior consistent with post-exploitation staging, command-and-control preparation, backend dependency probing, connector misuse, or adversary use of trusted mobile gateway infrastructure.
· Extend the report’s management-control-plane network coverage to secure mobile gateway assets without depending on CVE-specific request strings, exploit payloads, scanner names, attacker IP addresses, or one Ivanti-specific exploit implementation.
· This rule does not confirm successful exploitation of CVE-2026-10520 without supporting appliance, application, authentication, file, process, network, or privileged configuration-change evidence.
Detection Logic
· Identify Ivanti Sentry or comparable secure mobile gateway appliances using asset-role tags, inventory data, CMDB records, network zones, hostname patterns, appliance management records, or security architecture ownership.
· Identify outbound communication from the gateway to rare, newly observed, low-reputation, geographically unusual, or operationally inconsistent external destinations.
· Identify internal communication from the gateway to backend systems outside approved mobile gateway, identity, directory, certificate, connector, logging, monitoring, update, application, or administrative dependency baselines.
· Prioritize events where rare egress or backend dependency deviation occurs near suspicious administrative access, abnormal gateway request activity, gateway service instability, suspicious file activity, unexpected shell or script execution, unexpected connector access, unexpected certificate or keystore access, or unexpected appliance configuration changes.
· Treat the alert as higher confidence when the destination is not associated with approved vendor update paths, mobile access flows, backend application paths, connector destinations, identity services, directory services, certificate infrastructure, logging destinations, monitoring systems, or documented maintenance workflows.
· Do not classify the event as confirmed compromise without corroborating appliance, endpoint, application, authentication, file, network, or configuration-change evidence.
Required Telemetry
· Ivanti Sentry or secure mobile gateway asset inventory.
· Asset-role tags for enterprise mobility gateway, secure mobile gateway, or mobile access control-plane infrastructure.
· Network flow telemetry from Sentry source IPs.
· DNS telemetry where available.
· Proxy telemetry where available.
· Firewall telemetry where available.
· NDR telemetry where available.
· Destination IP, domain, ASN, port, protocol, connection direction, session timing, and byte volume.
· Known vendor update destinations.
· Approved mobile access flows.
· Approved backend application paths.
· Approved connector, identity, directory, certificate, logging, monitoring, backup, and integration destinations.
· Historical baseline for Sentry gateway outbound and backend communication.
· Optional correlated supporting telemetry from SIEM, Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, application logs, authentication logs, file telemetry, process telemetry, certificate infrastructure logs, connector logs, or backend service logs when the detection pattern uses supporting-context gates beyond network behavior.
Engineering Implementation Instructions
· Scope the rule to Ivanti Sentry appliances and comparable secure mobile gateway assets tagged as enterprise mobility gateway, secure mobile gateway, or mobile access control-plane infrastructure.
· Build or validate a Sentry dependency baseline before alert-mode deployment, including vendor update paths, approved mobile access flows, backend application paths, connector destinations, identity services, directory services, certificate infrastructure, logging destinations, monitoring systems, backup destinations, and approved administrative paths.
· Tune destination-rarity logic to Sentry gateway behavior rather than applying generic server rarity thresholds.
· Validate supporting-context enrichment before using non-network gates such as suspicious administrative access, abnormal gateway requests, gateway service instability, suspicious file activity, unexpected shell or script execution, unexpected connector access, unexpected certificate or keystore access, unexpected appliance configuration changes, or new backend access.
· Increase severity when rare egress or backend dependency deviation occurs near suspicious administrative access, abnormal gateway request activity, service instability, suspicious file activity, unexpected shell or script execution, unexpected connector access, unexpected certificate or keystore access, or unexpected appliance configuration changes.
· Suppress known maintenance, patching, backup, monitoring, connector, vendor-support, certificate-renewal, and update workflows only when source, destination, timing, asset role, change ticket, and operational context are validated.
· Route alerts involving internet-facing or semi-trusted-reachable Sentry appliances at higher priority.
· Use Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, backend service logs, application telemetry, and host telemetry where available as triage evidence rather than treating network deviation alone as confirmed compromise.
· Keep the rule in hunt mode until Sentry asset tags, dependency baselines, approved-destination lookups, source IP mappings, supporting-context enrichment, and false-positive baselines are validated.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to rare egress and backend dependency deviation from high-trust secure mobile gateway infrastructure.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, payload formatting changes, or public proof-of-concept behavior varies.
· The score is supported by the durability of compromised gateway appliances communicating outside approved mobile access, update, connector, identity, directory, certificate, logging, or backend dependency paths.
· The score is constrained by legitimate mobile access flows, backend application relay behavior, connector synchronization, vendor updates, monitoring, backup, support workflows, and incomplete dependency baselines.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on Sentry asset-role tagging, source IP accuracy, network flow visibility, DNS/proxy/firewall/NDR telemetry, approved-destination baselines, backend dependency mapping, and validated supporting-context enrichment.
· Operational confidence is reduced where Sentry appliances are not clearly tagged, gateway traffic is not separated from other mobile access infrastructure, backend dependencies are poorly documented, or supporting-context gates are not backed by reliable telemetry.
· Full-telemetry confidence improves when NDR telemetry is enriched with Sentry appliance logs, syslog, reverse proxy logs, WAF logs, load balancer logs, backend service logs, authentication logs, application logs, file telemetry, and process telemetry where available.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious Sentry gateway network behavior, not the original exploit request.
· Legitimate mobile access flows, connector activity, vendor updates, backend application traffic, monitoring systems, backup tools, support workflows, and maintenance activity may overlap with rare egress or backend dependency deviation.
· This rule requires asset-role tagging, source IP mapping, approved-destination baselining, dependency mapping, and supporting-context enrichment validation to remain reliable.
· Confirmation requires correlation with suspicious administrative access, gateway service instability, suspicious execution, file activity, unexpected connector access, unexpected certificate or keystore access, unexpected appliance configuration changes, backend anomalies, or other supporting compromise evidence.
Detection Query Pattern
NDR vendor-neutral detection pattern suitable for platform mapping. Field names, asset-role logic, dependency lookups, destination-rarity operators, and supporting-context fields must be mapped to the deployed NDR, SIEM, or enrichment platform before production use.
SENTRY_OR_SECURE_MOBILE_GATEWAY_ASSET
AND NETWORK_CONNECTION_FROM_GATEWAY
AND (
RARE_OR_UNUSUAL_EXTERNAL_DESTINATION
OR NEW_OR_RARE_BACKEND_DESTINATION
OR DESTINATION_NOT_IN_APPROVED_GATEWAY_DEPENDENCY_BASELINE
)
AND (
SUSPICIOUS_ADMINISTRATIVE_ACCESS_OBSERVED
OR ABNORMAL_GATEWAY_REQUEST_OBSERVED
OR GATEWAY_SERVICE_INSTABILITY_OBSERVED
OR SUSPICIOUS_FILE_ACTIVITY_OBSERVED
OR SUSPICIOUS_EXECUTION_OBSERVED
OR UNEXPECTED_CONNECTOR_ACCESS_OBSERVED
OR UNEXPECTED_CERTIFICATE_OR_KEYSTORE_ACCESS_OBSERVED
OR UNEXPECTED_APPLIANCE_CONFIGURATION_CHANGE_OBSERVED
OR NEW_BACKEND_ACCESS_OBSERVED
)
AssetRole IN (
"Ivanti Sentry",
"Secure Mobile Gateway",
"Enterprise Mobility Gateway",
"Mobile Access Control-Plane Asset"
)
AND NetworkConnectionObserved = TRUE
AND GatewayDestinationDeviation IN (
"New External Destination For Gateway",
"Rare External Destination For Gateway",
"Low Reputation External Destination",
"Unusual Destination ASN",
"Unusual Destination Geography",
"New Backend Destination",
"Rare Backend Destination For Gateway",
"Unexpected Port For Gateway",
"Unexpected Protocol For Gateway",
"Unexpected Directionality",
"Abnormal Byte Volume",
"Repeated Failed Backend Connection Attempts"
)
AND DestinationBaselineCategory NOT IN (
"Approved Vendor Update",
"Approved Mobile Access Flow",
"Approved Backend Application",
"Approved Connector",
"Approved Identity Service",
"Approved Directory Service",
"Approved Certificate Service",
"Approved Logging",
"Approved Monitoring",
"Approved Backup",
"Approved Integration",
"Approved Administrative Path"
)
AND (
SuspiciousAdministrativeAccessObserved = TRUE
OR AbnormalGatewayRequestObserved = TRUE
OR GatewayServiceInstabilityObserved = TRUE
OR SuspiciousFileActivityObserved = TRUE
OR SuspiciousExecutionObserved = TRUE
OR UnexpectedConnectorAccessObserved = TRUE
OR UnexpectedCertificateOrKeystoreAccessObserved = TRUE
OR UnexpectedApplianceConfigurationChangeObserved = TRUE
OR NewBackendAccessObserved = TRUE
)
SentinelOne
Detection Viability Assessment
SentinelOne has two rules for this EXP report.
· SentinelOne is viable for detecting endpoint-level post-access behavior on MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· SentinelOne is strongest where process ancestry, command-line capture, file activity, user context, service-account context, and host-role tagging are available.
· SentinelOne is not a standalone source for confirming exploit success, administrative session validity, or the original vulnerability trigger without application, authentication, or network telemetry.
· SentinelOne is most valuable for identifying suspicious service-context execution, script or utility launch activity, file staging, persistence-relevant changes, and post-exploitation behavior from management infrastructure.
Rule 1
Management Application Service Spawns Shell or Administrative Tooling
Rule Format
SentinelOne Deep Visibility query pattern suitable for STAR-style alerting after tenant syntax validation, field validation, host-role tagging, and environment-specific process tuning.
Detection Purpose
· Detect suspicious process execution where MDM, EPMM, endpoint-management, security-management, or enterprise administration service processes spawn shells, scripting engines, network utilities, archive tools, credential-access utilities, service-control commands, or persistence-related tooling.
· Identify post-access endpoint behavior that may follow exploitation or administrative-control-plane abuse without depending on CVE strings, exploit payloads, scanner names, attacker infrastructure, or one vendor-specific exploit implementation.
· Prioritize suspicious execution from management application context because trusted management services should not normally initiate interactive shell, scripting, staging, or persistence workflows.
· This rule does not confirm successful exploitation or prove that the administrative session was unauthorized without supporting authentication, application, file, network, or configuration-change evidence.
Detection Logic
· Identify process creation on tagged MDM, EPMM, endpoint-management, security-management, or enterprise administration servers.
· Identify source or parent processes associated with management application services, Java, Tomcat, web-service processes, vendor services, application-server processes, or management-platform service accounts.
· Prioritize child processes associated with shell execution, scripting, outbound retrieval, archive staging, service control, credential access, account manipulation, or persistence mechanisms.
· Treat the alert as higher confidence when activity follows unusual administrative access, abnormal API activity, privileged object changes, rare egress, file staging, service instability, or management-platform configuration changes.
· Suppress expected maintenance, patching, backup, monitoring, vendor-support, connector, and administrative automation workflows only when process lineage, command line, execution user, host role, and time window are validated.
· Do not classify the activity as confirmed compromise without corroborating authentication, application, file, outbound communication, or privileged configuration-change evidence.
Required Telemetry
· SentinelOne process creation telemetry.
· Process ancestry.
· Command-line capture.
· Source process and target process names.
· Source process and target process paths.
· Source user and effective user context where available.
· Service-account context where available.
· Host identity.
· Host role or asset tag.
· Endpoint operating system.
· Timestamp.
· Process-to-network connection mapping where available.
Engineering Implementation Instructions
· Validate SentinelOne tenant syntax and tenant field names for endpoint operating system, event type, source process, target process, command line, user, process path, parent process, host identity, and timestamp before deployment.
· Scope the rule to servers tagged as MDM, EPMM, endpoint-management, security-management, or enterprise administration systems.
· Tune source process names and service paths to the organization’s actual management-platform stack.
· Include common management-service parent contexts such as Java, Tomcat, web-service processes, application-server processes, vendor services, and platform-specific management daemons where present.
· Add allowlists for approved patching, vendor updates, backups, monitoring, support activity, connector workflows, vulnerability management, and administrative automation.
· Treat internet-exposed management-server status, unusual administrative access, privileged object changes, rare egress, file staging, or application instability as prioritization context.
· Use authentication, application, file, and network telemetry as triage evidence rather than assuming service-context execution alone equals compromise.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious service-context execution rather than brittle exploit artifacts.
· The rule remains useful if exploit delivery changes, public proof-of-concept behavior varies, attacker infrastructure rotates, or payload formatting changes.
· The score is supported by the durability of management application services spawning shells, interpreters, network utilities, archive tools, credential utilities, or persistence mechanisms as a post-access behavior.
· The score is constrained by overlap with legitimate maintenance, vendor-support, patching, monitoring, backup, connector, and administrative automation workflows.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on process ancestry fidelity, command-line capture, service-account context, host-role tagging, endpoint coverage, and maintenance baseline quality.
· Operational confidence is reduced where management-server processes are poorly baselined, command-line capture is inconsistent, or approved administrative automation overlaps with suspicious tooling.
· Full-telemetry confidence improves when SentinelOne telemetry is enriched with administrative authentication logs, application activity, file activity, rare egress, privileged object changes, and asset exposure context.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious post-access execution behavior, not the original exploit request.
· Legitimate patching, vendor updates, backups, monitoring, vulnerability management, connector workflows, support activity, and administrative automation may overlap with this behavior.
· This rule requires process ancestry, command-line visibility, endpoint coverage, and host-role scoping to remain reliable.
· Confirmation requires correlation with suspicious administrative access, application activity, file activity, outbound communication, privileged object changes, service instability, or other compromise evidence.
Detection Query Pattern
SentinelOne Deep Visibility query pattern requiring tenant syntax and field validation before production deployment.
EndpointOS IN ("windows", "linux")
AND EventType = "Process Creation"
AND AgentComputerName IN ASSET_GROUP (
"MDM Servers",
"EPMM Servers",
"Endpoint Management Servers",
"Security Management Servers",
"Enterprise Management Servers"
)
AND SrcProcName IN ANY (
"java",
"java.exe",
"tomcat",
"tomcat.exe",
"catalina",
"catalina.sh",
"httpd",
"apache2",
"nginx",
"w3wp.exe",
"vendor-management-service",
"mdm-service",
"epmm-service",
"management-service"
)
AND TgtProcName IN ANY (
"cmd.exe",
"powershell.exe",
"pwsh.exe",
"wscript.exe",
"cscript.exe",
"mshta.exe",
"rundll32.exe",
"regsvr32.exe",
"wmic.exe",
"bitsadmin.exe",
"certutil.exe",
"curl.exe",
"wget.exe",
"bash",
"sh",
"dash",
"zsh",
"python",
"python3",
"perl",
"php",
"curl",
"wget",
"nc",
"ncat",
"socat",
"tar",
"zip",
"gzip",
"openssl",
"systemctl",
"service",
"crontab",
"schtasks.exe",
"sc.exe",
"net.exe",
"net1.exe"
)
AND NOT TgtProcCmdLine CONTAINS ANY (
"approved_vendor_update",
"approved_patch_workflow",
"approved_backup_workflow",
"approved_monitoring_workflow",
"approved_connector_workflow",
"approved_support_workflow"
)
Rule 2
Suspicious File, Script, or Persistence Activity from Management Service Context
Rule Format
SentinelOne Deep Visibility query pattern suitable for STAR-style alerting after tenant syntax validation, field validation, host-role tagging, platform path validation, and environment-specific path tuning.
Detection Purpose
· Detect suspicious file creation, script staging, archive creation, web-accessible file writes, service modification, scheduled-task creation, startup modification, or persistence-relevant activity from management application, vendor service, application-server, web-service, shell, or interpreter context.
· Identify post-access file and persistence behavior that may follow exploitation or management-plane abuse without depending on static malware signatures, CVE strings, public proof-of-concept payloads, attacker IP addresses, or one exploit implementation.
· Prioritize file activity initiated by management-platform service context because management servers are high-trust systems with privileged operational reach.
· This rule does not prove that a file is malicious without supporting execution, access, persistence, network, application, or configuration-change context.
Detection Logic
· Identify file creation, file modification, or file attribute changes on tagged MDM, EPMM, endpoint-management, security-management, or enterprise administration servers.
· Prioritize activity initiated by management application services, Java, Tomcat, web-service processes, application-server processes, vendor services, shells, scripting engines, or service accounts.
· Prioritize file activity affecting application deployment directories, upload paths, plugin or extension paths, temporary staging directories, web-accessible paths, scheduled-task locations, startup locations, cron paths, service directories, or sensitive configuration paths.
· Increase confidence when file activity involves scripts, archives, encoded content, suspicious extensions, executable content, web-accessible files, persistence locations, or sensitive credential/token material.
· Treat the alert as higher confidence when file activity follows unusual administrative access, privileged object changes, suspicious process execution, rare egress, or application instability.
· Do not classify the activity as confirmed compromise without corroborating execution, unauthorized access, persistence, outbound communication, privileged object changes, or other compromise evidence.
Required Telemetry
· SentinelOne file creation, file modification, or file attribute telemetry where available.
· Process ancestry for the modifying process.
· Command-line capture where available.
· Source process and source process path.
· Target file path.
· File extension where available.
· File hash where available.
· File owner and permissions where available.
· Source user and effective user context where available.
· Service-account context where available.
· Host role or asset tag.
· Timestamp.
Engineering Implementation Instructions
· Validate SentinelOne tenant syntax and tenant field names for file event type, file path, source process, command line, user, host identity, and timestamp before deployment.
· Scope the rule to servers tagged as MDM, EPMM, endpoint-management, security-management, or enterprise administration systems.
· Validate local application deployment directories, upload paths, plugin paths, extension paths, web-accessible paths, temporary staging directories, service paths, scheduled-task paths, startup paths, cron paths, and sensitive configuration locations before deployment.
· Tune source process names and monitored paths to the organization’s actual management-platform stack and operating system.
· Add allowlists for approved patching, vendor updates, backups, monitoring, support activity, certificate renewal, connector workflows, vulnerability management, and administrative automation.
· Treat file activity from management service context as higher priority when paired with unusual administrative access, suspicious execution, privileged object changes, rare egress, or service instability.
· Use authentication, application, endpoint execution, and network telemetry as triage evidence rather than assuming file activity alone equals compromise.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to suspicious file, script, and persistence-relevant activity from management service context rather than static malware matching.
· The rule remains useful if attackers rename files, change extensions, alter payload content, rotate tooling, or rely on legitimate service context.
· The score is supported by the durability of script staging, archive creation, web-accessible writes, service modification, scheduled-task creation, and persistence-relevant activity as post-access behaviors.
· The score is constrained by overlap with legitimate patching, updates, backups, monitoring, support activity, certificate renewal, connector workflows, and administrative automation.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on file-event visibility, process ancestry fidelity, command-line capture, service-account context, host-role tagging, path awareness, and maintenance baseline quality.
· Operational confidence is reduced where file telemetry is incomplete, management application paths are poorly documented, or approved operational workflows create frequent file changes.
· Full-telemetry confidence improves when SentinelOne telemetry is enriched with administrative authentication logs, application activity, suspicious process execution, rare egress, privileged object changes, and service instability.
· Even under full telemetry conditions, suspicious file activity requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious file, script, or persistence-relevant activity, not the original exploit event.
· Legitimate patching, vendor updates, backups, monitoring, certificate renewal, support workflows, connector activity, and administrative automation may overlap with this behavior.
· This rule requires file telemetry, process lineage, path awareness, endpoint coverage, and host-role scoping to remain reliable.
· Confirmation requires correlation with suspicious administrative access, suspicious execution, outbound communication, privileged object changes, persistence evidence, service instability, or other supporting compromise evidence.
Detection Query Pattern
SentinelOne Deep Visibility query pattern requiring tenant syntax and field validation before production deployment.
EndpointOS IN ("windows", "linux")
AND EventType IN ANY (
"File Creation",
"File Modification",
"File Attribute Change"
)
AND AgentComputerName IN ASSET_GROUP (
"MDM Servers",
"EPMM Servers",
"Endpoint Management Servers",
"Security Management Servers",
"Enterprise Management Servers"
)
AND SrcProcName IN ANY (
"java",
"java.exe",
"tomcat",
"tomcat.exe",
"catalina",
"catalina.sh",
"httpd",
"apache2",
"nginx",
"w3wp.exe",
"vendor-management-service",
"mdm-service",
"epmm-service",
"management-service",
"cmd.exe",
"powershell.exe",
"pwsh.exe",
"bash",
"sh",
"python",
"python3",
"perl",
"php"
)
AND TgtFilePath CONTAINS ANY (
"\\inetpub\\wwwroot\\",
"\\ProgramData\\Vendor\\",
"\\Program Files\\Vendor\\",
"\\Temp\\",
"\\Windows\\Temp\\",
"\\System32\\Tasks\\",
"\\Startup\\",
"/opt/vendor/",
"/var/lib/vendor/",
"/var/log/vendor/",
"/tmp/",
"/var/tmp/",
"/dev/shm/",
"/etc/cron",
"/var/spool/cron",
"/etc/systemd/",
"/usr/local/vendor/",
"/webapps/",
"/uploads/",
"/plugins/",
"/extensions/"
)
AND (
TgtFilePath ENDSWITH ANY (
".ps1",
".bat",
".cmd",
".vbs",
".js",
".jsp",
".jspx",
".war",
".jar",
".sh",
".py",
".pl",
".php",
".phtml",
".cgi",
".zip",
".tar",
".gz",
".7z"
)
OR TgtFilePath CONTAINS ANY (
"\\Startup\\",
"\\System32\\Tasks\\",
"\\Temp\\",
"/tmp/",
"/var/tmp/",
"/dev/shm/",
"/cron",
"/systemd/",
"/uploads/",
"/plugins/",
"/extensions/",
"/webapps/"
)
)
AND NOT SrcProcCmdLine CONTAINS ANY (
"approved_vendor_update",
"approved_patch_workflow",
"approved_backup_workflow",
"approved_monitoring_workflow",
"approved_connector_workflow",
"approved_support_workflow",
"approved_certificate_renewal"
)
Splunk
Detection Viability Assessment
Splunk has three rules for this EXP report.
· Splunk is viable for correlating administrative access, application activity, endpoint process execution, file activity, network telemetry, and privileged configuration changes associated with MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· Splunk is strongest where management-control-plane assets are tagged, identity and application logs are available, endpoint telemetry is ingested, and network events can be correlated to host role.
· Splunk is not a standalone source for confirming exploit success unless the required authentication, application, endpoint, and network evidence is available and correlated.
· Splunk is most valuable for identifying chained behavior: unusual administrative access followed by suspicious server-side execution, privileged control-plane changes, file activity, rare egress, or unexpected east-west communication.
Rule 1
Unusual Management Console Access Followed by Suspicious Server-Side Execution
Rule Format
Splunk SPL correlation pattern suitable for Enterprise Security, correlation searches, or scheduled alerting after index, sourcetype, CIM, macro, lookup, asset, and derived-field validation.
The SPL below uses environment-specific macros, lookups, and derived fields. These must be mapped to the organization’s indexes, sourcetypes, CIM fields, asset inventory, and enrichment model before production deployment.
Detection Purpose
· Detect unusual administrative access to an MDM, EPMM, endpoint-management, security-management, or enterprise administration console followed by suspicious process execution on the associated management server.
· Identify behavior consistent with post-access execution, management-plane abuse, or exploitation-driven server-side activity.
· Detect the behavior without depending on CVE strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized session use without supporting application, endpoint, file, network, or privileged configuration-change evidence.
Detection Logic
· Identify successful administrative access to a tagged management-control-plane asset from an unusual source, account, device, geography, ASN, access path, or time window.
· Correlate the access event with suspicious process execution on the same management server within a defined investigation window.
· Prioritize execution where management application services, Java, Tomcat, web-service processes, application-server processes, vendor services, or service accounts spawn shells, scripting engines, network utilities, archive tools, credential-access utilities, service-control commands, or persistence-related tooling.
· Increase confidence when suspicious execution is accompanied by rare egress, file staging, privileged object changes, abnormal API activity, service instability, or application errors.
· Suppress expected maintenance, patching, backup, monitoring, support, connector, and administrative automation workflows only when account, source, process lineage, command line, asset role, and time window are validated.
· Do not classify the activity as confirmed compromise without corroborating application, endpoint, file, outbound communication, or privileged configuration-change evidence.
Required Telemetry
· Splunk-ingested administrative authentication logs.
· Application or API activity logs where available.
· Endpoint process creation telemetry.
· Process ancestry.
· Command-line capture.
· User and service-account context.
· Host identity and asset-role tags.
· Source IP, source user, access path, and session source.
· Network, DNS, proxy, or NDR telemetry where available.
· Timestamp normalization across sources.
· Management-server exposure or asset criticality context where available.
Engineering Implementation Instructions
· Validate Splunk indexes, sourcetypes, field names, CIM mappings, macros, derived fields, and asset lookups before deployment.
· Scope the rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Define administrative-access deviation fields as derived enrichment flags rather than assuming they exist natively.
· Define suspicious-process fields as derived enrichment flags based on parent process, child process, command line, user context, host role, and known maintenance workflows.
· Validate administrative access sources, including VPN, privileged access management, jump hosts, identity providers, reverse proxies, vendor-support paths, and approved administrative workflows.
· Tune suspicious parent and child process lists to the organization’s actual management-platform stack and operating systems.
· Tune the correlation window to the organization’s logging latency and operational patterns.
· Add allowlists for approved patching, backup, monitoring, connector, support, vulnerability management, and administrative automation workflows.
· Prefer stats-based or datamodel-backed correlation over join-based SPL for production scalability.
· Use application, file, network, and privileged-object telemetry as triage evidence rather than assuming administrative access followed by execution is confirmed compromise.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to unusual management-console access followed by suspicious server-side execution.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, public proof-of-concept behavior varies, or payload formatting changes.
· The score is supported by the durability of administrative access followed by management-service execution as a high-value post-access behavior.
· The score is constrained by legitimate maintenance, patching, support workflows, monitoring activity, connector operations, vulnerability management, and administrative automation that may overlap with the behavior.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on administrative authentication visibility, endpoint process telemetry, process ancestry, command-line capture, host-role tagging, derived-field quality, and timestamp normalization.
· Operational confidence is reduced where application logs are incomplete, command-line capture is inconsistent, administrative access paths are poorly baselined, or enrichment flags are not maintained.
· Full-telemetry confidence improves when Splunk correlates authentication, application activity, endpoint process execution, file activity, rare egress, and privileged object changes.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious access-to-execution behavior, not the original exploit request.
· Legitimate maintenance, patching, backup, monitoring, support, connector, vulnerability management, and administrative automation workflows may overlap with this behavior.
· This rule requires consistent timestamps, normalized fields, endpoint telemetry, derived enrichment flags, and asset-role tagging to remain reliable.
· Confirmation requires correlation with suspicious application activity, file activity, outbound communication, privileged object changes, service instability, or other compromise evidence.
Detection Query Pattern
Splunk SPL correlation pattern requiring index, sourcetype, CIM, macro, lookup, and derived-field validation before production deployment.
The macros in this pattern are placeholders for normalized event streams:
· management_admin_authentication should return management-console authentication and administrative access events.
· endpoint_process_creation should return endpoint process creation events from management servers.
· management_control_plane_assets should map host identity to asset role, exposure status, and management-platform type.
Derived fields such as admin_access_deviation and suspicious_process_execution must be created from local baselines, enrichment lookups, and field normalization before deployment.
(
`management_admin_authentication`
| lookup management_control_plane_assets host AS dest OUTPUT asset_role, exposure_status, platform_type
| where asset_role IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
| where action="success"
| eval admin_access_deviation=if(
is_new_source=1 OR is_new_geo=1 OR is_new_asn=1 OR is_new_device=1 OR outside_admin_window=1 OR unusual_access_path=1,
1,
0
)
| where admin_access_deviation=1
| eval event_stage="admin_access"
| rename _time AS event_time, src AS admin_src, user AS admin_user, dest AS mgmt_host
| table event_time, event_stage, mgmt_host, asset_role, exposure_status, platform_type, admin_user, admin_src, admin_access_deviation
)
| append [
search `endpoint_process_creation`
| lookup management_control_plane_assets host AS dest OUTPUT asset_role, exposure_status, platform_type
| where asset_role IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
| eval suspicious_parent=if(
parent_process IN (
"java","java.exe","tomcat","tomcat.exe","catalina","catalina.sh",
"httpd","apache2","nginx","w3wp.exe",
"vendor-management-service","mdm-service","epmm-service","management-service"
),
1,
0
)
| eval suspicious_child=if(
process_name IN (
"cmd.exe","powershell.exe","pwsh.exe","wscript.exe","cscript.exe",
"mshta.exe","rundll32.exe","regsvr32.exe","wmic.exe","bitsadmin.exe",
"certutil.exe","curl.exe","wget.exe","bash","sh","dash","zsh",
"python","python3","perl","php","nc","ncat","socat",
"tar","zip","gzip","openssl","systemctl","service","crontab",
"schtasks.exe","sc.exe","net.exe","net1.exe"
),
1,
0
)
| eval approved_workflow=if(
like(command_line,"%approved_vendor_update%")
OR like(command_line,"%approved_patch_workflow%")
OR like(command_line,"%approved_backup_workflow%")
OR like(command_line,"%approved_monitoring_workflow%")
OR like(command_line,"%approved_connector_workflow%")
OR like(command_line,"%approved_support_workflow%"),
1,
0
)
| eval suspicious_process_execution=if(suspicious_parent=1 AND suspicious_child=1 AND approved_workflow=0,1,0)
| where suspicious_process_execution=1
| eval event_stage="suspicious_execution"
| rename _time AS event_time, dest AS mgmt_host, user AS process_user
| table event_time, event_stage, mgmt_host, asset_role, exposure_status, platform_type, parent_process, process_name, command_line, process_user, suspicious_process_execution
]
| stats
min(eval(if(event_stage="admin_access", event_time, null()))) AS first_admin_time
values(eval(if(event_stage="admin_access", admin_user, null()))) AS admin_user
values(eval(if(event_stage="admin_access", admin_src, null()))) AS admin_src
values(eval(if(event_stage="admin_access", admin_access_deviation, null()))) AS admin_access_deviation
min(eval(if(event_stage="suspicious_execution", event_time, null()))) AS first_process_time
values(eval(if(event_stage="suspicious_execution", parent_process, null()))) AS parent_process
values(eval(if(event_stage="suspicious_execution", process_name, null()))) AS process_name
values(eval(if(event_stage="suspicious_execution", command_line, null()))) AS command_line
values(eval(if(event_stage="suspicious_execution", process_user, null()))) AS process_user
values(asset_role) AS asset_role
values(exposure_status) AS exposure_status
values(platform_type) AS platform_type
BY mgmt_host
| where isnotnull(first_admin_time)
AND isnotnull(first_process_time)
AND first_process_time >= first_admin_time
AND first_process_time <= relative_time(first_admin_time, "+24h")
| eval detection_reason="Unusual management console access followed by suspicious server-side execution"
| table first_admin_time, first_process_time, mgmt_host, asset_role, exposure_status, platform_type, admin_user, admin_src, parent_process, process_name, command_line, process_user, detection_reason
Rule 2
Privileged Management-Plane Object Change Followed by Abnormal Host or Network Behavior
Rule Format
Splunk SPL correlation pattern suitable for Enterprise Security, correlation searches, or scheduled alerting after index, sourcetype, CIM, macro, lookup, asset, and derived-field validation.
The SPL below uses environment-specific macros, lookups, and derived fields. These must be mapped to the organization’s indexes, sourcetypes, CIM fields, asset inventory, application audit model, and enrichment model before production deployment.
Detection Purpose
· Detect privileged management-plane object changes followed by suspicious host or network behavior from the associated management server.
· Identify behavior consistent with unauthorized control-plane modification, administrative abuse, post-exploitation staging, or adversary use of legitimate management-platform authority.
· Detect the behavior without relying on CVE strings, exploit payloads, static indicators, scanner names, attacker infrastructure, or one vendor-specific exploit path.
· This rule does not prove that the object change was malicious without supporting authentication, application, endpoint, file, or network evidence.
Detection Logic
· Identify creation, modification, or abnormal use of administrator accounts, roles, certificates, connectors, enrollment profiles, API tokens, device-management profiles, policies, integrations, or management-platform configuration objects.
· Correlate the privileged object change with suspicious endpoint process execution, file activity, rare egress, unexpected east-west communication, service instability, or abnormal API behavior on the same management server.
· Prioritize changes performed by unusual accounts, from unusual sources, outside administrative windows, or near suspicious endpoint or network activity.
· Increase confidence when object changes affect administrative authority, device control, connector reach, certificates, tokens, or downstream policy influence.
· Suppress approved maintenance, policy rollout, certificate rotation, connector updates, vendor-support, backup, migration, and administrative automation only when account, source, object type, change window, and operational context are validated.
· Do not classify the activity as confirmed compromise without corroborating unauthorized access, suspicious execution, rare egress, persistence, lateral movement, or downstream device impact.
Required Telemetry
· Splunk-ingested application or API activity logs.
· Administrative audit logs.
· Object-change records for accounts, roles, certificates, connectors, tokens, profiles, policies, and integrations.
· Endpoint process telemetry from management servers.
· File activity telemetry where available.
· Network, DNS, proxy, or NDR telemetry where available.
· User, source, object type, action, and timestamp context.
· Host identity and asset-role tags.
· Administrative baseline and maintenance-window context.
· Timestamp normalization across sources.
Engineering Implementation Instructions
· Validate Splunk indexes, sourcetypes, field names, CIM mappings, macros, derived fields, application audit fields, and asset lookups before deployment.
· Scope the rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Define privileged management-plane object types for the deployed platform, including administrative users, roles, certificates, connectors, tokens, enrollment profiles, policies, integrations, and platform configuration objects.
· Define abnormal-behavior fields as derived enrichment flags from normalized endpoint, file, network, application, and service-instability telemetry.
· Tune suspicious object-change logic to approved administrative workflows, maintenance windows, certificate rotations, connector updates, policy rollouts, and vendor-support activity.
· Correlate object changes with endpoint process execution, file activity, rare egress, unexpected east-west communication, service instability, or abnormal API behavior.
· Increase severity when the object change is performed by an unusual account, originates from an unusual source, affects administrative authority, or is followed by suspicious host or network behavior.
· Prefer stats-based or datamodel-backed correlation over join-based SPL for production scalability.
· Use endpoint, authentication, network, and downstream device-management telemetry as triage evidence rather than assuming the object change alone proves compromise.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to privileged control-plane changes followed by abnormal host or network behavior.
· The rule remains useful if exploit mechanics change, attackers use legitimate administrative workflows, or indicators rotate.
· The score is supported by the durability of administrator, role, certificate, connector, token, policy, profile, and integration changes as meaningful control-plane events.
· The score is constrained by overlap with legitimate administration, policy rollout, connector maintenance, certificate rotation, support activity, and automation workflows.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on application audit logging, object-change visibility, host-role tagging, endpoint telemetry, network telemetry, administrative baselines, derived-field quality, and timestamp normalization.
· Operational confidence is reduced where application logs are incomplete, privileged object changes are not well categorized, routine administration is poorly baselined, or abnormal-behavior enrichment flags are not maintained.
· Full-telemetry confidence improves when Splunk correlates object-change activity with authentication, endpoint process telemetry, file activity, rare egress, east-west communication, service instability, and downstream device impact.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious control-plane modification followed by abnormal behavior, not the initial exploitation event.
· Legitimate administrative changes, connector updates, policy rollouts, certificate rotation, support workflows, and automation may overlap with this behavior.
· This rule requires application audit visibility, object-change normalization, endpoint telemetry, network context, derived enrichment fields, and asset-role tagging to remain reliable.
· Confirmation requires correlation with suspicious access, suspicious execution, file activity, outbound communication, persistence, lateral movement, or downstream device impact.
Detection Query Pattern
Splunk SPL correlation pattern requiring index, sourcetype, CIM, macro, lookup, and derived-field validation before production deployment.
The macros in this pattern are placeholders for normalized event streams:
· management_platform_object_changes should return management-platform object-change events.
· management_server_abnormal_behavior should return normalized abnormal host, file, network, application, and service-instability events for management servers.
· management_control_plane_assets should map host identity to asset role, exposure status, and management-platform type.
Derived fields such as object_change_deviation and abnormal_behavior must be created from local baselines, application audit data, enrichment lookups, and field normalization before deployment.
(
`management_platform_object_changes`
| lookup management_control_plane_assets host AS dest OUTPUT asset_role, exposure_status, platform_type
| where asset_role IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
| where action IN ("created","modified","enabled","disabled","rotated","updated")
| where object_type IN (
"administrator_account",
"admin_role",
"certificate",
"connector",
"enrollment_profile",
"api_token",
"device_management_profile",
"policy",
"integration",
"platform_configuration"
)
| eval object_change_deviation=if(
is_unusual_user=1 OR is_unusual_source=1 OR outside_change_window=1 OR sensitive_object=1,
1,
0
)
| where object_change_deviation=1
| eval event_stage="object_change"
| rename _time AS event_time, user AS change_user, src AS change_src, dest AS mgmt_host
| table event_time, event_stage, mgmt_host, asset_role, exposure_status, platform_type, change_user, change_src, object_type, object_name, action, object_change_deviation
)
| append [
search `management_server_abnormal_behavior`
| lookup management_control_plane_assets host AS dest OUTPUT asset_role, exposure_status, platform_type
| where asset_role IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
| eval abnormal_behavior=if(
suspicious_process=1 OR suspicious_file_activity=1 OR rare_egress=1 OR unexpected_east_west=1 OR application_instability=1 OR abnormal_api_activity=1,
1,
0
)
| where abnormal_behavior=1
| eval event_stage="abnormal_behavior"
| rename _time AS event_time, dest AS mgmt_host
| table event_time, event_stage, mgmt_host, asset_role, exposure_status, platform_type, suspicious_process, suspicious_file_activity, rare_egress, unexpected_east_west, application_instability, abnormal_api_activity, abnormal_behavior
]
| stats
min(eval(if(event_stage="object_change", event_time, null()))) AS first_change_time
values(eval(if(event_stage="object_change", change_user, null()))) AS change_user
values(eval(if(event_stage="object_change", change_src, null()))) AS change_src
values(eval(if(event_stage="object_change", object_type, null()))) AS object_type
values(eval(if(event_stage="object_change", object_name, null()))) AS object_name
values(eval(if(event_stage="object_change", action, null()))) AS action
values(eval(if(event_stage="object_change", object_change_deviation, null()))) AS object_change_deviation
min(eval(if(event_stage="abnormal_behavior", event_time, null()))) AS first_behavior_time
values(eval(if(event_stage="abnormal_behavior", suspicious_process, null()))) AS suspicious_process
values(eval(if(event_stage="abnormal_behavior", suspicious_file_activity, null()))) AS suspicious_file_activity
values(eval(if(event_stage="abnormal_behavior", rare_egress, null()))) AS rare_egress
values(eval(if(event_stage="abnormal_behavior", unexpected_east_west, null()))) AS unexpected_east_west
values(eval(if(event_stage="abnormal_behavior", application_instability, null()))) AS application_instability
values(eval(if(event_stage="abnormal_behavior", abnormal_api_activity, null()))) AS abnormal_api_activity
values(asset_role) AS asset_role
values(exposure_status) AS exposure_status
values(platform_type) AS platform_type
BY mgmt_host
| where isnotnull(first_change_time)
AND isnotnull(first_behavior_time)
AND first_behavior_time >= first_change_time
AND first_behavior_time <= relative_time(first_change_time, "+24h")
| eval detection_reason="Privileged management-plane object change followed by abnormal host or network behavior"
| table first_change_time, first_behavior_time, mgmt_host, asset_role, exposure_status, platform_type, change_user, change_src, object_type, object_name, action, suspicious_process, suspicious_file_activity, rare_egress, unexpected_east_west, application_instability, abnormal_api_activity, detection_reason
Rule 3
Rule Format
Splunk SPL correlation pattern suitable for Enterprise Security, correlation searches, or scheduled alerting after index, sourcetype, CIM, macro, lookup, asset, Sentry telemetry, network telemetry, and derived-field validation.
Detection Purpose
· Detect Ivanti Sentry or comparable secure mobile gateway activity followed by rare outbound communication, unexpected backend dependency access, or suspicious gateway behavior.
· Identify behavior consistent with post-exploitation staging, command-and-control preparation, backend dependency probing, connector misuse, certificate or keystore access, appliance misuse, or adversary use of trusted mobile gateway infrastructure.
· Extend the report’s SIEM correlation coverage to secure mobile gateway assets without depending on CVE-specific request strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one Ivanti-specific exploit implementation.
· This rule does not confirm successful exploitation of CVE-2026-10520 without supporting appliance, application, authentication, file, process, network, or privileged configuration-change evidence.
Detection Logic
· Identify Ivanti Sentry or comparable secure mobile gateway assets using asset-role tags, CMDB records, host inventory, network zones, hostname patterns, platform ownership, source IP mappings, or gateway appliance records.
· Identify gateway-relevant activity from Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, authentication logs, application logs, endpoint telemetry, or network telemetry where available.
· Identify rare outbound communication from the Sentry appliance to newly observed, low-reputation, geographically unusual, operationally inconsistent, or non-baseline external destinations.
· Identify internal communication from the Sentry appliance to backend systems outside approved mobile gateway, identity, directory, certificate, connector, logging, monitoring, update, application, or administrative dependency baselines.
· Prioritize events where rare egress or backend dependency deviation occurs near suspicious administrative access, abnormal gateway request activity, gateway service instability, suspicious file activity, unexpected shell or script execution, unexpected connector access, unexpected certificate or keystore access, unexpected appliance configuration changes, or new backend access.
· Increase severity when the affected Sentry appliance was internet-facing, reachable from semi-trusted access paths, recently patched, associated with CVE-2026-10520 exposure, or missing complete appliance-level telemetry.
· Suppress approved maintenance, patching, backup, monitoring, connector, vendor-support, certificate-renewal, and update workflows only when account, source, destination, timing, asset role, change ticket, and operational context are validated.
· Do not classify the event as confirmed compromise without corroborating Sentry logs, authentication evidence, application telemetry, file activity, process telemetry, network telemetry, backend service evidence, or configuration-change evidence.
Required Telemetry
· Splunk-ingested Sentry appliance logs where available.
· Syslog-forwarded Sentry events where available.
· Reverse proxy, WAF, load balancer, or ingress logs in front of Sentry where available.
· Network flow, DNS, proxy, firewall, or NDR telemetry for Sentry source IPs.
· Authentication logs for administrative access to Sentry or related management infrastructure.
· Backend service logs for identity, directory, certificate, connector, application, administrative, or mobile access dependencies reachable through Sentry.
· Endpoint, process, file, or Linux audit telemetry where available.
· Asset-role tags for Ivanti Sentry, secure mobile gateway, enterprise mobility gateway, or mobile access control-plane infrastructure.
· Source IP, destination IP, domain, ASN, port, protocol, connection direction, session timing, and byte volume.
· Approved vendor update destinations.
· Approved mobile access flows.
· Approved backend application paths.
· Approved connector, identity, directory, certificate, logging, monitoring, backup, and integration destinations.
· Historical baseline for Sentry gateway outbound and backend communication.
· Timestamp normalization across Sentry, authentication, application, proxy, WAF, load balancer, network, endpoint, and backend service sources.
Engineering Implementation Instructions
· Validate Splunk indexes, sourcetypes, CIM mappings, field names, macros, asset lookups, source IP mappings, destination enrichment, and timestamp normalization before deployment.
· Scope the rule to Ivanti Sentry appliances and comparable secure mobile gateway assets tagged as enterprise mobility gateway, secure mobile gateway, or mobile access control-plane infrastructure.
· Create or validate a Sentry asset lookup that maps hostname, source IP, appliance role, exposure status, platform type, business owner, and approved backend dependency group.
· Create or validate an approved Sentry dependency lookup that includes vendor update paths, approved mobile access flows, backend application paths, connector destinations, identity services, directory services, certificate infrastructure, logging destinations, monitoring systems, backup destinations, and approved administrative paths.
· Define suspicious gateway activity as derived enrichment from local Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, authentication logs, application logs, endpoint telemetry, file telemetry, process telemetry, network telemetry, and backend service logs.
· Validate supporting-context fields before using gates such as suspicious administrative access, abnormal gateway request activity, gateway service instability, suspicious file activity, unexpected shell or script execution, unexpected connector access, unexpected certificate or keystore access, unexpected appliance configuration changes, or new backend access.
· Tune destination-rarity logic to Sentry gateway behavior rather than applying generic server rarity thresholds.
· Tune the correlation window to account for log latency, gateway request timing, delayed network telemetry, backend service logging, and SOC investigation requirements.
· Increase severity when rare egress or backend dependency deviation occurs near suspicious administrative access, abnormal gateway request activity, service instability, suspicious file activity, unexpected shell or script execution, unexpected connector access, unexpected certificate or keystore access, or unexpected appliance configuration changes.
· Suppress known maintenance, patching, backup, monitoring, connector, vendor-support, certificate-renewal, and update workflows only when source, destination, timing, account, asset role, change ticket, and operational context are validated.
· Prefer stats-based or datamodel-backed correlation over join-based SPL for production scalability.
· Keep the rule in hunt mode until Sentry asset tags, dependency baselines, approved-destination lookups, source IP mappings, supporting-context enrichment, false-positive baselines, and query-performance characteristics are validated.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to Sentry gateway activity correlated with rare egress or backend dependency deviation rather than brittle exploit artifacts.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, payload formatting changes, public proof-of-concept behavior varies, or adversaries rely on legitimate gateway infrastructure after access.
· The score is supported by the durability of secure mobile gateway assets communicating outside approved mobile access, update, connector, identity, directory, certificate, logging, monitoring, or backend dependency paths.
· The score is constrained by legitimate mobile access flows, backend application relay behavior, connector synchronization, vendor updates, monitoring, backup, support workflows, and incomplete dependency baselines.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on Sentry asset-role tagging, source IP accuracy, Splunk normalization, Sentry log availability, network flow visibility, DNS/proxy/firewall/NDR telemetry, approved-destination baselines, backend dependency mapping, and validated supporting-context enrichment.
· Operational confidence is reduced where Sentry appliances are not clearly tagged, gateway traffic is not separated from other mobile access infrastructure, backend dependencies are poorly documented, or supporting-context gates are not backed by reliable telemetry.
· Full-telemetry confidence improves when Splunk correlates Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, backend service logs, authentication logs, application logs, network telemetry, file telemetry, and process telemetry where available.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious Sentry gateway activity correlated with network or backend dependency deviation, not the original exploit request.
· Legitimate mobile access flows, connector activity, vendor updates, backend application traffic, monitoring systems, backup tools, support workflows, certificate renewal, and maintenance activity may overlap with rare egress or backend dependency deviation.
· This rule requires asset-role tagging, source IP mapping, approved-destination baselining, dependency mapping, Splunk field normalization, and supporting-context enrichment validation to remain reliable.
· Confirmation requires correlation with suspicious administrative access, gateway service instability, suspicious execution, file activity, unexpected connector access, unexpected certificate or keystore access, unexpected appliance configuration changes, backend anomalies, or other supporting compromise evidence.
Detection Query Pattern
Splunk SPL correlation pattern requiring index, sourcetype, CIM, macro, lookup, derived-field, asset, dependency, and enrichment validation before production deployment.
The macros in this pattern are placeholders for normalized event streams:
· sentry_gateway_activity should return Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, application logs, authentication logs, and other gateway-relevant events where available.
· network_connections should return network flow, proxy, DNS, firewall, or NDR events from Sentry source IPs.
· sentry_gateway_assets should map hostnames and source IPs to Sentry asset role, platform type, exposure status, and business context.
· sentry_approved_dependencies should map approved vendor update paths, mobile access flows, backend applications, connector destinations, identity services, directory services, certificate services, logging destinations, monitoring systems, backup destinations, integrations, and administrative paths.
Derived fields such as gateway_activity_deviation, destination_deviation, supporting_context_present, and approved_workflow must be created from local baselines, enrichment lookups, Sentry telemetry, network telemetry, backend service context, and field normalization before deployment.
(
sentry_gateway_activity
| lookup sentry_gateway_assets host AS dest OUTPUT asset_role, platform_type, exposure_status, sentry_source_ip, business_owner
| where asset_role IN (
"Ivanti Sentry",
"Secure Mobile Gateway",
"Enterprise Mobility Gateway",
"Mobile Access Control-Plane Asset"
)
| eval suspicious_admin_access=if(
is_new_admin_source=1 OR is_new_admin_geo=1 OR is_new_admin_asn=1 OR is_new_admin_device=1 OR outside_admin_window=1 OR unusual_admin_access_path=1,
1,
0
)
| eval abnormal_gateway_request=if(
abnormal_request_pattern=1 OR abnormal_request_volume=1 OR suspicious_gateway_error=1 OR unusual_admin_workflow=1,
1,
0
)
| eval gateway_service_instability=if(
service_restart=1 OR application_fault=1 OR crash_event=1 OR repeated_failed_operation=1,
1,
0
)
| eval suspicious_file_activity=if(
suspicious_file_write=1 OR script_staging=1 OR archive_creation=1 OR web_accessible_write=1 OR sensitive_config_access=1,
1,
0
)
| eval suspicious_execution=if(
service_context_shell=1 OR script_execution=1 OR network_utility_execution=1 OR archive_utility_execution=1 OR credential_utility_execution=1,
1,
0
)
| eval unexpected_connector_access=if(
connector_access_deviation=1 OR connector_access_outside_change_window=1,
1,
0
)
| eval unexpected_certificate_or_keystore_access=if(
certificate_access_deviation=1 OR keystore_access_deviation=1 OR credential_material_access_deviation=1,
1,
0
)
| eval unexpected_appliance_configuration_change=if(
appliance_config_change_deviation=1 OR gateway_policy_change_deviation=1,
1,
0
)
| eval supporting_context_present=if(
suspicious_admin_access=1
OR abnormal_gateway_request=1
OR gateway_service_instability=1
OR suspicious_file_activity=1
OR suspicious_execution=1
OR unexpected_connector_access=1
OR unexpected_certificate_or_keystore_access=1
OR unexpected_appliance_configuration_change=1,
1,
0
)
| where supporting_context_present=1
| eval event_stage="sentry_supporting_context"
| rename time AS eventtime, dest AS sentry_host
| table event_time, event_stage, sentry_host, sentry_source_ip, asset_role, platform_type, exposure_status, business_owner, suspicious_admin_access, abnormal_gateway_request, gateway_service_instability, suspicious_file_activity, suspicious_execution, unexpected_connector_access, unexpected_certificate_or_keystore_access, unexpected_appliance_configuration_change, supporting_context_present
)
| append [
search network_connections
| lookup sentry_gateway_assets src_ip AS src OUTPUT asset_role, platform_type, exposure_status, business_owner
| where asset_role IN (
"Ivanti Sentry",
"Secure Mobile Gateway",
"Enterprise Mobility Gateway",
"Mobile Access Control-Plane Asset"
)
| lookup sentry_approved_dependencies dest_ip AS dest OUTPUT dependency_category AS dest_dependency_category, approved_destination AS dest_approved
| lookup sentry_approved_dependencies dest_domain AS dest_domain OUTPUT dependency_category AS domain_dependency_category, approved_destination AS domain_approved
| eval approved_dependency=if(dest_approved=1 OR domain_approved=1,1,0)
| eval destination_deviation=if(
is_new_external_destination_for_gateway=1
OR is_rare_external_destination_for_gateway=1
OR low_reputation_destination=1
OR unusual_destination_asn=1
OR unusual_destination_geo=1
OR is_new_backend_destination=1
OR is_rare_backend_destination_for_gateway=1
OR unexpected_port_for_gateway=1
OR unexpected_protocol_for_gateway=1
OR unexpected_directionality=1
OR abnormal_byte_volume=1
OR repeated_failed_backend_connections=1,
1,
0
)
| where destination_deviation=1
| where approved_dependency=0
| eval event_stage="gateway_network_deviation"
| rename time AS eventtime, src AS sentry_source_ip, dest AS network_dest, dest_domain AS network_dest_domain
| table event_time, event_stage, sentry_source_ip, asset_role, platform_type, exposure_status, business_owner, network_dest, network_dest_domain, dest_port, protocol, bytes_out, bytes_in, destination_deviation, approved_dependency
]
| stats
min(eval(if(event_stage="sentry_supporting_context", event_time, null()))) AS first_context_time
values(eval(if(event_stage="sentry_supporting_context", sentry_host, null()))) AS sentry_host
values(eval(if(event_stage="sentry_supporting_context", suspicious_admin_access, null()))) AS suspicious_admin_access
values(eval(if(event_stage="sentry_supporting_context", abnormal_gateway_request, null()))) AS abnormal_gateway_request
values(eval(if(event_stage="sentry_supporting_context", gateway_service_instability, null()))) AS gateway_service_instability
values(eval(if(event_stage="sentry_supporting_context", suspicious_file_activity, null()))) AS suspicious_file_activity
values(eval(if(event_stage="sentry_supporting_context", suspicious_execution, null()))) AS suspicious_execution
values(eval(if(event_stage="sentry_supporting_context", unexpected_connector_access, null()))) AS unexpected_connector_access
values(eval(if(event_stage="sentry_supporting_context", unexpected_certificate_or_keystore_access, null()))) AS unexpected_certificate_or_keystore_access
values(eval(if(event_stage="sentry_supporting_context", unexpected_appliance_configuration_change, null()))) AS unexpected_appliance_configuration_change
min(eval(if(event_stage="gateway_network_deviation", event_time, null()))) AS first_network_deviation_time
values(eval(if(event_stage="gateway_network_deviation", network_dest, null()))) AS network_dest
values(eval(if(event_stage="gateway_network_deviation", network_dest_domain, null()))) AS network_dest_domain
values(eval(if(event_stage="gateway_network_deviation", dest_port, null()))) AS dest_port
values(eval(if(event_stage="gateway_network_deviation", protocol, null()))) AS protocol
values(eval(if(event_stage="gateway_network_deviation", bytes_out, null()))) AS bytes_out
values(eval(if(event_stage="gateway_network_deviation", bytes_in, null()))) AS bytes_in
values(eval(if(event_stage="gateway_network_deviation", destination_deviation, null()))) AS destination_deviation
values(asset_role) AS asset_role
values(platform_type) AS platform_type
values(exposure_status) AS exposure_status
values(business_owner) AS business_owner
BY sentry_source_ip
| where isnotnull(first_context_time)
AND isnotnull(first_network_deviation_time)
AND first_network_deviation_time >= relative_time(first_context_time, "-2h")
AND first_network_deviation_time <= relative_time(first_context_time, "+24h")
| eval detection_reason="Ivanti Sentry or secure mobile gateway activity correlated with rare egress or backend dependency deviation"
| table first_context_time, first_network_deviation_time, sentry_host, sentry_source_ip, asset_role, platform_type, exposure_status, business_owner, suspicious_admin_access, abnormal_gateway_request, gateway_service_instability, suspicious_file_activity, suspicious_execution, unexpected_connector_access, unexpected_certificate_or_keystore_access, unexpected_appliance_configuration_change, network_dest, network_dest_domain, dest_port, protocol, bytes_out, bytes_in, detection_reason
Elastic
Detection Viability Assessment
Elastic has two rules for this EXP report.
· Elastic is viable for detecting suspicious endpoint, authentication, application, and network behavior associated with MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· Elastic is strongest where Elastic Defend, endpoint process telemetry, authentication logs, application audit events, network events, and asset-role context are normalized into ECS-aligned fields.
· Elastic is not a standalone source for confirming exploit success unless authentication, application, endpoint, and network evidence can be correlated.
· Elastic is most valuable for identifying suspicious management-service execution and management-server network anomalies through ECS-aligned process, host, user, file, event, and network fields.
Rule 1
Management Application Process Spawns Suspicious Child Process
Rule Format
Elastic EQL/KQL detection pattern suitable for Elastic Security rule deployment after ECS field validation, index-pattern validation, asset-role enrichment, exception tuning, and environment-specific process validation.
Detection Purpose
· Detect suspicious process execution where MDM, EPMM, endpoint-management, security-management, or enterprise administration service processes spawn shells, scripting engines, network utilities, archive tools, credential-access utilities, service-control commands, or persistence-related tooling.
· Identify post-access endpoint behavior that may follow exploitation, administrative abuse, or management-control-plane compromise.
· Detect the behavior without relying on CVE strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized administrative access without supporting authentication, application, file, network, or configuration-change evidence.
Detection Logic
· Identify process start events on tagged management-control-plane assets.
· Identify parent processes associated with management application services, Java, Tomcat, web-service processes, application-server processes, vendor services, or management-platform service accounts.
· Prioritize child processes associated with shell execution, scripting, outbound retrieval, archive staging, service control, account manipulation, credential access, or persistence mechanisms.
· Increase confidence when suspicious process execution follows unusual administrative access, abnormal API activity, privileged object changes, rare egress, file staging, service instability, or application errors.
· Suppress expected patching, backup, monitoring, vendor-support, connector, vulnerability management, and administrative automation workflows only when process lineage, command line, execution user, host role, and time window are validated.
· Do not classify the activity as confirmed compromise without corroborating authentication, application, file, outbound communication, or privileged configuration-change evidence.
Required Telemetry
· Elastic endpoint process start events.
· ECS-aligned process parent and child fields.
· Process command line.
· User and service-account context.
· Host identity.
· Host role or asset-role enrichment.
· Endpoint operating system.
· Timestamp.
· Process executable path.
· Process-to-network correlation where available.
· Application, authentication, file, and network telemetry for enrichment where available.
Engineering Implementation Instructions
· Validate Elastic index patterns, ECS field mappings, event categories, host fields, user fields, process fields, labels, and asset enrichment before deployment.
· Scope the rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Tune parent process names and executable paths to the organization’s actual management-platform stack.
· Tune suspicious child process lists to the operating systems and administrative tooling used in the environment.
· Add exceptions for approved patching, vendor updates, backups, monitoring, support workflows, connector operations, vulnerability management, and administrative automation.
· Treat internet-exposed management-server status, unusual administrative access, privileged object changes, rare egress, file staging, or service instability as prioritization context.
· Use authentication, application, file, and network telemetry as triage evidence rather than assuming service-context execution alone equals compromise.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious management-service child-process execution rather than brittle exploit artifacts.
· The rule remains useful if exploit delivery changes, public proof-of-concept behavior varies, attacker infrastructure rotates, or payload formatting changes.
· The score is supported by the durability of management application processes spawning shells, interpreters, network utilities, archive tools, credential utilities, or persistence mechanisms as post-access behavior.
· The score is constrained by overlap with legitimate maintenance, patching, monitoring, support workflows, backup operations, connector behavior, and administrative automation.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on ECS field quality, process ancestry fidelity, command-line capture, user context, host-role tagging, endpoint coverage, and maintenance baseline quality.
· Operational confidence is reduced where endpoint telemetry is incomplete, process lineage is inconsistent, or management-platform service paths are poorly baselined.
· Full-telemetry confidence improves when Elastic correlates endpoint process telemetry with administrative authentication, application activity, file activity, rare egress, privileged object changes, and service instability.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious post-access execution behavior, not the original exploit request.
· Legitimate maintenance, patching, backup, monitoring, support, connector, vulnerability management, and administrative automation workflows may overlap with this behavior.
· This rule requires endpoint process telemetry, command-line visibility, ECS normalization, and host-role scoping to remain reliable.
· Confirmation requires correlation with suspicious administrative access, application activity, file activity, outbound communication, privileged object changes, service instability, or other compromise evidence.
Detection Query Pattern
Elastic EQL detection pattern requiring index-pattern, ECS field, asset-role, exception, and enrichment validation before production deployment.
Fields such as labels.asset_role, labels.approved_workflow, and related enrichment labels are deployment-specific fields that must be mapped to the organization’s Elastic asset inventory and exception model before use.
process where event.type == "start"
and labels.asset_role in (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
and process.parent.name in (
"java",
"java.exe",
"tomcat",
"tomcat.exe",
"catalina",
"catalina.sh",
"httpd",
"apache2",
"nginx",
"w3wp.exe",
"vendor-management-service",
"mdm-service",
"epmm-service",
"management-service"
)
and process.name in (
"cmd.exe",
"powershell.exe",
"pwsh.exe",
"wscript.exe",
"cscript.exe",
"mshta.exe",
"rundll32.exe",
"regsvr32.exe",
"wmic.exe",
"bitsadmin.exe",
"certutil.exe",
"curl.exe",
"wget.exe",
"bash",
"sh",
"dash",
"zsh",
"python",
"python3",
"perl",
"php",
"nc",
"ncat",
"socat",
"tar",
"zip",
"gzip",
"openssl",
"systemctl",
"service",
"crontab",
"schtasks.exe",
"sc.exe",
"net.exe",
"net1.exe"
)
and not process.command_line : (
"*approved_vendor_update*",
"*approved_patch_workflow*",
"*approved_backup_workflow*",
"*approved_monitoring_workflow*",
"*approved_connector_workflow*",
"*approved_support_workflow*"
)
and not labels.approved_workflow == true
Rule 2
Management Server Rare Egress or Lateral Communication After Administrative Access
Rule Format
Elastic EQL sequence pattern suitable for Elastic Security rule deployment after ECS field validation, index-pattern validation, asset-role enrichment, administrative-access enrichment, and network baseline tuning.
Detection Purpose
· Detect unusual administrative access to a management-control-plane asset followed by rare external egress or unexpected internal communication from the same management server.
· Identify possible post-access staging, command-and-control preparation, discovery, lateral movement, connector abuse, or unauthorized use of trusted management infrastructure.
· Detect the behavior without relying on CVE strings, exploit payloads, static indicators, scanner names, attacker infrastructure, or one vendor-specific exploit path.
· This rule does not prove compromise without supporting authentication, endpoint, application, file, or privileged configuration-change evidence.
Detection Logic
· Identify unusual administrative access to a tagged MDM, EPMM, endpoint-management, security-management, or enterprise administration asset.
· Correlate that access with subsequent network behavior from the same host, including rare external destinations, new DNS patterns, abnormal egress, unexpected east-west communication, or internal dependency deviation.
· Prioritize network activity involving new destinations, unusual ports, unusual protocols, abnormal byte volume, repeated failed connection attempts, or communication outside approved vendor, connector, identity, directory, logging, monitoring, backup, database, or integration dependencies.
· Increase confidence when network anomalies occur near suspicious process execution, file staging, privileged object changes, abnormal API activity, service instability, or application errors.
· Suppress expected maintenance, vendor updates, monitoring, backups, connector behavior, vulnerability scanning, support, and administrative automation only when source, destination, timing, asset role, and operational context are validated.
· Do not classify the activity as confirmed compromise without corroborating endpoint, application, authentication, file, or privileged configuration-change evidence.
Required Telemetry
· Elastic-ingested administrative authentication events.
· Elastic network events, DNS events, proxy events, or NDR-derived events.
· Host identity and host-role tags.
· Source and destination IP, port, protocol, and domain where available.
· User and administrative-access context.
· Destination rarity or baseline-enrichment fields.
· Internal dependency baseline where available.
· Timestamp normalization across authentication and network sources.
· Endpoint, file, application, and object-change telemetry for enrichment where available.
Engineering Implementation Instructions
· Validate Elastic index patterns, ECS mappings, event categories, host fields, user fields, source and destination fields, network fields, DNS fields, labels, and asset enrichment before deployment.
· Scope the rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Define administrative-access deviation as a local enrichment derived from baseline source networks, geographies, devices, access paths, accounts, and administrative windows.
· Define network deviation using destination rarity, internal dependency mapping, known vendor paths, connector dependencies, and approved integration baselines.
· Tune the sequence window to the organization’s logging latency and operational model.
· Add exceptions for approved vendor updates, monitoring, backups, connector workflows, support activity, vulnerability scanning, and administrative automation.
· Use endpoint, application, file, and privileged-object telemetry as triage evidence rather than assuming rare egress or lateral communication alone proves compromise.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to unusual administrative access followed by rare egress or unexpected lateral communication.
· The rule remains useful if exploit mechanics change, attacker infrastructure rotates, or public indicators become stale.
· The score is supported by the durability of management servers communicating outside expected administrative, connector, update, identity, directory, and integration patterns.
· The score is constrained by legitimate maintenance, vendor updates, connector behavior, monitoring traffic, backup workflows, vulnerability scanning, support activity, and incomplete dependency mapping.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on authentication visibility, ECS field quality, host-role tagging, network telemetry, destination baselining, administrative baselines, and timestamp normalization.
· Operational confidence is reduced where network visibility is incomplete, administrative-access deviation is not modeled, or approved dependencies are poorly documented.
· Full-telemetry confidence improves when Elastic correlates administrative access, endpoint execution, file activity, network anomalies, privileged object changes, and application instability.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious access-to-network behavior, not the original exploit request.
· Legitimate vendor updates, connectors, integrations, monitoring systems, backups, vulnerability scanners, support workflows, and administrative automation may overlap with this behavior.
· This rule requires authentication telemetry, network telemetry, ECS normalization, host-role tagging, and baseline enrichment to remain reliable.
· Confirmation requires correlation with suspicious endpoint execution, application activity, file activity, privileged object changes, persistence, service instability, or other supporting compromise evidence.
Detection Query Pattern
Elastic EQL sequence pattern requiring ECS field validation, index-pattern validation, asset-role enrichment, administrative-deviation enrichment, and destination-baseline enrichment before production deployment.
Fields such as labels.asset_role, labels.admin_access_deviation, labels.rare_external_destination, labels.unexpected_east_west, and labels.destination_in_approved_dependency_baseline are deployment-specific enrichment fields that must be mapped before use.
sequence by host.id with maxspan=24h
[authentication where event.outcome == "success"
and labels.asset_role in (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
and (
labels.admin_access_deviation == true
or labels.new_source == true
or labels.new_geo == true
or labels.new_asn == true
or labels.new_device == true
or labels.outside_admin_window == true
or labels.unusual_access_path == true
)
]
[network where event.type in ("connection", "start")
and labels.asset_role in (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
and (
labels.rare_external_destination == true
or labels.new_internal_destination == true
or labels.unexpected_east_west == true
or labels.unusual_destination_asn == true
or labels.unusual_destination_geo == true
or labels.abnormal_byte_volume == true
or labels.rare_port_for_asset == true
or labels.rare_protocol_for_asset == true
)
and not labels.destination_in_approved_dependency_baseline == true
]
QRadar
Detection Viability Assessment
QRadar has one rule for this EXP report.
· QRadar is viable for correlating administrative access, application audit events, endpoint process telemetry, network events, and privileged management-plane changes associated with MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· QRadar is strongest where log sources are normalized, management-control-plane assets are tagged, administrative audit logs are available, and CRE correlation can connect access, object-change, endpoint, and network behavior.
· QRadar is not a standalone source for confirming exploit success unless authentication, application, endpoint, and network evidence are available and correlated.
· QRadar is most valuable as a consolidated correlation layer for unusual management-plane access followed by suspicious host activity, rare egress, unexpected east-west communication, or privileged control-plane modification.
Rule 1
Management-Plane Administrative Access Followed by Suspicious Host or Network Event
Rule Format
QRadar CRE correlation rule with supporting AQL search pattern. Suitable for deployment after log-source validation, DSM normalization, custom-property mapping, reference-set validation, asset tagging, and field mapping.
Detection Purpose
· Detect unusual administrative access to an MDM, EPMM, endpoint-management, security-management, or enterprise administration system followed by suspicious host or network behavior from the same management-control-plane asset.
· Identify behavior consistent with exploitation, administrative abuse, post-access execution, control-plane modification, staging, rare egress, or internal expansion.
· Detect the behavior without depending on CVE strings, exploit payloads, scanner names, attacker infrastructure, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized session use without supporting endpoint, application, file, network, or privileged configuration-change evidence.
Detection Logic
· Identify successful administrative access to a tagged management-control-plane asset from an unusual source, account, device, geography, ASN, access path, or time window.
· Correlate the administrative access with suspicious endpoint execution, file activity, privileged object changes, rare egress, unexpected east-west communication, service instability, or abnormal API activity involving the same management server.
· Prioritize activity where management application services, Java, Tomcat, web-service processes, vendor services, application-server processes, or service accounts spawn shells, scripting engines, network utilities, archive tools, credential-access utilities, service-control commands, or persistence-related tooling.
· Increase confidence when the same sequence includes administrator-account changes, role changes, certificate changes, connector changes, API-token activity, enrollment-profile modification, policy changes, rare external communication, or unexpected internal communication.
· Suppress approved maintenance, patching, backup, monitoring, connector, vendor-support, vulnerability management, certificate rotation, policy rollout, and administrative automation only when account, source, object type, process lineage, destination, timing, and asset role are validated.
· Do not classify the activity as confirmed compromise without corroborating application, endpoint, file, outbound communication, privileged configuration-change, or downstream impact evidence.
Required Telemetry
· QRadar-ingested administrative authentication logs.
· MDM, EPMM, endpoint-management, security-management, or enterprise administration application logs where available.
· Endpoint process creation telemetry.
· File activity telemetry where available.
· Network flow telemetry.
· DNS, proxy, or NDR-derived telemetry where available.
· Administrative audit events.
· Privileged object-change events.
· Source IP, source user, destination host, action, object type, process, command line, destination IP, port, protocol, and timestamp context.
· QRadar asset model or reference set for management-control-plane systems.
· Reference sets for approved administrative sources, vendor update paths, connector dependencies, identity services, directory services, logging infrastructure, monitoring systems, backups, and approved integrations.
Engineering Implementation Instructions
· Validate QRadar log sources, DSM parsing, normalized fields, custom properties, CRE rule tests, reference sets, building blocks, and asset model entries before deployment.
· Scope the rule to assets tagged or referenced as MDM, EPMM, endpoint-management, security-management, or enterprise administration systems.
· Implement asset role, administrative access deviation, suspicious host behavior, suspicious network behavior, and privileged object change indicators as QRadar custom properties, building blocks, or reference-set-derived flags.
· Define administrative-access deviation using reference sets and derived logic for new sources, unusual accounts, uncommon geographies, new devices, unusual access paths, and activity outside administrative windows.
· Define suspicious host behavior using process ancestry, command line, parent process, child process, file activity, service activity, and persistence-relevant events where available.
· Define suspicious network behavior using rare destinations, unexpected east-west communication, unusual administrative protocols, abnormal byte volume, repeated failed connections, and communication outside approved dependencies.
· Define privileged control-plane changes using application or API audit events for administrator accounts, roles, certificates, connectors, API tokens, enrollment profiles, policies, integrations, and platform configuration objects.
· Use QRadar CRE correlation to link administrative access and suspicious host or network behavior within a default 24-hour investigation window. Tune the window to the organization’s logging latency, operational model, administrative workflows, and detection objectives.
· Add reference sets or rule exceptions for approved patching, backups, monitoring, vendor updates, support workflows, connector activity, certificate rotation, policy rollout, vulnerability management, and administrative automation.
· Route events involving internet-exposed management servers, externally reachable administrative interfaces, suspicious execution, or rare egress at higher priority.
· Use QRadar offenses as investigation triggers rather than confirmed compromise determinations unless corroborating evidence is present.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to unusual management-plane administrative access followed by suspicious host or network behavior.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, public proof-of-concept behavior varies, or payload formatting changes.
· The score is supported by the durability of access-to-execution, access-to-egress, and access-to-object-change behavior across management-control-plane compromise scenarios.
· The score is constrained by legitimate administration, support workflows, patching, monitoring, connector operations, certificate rotation, policy rollout, backup activity, vulnerability management, and automation that may overlap with the behavior.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on QRadar log-source coverage, DSM normalization, custom-property quality, asset tagging, reference-set maturity, timestamp consistency, and administrative baseline quality.
· Operational confidence is reduced where application logs are incomplete, endpoint telemetry is not ingested, network flow data lacks host identity, or administrative access paths are poorly baselined.
· Full-telemetry confidence improves when QRadar correlates authentication logs, application audit events, endpoint process telemetry, file activity, network flows, privileged object changes, and NDR-derived anomalies.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious management-plane access followed by abnormal behavior, not the original exploit request.
· Legitimate administrative maintenance, policy rollout, certificate rotation, connector updates, backups, monitoring, support workflows, vulnerability management, and automation may overlap with this behavior.
· This rule requires log-source coverage, DSM normalization, asset tagging, reference sets, and custom properties to remain reliable.
· Confirmation requires correlation with suspicious execution, file activity, privileged object changes, rare egress, unexpected east-west communication, persistence evidence, service instability, or downstream impact.
Detection Query Pattern
Primary QRadar CRE correlation pattern. The 24-hour window is a default tunable investigation window and should be adjusted based on logging latency, administrative workflow patterns, and operational requirements.
WHEN AdministrativeAuthenticationSuccess = true
AND DestinationAssetRole IN (
"MDM Server",
"EPMM Server",
"Endpoint Management Server",
"Security Management Server",
"Enterprise Management Server"
)
AND AdministrativeAccessDeviation = true
AND WITHIN TunableInvestigationWindow_Default24h
AND SameDestinationAsset HAS ANY (
SuspiciousHostBehavior = true,
SuspiciousNetworkBehavior = true,
PrivilegedObjectChange = true,
ApplicationOrServiceInstability = true,
AbnormalAPIActivity = true
)
AND NOT ApprovedOperationalWorkflow = true
THEN CreateOffense(
"Management-plane administrative access followed by suspicious host or network behavior"
)
Supporting QRadar AQL search pattern. This search is intended to support investigation, validation, and tuning of the CRE logic. It is not the primary detection mechanism by itself.
Custom-property and reference-set-derived fields such as asset_role, admin_access_deviation, suspicious_host_behavior, suspicious_network_behavior, privileged_object_change, application_or_service_instability, abnormal_api_activity, and approved_operational_workflow must be mapped to the deployed QRadar environment before production use.
SELECT
sourceip,
username,
destinationip,
destinationhostname,
LOGSOURCENAME(logsourceid) AS log_source,
QIDNAME(qid) AS event_name,
categoryname(category) AS event_category,
starttime,
"asset_role",
"admin_access_deviation",
"suspicious_host_behavior",
"suspicious_network_behavior",
"privileged_object_change",
"application_or_service_instability",
"abnormal_api_activity",
"approved_operational_workflow"
FROM events
WHERE
"asset_role" IN (
'MDM Server',
'EPMM Server',
'Endpoint Management Server',
'Security Management Server',
'Enterprise Management Server'
)
AND (
(
"event_type" = 'administrative_authentication'
AND "action" = 'success'
AND "admin_access_deviation" = 'true'
)
OR (
"suspicious_host_behavior" = 'true'
OR "suspicious_network_behavior" = 'true'
OR "privileged_object_change" = 'true'
OR "application_or_service_instability" = 'true'
OR "abnormal_api_activity" = 'true'
)
)
AND "approved_operational_workflow" != 'true'
LAST 24 HOURS
SIGMA
Detection Viability Assessment
SIGMA has two rules for this EXP report.
· SIGMA is viable for portable detection logic covering suspicious process execution, administrative-object changes, and post-access management-server behavior across SIEM platforms.
· SIGMA is strongest when endpoint, application, identity, and network telemetry are normalized consistently and management-control-plane assets are tagged.
· SIGMA is not a standalone source for confirming exploit success, administrative session validity, or a specific CVE exploit path.
· SIGMA is most valuable for expressing portable behavior-led logic that can be translated into Splunk, Elastic, QRadar, Microsoft Sentinel, or other supported SIEM environments after field mapping and platform validation.
Rule 1
Management Application Service Spawns Suspicious Child Process
Rule Format
SIGMA YAML rule suitable for SIEM translation after logsource validation, field mapping, asset-role enrichment, exception tuning, and platform-specific syntax validation.
Detection Purpose
· Detect suspicious child-process execution from MDM, EPMM, endpoint-management, security-management, or enterprise administration service context.
· Identify post-access behavior that may follow exploitation, administrative abuse, or management-control-plane compromise.
· Detect the behavior without relying on CVE strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized administrative access without supporting authentication, application, file, network, or privileged configuration-change evidence.
Detection Logic
· Identify process creation on tagged management-control-plane servers.
· Identify parent processes associated with management application services, Java, Tomcat, web-service processes, application-server processes, vendor services, or management-platform service accounts.
· Prioritize child processes associated with shells, scripting engines, network utilities, archive tools, credential-access utilities, service-control commands, account manipulation, or persistence mechanisms.
· Increase confidence when suspicious execution follows unusual administrative access, privileged object changes, rare egress, file staging, abnormal API activity, or service instability.
· Suppress approved maintenance, patching, backup, monitoring, connector, vendor-support, vulnerability management, and administrative automation only when process lineage, command line, user, host role, and time window are validated.
· Do not classify the event as confirmed compromise without corroborating authentication, application, file, network, or privileged configuration-change evidence.
Required Telemetry
· Process creation telemetry.
· Parent process and child process fields.
· Command-line capture.
· User and service-account context.
· Host identity.
· Host role or asset-role enrichment.
· Endpoint operating system.
· Timestamp.
· Application, authentication, file, and network telemetry for enrichment where available.
Engineering Implementation Instructions
· Validate SIEM backend support for SIGMA translation before deployment.
· Validate field mappings for parent process, child process, command line, host, user, process path, event type, and timestamp.
· Scope the translated rule to tagged MDM, EPMM, endpoint-management, security-management, and enterprise administration servers.
· Tune parent process names and service paths to the organization’s actual management-platform stack.
· Tune child process lists to the operating systems and administrative tooling used in the environment.
· Add exceptions for approved patching, vendor updates, backups, monitoring, support workflows, connector operations, vulnerability management, and administrative automation.
· Treat internet exposure, unusual administrative access, privileged object changes, rare egress, file staging, and service instability as enrichment and triage context.
· Use the translated SIGMA rule as a portable detection pattern that requires backend-specific validation before production use.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious management-service child-process execution rather than brittle exploit artifacts.
· The rule remains useful if exploit delivery changes, public proof-of-concept behavior varies, attacker infrastructure rotates, or payload formatting changes.
· The score is supported by the durability of management application services spawning shells, scripting engines, network utilities, archive tools, credential utilities, or persistence mechanisms as post-access behavior.
· The score is constrained by legitimate maintenance, patching, support workflows, backups, connector behavior, vulnerability management, and administrative automation.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on field mapping quality, process ancestry fidelity, command-line capture, host-role tagging, user context, endpoint coverage, and exception tuning.
· Operational confidence is reduced where process lineage is incomplete, backend translation is lossy, asset-role enrichment is missing, or management-platform service paths are poorly baselined.
· Full-telemetry confidence improves when translated SIGMA output is enriched with authentication, application, file, network, rare egress, and privileged object-change context.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious post-access execution behavior, not the original exploit request.
· Backend translation may alter field names, operators, case sensitivity, wildcard behavior, and list handling.
· Legitimate patching, vendor updates, backups, monitoring, support workflows, connector operations, vulnerability management, and administrative automation may overlap with this behavior.
· Confirmation requires correlation with suspicious access, application activity, file activity, outbound communication, privileged object changes, service instability, or other compromise evidence.
Detection Query Pattern
SIGMA YAML rule requiring backend field mapping, asset-role enrichment, and exception validation before production deployment.
title: Management Application Service Spawns Suspicious Child Process
id: 7e2f35d1-9e4b-4d8c-91aa-2b8b4bb14e41
status: test
description: Detects suspicious child-process execution from MDM, EPMM, endpoint-management, security-management, or enterprise administration service context.
author: Detection Engineering
date: 2026/05/07
logsource:
category: process_creation
detection:
selection_asset_role:
AssetRole|contains:
- MDM Server
- EPMM Server
- Endpoint Management Server
- Security Management Server
- Enterprise Management Server
selection_parent_image:
ParentImage|endswith:
- '\java.exe'
- '\tomcat.exe'
- '\w3wp.exe'
- '\httpd.exe'
- '\nginx.exe'
- '/java'
- '/tomcat'
- '/catalina'
- '/httpd'
- '/apache2'
- '/nginx'
selection_parent_cmdline:
ParentCommandLine|contains:
- vendor-management-service
- mdm-service
- epmm-service
- management-service
selection_child:
Image|endswith:
- '\cmd.exe'
- '\powershell.exe'
- '\pwsh.exe'
- '\wscript.exe'
- '\cscript.exe'
- '\mshta.exe'
- '\rundll32.exe'
- '\regsvr32.exe'
- '\wmic.exe'
- '\bitsadmin.exe'
- '\certutil.exe'
- '\curl.exe'
- '\wget.exe'
- '\schtasks.exe'
- '\sc.exe'
- '\net.exe'
- '\net1.exe'
- '/bash'
- '/sh'
- '/dash'
- '/zsh'
- '/python'
- '/python3'
- '/perl'
- '/php'
- '/curl'
- '/wget'
- '/nc'
- '/ncat'
- '/socat'
- '/tar'
- '/zip'
- '/gzip'
- '/openssl'
- '/systemctl'
- '/service'
- '/crontab'
filter_approved_workflows:
CommandLine|contains:
- approved_vendor_update
- approved_patch_workflow
- approved_backup_workflow
- approved_monitoring_workflow
- approved_connector_workflow
- approved_support_workflow
condition: selection_asset_role and (selection_parent_image or selection_parent_cmdline) and selection_child and not filter_approved_workflows
fields:
- UtcTime
- Hostname
- User
- ParentImage
- ParentCommandLine
- Image
- CommandLine
- AssetRole
falsepositives:
- Approved patching and vendor update workflows
- Backup and monitoring activity
- Connector workflows
- Vendor-support activity
- Vulnerability management
- Administrative automation
level: high
tags:
- attack.execution
- attack.persistence
- attack.t1059
- attack.t1105
- attack.t1569
Rule 2
Suspicious Management-Plane Object Change or Administrative Action
Rule Format
SIGMA YAML rule suitable for SIEM translation after application audit log validation, field mapping, asset-role enrichment, object-type normalization, exception tuning, and platform-specific syntax validation.
Detection Purpose
· Detect suspicious administrative or management-plane object changes involving MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms.
· Identify possible control-plane abuse involving administrator accounts, roles, certificates, connectors, API tokens, enrollment profiles, policies, integrations, or platform configuration objects.
· Detect the behavior without relying on CVE strings, exploit payloads, static indicators, scanner names, attacker infrastructure, or one vendor-specific exploit path.
· This rule does not prove the object change is malicious without supporting authentication, endpoint, file, network, application, or downstream device-impact evidence.
Detection Logic
· Identify creation, modification, enablement, disablement, rotation, or update of privileged management-plane objects.
· Prioritize changes affecting administrator accounts, roles, certificates, connectors, enrollment profiles, API tokens, device-management profiles, policies, integrations, and platform configuration objects.
· Increase confidence when the change is performed by an unusual account, from an unusual source, outside administrative windows, or near suspicious endpoint, network, file, API, or service-instability activity.
· Suppress approved policy rollout, certificate rotation, connector updates, patching, backup, migration, vendor-support, and administrative automation only when account, source, object type, change window, and operational context are validated.
· Do not classify the event as confirmed compromise without corroborating suspicious access, execution, file activity, rare egress, persistence, lateral movement, or downstream device impact.
Required Telemetry
· Application or API audit logs.
· Administrative action logs.
· Object-change events.
· User and source context.
· Object type and object name.
· Action and outcome.
· Host identity.
· Host role or platform role.
· Timestamp.
· Endpoint, file, authentication, and network telemetry for enrichment where available.
Engineering Implementation Instructions
· Validate SIEM backend support for SIGMA translation before deployment.
· Validate field mappings for application audit events, administrative actions, object type, object name, user, source, host, action, outcome, and timestamp.
· Scope the translated rule to MDM, EPMM, endpoint-management, security-management, and enterprise administration platform logs.
· Normalize platform-specific object types to common categories such as administrator account, role, certificate, connector, API token, enrollment profile, device profile, policy, integration, and platform configuration.
· Define unusual source, unusual user, sensitive object, outside change window, approved workflow, and related change context values as environment-specific enrichment fields where supported.
· Add exceptions for approved policy rollout, certificate rotation, connector maintenance, vendor-support, patching, backup, migration, vulnerability management, and administrative automation.
· Use endpoint, authentication, network, file, and downstream device telemetry as triage evidence rather than treating object change alone as confirmed compromise.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to privileged management-plane object changes rather than exploit artifacts.
· The rule remains useful if exploit mechanics change, attackers use legitimate administrative workflows, or public indicators rotate.
· The score is supported by the durability of administrator, role, certificate, connector, API-token, profile, policy, integration, and platform configuration changes as meaningful control-plane events.
· The score is constrained by legitimate administrative workflows, policy rollout, certificate rotation, connector maintenance, vendor-support activity, patching, backup, migration, and automation.
TCR Assessment
Operational TCR
6.5 / 10
Full-Telemetry TCR
8.0 / 10
· Operational confidence depends on application audit logging, object-type normalization, user/source context, asset-role tagging, change-window baselines, and backend translation quality.
· Operational confidence is reduced where application logs are incomplete, privileged objects are not categorized, or routine administrative changes are poorly baselined.
· Full-telemetry confidence improves when translated SIGMA output is enriched with suspicious access, endpoint execution, file activity, rare egress, application instability, and downstream device impact.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule detects suspicious management-plane object changes, not the original exploit request.
· Backend translation may alter field names, operators, case sensitivity, wildcard behavior, and list handling.
· Legitimate administration, policy rollout, certificate rotation, connector updates, patching, support, backup, migration, and automation may overlap with this behavior.
· Confirmation requires correlation with suspicious administrative access, endpoint execution, file activity, outbound communication, persistence, lateral movement, or downstream impact.
Detection Query Pattern
SIGMA YAML rule requiring application log mapping, object-type normalization, environment-specific enrichment-field mapping, backend field mapping, and exception validation before production deployment.
Fields such as ChangeContext, PlatformRole, ObjectType, and Action are portable placeholders. They must be mapped to the target SIEM’s normalized application audit fields or platform-specific audit schema before deployment.
title: Suspicious Management-Plane Object Change or Administrative Action
id: b9c4d3d6-0c65-4b34-9b9f-3f0fa91b7ef2
status: test
description: Detects suspicious privileged object changes in MDM, EPMM, endpoint-management, security-management, or enterprise administration platforms.
author: Detection Engineering
date: 2026/05/07
logsource:
category: application
detection:
selection_platform:
PlatformRole|contains:
- MDM
- EPMM
- Endpoint Management
- Security Management
- Enterprise Management
selection_action:
Action|contains:
- created
- modified
- enabled
- disabled
- rotated
- updated
selection_object:
ObjectType|contains:
- administrator_account
- admin_role
- certificate
- connector
- enrollment_profile
- api_token
- device_management_profile
- policy
- integration
- platform_configuration
selection_deviation:
ChangeContext|contains:
- unusual_user
- unusual_source
- outside_change_window
- sensitive_object
filter_approved_workflows:
ChangeContext|contains:
- approved_policy_rollout
- approved_certificate_rotation
- approved_connector_update
- approved_patch_workflow
- approved_backup_workflow
- approved_migration
- approved_vendor_support
- approved_administrative_automation
condition: selection_platform and selection_action and selection_object and selection_deviation and not filter_approved_workflows
fields:
- UtcTime
- Hostname
- User
- SourceIp
- PlatformRole
- Action
- ObjectType
- ObjectName
- ChangeContext
falsepositives:
- Approved administrative changes
- Policy rollout
- Certificate rotation
- Connector maintenance
- Vendor-support activity
- Backup and migration workflows
- Administrative automation
level: medium
tags:
- attack.persistence
- attack.privilege_escalation
- attack.defense_evasion
- attack.t1098
- attack.t1136
YARA
Detection Viability Assessment
YARA has zero rules for this EXP report.
· YARA is not carried forward because no validated malware sample, file artifact, webshell pattern, memory artifact, payload structure, or confirmed malicious script is available.
· YARA is not appropriate for the current behavior-led detection model, which focuses on administrative access anomalies, management-service execution, rare egress, privileged control-plane changes, and management-server network deviation.
· YARA may be reassessed if future authoritative reporting provides validated file or memory artifacts associated with this activity.
Rule Disposition
No YARA rules are carried forward.
AWS
Detection Viability Assessment
AWS has one conditional rule for this EXP report.
· AWS is conditionally viable where MDM, EPMM, endpoint-management, security-management, or enterprise administration infrastructure is deployed on AWS-hosted assets.
· AWS is strongest when CloudTrail, VPC Flow Logs, Route 53 Resolver DNS logs, GuardDuty findings, Security Hub findings, EC2 context, SSM activity, and centralized endpoint or application logs can be correlated to a tagged management-control-plane asset.
· AWS is not a standalone source for confirming exploit success, administrative session validity, or a specific CVE exploit path.
· AWS is most valuable for identifying suspicious cloud-hosted management-control-plane activity, including unusual administrative access, abnormal instance behavior, rare egress, unexpected internal communication, suspicious identity activity, or post-access infrastructure changes.
Rule 1
AWS-Hosted Management-Control-Plane Activity Followed by Suspicious Compute, Identity, or Network Behavior
Rule Format
Normalized AWS data-lake / SIEM correlation pattern suitable for implementation in Athena, CloudWatch Logs Insights, Security Lake, a SIEM, or a centralized data lake after account, region, tag, resource, identity, VPC, and log-source validation.
This query pattern is not literal native AWS syntax. Table names, field names, enrichment fields, and correlation keys must be mapped to the deployed AWS logging architecture before production use.
Detection Purpose
· Detect unusual administrative or management activity associated with an AWS-hosted MDM, EPMM, endpoint-management, security-management, or enterprise administration server followed by suspicious compute, identity, or network behavior tied to the same management-control-plane asset.
· Identify behavior consistent with post-access staging, unauthorized use of trusted management infrastructure, rare egress, internal expansion, credential abuse, or cloud-hosted management-server compromise.
· Detect the behavior without relying on CVE strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized administrative access without supporting application, endpoint, identity, network, or configuration-change evidence.
Detection Logic
· Identify AWS-hosted assets tagged as MDM, EPMM, endpoint-management, security-management, or enterprise administration systems.
· Use an enriched management asset key to correlate activity tied to the same management server, instance, IAM instance role, security group, subnet, VPC, or approved administrative workflow.
· Identify unusual administrative or management activity associated with that asset, including unusual source IP, unusual geography, unusual IAM principal, unusual access path, unusual SSM activity, or activity outside expected administrative windows.
· Correlate the activity with suspicious compute, identity, or network behavior involving the same enriched management asset context.
· Prioritize activity involving rare egress, new external destinations, unexpected east-west traffic, abnormal DNS activity, unusual role assumption tied to the management asset, security group modification affecting the management asset, route modification affecting the management subnet or VPC, relevant GuardDuty findings, or abnormal SSM activity.
· Increase confidence when suspicious AWS activity occurs near endpoint execution alerts, application audit events, privileged control-plane changes, file staging, service instability, or abnormal management-platform API activity.
· Do not classify the activity as confirmed compromise without corroborating application, endpoint, identity, network, or privileged configuration-change evidence.
Required Telemetry
· AWS asset tags or inventory identifying management-control-plane assets.
· Enriched management asset key linking instance ID, resource ID, IAM role, security group, subnet, VPC, account, and region.
· CloudTrail management events.
· CloudTrail data events where relevant.
· VPC Flow Logs.
· Route 53 Resolver DNS logs where available.
· GuardDuty findings where available.
· Security Hub findings where available.
· EC2 instance metadata and tag context.
· IAM principal, role, session, and source context.
· Security group, network ACL, route table, subnet, and VPC context.
· SSM Session Manager and Run Command activity where available.
· Centralized endpoint, application, or management-platform logs where available.
· Timestamp normalization across AWS and non-AWS sources.
Engineering Implementation Instructions
· Scope the rule to AWS-hosted MDM, EPMM, endpoint-management, security-management, and enterprise administration systems using asset tags, instance inventory, subnet context, VPC context, IAM instance profile, or CMDB enrichment.
· Build or validate a normalized management asset key before deployment. The key should map cloud events to the affected management server or its immediate AWS resource context.
· Validate CloudTrail, VPC Flow Logs, Route 53 Resolver DNS logs, GuardDuty, Security Hub, EC2, IAM, and SSM log availability before deployment.
· Define unusual administrative activity using expected IAM principals, source networks, access paths, administrative windows, regions, and management workflows.
· Treat IAM events as relevant only when they are tied to the management asset, its instance role, associated security group, subnet, VPC, administrative workflow, or management-platform operational context.
· Define suspicious network behavior using rare destination analysis, VPC baseline deviation, unexpected east-west communication, abnormal DNS activity, unusual ports, unusual protocols, or traffic outside approved dependencies.
· Define suspicious infrastructure behavior using security group changes, route changes, SSM activity, GuardDuty findings, or Security Hub findings that affect or reference the management asset context.
· Tune exceptions for approved patching, backups, monitoring, vendor updates, connector workflows, support activity, vulnerability management, and administrative automation.
· Use a default 24-hour investigation window for correlation and tune it to logging latency, administrative workflow patterns, and operational requirements.
· Increase severity when the affected instance is internet-exposed, associated with externally reachable administrative interfaces, or linked to suspicious endpoint, application, or privileged object-change activity.
· Use AWS findings as investigation triggers unless corroborating application, endpoint, identity, file, or network evidence supports compromise classification.
DRI Assessment
DRI
7.5 / 10
· The rule is behaviorally anchored to suspicious AWS-hosted management-control-plane activity rather than exploit artifacts.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, public indicators become stale, or payload behavior varies.
· The score is supported by the durability of rare egress, suspicious identity activity tied to management-asset context, abnormal SSM usage, security group changes, route changes, and VPC communication deviation as post-access behaviors.
· The score is constrained by legitimate administration, patching, backup workflows, connector behavior, monitoring systems, vendor-support activity, vulnerability management, and cloud automation.
TCR Assessment
Operational TCR
6.5 / 10
Full-Telemetry TCR
8.0 / 10
· Operational confidence depends on asset tagging, management asset key enrichment, CloudTrail coverage, VPC Flow Log visibility, DNS visibility, GuardDuty or Security Hub enrichment, IAM context, SSM visibility, and management-server baseline quality.
· Operational confidence is reduced where cloud-hosted management assets are not tagged, asset-to-cloud-resource mapping is incomplete, VPC Flow Logs are incomplete, DNS logs are unavailable, or application and endpoint telemetry are not centralized.
· Full-telemetry confidence improves when AWS telemetry is correlated with endpoint execution, application audit logs, administrative authentication events, file activity, privileged control-plane changes, and NDR or proxy telemetry.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule applies only where management-control-plane infrastructure is deployed in AWS or where AWS telemetry provides meaningful visibility into the affected management server.
· This rule detects suspicious cloud-hosted management-control-plane behavior, not the original exploit request.
· Legitimate administration, vendor updates, monitoring, backups, connector workflows, support activity, vulnerability management, and cloud automation may overlap with this behavior.
· Identity events can be noisy unless they are tied to the management asset, its instance role, security group, subnet, VPC, administrative workflow, or platform operational context.
· Confirmation requires correlation with suspicious administrative access, endpoint execution, application activity, file activity, privileged object changes, rare egress, or other supporting compromise evidence.
Detection Query Pattern
Normalized AWS data-lake / SIEM correlation pattern requiring account, region, tag, resource, identity, VPC, log-source, and enrichment validation before production deployment.
This pattern uses normalized placeholder tables and fields. It is intended for implementation in Athena, CloudWatch Logs Insights, Security Lake, SIEM, or a centralized data lake after mapping to the deployed AWS logging architecture. The default 24-hour window is tunable and should be adjusted based on logging latency, administrative workflows, and operational requirements.
WITH management_assets AS (
SELECT
management_asset_id,
instance_id,
resource_id,
account_id,
region,
asset_role,
exposure_status,
iam_instance_role,
security_group_id,
subnet_id,
vpc_id
FROM normalized_asset_inventory
WHERE asset_role IN (
'MDM Server',
'EPMM Server',
'Endpoint Management Server',
'Security Management Server',
'Enterprise Management Server'
)
),
admin_activity AS (
SELECT
event_time,
management_asset_id,
account_id,
region,
user_identity_arn,
source_ip_address,
event_name,
resource_id,
instance_id,
iam_role_arn,
security_group_id,
subnet_id,
vpc_id,
'admin_activity' AS event_stage
FROM normalized_aws_control_plane_events
WHERE event_name IN (
'ConsoleLogin',
'AssumeRole',
'StartSession',
'SendCommand',
'AuthorizeSecurityGroupIngress',
'AuthorizeSecurityGroupEgress',
'ModifyInstanceAttribute',
'CreateRoute',
'ReplaceRoute'
)
AND related_to_management_asset = true
AND (
unusual_source = true
OR unusual_geo = true
OR unusual_principal = true
OR outside_admin_window = true
OR unusual_access_path = true
OR unusual_ssm_activity = true
)
),
suspicious_activity AS (
SELECT
event_time,
management_asset_id,
account_id,
region,
resource_id,
instance_id,
vpc_id,
destination_ip,
destination_domain,
destination_port,
protocol,
finding_type,
event_name,
'suspicious_activity' AS event_stage
FROM normalized_aws_security_network_events
WHERE related_to_management_asset = true
AND (
rare_external_destination = true
OR unexpected_east_west = true
OR abnormal_dns_activity = true
OR unusual_ssm_activity = true
OR suspicious_iam_activity = true
OR guardduty_relevant_finding = true
OR security_group_deviation = true
OR route_table_deviation = true
)
AND approved_operational_workflow != true
)
SELECT
a.event_time AS admin_time,
s.event_time AS suspicious_time,
m.account_id,
m.region,
m.management_asset_id,
m.instance_id,
m.resource_id,
m.asset_role,
m.exposure_status,
a.user_identity_arn,
a.source_ip_address,
a.event_name AS admin_event,
s.event_name AS suspicious_event,
s.finding_type,
s.destination_ip,
s.destination_domain,
s.destination_port,
s.protocol
FROM management_assets m
JOIN admin_activity a
ON m.management_asset_id = a.management_asset_id
JOIN suspicious_activity s
ON m.management_asset_id = s.management_asset_id
WHERE s.event_time >= a.event_time
AND s.event_time <= a.event_time + INTERVAL '24' HOUR;
Azure
Detection Viability Assessment
Azure has one conditional rule for this EXP report.
· Azure is conditionally viable where MDM, EPMM, endpoint-management, security-management, or enterprise administration infrastructure is deployed on Azure-hosted assets.
· Azure is strongest when Azure Activity Logs, Entra ID sign-in and audit logs, NSG Flow Logs, Defender for Cloud alerts, VM telemetry, Azure Monitor logs, and centralized endpoint or application logs can be correlated to a tagged management-control-plane asset.
· Azure is not a standalone source for confirming exploit success, administrative session validity, or a specific CVE exploit path.
· Azure is most valuable for identifying suspicious cloud-hosted management-control-plane activity, including unusual administrative access, abnormal VM behavior, rare egress, unexpected internal communication, suspicious identity activity, or post-access infrastructure changes.
Rule 1
Azure-Hosted Management-Control-Plane Activity Followed by Suspicious VM, Identity, or Network Behavior
Rule Format
Normalized Azure data-lake / SIEM correlation pattern suitable for implementation in Microsoft Sentinel, Log Analytics, Azure Monitor, Defender for Cloud, a SIEM, or a centralized data lake after tenant, subscription, resource, identity, VNet, tag, and log-source validation.
This query pattern is not literal native Azure syntax. Table names, field names, enrichment fields, and correlation keys must be mapped to the deployed Azure logging architecture before production use.
Detection Purpose
· Detect unusual administrative or management activity associated with an Azure-hosted MDM, EPMM, endpoint-management, security-management, or enterprise administration server followed by suspicious VM, identity, or network behavior tied to the same management-control-plane asset.
· Identify behavior consistent with post-access staging, unauthorized use of trusted management infrastructure, rare egress, internal expansion, credential abuse, or cloud-hosted management-server compromise.
· Detect the behavior without relying on CVE strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized administrative access without supporting application, endpoint, identity, network, or configuration-change evidence.
Detection Logic
· Identify Azure-hosted assets tagged as MDM, EPMM, endpoint-management, security-management, or enterprise administration systems.
· Use an enriched management asset key to correlate activity tied to the same management server, VM, managed identity, network interface, subnet, network security group, VNet, subscription, resource group, or approved administrative workflow.
· Identify unusual administrative or management activity associated with that asset, including unusual source IP, unusual geography, unusual Entra ID principal, unusual access path, unusual VM management action, or activity outside expected administrative windows.
· Correlate the activity with suspicious VM, identity, or network behavior involving the same enriched management asset context.
· Prioritize activity involving rare egress, new external destinations, unexpected east-west traffic, abnormal DNS activity, unusual managed identity use, NSG modification affecting the management asset, route modification affecting the management subnet or VNet, Defender for Cloud alerts, or abnormal VM extension / Run Command activity.
· Increase confidence when suspicious Azure activity occurs near endpoint execution alerts, application audit events, privileged control-plane changes, file staging, service instability, or abnormal management-platform API activity.
· Do not classify the activity as confirmed compromise without corroborating application, endpoint, identity, network, or privileged configuration-change evidence.
Required Telemetry
· Azure asset tags or inventory identifying management-control-plane assets.
· Enriched management asset key linking VM resource ID, host identity, managed identity, network interface, subnet, NSG, VNet, subscription, resource group, and region.
· Azure Activity Logs.
· Entra ID sign-in logs.
· Entra ID audit logs.
· NSG Flow Logs or equivalent network flow telemetry.
· Azure Firewall, proxy, DNS, or private DNS logs where available.
· Defender for Cloud alerts where available.
· VM telemetry and endpoint telemetry where available.
· Azure Monitor / Log Analytics logs.
· Managed identity, service principal, role assignment, and session context.
· NSG, route table, network interface, subnet, VNet, and public IP context.
· VM Run Command, VM extension, serial console, or automation activity where available.
· Centralized application or management-platform logs where available.
· Timestamp normalization across Azure and non-Azure sources.
Engineering Implementation Instructions
· Scope the rule to Azure-hosted MDM, EPMM, endpoint-management, security-management, and enterprise administration systems using asset tags, VM inventory, subnet context, VNet context, managed identity, subscription metadata, or CMDB enrichment.
· Build or validate a normalized management asset key before deployment. The key should map Azure events to the affected management server or its immediate Azure resource context.
· Validate Azure Activity Logs, Entra ID sign-in logs, Entra ID audit logs, NSG Flow Logs, Defender for Cloud, VM telemetry, Azure Monitor, Log Analytics, managed identity, and VM management activity before deployment.
· Define unusual administrative activity using expected Entra ID principals, source networks, access paths, administrative windows, regions, subscriptions, and management workflows.
· Treat identity events as relevant only when they are tied to the management asset, its managed identity, service principal, role assignment, network interface, NSG, subnet, VNet, administrative workflow, or platform operational context.
· Define suspicious network behavior using rare destination analysis, VNet baseline deviation, unexpected east-west communication, abnormal DNS activity, unusual ports, unusual protocols, or traffic outside approved dependencies.
· Define suspicious infrastructure behavior using NSG changes, route changes, VM Run Command activity, VM extension changes, Defender for Cloud alerts, or Azure Activity events that affect or reference the management asset context.
· Tune exceptions for approved patching, backups, monitoring, vendor updates, connector workflows, support activity, vulnerability management, and administrative automation.
· Use a default 24-hour investigation window for correlation and tune it to logging latency, administrative workflow patterns, and operational requirements.
· Increase severity when the affected VM is internet-exposed, associated with externally reachable administrative interfaces, or linked to suspicious endpoint, application, or privileged object-change activity.
· Use Azure findings as investigation triggers unless corroborating application, endpoint, identity, file, or network evidence supports compromise classification.
DRI Assessment
DRI
7.5 / 10
· The rule is behaviorally anchored to suspicious Azure-hosted management-control-plane activity rather than exploit artifacts.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, public indicators become stale, or payload behavior varies.
· The score is supported by the durability of rare egress, suspicious identity activity tied to management-asset context, abnormal VM management activity, NSG changes, route changes, and VNet communication deviation as post-access behaviors.
· The score is constrained by legitimate administration, patching, backup workflows, connector behavior, monitoring systems, vendor-support activity, vulnerability management, and cloud automation.
TCR Assessment
Operational TCR
6.5 / 10
Full-Telemetry TCR
8.0 / 10
· Operational confidence depends on asset tagging, management asset key enrichment, Azure Activity Log coverage, Entra ID telemetry, NSG Flow Log visibility, DNS visibility, Defender for Cloud enrichment, managed identity context, VM telemetry, and management-server baseline quality.
· Operational confidence is reduced where cloud-hosted management assets are not tagged, asset-to-cloud-resource mapping is incomplete, NSG Flow Logs are incomplete, DNS logs are unavailable, or application and endpoint telemetry are not centralized.
· Full-telemetry confidence improves when Azure telemetry is correlated with endpoint execution, application audit logs, administrative authentication events, file activity, privileged control-plane changes, and NDR or proxy telemetry.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule applies only where management-control-plane infrastructure is deployed in Azure or where Azure telemetry provides meaningful visibility into the affected management server.
· This rule detects suspicious cloud-hosted management-control-plane behavior, not the original exploit request.
· Legitimate administration, vendor updates, monitoring, backups, connector workflows, support activity, vulnerability management, and cloud automation may overlap with this behavior.
· Identity events can be noisy unless they are tied to the management asset, its managed identity, service principal, role assignment, network interface, NSG, subnet, VNet, administrative workflow, or platform operational context.
· Confirmation requires correlation with suspicious administrative access, endpoint execution, application activity, file activity, privileged object changes, rare egress, or other supporting compromise evidence.
Detection Query Pattern
Normalized Azure data-lake / SIEM correlation pattern requiring tenant, subscription, resource, identity, VNet, tag, log-source, and enrichment validation before production deployment.
This pattern uses normalized placeholder tables and fields. It is intended for implementation in Microsoft Sentinel, Log Analytics, Azure Monitor, Defender for Cloud, SIEM, or a centralized data lake after mapping to the deployed Azure logging architecture. The default 24-hour window is tunable and should be adjusted based on logging latency, administrative workflows, and operational requirements.
WITH management_assets AS (
SELECT
management_asset_id,
vm_resource_id,
host_id,
tenant_id,
subscription_id,
resource_group,
region,
asset_role,
exposure_status,
managed_identity_id,
service_principal_id,
network_interface_id,
nsg_id,
subnet_id,
vnet_id
FROM normalized_asset_inventory
WHERE asset_role IN (
'MDM Server',
'EPMM Server',
'Endpoint Management Server',
'Security Management Server',
'Enterprise Management Server'
)
),
admin_activity AS (
SELECT
event_time,
management_asset_id,
tenant_id,
subscription_id,
region,
principal_id,
principal_name,
source_ip_address,
operation_name,
vm_resource_id,
managed_identity_id,
service_principal_id,
network_interface_id,
nsg_id,
subnet_id,
vnet_id,
'admin_activity' AS event_stage
FROM normalized_azure_control_plane_events
WHERE operation_name IN (
'SignIn',
'RoleAssignmentWrite',
'VirtualMachinesRunCommandAction',
'VirtualMachinesExtensionsWrite',
'NetworkSecurityGroupsWrite',
'SecurityRulesWrite',
'RouteTablesWrite',
'RoutesWrite',
'PublicIPAddressesWrite',
'NetworkInterfacesWrite'
)
AND related_to_management_asset = true
AND (
unusual_source = true
OR unusual_geo = true
OR unusual_principal = true
OR outside_admin_window = true
OR unusual_access_path = true
OR unusual_vm_management_activity = true
)
),
suspicious_activity AS (
SELECT
event_time,
management_asset_id,
tenant_id,
subscription_id,
region,
vm_resource_id,
vnet_id,
destination_ip,
destination_domain,
destination_port,
protocol,
alert_type,
operation_name,
'suspicious_activity' AS event_stage
FROM normalized_azure_security_network_events
WHERE related_to_management_asset = true
AND (
rare_external_destination = true
OR unexpected_east_west = true
OR abnormal_dns_activity = true
OR unusual_vm_run_command = true
OR suspicious_identity_activity = true
OR defender_relevant_alert = true
OR nsg_deviation = true
OR route_table_deviation = true
)
AND approved_operational_workflow != true
)
SELECT
a.event_time AS admin_time,
s.event_time AS suspicious_time,
m.tenant_id,
m.subscription_id,
m.region,
m.management_asset_id,
m.vm_resource_id,
m.asset_role,
m.exposure_status,
a.principal_id,
a.principal_name,
a.source_ip_address,
a.operation_name AS admin_operation,
s.operation_name AS suspicious_operation,
s.alert_type,
s.destination_ip,
s.destination_domain,
s.destination_port,
s.protocol
FROM management_assets m
JOIN admin_activity a
ON m.management_asset_id = a.management_asset_id
JOIN suspicious_activity s
ON m.management_asset_id = s.management_asset_id
WHERE s.event_time >= a.event_time
AND s.event_time <= a.event_time + INTERVAL '24' HOUR;
GCP
Detection Viability Assessment
GCP has one conditional rule for this EXP report.
· GCP is conditionally viable where MDM, EPMM, endpoint-management, security-management, or enterprise administration infrastructure is deployed on GCP-hosted assets.
· GCP is strongest when Cloud Audit Logs, VPC Flow Logs, Cloud DNS logs, Security Command Center findings, Compute Engine telemetry, IAM activity, service account activity, and centralized endpoint or application logs can be correlated to a tagged management-control-plane asset.
· GCP is not a standalone source for confirming exploit success, administrative session validity, or a specific CVE exploit path.
· GCP is most valuable for identifying suspicious cloud-hosted management-control-plane activity, including unusual administrative access, abnormal compute behavior, rare egress, unexpected internal communication, suspicious identity activity, or post-access infrastructure changes.
Rule 1
GCP-Hosted Management-Control-Plane Activity Followed by Suspicious Compute, Identity, or Network Behavior
Rule Format
Normalized GCP data-lake / SIEM correlation pattern suitable for implementation in BigQuery, Cloud Logging, Security Command Center, Chronicle, a SIEM, or a centralized data lake after organization, folder, project, resource, identity, VPC, tag, log-source, and enrichment validation.
This query pattern is not literal native GCP syntax. Table names, field names, operation categories, enrichment fields, and correlation keys must be mapped to the deployed GCP logging architecture before production use.
Detection Purpose
· Detect unusual administrative or management activity associated with a GCP-hosted MDM, EPMM, endpoint-management, security-management, or enterprise administration server followed by suspicious compute, identity, or network behavior tied to the same management-control-plane asset.
· Identify behavior consistent with post-access staging, unauthorized use of trusted management infrastructure, rare egress, internal expansion, credential abuse, or cloud-hosted management-server compromise.
· Detect the behavior without relying on CVE strings, exploit payloads, scanner names, attacker IP addresses, public proof-of-concept artifacts, or one vendor-specific exploit implementation.
· This rule does not confirm successful exploitation or unauthorized administrative access without supporting application, endpoint, identity, network, or configuration-change evidence.
Detection Logic
· Identify GCP-hosted assets tagged as MDM, EPMM, endpoint-management, security-management, or enterprise administration systems.
· Use an enriched management asset key to correlate activity tied to the same management server, VM instance, service account, IAM binding, impersonation path, network interface, subnet, firewall rule, VPC, project, or approved administrative workflow.
· Identify unusual administrative or management activity associated with that asset, including unusual source IP, unusual geography, unusual principal, unusual service account use, unusual access path, unusual compute management action, or activity outside expected administrative windows.
· Correlate the activity with suspicious compute, identity, or network behavior involving the same enriched management asset context.
· Prioritize normalized operation categories such as IAM policy changes, service account token use, service account impersonation, instance metadata changes, firewall rule changes, route changes, OS Login activity, external IP changes, abnormal DNS activity, rare egress, unexpected east-west traffic, and Security Command Center findings.
· Treat service-account activity as relevant only when it is tied to the management asset, its service account, IAM binding, impersonation path, project, VPC, subnet, firewall rule, administrative workflow, or platform operational context.
· Increase confidence when suspicious GCP activity occurs near endpoint execution alerts, application audit events, privileged control-plane changes, file staging, service instability, or abnormal management-platform API activity.
· Do not classify the activity as confirmed compromise without corroborating application, endpoint, identity, network, or privileged configuration-change evidence.
Required Telemetry
· GCP asset tags, labels, or inventory identifying management-control-plane assets.
· Enriched management asset key linking VM instance ID, resource name, service account, IAM binding, impersonation path, network interface, subnet, firewall rule, VPC, project, folder, organization, and region or zone.
· Cloud Audit Logs.
· IAM activity and service account activity.
· VPC Flow Logs.
· Cloud DNS logs where available.
· Security Command Center findings where available.
· Compute Engine instance metadata and label context.
· OS Login, SSH, serial console, metadata change, or instance management activity where available.
· Firewall rule, route, subnet, VPC, external IP, and network interface context.
· Centralized endpoint, application, or management-platform logs where available.
· Timestamp normalization across GCP and non-GCP sources.
Engineering Implementation Instructions
· Scope the rule to GCP-hosted MDM, EPMM, endpoint-management, security-management, and enterprise administration systems using asset labels, Compute Engine inventory, subnet context, VPC context, service account context, project metadata, or CMDB enrichment.
· Build or validate a normalized management asset key before deployment. The key should map GCP events to the affected management server or its immediate GCP resource context.
· Validate Cloud Audit Logs, VPC Flow Logs, Cloud DNS logs, Security Command Center, Compute Engine telemetry, IAM logs, service account activity, OS Login, and instance management activity before deployment.
· Normalize GCP audit activity into operation categories such as iam_policy_change, service_account_token_use, service_account_impersonation, instance_metadata_change, firewall_rule_change, route_change, external_ip_change, os_login_activity, instance_management_activity, and security_command_center_finding.
· Define unusual administrative activity using expected principals, service accounts, source networks, access paths, administrative windows, projects, regions, zones, and management workflows.
· Treat identity and service-account events as relevant only when they are tied to the management asset, its service account, IAM binding, impersonation path, firewall rule, subnet, VPC, project, administrative workflow, or platform operational context.
· Define suspicious network behavior using rare destination analysis, VPC baseline deviation, unexpected east-west communication, abnormal DNS activity, unusual ports, unusual protocols, or traffic outside approved dependencies.
· Define suspicious infrastructure behavior using firewall changes, route changes, instance metadata changes, OS Login activity, serial console activity, Security Command Center findings, or Cloud Audit events that affect or reference the management asset context.
· Tune exceptions for approved patching, backups, monitoring, vendor updates, connector workflows, support activity, vulnerability management, and administrative automation.
· Use a default tunable investigation window for correlation and adjust it to logging latency, administrative workflow patterns, and operational requirements.
· Increase severity when the affected VM is internet-exposed, associated with externally reachable administrative interfaces, or linked to suspicious endpoint, application, or privileged object-change activity.
· Use GCP findings as investigation triggers unless corroborating application, endpoint, identity, file, or network evidence supports compromise classification.
DRI Assessment
DRI
7.5 / 10
· The rule is behaviorally anchored to suspicious GCP-hosted management-control-plane activity rather than exploit artifacts.
· The rule remains useful if exploit delivery changes, attacker infrastructure rotates, public indicators become stale, or payload behavior varies.
· The score is supported by the durability of rare egress, suspicious service account activity tied to management-asset context, abnormal instance management activity, firewall changes, route changes, and VPC communication deviation as post-access behaviors.
· The score is constrained by legitimate administration, patching, backup workflows, connector behavior, monitoring systems, vendor-support activity, vulnerability management, and cloud automation.
TCR Assessment
Operational TCR
6.5 / 10
Full-Telemetry TCR
8.0 / 10
· Operational confidence depends on asset labeling, management asset key enrichment, Cloud Audit Log coverage, IAM and service account telemetry, VPC Flow Log visibility, DNS visibility, Security Command Center enrichment, Compute Engine telemetry, and management-server baseline quality.
· Operational confidence is reduced where cloud-hosted management assets are not labeled, asset-to-cloud-resource mapping is incomplete, VPC Flow Logs are incomplete, DNS logs are unavailable, or application and endpoint telemetry are not centralized.
· Full-telemetry confidence improves when GCP telemetry is correlated with endpoint execution, application audit logs, administrative authentication events, file activity, privileged control-plane changes, and NDR or proxy telemetry.
· Even under full telemetry conditions, this rule requires correlation before confirmed compromise classification.
Limitations
· This rule applies only where management-control-plane infrastructure is deployed in GCP or where GCP telemetry provides meaningful visibility into the affected management server.
· This rule detects suspicious cloud-hosted management-control-plane behavior, not the original exploit request.
· Legitimate administration, vendor updates, monitoring, backups, connector workflows, support activity, vulnerability management, and cloud automation may overlap with this behavior.
· Identity and service account events can be noisy unless they are tied to the management asset, its service account, IAM binding, impersonation path, firewall rule, subnet, VPC, project, administrative workflow, or platform operational context.
· Confirmation requires correlation with suspicious administrative access, endpoint execution, application activity, file activity, privileged object changes, rare egress, or other supporting compromise evidence.
Detection Query Pattern
Normalized GCP data-lake / SIEM correlation pattern requiring organization, folder, project, resource, identity, VPC, tag, log-source, operation-category, and enrichment validation before production deployment.
This pattern uses normalized placeholder tables and fields. It is intended for implementation in BigQuery, Cloud Logging, Security Command Center, Chronicle, SIEM, or a centralized data lake after mapping to the deployed GCP logging architecture. TUNABLE_INVESTIGATION_WINDOW_HOURS is a deployment-specific parameter and should be set based on logging latency, administrative workflows, and operational requirements.
WITH parameters AS (
SELECT
24 AS TUNABLE_INVESTIGATION_WINDOW_HOURS
),
management_assets AS (
SELECT
management_asset_id,
instance_id,
resource_name,
organization_id,
folder_id,
project_id,
region,
zone,
asset_role,
exposure_status,
service_account_email,
iam_binding_id,
impersonation_path,
network_interface_id,
firewall_rule_id,
subnet_id,
vpc_id
FROM normalized_asset_inventory
WHERE asset_role IN (
'MDM Server',
'EPMM Server',
'Endpoint Management Server',
'Security Management Server',
'Enterprise Management Server'
)
),
admin_activity AS (
SELECT
event_time,
management_asset_id,
organization_id,
folder_id,
project_id,
region,
zone,
principal_email,
service_account_email,
source_ip_address,
operation_category,
resource_name,
instance_id,
iam_binding_id,
impersonation_path,
firewall_rule_id,
subnet_id,
vpc_id,
'admin_activity' AS event_stage
FROM normalized_gcp_control_plane_events
WHERE operation_category IN (
'iam_policy_change',
'service_account_token_use',
'service_account_impersonation',
'instance_metadata_change',
'instance_management_activity',
'firewall_rule_change',
'route_change',
'external_ip_change',
'os_login_activity'
)
AND related_to_management_asset = true
AND identity_context_tied_to_management_asset = true
AND (
unusual_source = true
OR unusual_geo = true
OR unusual_principal = true
OR unusual_service_account_use = true
OR outside_admin_window = true
OR unusual_access_path = true
OR unusual_instance_management_activity = true
)
),
suspicious_activity AS (
SELECT
event_time,
management_asset_id,
organization_id,
folder_id,
project_id,
region,
zone,
resource_name,
instance_id,
vpc_id,
destination_ip,
destination_domain,
destination_port,
protocol,
finding_type,
operation_category,
'suspicious_activity' AS event_stage
FROM normalized_gcp_security_network_events
WHERE operation_category IN (
'rare_external_destination',
'unexpected_east_west',
'abnormal_dns_activity',
'service_account_anomaly',
'security_command_center_finding',
'firewall_rule_deviation',
'route_table_deviation',
'instance_metadata_deviation',
'os_login_anomaly'
)
AND related_to_management_asset = true
AND approved_operational_workflow != true
)
SELECT
a.event_time AS admin_time,
s.event_time AS suspicious_time,
m.organization_id,
m.folder_id,
m.project_id,
m.region,
m.zone,
m.management_asset_id,
m.instance_id,
m.resource_name,
m.asset_role,
m.exposure_status,
a.principal_email,
a.service_account_email,
a.source_ip_address,
a.operation_category AS admin_operation_category,
s.operation_category AS suspicious_operation_category,
s.finding_type,
s.destination_ip,
s.destination_domain,
s.destination_port,
s.protocol
FROM management_assets m
JOIN admin_activity a
ON m.management_asset_id = a.management_asset_id
JOIN suspicious_activity s
ON m.management_asset_id = s.management_asset_id
CROSS JOIN parameters p
WHERE s.event_time >= a.event_time
AND s.event_time <= a.event_time + INTERVAL p.TUNABLE_INVESTIGATION_WINDOW_HOURS HOUR;
S26 — Threat-to-Rule Traceability Matrix
Traceability Overview
The S25 rule package maps to the primary behavioral risks identified in this report: unusual administrative access, suspicious management-service execution, rare egress, unexpected east-west communication, privileged control-plane object changes, file and persistence activity, secure mobile gateway dependency deviation, and conditional cloud-hosted management-control-plane behavior.
The rule set provides behavior-led coverage across NDR / Network Behavioral Analytics, SentinelOne, Splunk, Elastic, QRadar, SIGMA, AWS, Azure, and GCP. YARA is documented as a zero-rule system because validated artifact evidence is not available.
Unusual Administrative Access Followed by Suspicious Activity
Primary Rule Coverage
Splunk Rule 1 — Unusual Management Console Access Followed by Suspicious Server-Side Execution
Supporting Rule Coverage
· QRadar Rule 1.
· Elastic Rule 2.
· NDR Rule 1.
Rule Outcome
Covered.
Management Application Service Spawning Suspicious Child Processes
Primary Rule Coverage
SentinelOne Rule 1 — Management Application Service Spawns Shell or Administrative Tooling
Supporting Rule Coverage
· Elastic Rule 1.
· SIGMA Rule 1.
· Splunk Rule 1.
· QRadar Rule 1.
Rule Outcome
Covered.
Suspicious Execution from Java, Tomcat, Web-Service, Application-Server, Vendor-Service, or Management-Platform Context
Primary Rule Coverage
Elastic Rule 1 — Management Application Process Spawns Suspicious Child Process
Supporting Rule Coverage
· SentinelOne Rule 1.
· SIGMA Rule 1.
· Splunk Rule 1.
· QRadar Rule 1.
Rule Outcome
Covered.
Rare External Egress After Unusual Administrative Access
Primary Rule Coverage
NDR Rule 1 — Management-Control Plane Administrative Access Followed by Rare Egress
Supporting Rule Coverage
· Elastic Rule 2.
· Splunk Rule 1.
· Splunk Rule 2.
· QRadar Rule 1.
Rule Outcome
Covered.
Unexpected East-West Communication or Internal Dependency Deviation
Primary Rule Coverage
NDR Rule 2 — Management Server Initiates Unexpected East-West or Dependency-Deviation Traffic
Supporting Rule Coverage
· Elastic Rule 2.
· Splunk Rule 2.
· QRadar Rule 1.
Rule Outcome
Covered.
Privileged Control-Plane Object Changes
Primary Rule Coverage
Splunk Rule 2 — Privileged Management-Plane Object Change Followed by Abnormal Host or Network Behavior
Supporting Rule Coverage
· SIGMA Rule 2.
· QRadar Rule 1.
· Elastic Rule 2.
Rule Outcome
Covered.
Suspicious Management-Plane Administrative Action or Object-Change Activity
Primary Rule Coverage
SIGMA Rule 2 — Suspicious Management-Plane Object Change or Administrative Action
Supporting Rule Coverage
· Splunk Rule 2.
· QRadar Rule 1.
Rule Outcome
Covered.
Suspicious File, Script, or Persistence-Relevant Activity from Management Service Context
Primary Rule Coverage
SentinelOne Rule 2 — Suspicious File, Script, or Persistence Activity from Management Service Context
Supporting Rule Coverage
· Splunk Rule 2.
· QRadar Rule 1.
· SIGMA Rule 1.
Rule Outcome
Covered.
Management Server Network Behavior Outside Approved Dependencies
Primary Rule Coverage
· NDR Rule 1 — Management-Control Plane Administrative Access Followed by Rare Egress.
· NDR Rule 2 — Management Server Initiates Unexpected East-West or Dependency-Deviation Traffic.
Supporting Rule Coverage
· Elastic Rule 2.
· Splunk Rule 2.
· QRadar Rule 1.
Rule Outcome
Covered.
Ivanti Sentry Gateway Rare Egress or Backend Dependency Deviation
Primary Rule Coverage
· NDR Rule 3 — Ivanti Sentry Gateway Rare Egress or Backend Dependency Deviation.
· Splunk Rule 3 — Ivanti Sentry Gateway Activity Correlated With Rare Egress or Backend Dependency Deviation.
Supporting Rule Coverage
· Existing management-server rare egress, unexpected east-west communication, suspicious execution, file activity, and privileged object-change rules may provide supporting context where Ivanti Sentry or comparable secure mobile gateway telemetry is available and mapped to the management-control-plane asset model.
· SentinelOne, Elastic, and SIGMA may provide supporting execution or file-activity context only where Sentry or comparable secure mobile gateway infrastructure has endpoint, process, Linux audit, or file telemetry available.
· QRadar may provide supporting correlation where Sentry appliance, network, authentication, backend service, and supporting-context telemetry are ingested and normalized.
· AWS, Azure, and GCP rules may provide supporting context only where Sentry or related secure mobile gateway infrastructure is cloud-hosted or where cloud telemetry provides meaningful visibility into the affected gateway asset.
Rule Outcome
Coverage with adaptation.
Ivanti Sentry Gateway Activity With Supporting Appliance or Backend Context
Primary Rule Coverage
Splunk Rule 3 — Ivanti Sentry Gateway Activity Correlated With Rare Egress or Backend Dependency Deviation
Supporting Rule Coverage
· NDR Rule 3 provides network-behavior support where Sentry source IPs, approved dependencies, destination baselines, and gateway asset tags are available.
· NDR Rule 1 and NDR Rule 2 provide supporting rare egress and dependency-deviation context where Sentry is mapped into the broader management-control-plane asset model.
· SentinelOne, Elastic, or SIGMA rules may provide supporting execution or file-activity context only where Sentry or comparable gateway infrastructure has endpoint, process, Linux audit, or file telemetry available.
· Cloud rules provide supporting context only where Sentry or related gateway infrastructure is cloud-hosted or where cloud telemetry provides meaningful visibility into the affected gateway asset.
Rule Outcome
Coverage with adaptation.
AWS-Hosted Management-Control-Plane Activity
Primary Rule Coverage
AWS Rule 1 — AWS-Hosted Management-Control-Plane Activity Followed by Suspicious Compute, Identity, or Network Behavior
Supporting Rule Coverage
· NDR Rule 1 where cloud network telemetry is integrated.
· NDR Rule 2 where cloud network telemetry is integrated.
· NDR Rule 3 where cloud-hosted Sentry or secure mobile gateway network telemetry is integrated and mapped to the secure mobile gateway asset role.
· Splunk Rule 1 where AWS logs are centralized.
· Splunk Rule 2 where AWS logs are centralized.
· Splunk Rule 3 where cloud-hosted Sentry telemetry, AWS network telemetry, backend service logs, or gateway-relevant supporting context are centralized.
Rule Outcome
Conditional Coverage.
Azure-Hosted Management-Control-Plane Activity
Primary Rule Coverage
Azure Rule 1 — Azure-Hosted Management-Control-Plane Activity Followed by Suspicious VM, Identity, or Network Behavior
Supporting Rule Coverage
· NDR Rule 1 where cloud network telemetry is integrated.
· NDR Rule 2 where cloud network telemetry is integrated.
· NDR Rule 3 where cloud-hosted Sentry or secure mobile gateway network telemetry is integrated and mapped to the secure mobile gateway asset role.
· Splunk Rule 1 where Azure logs are centralized.
· Splunk Rule 2 where Azure logs are centralized.
· Splunk Rule 3 where cloud-hosted Sentry telemetry, Azure network telemetry, backend service logs, or gateway-relevant supporting context are centralized.
Rule Outcome
Conditional Coverage.
GCP-Hosted Management-Control-Plane Activity
Primary Rule Coverage
GCP Rule 1 — GCP-Hosted Management-Control-Plane Activity Followed by Suspicious Compute, Identity, or Network Behavior
Supporting Rule Coverage
· NDR Rule 1 where cloud network telemetry is integrated.
· NDR Rule 2 where cloud network telemetry is integrated.
· NDR Rule 3 where cloud-hosted Sentry or secure mobile gateway network telemetry is integrated and mapped to the secure mobile gateway asset role.
· Splunk Rule 1 where GCP logs are centralized.
· Splunk Rule 2 where GCP logs are centralized.
· Splunk Rule 3 where cloud-hosted Sentry telemetry, GCP network telemetry, backend service logs, or gateway-relevant supporting context are centralized.
Rule Outcome
Conditional Coverage.
Artifact-Based Detection
Primary Rule Coverage
No YARA rule carried forward.
Supporting Rule Coverage
Behavioral endpoint, SIEM, and NDR detections remain primary.
Rule Outcome
Zero-rule system disposition.
Rule Coverage Summary
NDR / Network Behavioral Analytics
Rule Count
3
Coverage Role
Management-server rare egress, east-west deviation, dependency deviation, secure mobile gateway rare egress, Sentry backend dependency deviation, and network anomaly coverage.
SentinelOne
Rule Count
2
Coverage Role
Endpoint execution, service-context child-process activity, file staging, and persistence-relevant activity where endpoint telemetry exists on management-control-plane infrastructure.
Splunk
Rule Count
3
Coverage Role
Cross-domain SIEM correlation across administrative access, endpoint execution, object changes, file activity, Sentry appliance context, backend dependency deviation, and network behavior.
Elastic
Rule Count
2
Coverage Role
ECS-aligned endpoint execution and access-to-network correlation.
QRadar
Rule Count
1
Coverage Role
Consolidated CRE correlation across management-plane access, host activity, network behavior, and object changes.
SIGMA
Rule Count
2
Coverage Role
Portable SIEM logic for suspicious service-context execution and management-plane object changes.
YARA
Rule Count
0
Coverage Role
Zero-rule system disposition.
AWS
Rule Count
1 conditional
Coverage Role
Cloud-hosted management-control-plane activity in AWS.
Azure
Rule Count
1 conditional
Coverage Role
Cloud-hosted management-control-plane activity in Azure.
GCP
Rule Count
1 conditional
Coverage Role
Cloud-hosted management-control-plane activity in GCP.
S25 Package Summary
13 primary rules and 3 conditional cloud rules, with YARA documented as a zero-rule system.
Traceability Assessment
Primary Behavioral Coverage
The rule set provides strong coverage for the report’s primary behavioral model: unusual administrative access, suspicious management-service execution, rare egress, unexpected east-west communication, privileged control-plane object changes, persistence-relevant activity from management infrastructure, and secure mobile gateway dependency deviation.
Correlation Coverage
Splunk, QRadar, Elastic, and the conditional cloud rules provide correlation coverage across administrative access, host execution, network behavior, object changes, cloud-hosted infrastructure activity, Sentry appliance context, and backend dependency deviation where telemetry is available.
Endpoint Coverage
SentinelOne, Elastic, SIGMA, Splunk, and QRadar provide coverage for suspicious child-process execution and file or persistence activity from management service context. Sentry-specific endpoint coverage is conditional because secure mobile gateway appliances may not provide normal EDR, process, Linux audit, or file telemetry.
Network Coverage
NDR provides the primary behavioral network coverage. NDR Rule 3 extends network coverage to Ivanti Sentry and comparable secure mobile gateway assets where Sentry source IPs, asset tags, approved dependencies, and destination baselines are available. Elastic, Splunk, QRadar, AWS, Azure, and GCP provide supporting network correlation where telemetry is available.
Cloud Coverage
AWS, Azure, and GCP provide conditional coverage only where management-control-plane or secure mobile gateway infrastructure is hosted in those environments or where cloud telemetry provides meaningful visibility into the affected management server or gateway appliance.
Artifact Coverage
YARA is documented as a zero-rule system for this report. Detection coverage remains behavior-led.
Coverage Gaps
No Validated Artifact Set for YARA
Impact
Artifact-based detection is not available.
Mitigation Path
Continue behavior-led endpoint, SIEM, and NDR detection.
Limited Application Audit Logging
Impact
Reduced visibility into privileged object changes, administrative workflow abuse, gateway service activity, and appliance-level context.
Mitigation Path
Use proxy, identity, endpoint, Sentry logs, syslog, reverse proxy logs, WAF logs, load balancer logs, backend service logs, and SIEM correlation where application logs are incomplete.
Missing Process Ancestry or Command-Line Capture
Impact
Reduced confidence in service-context execution detections.
Mitigation Path
Prioritize endpoint telemetry coverage on management servers where supported. For secure mobile gateway appliances that do not support normal endpoint telemetry, use Sentry logs, syslog, network telemetry, reverse proxy logs, WAF logs, load balancer logs, backend dependency logs, and SIEM correlation.
Weak Asset-Role Tagging
Impact
Reduced rule fidelity across all systems.
Mitigation Path
Tag MDM, EPMM, endpoint-management, security-management, enterprise administration servers, Ivanti Sentry appliances, secure mobile gateways, enterprise mobility gateways, and mobile access control-plane assets.
Incomplete Network Baselines
Impact
Reduced fidelity for rare egress, east-west deviation, secure mobile gateway dependency deviation, and backend access anomaly detection.
Mitigation Path
Establish vendor, connector, identity, directory, certificate, logging, monitoring, backup, mobile access, backend application, integration, and approved administrative path baselines.
Cloud Telemetry Not Present or Not Relevant
Impact
Reduced AWS, Azure, and GCP applicability.
Mitigation Path
Use cloud detections only where management-control-plane or secure mobile gateway infrastructure is cloud-hosted or where cloud telemetry provides meaningful visibility into the affected asset.
S27 — Behavior & Log Artifacts
Behavioral Artifact Overview
This report prioritizes behavior-led artifacts associated with management-control-plane compromise rather than static CVE-specific indicators. The most useful artifacts are those that show anomalous administrative access, suspicious service-context execution, abnormal management-server communication, privileged object modification, file staging, persistence activity, or conditional cloud-hosted infrastructure abuse.
Administrative Access Artifacts
Relevant Artifacts
· Successful administrative access from unusual source IPs, devices, geographies, ASNs, access paths, or time windows.
· Administrative session creation from an unfamiliar network or identity context.
· Repeated failed access attempts followed by successful administrative access.
· New administrator access patterns inconsistent with prior account behavior.
· Administrative access through VPN, reverse proxy, identity provider, privileged access management, jump host, or vendor-support path outside expected baseline.
Log Sources
· MDM / EPMM administrative logs
· Identity provider logs
· VPN logs
· Reverse proxy logs
· Privileged access management logs
· SIEM authentication logs
· Cloud identity logs where management infrastructure is cloud-hosted
Detection Value
Administrative access artifacts provide important context but should not be treated as standalone compromise evidence unless the access is highly abnormal or followed by suspicious host, network, file, or control-plane behavior.
Management-Service Execution Artifacts
Relevant Artifacts
· Management application service spawning a shell, scripting engine, or administrative utility.
· Java, Tomcat, web-service, application-server, vendor-service, or management-platform process spawning unexpected child processes.
· Service-context execution of network utilities, archive tools, credential-access utilities, service-control commands, or persistence-related tooling.
· Command-line activity inconsistent with normal management-platform operation.
· Process execution by a service account outside expected application workflow.
Log Sources
· EDR process creation telemetry
· SentinelOne Deep Visibility
· Elastic Defend telemetry
· Windows event logs where applicable
· Linux audit logs where applicable
· SIEM-ingested endpoint telemetry
· Process-to-network telemetry where available
Detection Value
Management-service execution artifacts are among the strongest indicators in this report because management application services should not normally initiate interactive shell, scripting, staging, or persistence workflows.
File, Script, and Persistence Artifacts
Relevant Artifacts
· Script creation or modification in application, upload, plugin, extension, temporary, service, startup, scheduled-task, cron, or web-accessible paths.
· Archive staging or compressed file creation on management infrastructure.
· Web-accessible file writes associated with management application directories.
· Service, scheduled-task, cron, startup, launch-agent, or comparable persistence changes.
· Unexpected changes to sensitive configuration files, certificates, API tokens, keystores, or integration secrets.
Log Sources
· EDR file telemetry
· File integrity monitoring
· Windows event logs where applicable
· Linux audit logs where applicable
· Application server logs
· SIEM-ingested file activity
· Endpoint detection telemetry
Detection Value
File and persistence artifacts become higher fidelity when initiated by management-service context or when correlated with unusual administrative access, suspicious process execution, rare egress, or privileged object changes.
Privileged Control-Plane Object Artifacts
Relevant Artifacts
· Administrator account creation, modification, enablement, or role change.
· API token creation, use, rotation, or permission change.
· Certificate, connector, enrollment-profile, device-profile, policy, integration, or platform configuration changes.
· Unexpected policy push or device-management profile modification.
· Administrative changes affecting downstream device behavior or management authority.
Log Sources
· MDM / EPMM application audit logs
· API audit logs
· Administrative action logs
· SIEM application telemetry
· Identity and access-management logs
· Cloud audit logs where infrastructure is cloud-hosted
Detection Value
Privileged control-plane object artifacts are high-value because they may indicate adversary use of legitimate management authority. These artifacts should be correlated with account behavior, source context, timing, and subsequent host or network activity.
Network and Egress Artifacts
Relevant Artifacts
· Rare external destinations contacted by management servers.
· New DNS lookups inconsistent with the management server baseline.
· Outbound communication outside known vendor update paths, connector dependencies, identity services, directory services, logging systems, monitoring systems, backup paths, or approved integrations.
· Beacon-like communication patterns.
· Large, staged, compressed, repeated, or directionally unusual transfers.
· Unexpected east-west communication to internal systems outside the management platform dependency map.
· Use of administrative protocols from management infrastructure to unusual internal destinations.
Log Sources
· NDR telemetry
· Network flow logs
· Proxy logs
· DNS logs
· Firewall logs
· Cloud network logs where applicable
· SIEM-ingested network telemetry
Detection Value
Network artifacts are strongest when asset role and baseline are known. Rare egress or unexpected east-west communication should be enriched before escalation because legitimate vendor, connector, monitoring, backup, and support workflows may overlap with these patterns.
Crash, Fault, and Instability Artifacts
Relevant Artifacts
· Application service restarts.
· Unexpected crash events.
· Web-service or application-server error spikes.
· Repeated failed application operations.
· Management-platform instability near administrative access, API activity, process execution, or network anomalies.
· Abnormal restart patterns affecting the management application or supporting services.
Log Sources
· Application logs
· Web server logs
· System logs
· Service manager logs
· EDR telemetry
· SIEM operational logs
· Cloud monitoring logs where applicable
Detection Value
Crash and fault artifacts are supporting signals. They should not be treated as standalone proof of compromise but can strengthen a broader pattern when paired with suspicious access, execution, file activity, object changes, or outbound communication.
Cloud-Hosted Management Infrastructure Artifacts
Relevant Artifacts
· Unusual cloud administrative activity tied to a management-control-plane asset.
· Cloud identity activity tied to the management asset, instance role, managed identity, service account, subnet, security group, VPC/VNet, project, or administrative workflow.
· Security group, NSG, firewall rule, route, or network policy changes affecting the management asset.
· VM or instance management actions outside expected workflows.
· Rare egress or unexpected internal cloud network communication.
· Relevant cloud security findings associated with the management asset.
Log Sources
· AWS CloudTrail, VPC Flow Logs, Route 53 Resolver DNS logs, GuardDuty, Security Hub, SSM logs
· Azure Activity Logs, Entra ID logs, NSG Flow Logs, Defender for Cloud, Azure Monitor, VM telemetry
· GCP Cloud Audit Logs, VPC Flow Logs, Cloud DNS logs, Security Command Center, IAM and service account logs
· Centralized SIEM or data-lake telemetry
Detection Value
Cloud artifacts are conditional. They are relevant only where management-control-plane infrastructure is hosted in cloud environments or where cloud telemetry provides meaningful visibility into the affected management server.
Artifact Handling Requirements
· Prioritize artifacts tied to tagged management-control-plane assets.
· Correlate administrative access, process execution, file activity, object changes, and network behavior before classifying compromise.
· Treat static indicators as secondary unless validated by authoritative technical reporting.
· Preserve event timing, source identity, destination context, process ancestry, command line, object type, asset role, and baseline deviation during investigation.
· Separate confirmed evidence from inferred post-exploitation behavior.
S28 — Detection Strategy and SOC Implementation Guidance

Figure 5
SOC Implementation Objective
The SOC implementation objective is to convert the behavior-led detection model into practical monitoring across management-control-plane assets. The SOC should prioritize high-trust systems that control users, devices, policies, certificates, connectors, tokens, integrations, and downstream administrative workflows.
Asset Scoping Guidance
Management-control-plane assets must be identified before reliable detection can occur.
Required Asset Scope
· MDM servers
· Ivanti EPMM servers
· Endpoint-management servers
· Security-management servers
· Enterprise administration servers
· Identity-adjacent management systems
· Cloud-hosted management infrastructure where applicable
Implementation Guidance
Asset tags, CMDB records, EDR groups, SIEM lookups, NDR asset groups, and cloud labels should consistently identify management-control-plane systems. Rules should apply elevated detection sensitivity to these systems because their compromise can create downstream enterprise-wide impact.
Detection Deployment Priority
Priority 1
Deploy endpoint execution detections for management application services spawning suspicious child processes.
Priority 2
Deploy SIEM correlation for unusual administrative access followed by suspicious execution, file activity, object changes, rare egress, or service instability.
Priority 3
Deploy NDR analytics for rare egress, unexpected east-west communication, and dependency deviation from management infrastructure.
Priority 4
Deploy application and API audit monitoring for privileged control-plane object changes.
Priority 5
Deploy cloud-hosted management-control-plane detections only where AWS, Azure, or GCP telemetry is relevant to the deployed architecture.
Triage Guidance
SOC review should determine whether the affected system is a tagged management-control-plane asset and whether the activity aligns with expected maintenance, patching, backup, support, connector, monitoring, or administrative automation activity.
Behavior Validation
The analyst should validate whether the alert involves one or more high-value behavior anchors:
· Management-service child-process execution
· Suspicious file or script staging
· Privileged object modification
· Rare egress
· Unexpected east-west communication
· Abnormal API activity
· Application or service instability
Context Enrichment
The analyst should enrich the alert with:
· Asset role
· Internet exposure
· Patch status
· Administrative account history
· Source IP and geography
· Authentication path
· Process ancestry
· Command line
· File path
· Destination domain or IP
· Object type modified
· Maintenance-window status
· Related alerts within the investigation window
Escalation Criteria
Escalation is appropriate when suspicious management-server behavior is paired with abnormal administrative access, service-context execution, file staging, privileged object changes, rare egress, or unexpected internal communication.
High-Priority Escalation Conditions
· Management application process launches a shell, scripting engine, network utility, archive utility, credential-access utility, or persistence tool.
· Unusual administrator access is followed by suspicious execution or file activity.
· Management server communicates with rare external destinations after administrative access.
· Privileged management-plane objects are changed by unusual accounts or sources.
· Management server initiates unexpected east-west communication outside approved dependencies.
· Cloud-hosted management asset shows suspicious identity, compute, or network activity tied to the management asset context.
Investigation Questions
· Was the management platform externally reachable at the time of activity?
· Was the affected asset patched or known to be exposed?
· Was administrative access expected for the user, source, device, and time window?
· Did a management application service spawn suspicious child processes?
· Did the server create scripts, archives, web-accessible files, or persistence artifacts?
· Did privileged objects change near the suspicious activity?
· Did the server contact rare external destinations or unusual internal systems?
· Did cloud telemetry show identity, compute, network, or infrastructure changes tied to the management asset?
· Is there downstream device, policy, connector, certificate, or integration impact?
Response Considerations
Management-control-plane systems are operationally sensitive. Response decisions should account for device enrollment, policy delivery, security configuration, certificates, connectors, integrations, and administrative workflows before disruptive containment actions are taken.
Recommended Response Focus
· Validate administrative accounts, roles, tokens, certificates, connectors, and policies.
· Preserve relevant logs before service restart or remediation.
· Review management-platform integrations and downstream device-impact scope.
· Restrict administrative access to trusted sources where appropriate.
· Coordinate response with platform owners, identity administrators, and infrastructure owners.
Tuning Guidance
Tuning should reduce noise without suppressing high-risk management-server behavior.
Tuning Inputs
· Approved maintenance windows
· Vendor update paths
· Connector dependencies
· Identity and directory-service dependencies
· Monitoring and backup workflows
· Known administrative source networks
· Approved privileged access paths
· Known vendor-support procedures
· Cloud-hosted asset labels and subscriptions, accounts, or projects where applicable
SOC Operating Model
The SOC should treat management-control-plane alerts as high-context events. The same behavior observed on a standard endpoint may be lower priority, but when observed on a management server it can indicate broader enterprise risk because the asset may control devices, policies, tokens, certificates, connectors, and administrative authority.
S29 — Detection Coverage Summary
Coverage Overview
The detection package provides broad behavior-led coverage for exploitation and post-exploitation activity involving MDM and enterprise management control planes. Coverage is strongest when endpoint, SIEM, NDR, application, identity, and cloud telemetry can be correlated around tagged management-control-plane assets.
Primary Coverage Areas
Administrative Access Coverage
The rule set covers unusual administrative access through Splunk, QRadar, Elastic, and conditional cloud rules. Coverage improves when identity, proxy, VPN, privileged access, and application logs are available.
Management-Service Execution Coverage
The rule set provides strong coverage for management application services spawning suspicious child processes through SentinelOne, Elastic, SIGMA, Splunk, and QRadar.
File and Persistence Coverage
The rule set provides strong coverage for suspicious file, script, archive, and persistence-relevant activity through SentinelOne, Splunk, QRadar, and supporting SIGMA logic.
Network Anomaly Coverage
The rule set provides strong coverage for rare egress, unexpected east-west communication, and dependency deviation through NDR, Elastic, Splunk, QRadar, and conditional cloud rules where telemetry is available.
Privileged Object-Change Coverage
The rule set provides strong coverage for administrator, role, certificate, connector, token, enrollment-profile, policy, integration, and platform configuration changes through Splunk, SIGMA, QRadar, and supporting Elastic logic.
Cloud-Hosted Coverage
The rule set provides conditional coverage for AWS, Azure, and GCP where management-control-plane infrastructure is hosted in cloud environments or where cloud telemetry provides meaningful visibility into the affected asset.
Coverage Strengths
· Strong behavior-led detection across endpoint, SIEM, NDR, and cloud telemetry.
· Strong coverage for suspicious service-context execution.
· Strong correlation coverage for unusual access followed by abnormal server behavior.
· Strong network coverage for rare egress and unexpected east-west communication.
· Strong object-change coverage where application or API audit logs are available.
· Conditional cloud coverage across AWS, Azure, and GCP.
· Low dependency on static indicators, exploit payloads, scanner names, attacker infrastructure, or one vendor-specific exploit path.
Coverage Constraints
· Detection quality depends on management-control-plane asset tagging.
· Application audit log availability varies by platform and deployment.
· Process ancestry and command-line capture are required for high-confidence execution detection.
· Network anomaly detection depends on known baselines for vendor, connector, identity, directory, logging, monitoring, backup, and integration paths.
· Cloud coverage applies only when management infrastructure is cloud-hosted or cloud telemetry provides meaningful visibility.
· Artifact-based detection is not available through YARA for this report.
Coverage by Rule Family
NDR / Network Behavioral Analytics
Covers rare egress, east-west deviation, dependency deviation, and management-server network anomalies.
SentinelOne
Covers suspicious endpoint execution, service-context child-process activity, file staging, and persistence-relevant behavior.
Splunk
Covers cross-domain SIEM correlation across administrative access, endpoint execution, object changes, file activity, and network behavior.
Elastic
Covers ECS-aligned process execution and administrative-access-to-network correlation.
QRadar
Covers consolidated correlation across management-plane access, host activity, network behavior, and privileged object changes.
SIGMA
Covers portable SIEM logic for suspicious service-context execution and management-plane object changes.
AWS
Provides conditional coverage for AWS-hosted management-control-plane activity.
Azure
Provides conditional coverage for Azure-hosted management-control-plane activity.
GCP
Provides conditional coverage for GCP-hosted management-control-plane activity.
YARA
Carries no rule for this report because validated artifact evidence is not available.
Detection Coverage Conclusion
The detection package provides strong behavioral coverage for management-control-plane exploitation and post-exploitation activity. The highest-confidence coverage is achieved when administrative access, service-context execution, file activity, privileged object changes, and network behavior are correlated around tagged management-control-plane assets.
CVE-2026-10520 — Ivanti Sentry OS Command Injection Vulnerability is covered with adaptation by this report’s behavior-led detection model. The original report did not directly name Ivanti Sentry or CVE-2026-10520, but the amended NDR and Splunk rules extend coverage to secure mobile gateway assets by detecting rare egress, backend dependency deviation, suspicious gateway activity, and supporting appliance or backend context. Coverage depends on Sentry asset-role tagging, source IP mapping, approved dependency baselines, Sentry logs or syslog where available, network telemetry, backend service logs, and validated supporting-context enrichment.
S30 — Intelligence Maturity Assessment
Assessment Overview
The intelligence maturity for this report is assessed as moderate-to-high for behavioral detection and moderate for exploit-specific technical characterization. The case trigger establishes active-exploitation relevance, but the strongest defensive value comes from behavior-led detection across management-control-plane abuse patterns rather than static exploit artifacts.
Current Intelligence Maturity
Behavioral Intelligence
Maturity Level
High
Assessment
The behavioral model is mature because it is based on durable post-access and post-exploitation behaviors: unusual administrative access, management-service child-process execution, rare egress, unexpected east-west communication, privileged object changes, and suspicious file or persistence activity.
Detection Engineering Intelligence
Maturity Level
Moderate-to-High
Assessment
The detection engineering model is strong because S25 provides coverage across NDR / Network Behavioral Analytics, SentinelOne, Splunk, Elastic, QRadar, SIGMA, and conditional cloud platforms. Maturity is assessed as moderate-to-high rather than high because detection quality depends on telemetry availability, field normalization, asset-role tagging, baseline maturity, and implementation quality.
Exploit-Specific Intelligence
Maturity Level
Moderate
Assessment
Exploit-specific maturity is limited because durable exploit-path indicators, validated payload structures, and artifact-level details are not available in the current report scope. The detection strategy therefore avoids overfitting to unconfirmed exploit mechanics.
Artifact Intelligence
Maturity Level
Low
Assessment
Artifact intelligence is limited because no validated malware sample, webshell pattern, file artifact, memory artifact, payload structure, or confirmed malicious script is available for YARA-based detection.
Telemetry Intelligence
Maturity Level
Moderate-to-High
Assessment
Telemetry maturity is strong where endpoint process telemetry, administrative authentication logs, application audit logs, NDR telemetry, SIEM correlation, and cloud logs are available. Maturity decreases where application logs, process ancestry, command-line capture, asset-role tagging, or network baselines are incomplete.
Cloud Intelligence
Maturity Level
Conditional
Assessment
Cloud intelligence is mature only where the affected management-control-plane infrastructure is hosted in AWS, Azure, or GCP, or where cloud telemetry provides meaningful visibility into the management asset. Cloud detections should remain conditional and architecture-dependent.
Attribution Intelligence
Maturity Level
Low
Assessment
Attribution maturity is low because this report does not require or assert a specific adversary, campaign, intrusion set, or nation-state actor. Detection and response should remain behavior-led unless authoritative attribution becomes available.
Confidence Assessment
High Confidence
· Management-control-plane assets require elevated detection sensitivity.
· Suspicious management-service child-process execution is a high-value detection anchor.
· Unusual administrative access followed by abnormal server behavior is a strong correlation pattern.
· Rare egress and unexpected east-west communication from management infrastructure are meaningful post-access signals when baseline context exists.
· Privileged control-plane object changes are high-value signals when paired with unusual source, account, timing, or downstream behavior.
Moderate Confidence
· Crash, fault, and service-instability artifacts can support investigation when correlated with stronger signals.
· Cloud-hosted management-control-plane detections are valuable where AWS, Azure, or GCP telemetry is available and properly tied to the affected asset.
· Application and API logs can provide strong visibility, but availability and field quality vary by platform.
Low Confidence
· Static artifact detection is not currently viable.
· Actor attribution is not established.
· CVE-specific detection logic should not be prioritized without durable, validated exploit indicators.
Intelligence Gaps
Exploit Path Specificity
The current detection model does not depend on detailed exploit-path indicators. This is appropriate for durability but limits exploit-specific confirmation.
Artifact Availability
No validated artifact set is available for YARA or static file-content detection.
Application Audit Completeness
Application and API audit coverage may vary across management platforms and deployments.
Baseline Maturity
Detection quality depends on baselines for administrator behavior, expected management-console activity, vendor update paths, connector dependencies, identity services, directory services, and normal management-server communication.
Cloud Architecture Dependency
AWS, Azure, and GCP coverage depends on whether management infrastructure is cloud-hosted or whether cloud telemetry provides meaningful visibility into the management server.
Maturity Improvement Priorities
· Improve asset-role tagging for management-control-plane systems.
· Centralize administrative authentication and application audit logs.
· Ensure endpoint telemetry captures process ancestry and command line on management servers.
· Establish network baselines for vendor, connector, identity, directory, logging, monitoring, backup, and integration dependencies.
· Correlate NDR, SIEM, endpoint, application, and cloud telemetry around management-control-plane assets.
· Reassess artifact-based detection only if validated files, scripts, payloads, or memory artifacts become available.
· Maintain behavior-led detection until exploit-specific indicators are durable and authoritative.
Intelligence Maturity Conclusion
The report has strong behavioral maturity, moderate-to-high detection-engineering maturity, moderate exploit-specific maturity, and low artifact maturity. This supports a behavior-led EXP report focused on management-control-plane compromise rather than a single-CVE or artifact-driven detection package.
S31 — Telemetry Dependencies
Effective detection and response for [EXP] Active Exploitation of MDM and Enterprise Management Control Planes depends on the organization’s ability to identify management-control-plane assets, preserve administrative activity, observe management-server behavior, monitor privileged object changes, and correlate downstream device-management impact.
The most important dependency is asset-role clarity. MDM, EPMM, endpoint-management, security-management, and enterprise administration platforms must be tagged and treated as high-trust control-plane infrastructure, not as ordinary application servers.
Required Telemetry Dependencies
· Asset inventory and asset-role tagging for MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Administrative authentication logs for management consoles, administrative interfaces, APIs, VPN paths, privileged access workflows, jump hosts, and identity-provider access.
· Management-platform audit logs covering administrator accounts, roles, policies, certificates, connectors, enrollment profiles, API tokens, integrations, device-management profiles, and platform configuration objects.
· Endpoint process telemetry from management servers, including parent-child process relationships, process names, command lines, process paths, execution users, service-account context, and process-to-network mapping where available.
· File and persistence telemetry from management servers, including file creation, file modification, script staging, archive creation, web-accessible writes, service modification, scheduled tasks, startup entries, cron jobs, and sensitive configuration access.
· Network telemetry from management servers, including DNS, proxy, firewall, NDR, flow records, destination IPs, domains, ASNs, ports, protocols, session timing, byte counts, external egress, and east-west communication.
· Baseline data for expected administrator behavior, approved source networks, vendor update paths, connector dependencies, identity-service traffic, directory-service traffic, certificate-service traffic, logging paths, monitoring systems, backup systems, and approved integrations.
· SIEM correlation across administrative authentication, management-platform events, endpoint events, file events, network events, identity events, and cloud telemetry where applicable.
· Downstream device-management telemetry where available, including policy pushes, enrollment changes, certificate distribution changes, device-profile changes, compliance-state changes, device actions, and application deployment activity.
· Cloud telemetry where management-control-plane infrastructure is hosted in AWS, Azure, or GCP, including audit logs, identity activity, compute activity, network flow logs, DNS logs, security findings, and resource-tag context.
Minimum Viable Telemetry
· Asset-role tagging for management-control-plane systems.
· Administrative authentication logs.
· Endpoint process telemetry from management servers.
· Network egress or DNS visibility from management servers.
· Management-platform audit logs or equivalent application activity records where available.
Preferred Telemetry State
· Correlation across management-platform logs, administrative authentication, endpoint process telemetry, file telemetry, NDR or network telemetry, proxy or DNS records, cloud telemetry where applicable, identity logs, and downstream device-management evidence.
· Baselines that distinguish normal management-platform behavior from suspicious post-access activity.
· Retention sufficient to support historical compromise review for systems exposed before remediation.
· Enrichment that links management actions to users, devices, groups, certificates, connectors, policies, applications, business units, and downstream dependencies.
S32 — Detection Limitations
Detection limitations are primarily driven by incomplete management-platform visibility, weak asset-role tagging, and limited ability to distinguish normal administrative workflows from adversary control-plane abuse. Exposure, scanning, administrative login anomalies, service instability, and rare egress should not be treated as confirmed compromise without supporting evidence.
The original exploit attempt may not be visible in every environment. Detection confidence depends on correlated post-access behavior, including suspicious management-server execution, privileged object changes, file staging, rare outbound communication, unexpected east-west traffic, connector misuse, persistence-relevant activity, or downstream device-management impact.
Primary Detection Limitations
· Exposure-only findings do not confirm compromise.
· Administrative access anomalies require supporting post-access evidence before compromise classification.
· Rare outbound communication requires enrichment against vendor update paths, connector dependencies, monitoring systems, logging systems, backup systems, and approved integrations.
· Application errors, service instability, crash events, and failed requests are supporting signals unless paired with suspicious access, execution, file activity, privileged object changes, or abnormal communication.
· Missing asset-role tagging reduces detection fidelity across every telemetry source.
· Missing application audit logs limits visibility into administrator accounts, roles, connectors, certificates, enrollment profiles, API tokens, policies, integrations, and platform configuration changes.
· Missing process ancestry weakens confidence in management-service execution detections.
· Missing command-line telemetry reduces the ability to distinguish suspicious tooling from approved administrative automation.
· Missing file telemetry limits detection of script staging, web-accessible writes, archive creation, service modification, scheduled tasks, startup changes, and sensitive configuration access.
· Missing network flow, DNS, proxy, or NDR telemetry limits detection of rare egress, beacon-like behavior, staged transfer activity, and unexpected east-west communication.
· Weak baselines for administrator behavior, maintenance windows, connector behavior, vendor update paths, and management-server communication increase false-positive risk.
· Cloud detection coverage is conditional and should only be applied where management-control-plane infrastructure is hosted in AWS, Azure, or GCP, or where cloud telemetry provides meaningful visibility.
· Artifact-based detection is limited because no validated malware sample, payload structure, webshell pattern, memory artifact, or confirmed malicious script is established for YARA-style coverage.
· Legitimate patching, vendor support, backup workflows, monitoring activity, connector synchronization, certificate renewal, device enrollment, policy rollout, vulnerability scanning, and administrative automation may overlap with suspicious behavior.
· Confirmation requires correlation across authentication, application, endpoint, file, network, cloud, identity, or configuration-change evidence.
S33 — Defensive Control & Hardening Improvements
Defensive improvement should focus on reducing exposure, protecting management-platform authority, improving telemetry fidelity, and limiting downstream blast radius. The highest-priority control objective is to prevent exposed management infrastructure from becoming a trusted adversary operating position.
Hardening should not rely only on patch completion. Systems exposed before remediation require historical compromise review, administrative-object validation, connector review, certificate and token assurance, device-policy validation, and management-server behavior review.
Priority Defensive Improvements
· Maintain an authoritative inventory of MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Tag management-control-plane assets in CMDB, EDR, SIEM, NDR, cloud inventory, vulnerability management, and exposure-management systems.
· Restrict management-console and administrative API access to trusted administrative networks, privileged access paths, controlled jump infrastructure, or approved identity-provider workflows.
· Remove public internet exposure for management consoles, administrative APIs, enrollment administration, and supporting application services unless explicitly required and compensating controls are validated.
· Enforce MFA and strong conditional access for all management-platform administrators.
· Restrict administrative access by source network, device posture, privileged access workflow, account role, session context, and maintenance window.
· Review administrator accounts, roles, service accounts, API tokens, certificates, connectors, enrollment profiles, device-management profiles, policies, integrations, and platform configuration objects.
· Rotate or revoke exposed, stale, unused, suspicious, or over-privileged API tokens, certificates, connector credentials, service-account credentials, integration secrets, and keystore material.
· Establish baselines for administrator behavior, management-console access, vendor update paths, connector dependencies, identity-service communication, directory-service communication, certificate-service traffic, logging paths, monitoring systems, backup systems, and approved integrations.
· Enable detailed administrative audit logging and API activity logging where supported by the platform.
· Enable endpoint process telemetry, command-line capture, process ancestry, file telemetry, and persistence telemetry on management servers.
· Monitor management application services, Java processes, Tomcat processes, web-service processes, application-server processes, vendor services, and management-platform service accounts for suspicious child-process activity.
· Monitor management servers for rare outbound communication, unexpected east-west communication, staged transfer behavior, beacon-like communication, and dependency deviation.
· Validate that security policies, compliance policies, enrollment workflows, device profiles, certificate distribution, connector settings, and application deployment behavior remain authorized.
· Preserve logs from exposed systems before remediation and perform retrospective review across the exposure window.
· Segment management-plane infrastructure from ordinary server trust zones using role-specific access controls.
· Apply least privilege to administrator accounts, service accounts, connectors, API tokens, certificates, and integration identities.
· Require escalation review for unexpected policy pushes, enrollment changes, device actions, certificate changes, connector changes, and administrative-role modifications.
· Test incident-response procedures for management-platform isolation, connector credential rotation, token revocation, certificate revocation, device-policy rollback, and downstream device assurance.
S34 — Defensive Control & Hardening Architecture

Figure 6
The defensive architecture should treat MDM, EPMM, endpoint-management, security-management, and enterprise administration platforms as high-trust control-plane systems. These assets require stronger exposure control, stricter access governance, deeper telemetry, and faster escalation paths because they may influence devices, policies, certificates, connectors, and downstream enterprise integrations.
The architecture should combine exposure reduction, identity control, network segmentation, telemetry coverage, privileged-object governance, device assurance, and response readiness. Defensive design should assume that a compromised management platform may be used to issue legitimate-looking actions through trusted workflows.
Control-Plane Asset Layer
· Maintain a dedicated inventory of management-control-plane assets.
· Apply consistent asset-role tags across EDR, SIEM, NDR, cloud, vulnerability management, CMDB, and exposure-management systems.
· Track platform owner, business owner, exposure status, patch status, device-fleet scope, connector dependencies, certificate dependencies, and downstream integration scope.
· Assign elevated criticality to systems that manage regulated users, executive devices, privileged endpoints, large mobile fleets, certificate distribution, identity-adjacent integrations, or security tooling.
Access Control Layer
· Restrict administrative access to approved networks, privileged access management workflows, jump hosts, identity-provider controls, and approved administrator devices.
· Enforce MFA, conditional access, device posture requirements, and session logging for administrators.
· Separate human administrator accounts from service accounts, connector identities, automation identities, and break-glass accounts.
· Minimize administrator roles, API scopes, connector privileges, and service-account permissions.
Network Segmentation Layer
· Place management-control-plane systems in restricted network segments.
· Limit inbound access to required administrative paths only.
· Limit outbound communication to approved vendor update paths, connector dependencies, identity services, directory services, certificate services, logging systems, monitoring systems, backup services, and approved integrations.
· Monitor east-west communication from management servers for dependency deviation or unauthorized internal access.
Telemetry and Correlation Layer
· Collect administrative authentication, application audit, API activity, endpoint process, file activity, persistence, DNS, proxy, firewall, NDR, identity, and cloud telemetry where applicable.
· Normalize logs into SIEM with consistent asset-role context.
· Correlate administrative access with endpoint execution, privileged object changes, file activity, rare egress, service instability, and downstream device-management impact.
· Retain logs long enough to support historical compromise review after emergency remediation.
Privileged Object Governance Layer
· Track administrator accounts, roles, certificates, connectors, API tokens, enrollment profiles, device-management profiles, policies, integrations, and platform configuration objects.
· Require approval and logging for creation, modification, rotation, disablement, export, or deletion of privileged management-plane objects.
· Alert on privileged object changes outside maintenance windows or from unusual accounts, sources, devices, or access paths.
Device and Downstream Assurance Layer
· Validate downstream policy state, certificate distribution, enrollment changes, compliance status, application deployment, device actions, and connector activity.
· Map management-platform actions to users, devices, groups, applications, certificates, connectors, and business units.
· Prepare rollback procedures for unauthorized policy pushes, enrollment-profile changes, device-profile changes, certificate changes, connector changes, or device actions.
Response Readiness Layer
· Maintain procedures for management-server isolation, application log preservation, administrative account review, credential rotation, certificate revocation, token revocation, connector rebuilds, policy rollback, and device-fleet assurance.
· Define escalation criteria for suspicious administrative access followed by management-server misuse, privileged object changes, rare egress, persistence activity, or downstream device impact.
· Coordinate incident response across security operations, endpoint engineering, identity, mobility, infrastructure, cloud, legal, communications, and business owners.
S35 — Defensive Control Mapping Matrix
Control Area
Asset Identification and Exposure Governance
Mapped Risk
Unknown or misclassified management-control-plane assets reduce detection fidelity and delay remediation.
Control Objective
Ensure every MDM, EPMM, endpoint-management, security-management, and enterprise administration system is identified, owned, tagged, and prioritized as high-trust infrastructure.
Recommended Improvements
· Create a dedicated inventory of management-control-plane assets.
· Tag assets consistently across CMDB, SIEM, EDR, NDR, cloud, vulnerability management, and exposure-management tools.
· Track exposure status, patch status, device-fleet scope, connector dependencies, certificate dependencies, and administrative owner.
· Prioritize internet-facing or externally reachable management platforms for emergency review.
Control Area
Administrative Access Control
Mapped Risk
Unauthorized or weakly governed administrative access may enable control-plane abuse.
Control Objective
Restrict and monitor administrative access to management platforms.
Recommended Improvements
· Enforce MFA and conditional access for all management-platform administrators.
· Restrict access to approved administrator networks, jump hosts, privileged access workflows, and trusted devices.
· Review administrator accounts, roles, break-glass accounts, service accounts, and API scopes.
· Monitor unusual source IPs, geographies, ASNs, devices, access paths, and time windows.
Control Area
Privileged Management-Plane Object Governance
Mapped Risk
Unauthorized changes to accounts, roles, certificates, connectors, tokens, policies, profiles, or integrations may create persistence, privilege expansion, or downstream impact.
Control Objective
Control, log, and review privileged management-plane object changes.
Recommended Improvements
· Require change approval for administrator accounts, roles, certificates, connectors, API tokens, enrollment profiles, policies, integrations, and platform configuration objects.
· Alert on sensitive object changes outside approved windows.
· Review suspicious creation, modification, rotation, disablement, export, or deletion events.
· Map object changes to the responsible user, source, device, business purpose, and affected downstream scope.
Control Area
Management-Server Execution Control
Mapped Risk
Management application services may be abused to launch shells, scripts, network utilities, archive tools, credential utilities, or persistence mechanisms.
Control Objective
Detect and restrict suspicious execution from management-server service context.
Recommended Improvements
· Enable endpoint process telemetry and command-line capture on management servers.
· Monitor Java, Tomcat, web-service, application-server, vendor-service, and management-platform service processes for suspicious child-process activity.
· Establish exceptions for approved patching, backup, monitoring, support, connector, and administrative automation workflows.
· Investigate unexpected shells, scripting engines, network utilities, archive utilities, credential utilities, service-control commands, or persistence tools.
Control Area
File and Persistence Monitoring
Mapped Risk
Attackers may stage scripts, archives, web-accessible files, service changes, scheduled tasks, startup entries, or sensitive configuration access on management infrastructure.
Control Objective
Identify suspicious file and persistence activity on management servers.
Recommended Improvements
· Enable file creation, modification, deletion, rename, permission, and hash telemetry where available.
· Monitor upload paths, plugin paths, extension paths, temporary directories, application directories, service paths, scheduled-task paths, startup locations, cron paths, and sensitive configuration locations.
· Prioritize activity initiated by management-platform service context or unusual administrative sessions.
· Correlate file activity with administrative access, suspicious execution, rare egress, privileged object changes, or service instability.
Control Area
Network Egress and East-West Control
Mapped Risk
Compromised management servers may communicate with rare external destinations or initiate unexpected internal connections.
Control Objective
Limit and monitor management-server communication outside approved dependencies.
Recommended Improvements
· Baseline vendor update paths, connector dependencies, identity services, directory services, certificate services, logging systems, monitoring systems, backup paths, and approved integrations.
· Monitor rare external egress, new DNS patterns, staged transfer behavior, beacon-like communication, and unexpected east-west communication.
· Restrict outbound communication to approved dependencies where feasible.
· Investigate management-server traffic that deviates from expected operational architecture.
Control Area
Connector, Certificate, and Token Assurance
Mapped Risk
Connector credentials, certificates, API tokens, keystores, service accounts, and integration secrets may expand adversary reach beyond the management server.
Control Objective
Reduce credential, certificate, token, and connector blast radius.
Recommended Improvements
· Inventory certificates, API tokens, connector credentials, keystores, database credentials, integration secrets, and service-account credentials.
· Rotate or revoke stale, unused, over-privileged, exposed, or suspicious credentials.
· Restrict connector permissions to least privilege.
· Review connector changes, token activity, certificate distribution, and integration behavior after exposure.
Control Area
Downstream Device and Policy Assurance
Mapped Risk
Unauthorized management actions may affect devices, users, policies, profiles, certificates, applications, or compliance state.
Control Objective
Validate that downstream management actions remain authorized and scoped.
Recommended Improvements
· Review policy pushes, enrollment changes, device-profile changes, certificate distribution, device actions, compliance-state changes, and application deployment activity.
· Map management actions to affected devices, users, groups, applications, certificates, connectors, and business units.
· Prepare rollback procedures for unauthorized policy or profile changes.
· Prioritize executive, regulated-user, privileged-user, contractor, BYOD, and high-value operational device populations.
Control Area
Cloud-Hosted Management Infrastructure
Mapped Risk
Cloud-hosted management servers may be exposed through cloud ingress, identity misconfiguration, permissive security groups, route changes, or insufficient cloud telemetry.
Control Objective
Apply cloud-specific visibility and control where management infrastructure is hosted in AWS, Azure, or GCP.
Recommended Improvements
· Tag cloud-hosted management assets and map them to instances, identities, subnets, security groups, VPCs or VNets, projects, subscriptions, and regions.
· Collect cloud audit logs, identity logs, compute logs, network flow logs, DNS logs, and cloud security findings.
· Monitor unusual identity activity, security group or NSG changes, route changes, SSM or Run Command activity, VM extension changes, firewall changes, and rare cloud egress.
· Correlate cloud events with endpoint, application, administrative, and network telemetry.
S36 — CyberDax Intelligence Maturity Assessment
Current Intelligence Maturity
Moderate to High.
The report has a strong behavior-led defensive model because it is anchored to management-control-plane behavior rather than static exploit artifacts. Intelligence maturity is strongest where organizations can correlate administrative access, application audit logs, endpoint execution, file activity, network telemetry, privileged object changes, and cloud telemetry around tagged management-control-plane assets.
The maturity rating is constrained by uncertainty around actor attribution, lack of a validated artifact set for YARA-style detection, variability in MDM and EPMM logging quality, and inconsistent visibility across application, endpoint, network, cloud, and downstream device-management systems.
Maturity Strengths
· The report uses a behavior-led model that remains resilient when exploit paths, payloads, infrastructure, and public indicators change.
· The detection strategy prioritizes management-service execution, unusual administrative access followed by abnormal behavior, privileged object changes, rare egress, and east-west deviation.
· The defensive model treats management platforms as high-trust control-plane infrastructure rather than ordinary application servers.
· Conditional cloud coverage is limited to environments where AWS, Azure, or GCP telemetry provides meaningful visibility.
· YARA is not forced without a validated artifact, malware sample, payload structure, script, or memory pattern.
· The report avoids over-attribution to a named actor or intrusion set without authoritative reporting.
Maturity Constraints
· Confirmed actor attribution is not established.
· A complete post-exploitation playbook is not confirmed.
· Native application logging varies across platforms and deployments.
· Administrative action logs, API logs, session source data, and object-change records may be incomplete.
· Endpoint process ancestry and command-line telemetry may be missing or inconsistent.
· File and persistence telemetry may be limited on management servers.
· Network, DNS, proxy, and east-west visibility may be incomplete.
· Asset-role tagging may be immature or inconsistent.
· Management-server communication baselines may be poorly documented.
· Connector, certificate, token, and downstream integration dependencies may not be fully mapped.
· Cloud telemetry is conditional and may not apply to all deployments.
Recommended Maturity Target
High.
To reach high maturity, organizations should establish reliable asset-role tagging, administrative audit coverage, endpoint process telemetry, file telemetry, network and DNS visibility, privileged object monitoring, connector dependency mapping, certificate and token inventory, SIEM correlation, and downstream device-management assurance for management-control-plane systems.
Maturity Advancement Requirements
· Maintain authoritative management-control-plane asset inventory.
· Enforce consistent asset-role tagging across security and infrastructure platforms.
· Enable administrative action logging and API logging where supported.
· Capture endpoint process ancestry and command-line telemetry from management servers.
· Collect file and persistence telemetry from management infrastructure.
· Baseline approved management-server outbound and east-west communication.
· Map connector, certificate, token, identity, directory, logging, monitoring, backup, and cloud dependencies.
· Centralize logs in SIEM with normalized asset-role context.
· Correlate suspicious administrative access with endpoint execution, file activity, privileged object changes, rare egress, service instability, and downstream device impact.
· Test response procedures for management-server isolation, credential rotation, certificate revocation, connector rebuilds, policy rollback, and device-fleet assurance.
S37 — Strategic Defensive Improvements
Strategic improvement should focus on reducing management-control-plane exposure, strengthening administrative trust, improving telemetry depth, and limiting downstream blast radius. The long-term objective is to make MDM, EPMM, endpoint-management, security-management, and enterprise administration platforms defensible as high-trust infrastructure.
Strategic Priority 1 — Establish Management-Control-Plane Governance
· Create a formal governance category for MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Assign executive ownership, technical ownership, security ownership, and business ownership for each platform.
· Require asset-role tagging, criticality classification, exposure tracking, patch tracking, and dependency mapping.
· Treat high-trust management platforms as Tier 0 or Tier 1 operational infrastructure where appropriate.
Strategic Priority 2 — Reduce Exposure and Administrative Attack Surface
· Remove public internet exposure for administrative interfaces wherever feasible.
· Restrict management-console and administrative API access to controlled administrative paths.
· Require MFA, conditional access, privileged access management, device posture, and session logging for administrators.
· Eliminate stale administrator accounts, excessive roles, unused API tokens, obsolete connectors, and unnecessary integration privileges.
Strategic Priority 3 — Harden Connector, Certificate, and Token Management
· Maintain a current inventory of certificates, API tokens, connector credentials, keystores, integration secrets, service accounts, and database credentials.
· Apply least privilege to connectors, service accounts, API scopes, and integration identities.
· Rotate or revoke stale, over-privileged, exposed, or suspicious credentials.
· Validate certificate distribution, token use, connector behavior, and integration activity after exposure events.
Strategic Priority 4 — Improve Behavior-Led Detection Coverage
· Prioritize management-server process ancestry, command-line capture, file telemetry, persistence telemetry, administrative audit logs, network telemetry, DNS logs, proxy logs, and NDR visibility.
· Correlate administrative access with suspicious host execution, privileged object changes, file staging, rare egress, service instability, and downstream device impact.
· Use asset-role context as a severity multiplier for management-control-plane detections.
· Avoid reliance on CVE strings, exploit paths, static indicators, scanner infrastructure, or artifact-only logic.
Strategic Priority 5 — Build Dependency and Baseline Intelligence
· Baseline administrator behavior, access sources, maintenance windows, vendor update paths, connector dependencies, directory-service dependencies, identity-service dependencies, certificate-service traffic, logging flows, monitoring flows, backup paths, and approved integrations.
· Maintain dependency maps for each management platform.
· Identify expected communication patterns for management servers before an incident occurs.
· Use baseline deviations to prioritize investigation and response.
Strategic Priority 6 — Strengthen Response Readiness
· Prepare playbooks for management-server isolation, forensic preservation, administrator account review, token rotation, certificate revocation, connector rebuilds, service-account reset, policy rollback, and device-fleet assurance.
· Define escalation criteria for suspicious administrative access followed by management-server misuse, privileged object changes, abnormal outbound communication, persistence activity, or downstream device impact.
· Coordinate response across security operations, identity, endpoint engineering, mobility, infrastructure, cloud, legal, communications, and business owners.
· Test incident scenarios involving management-platform compromise and downstream device-trust erosion.
Strategic Priority 7 — Improve Assurance for Downstream Device Impact
· Establish procedures to validate device policies, enrollment profiles, certificate distribution, compliance state, application deployment, device actions, and connector behavior.
· Map management actions to users, devices, groups, applications, certificates, connectors, and business units.
· Prioritize assurance for executive devices, regulated-user devices, privileged-user devices, contractor devices, BYOD devices, and high-value operational populations.
· Maintain rollback and remediation procedures for unauthorized policy, profile, certificate, connector, application, or device-action changes.
S38 — Attack Economics & Organizational Impact Model

Figure 7
Adversary Cost Advantage
[EXP] Active Exploitation of MDM and Enterprise Management Control Planes creates favorable attack economics when exposed management infrastructure is reachable from untrusted paths. Attackers can focus on externally visible or otherwise reachable MDM, EPMM, endpoint-management, security-management, and enterprise administration platforms without first gaining access to an ordinary endpoint, user workstation, phishing path, or downstream application.
The attacker advantage is strongest where organizations expose management consoles, administrative APIs, enrollment workflows, or supporting application services to the public internet, cloud ingress, permissive routing paths, partner access paths, VPN-adjacent paths, or other semi-trusted access routes. The advantage increases when defenders cannot rapidly distinguish exposed infrastructure from attempted exploitation, probable exploitation, and confirmed compromise.
Attackers gain additional leverage because management platforms may already hold trusted authority over devices, users, certificates, policies, connectors, API tokens, service accounts, enrollment workflows, and downstream integrations. Successful access to the management layer can reduce attacker effort by turning an existing enterprise administration platform into a potential operating position.
Defender Cost Disadvantage
Defender cost is elevated because the management platform is both the affected asset and the trusted administrative control layer under review. If exploitation is suspected, response may require more than patching, mitigation, or access restriction. The organization may need to validate management-server integrity, review administrative activity, inspect privileged object changes, reconstruct policy and enrollment timelines, validate connector behavior, rotate tokens and credentials, review certificate distribution, assess downstream device actions, and hunt for abnormal management-server communication.
The cost disadvantage increases when telemetry is incomplete, administrative audit logs are short-retained, platform object changes are poorly linked to approved maintenance, connector dependencies are not documented, certificate and token inventories are incomplete, or affected systems manage large mobile-device, endpoint, executive-device, contractor-device, BYOD, or regulated-user populations.
Operational Leverage for Attackers
Successful compromise of a management-control-plane platform can provide attackers with outsized operational leverage. A compromised or abused management platform may affect device policy, certificate distribution, enrollment workflows, connector behavior, administrator trust, compliance state, application deployment, security tooling, and downstream identity-adjacent integrations.
Attackers do not need to immediately demonstrate broad downstream compromise to create organizational impact. Suspicious administrative access followed by management-server misuse, privileged object changes, certificate or token exposure, connector misuse, abnormal outbound communication, persistence-relevant activity, or downstream device-management anomalies can trigger incident-response escalation, emergency change activity, workforce-impact review, legal readiness, and executive governance.
Organizational Impact Model
The organizational impact model should be based on exposure, evidence strength, management-platform role, device-fleet scope, telemetry confidence, privileged-object integrity, connector dependency, certificate and token exposure, and downstream device-management impact.
Low Impact
Low impact applies when affected management platforms were not externally reachable, access was restricted to trusted paths, remediation was completed quickly, logs are preserved, suspicious administrative access is not observed, and no management-server misuse, privileged object change, certificate or token exposure, connector misuse, abnormal outbound communication, persistence activity, or downstream device action is linked to the exposure.
Organizational impact remains meaningful because the organization must still validate inventory, exposure state, mitigation status, telemetry retention, administrative activity, privileged object integrity, connector state, certificate and token posture, and historical activity during the active exploitation window.
Moderate Impact
Moderate impact applies when one or more affected management platforms were reachable from untrusted paths, suspicious administrative access occurred, telemetry is incomplete, or limited privileged object changes, management-server anomalies, connector activity, file staging, rare egress, or downstream device-management events require investigation without confirmed large-scale device manipulation or sustained adversary control.
Organizational impact may include incident-response mobilization, management-server isolation planning, administrator account review, token and certificate validation, connector review, policy and enrollment reconstruction, device-fleet scoping, selective downstream hunting, legal readiness, workforce communications planning, customer assurance planning, and executive coordination.
High Impact
High impact applies when management-control-plane compromise is confirmed or strongly suspected, unauthorized administrative influence is identified, certificate or API-token exposure is present, connector misuse is observed, security or compliance policy manipulation occurs, downstream device actions are linked to suspicious activity, or historical telemetry is insufficient to scope the exposure with confidence.
Organizational impact may include management-platform isolation, server rebuild or migration, emergency policy freezes, certificate revocation and reissuance, API-token and connector credential rotation, privileged account reset at scale, device re-enrollment, mobile-fleet assurance campaigns, identity and directory review, downstream compromise assessment, legal and regulatory review, cyber-insurance engagement, workforce productivity coordination, customer assurance, and board-level governance.
Economic Pressure Points
· Number of affected MDM, EPMM, endpoint-management, security-management, and enterprise administration systems.
· Duration of exposure before remediation, mitigation, access restriction, or patch validation.
· Device-fleet scope, including mobile devices, managed endpoints, executive devices, contractor devices, BYOD devices, privileged-user devices, and regulated-user devices.
· Management-platform authority over policies, certificates, enrollment profiles, connectors, API tokens, service accounts, applications, compliance state, and downstream integrations.
· Quality and retention of management-platform audit logs, administrative authentication logs, API logs, endpoint process telemetry, file telemetry, DNS logs, proxy logs, network flow data, cloud audit logs, and SIEM correlation.
· Ability to map management actions to affected users, devices, groups, applications, certificates, policies, connectors, and business units.
· Completeness of certificate, token, connector, keystore, integration-secret, database-credential, and service-account inventories.
· Need for certificate revocation, certificate reissuance, API-token rotation, connector rebuilds, service-account resets, administrator credential rotation, device re-enrollment, or policy rollback.
· Need to validate policy pushes, enrollment changes, device-profile changes, certificate distribution, application deployment, compliance-state changes, and device actions.
· Scope of downstream review required when suspected management-platform compromise may have affected identity, directory, certificate, endpoint, cloud, application, security-management, or device-control dependencies.
· Customer, workforce, regulatory, insurance, legal, and executive-governance obligations.
S39 Economic Impact & Organizational Exposure
Active exploitation of MDM and enterprise management control planes creates organizational exposure by increasing uncertainty around management-platform trust, secure mobile gateway integrity, device-management authority, administrative object integrity, connector behavior, certificate posture, API-token exposure, enrollment workflows, mobile-access reliability, downstream device impact, and enterprise control-plane confidence. Exposure rises when suspicious activity affects Ivanti EPMM, Ivanti Sentry, comparable MDM platforms, endpoint-management systems, security-management systems, enterprise administration servers, executive-device management, regulated-user device management, certificate-based authentication, conditional-access dependencies, identity-adjacent integrations, secure mobile gateway paths, or downstream administrative systems.
Estimated Economic Exposure
Estimated exposure should be treated as scenario-based rather than fixed. The most defensible enterprise estimate is tied to whether the activity remains limited to attempted or low-scope exposure, becomes confirmed or strongly suspected management-control-plane or secure mobile gateway compromise, or expands into broad device-management, connector, certificate, identity-adjacent, mobile-access, legal, regulatory, cyber-insurance, executive, or board-level response.
Low Impact Scenario
Estimated impact $500K to $3M.
This scenario applies when affected Ivanti EPMM, Ivanti Sentry, MDM, endpoint-management, security-management, enterprise administration, or secure mobile gateway systems are patched or mitigated quickly, exposure is understood, logs are preserved, and review confirms no suspicious administrative access, management-server or gateway misuse, privileged object change, certificate or token exposure, connector misuse, abnormal outbound communication, backend dependency deviation, persistence activity, downstream device-management impact, or mobile-access impact. Response still requires exposure validation, patch confirmation, administrative review, limited network review, connector assurance, certificate and token review, and executive tracking because active exploitation conditions existed before remediation.
Moderate Impact Scenario
Estimated impact $5M to $25M.
This scenario applies when one or more management-control-plane or secure mobile gateway systems were exposed, vulnerable, internet-facing, semi-trusted-reachable, VPN-reachable, partner-reachable, or otherwise reachable through untrusted paths during the active exploitation window, and investigation identifies suspicious administrative access, abnormal API activity, management-server or gateway instability, rare egress, backend dependency deviation, limited privileged object changes, file staging, connector access anomalies, certificate or keystore access anomalies, or incomplete telemetry without confirmed large-scale device manipulation, broad credential exposure, certificate compromise, sustained adversary control, or enterprise-wide downstream compromise. Response may require incident-response mobilization, management-server or gateway containment, administrative audit reconstruction, connector and integration validation, certificate and token review, targeted privileged account rotation, device-policy validation, mobile-fleet scoping, legal assessment, executive coordination, and workforce or customer communications readiness.
High Impact Scenario
Estimated impact $30M to $150M or higher.
This scenario applies when confirmed or strongly suspected compromise affects MDM, EPMM, endpoint-management, security-management, enterprise administration, Ivanti Sentry, or secure mobile gateway infrastructure with evidence of unauthorized administrative control, suspicious management-service or gateway behavior, privileged role or account manipulation, certificate or API-token exposure, connector misuse, keystore access, policy tampering, enrollment-profile modification, downstream device actions, mobile-access path abuse, lateral movement, abnormal egress, backend dependency deviation, persistence activity, or incomplete historical telemetry. Response may require broad management-platform or gateway containment, emergency device-policy freezes, certificate revocation and reissuance, API-token and connector credential rotation, privileged account reset, mobile-device and endpoint assurance campaigns, selective device re-enrollment, integration rebuilds, identity and directory review, downstream compromise hunting, server or appliance rebuild, legal and regulatory review, cyber-insurance engagement, workforce-productivity coordination, customer assurance where applicable, and board-level incident governance.
Annualized Risk Exposure
Estimated annualized risk exposure is $8M to $55M or higher.
Annualized risk exposure is driven by management-platform and secure mobile gateway exposure, active exploitation conditions, device-fleet size, privileged administration scope, connector dependency, certificate and token footprint, remediation latency, telemetry completeness, administrative-object integrity, backend dependency scope, downstream device impact, credential rotation burden, containment complexity, mobile-access disruption, workforce-productivity exposure, customer assurance requirements, and legal or regulatory obligations.
Management-Platform Dependency
Management-platform dependency is high where affected platforms support mobile-device management, endpoint administration, executive devices, regulated-user devices, contractor devices, BYOD populations, remote workforce devices, endpoint compliance, device-policy enforcement, certificate distribution, application deployment, conditional access, mobile gateways, secure mobile access, or security-management workflows. Dependency increases when affected systems support identity-adjacent integrations, device-trust decisions, security-control enforcement, certificate-based authentication, or large mobile and endpoint populations.
Control-Plane Trust
Control-plane trust is reduced when affected management platforms or secure mobile gateway appliances were exposed, vulnerable, internet-facing, semi-trusted-reachable, reachable through untrusted paths, insufficiently monitored, or remediated without historical compromise review. Trust is further reduced when administrative access, privileged object integrity, connector behavior, certificate distribution, token posture, enrollment workflows, device policies, gateway configuration, backend dependency access, or downstream management actions cannot be confidently explained.
Visibility Confidence
Visibility confidence is highest when management-platform audit logs, Sentry appliance logs, syslog-forwarded gateway events, administrative authentication records, API logs, application logs, endpoint telemetry where available, network telemetry, proxy records, firewall logs, reverse proxy logs, WAF logs, load balancer logs, backend service logs, cloud audit logs where applicable, SIEM correlation, and change-management records can be joined reliably. Visibility confidence is reduced when logs are incomplete, Sentry or gateway telemetry is unavailable, process visibility is missing, file activity is not retained, east-west traffic is not monitored, backend dependency paths are not documented, or management-control-plane and secure mobile gateway assets are not reliably tagged.
Privileged Object Confidence
Privileged object confidence is reduced when administrator accounts, roles, permissions, certificates, API tokens, connectors, enrollment profiles, device-management profiles, policies, integrations, service accounts, keystores, database credentials, connector credentials, integration secrets, or platform configuration objects are poorly documented, weakly logged, inconsistently approved, or difficult to separate from suspicious management-control-plane or gateway activity.
Connector and Credential Dependency
Connector and credential dependency is high where affected management platforms or secure mobile gateway appliances integrate with identity services, directory services, certificate authorities, mobile gateways, backend applications, cloud infrastructure, logging systems, monitoring tools, security platforms, endpoint platforms, or downstream administrative systems using privileged credentials, tokens, certificates, keystores, database credentials, connector credentials, integration secrets, or service accounts. These dependencies increase response cost because compromise review may require credential rotation, certificate reissuance, connector validation, service-account review, and backend dependency scoping.
Downstream Device Dependency
Downstream device dependency is high when affected platforms or gateways can influence device policies, enrollment state, certificate distribution, compliance state, application deployment, configuration profiles, device actions, remote support workflows, mobile-fleet assurance, endpoint posture, mobile access flows, backend enterprise access, or security-control behavior across managed devices. Even limited compromise can create broader uncertainty when defenders cannot quickly prove that device-management actions, mobile-access paths, and backend interactions remained legitimate.
Customer, Workforce, and Regulatory Exposure
Customer, workforce, and regulatory exposure increases when affected systems manage regulated-user devices, executive devices, customer-facing operations, workforce mobility, privileged endpoints, contractor devices, BYOD populations, compliance-dependent controls, certificate-based authentication, customer-impacting services, mobile access paths, backend enterprise dependencies, or contractual security commitments. Exposure also increases when incomplete telemetry prevents timely confirmation of whether administrative activity, object changes, certificate exposure, token exposure, connector behavior, gateway activity, device-policy changes, backend dependency access, downstream device impact, or external communication was legitimate, malicious, or caused by approved operational activity.
Residual Economic Risk
Residual economic risk remains after containment if the organization cannot prove that affected management platforms or secure mobile gateway appliances were patched, exposure was reduced, administrative activity was reviewed, connector integrity was validated, certificates and tokens were reviewed, privileged accounts were assessed, downstream device actions were scoped, backend dependencies were checked, and mobile-access trust was restored. Residual risk is highest where affected systems were exposed before remediation and where logs, asset-role tagging, administrative audit records, gateway telemetry, network baselines, or dependency mapping are incomplete.
Proof-of-Concept / KEV Behavioral Coverage Assessment
This report’s behavioral detection model covers Ivanti EPMM, Ivanti Sentry, MDM, endpoint-management, security-management, enterprise administration, and secure mobile gateway activity that aligns with management-control-plane exploitation, administrative access anomalies, management-service or gateway misuse, suspicious child-process creation, abnormal API activity, file or script staging, privileged object changes, connector misuse, certificate or keystore access, rare outbound communication, backend dependency deviation, service instability, persistence-relevant activity, downstream device-management activity, and mobile-access trust impact.
The report is behavior-led and should not be interpreted as limited to one CVE, exploit string, payload, request path, user agent, proof-of-concept artifact, attacker infrastructure, malware family, vendor alert, or attacker workflow.
Detection Engineering Coverage Interpretation
The S25 detection content provides direct behavioral coverage for Ivanti EPMM exploitation behavior where observable activity includes suspicious administrative access, abnormal management-console activity, unusual API activity, management-service execution, suspicious child-process creation, file or script staging, privileged object changes, connector misuse, certificate or token exposure, rare outbound communication, unexpected east-west traffic, service instability, persistence-relevant activity, or downstream device-management actions.
The S25 detection content provides coverage with adaptation for Ivanti Sentry and comparable secure mobile gateway exploitation behavior where observable activity includes secure mobile gateway exposure, suspicious gateway activity, rare egress, backend dependency deviation, unexpected connector access, unexpected certificate or keystore access, suspicious file activity, unexpected shell or script execution where telemetry exists, appliance configuration changes, gateway instability, or mobile-access path impact.
Direct Coverage
Direct behavioral coverage applies to vulnerabilities that share the report’s primary Ivanti EPMM and management-control-plane exploitation model. Listed CVEs are ordered newest to oldest.
· CVE-2026-6973 - Ivanti EPMM improper input validation and authenticated administrative remote-code-execution behavior where suspicious administrative access, management-service execution, file or script staging, privileged object changes, rare egress, dependency-deviation traffic, service instability, connector misuse, or downstream device-management activity is observable.
· CVE-2026-1340 - Ivanti EPMM exploitation behavior where exposed management-control-plane access, management-service misuse, abnormal API activity, suspicious execution, privileged object changes, connector activity, certificate or token exposure, rare egress, or downstream device-management impact is observable.
· CVE-2026-1281 - Ivanti EPMM code-injection behavior where exposed management-control-plane access, suspicious management-service execution, abnormal application activity, file or script staging, rare outbound communication, unexpected internal dependency access, or downstream device-management impact is observable.
· CVE-2025-4428 - Ivanti EPMM code-injection or remote-code-execution behavior where management-service execution, suspicious file activity, API abuse, rare egress, connector misuse, persistence-relevant activity, or downstream device-management impact is observable.
· CVE-2025-4427 - Ivanti EPMM authentication-bypass behavior where unauthorized management-plane access, abnormal administrative workflow activity, API abuse, privileged object changes, connector misuse, or chained management-service execution is observable.
Coverage With Adaptation
Coverage with adaptation applies to related Ivanti Sentry, secure mobile gateway, enterprise mobility gateway, MDM, endpoint-management, security-management, or enterprise administration activity that aligns with the S25 model but requires local tuning for product role, appliance telemetry, exposure path, administrative access model, gateway audit coverage, identity-provider fields, backend dependency mapping, network visibility, cloud-hosting model, or platform-specific query syntax. Listed CVEs are ordered newest to oldest.
· CVE-2026-10520 - Ivanti Sentry OS command injection behavior where secure mobile gateway exposure, suspicious gateway activity, rare outbound communication, backend dependency deviation, gateway service instability, unexpected connector access, unexpected certificate or keystore access, suspicious file activity, unexpected shell or script execution where telemetry exists, appliance configuration changes, or mobile-access path impact is observable.
· Related Ivanti Sentry, secure mobile gateway, enterprise mobility gateway, MDM, endpoint-management, security-management, or enterprise administration CVEs should be added when NVD records, vendor advisories, CISA KEV entries, proof-of-concept reporting, or confirmed exploitation reports show that the affected behavior aligns with this report’s management-control-plane or secure mobile gateway detection model.
· Related vulnerabilities should remain coverage-with-adaptation when the affected product sits adjacent to the report’s core EPMM model but requires local tuning for gateway role, asset tags, appliance logs, source IP mapping, approved dependency baselines, backend service logs, process telemetry, file telemetry, cloud telemetry, or SIEM normalization.
Non-Coverage Conditions
Non-coverage applies where related activity produces no observable administrative, application, API, appliance, endpoint, file, DNS, proxy, firewall, NDR, cloud, SIEM, backend service, gateway, or downstream device-management telemetry.
Activity limited to unrelated product flaws, direct host compromise without management-control-plane or secure mobile gateway relevance, client-side exploitation outside the management-control-plane model, cloud-only anomalies without upstream management-platform or gateway correlation, identity-only anomalies without management-platform or gateway linkage, unrelated malware execution, or isolated exposure findings without behavioral evidence should not be represented as covered by this report.
A CVE should not be counted when it lacks sufficient technical detail, produces no aligned telemetry, cannot be correlated through the report’s management-control-plane or secure mobile gateway model, or would require detection logic outside the S21 through S25 strategy.
Current Coverage Count
Directly covered CVEs / proof-of-concept behavior patterns: 5.
Covered with adaptation: 1.
Known Exploited Vulnerabilities represented in this coverage set: 6.
Not currently counted as separately covered: 0.
Total CVE / proof-of-concept behavior patterns directly or largely covered by this report’s behavioral detection model: 6.
Coverage Qualification
This count is a living analytical note, not a universal Ivanti, MDM, endpoint-management, security-management, enterprise administration, or secure mobile gateway CVE coverage claim. A related CVE, KEV entry, exploitation report, proof-of-concept, or advisory should only be added when it shares enough observable behavior with the report’s detection model to support credible detection or detection-readiness coverage.
Direct coverage should remain limited to vulnerabilities that share the report’s core Ivanti EPMM, management-control-plane exploitation, administrative access anomaly, management-service execution, privileged object change, connector misuse, certificate or token exposure, rare egress, dependency deviation, and downstream device-management model.
Covered-with-adaptation CVEs should remain counted only when the activity can be correlated through asset inventory, product role, exposure state, administrative authentication, application logs, Sentry logs, syslog events, endpoint process telemetry where available, file telemetry where available, network telemetry, backend dependency mapping, cloud telemetry where applicable, SIEM-normalized correlation, and approved workflow context.
KEV status should be treated as an urgency and remediation-prioritization signal, not as the basis for coverage by itself. Coverage remains based on observable management-control-plane or secure mobile gateway behavior aligned to the report’s S21 through S25 detection strategy.
A related CVE or proof-of-concept should not be counted when it depends on unrelated exploitation mechanics, lacks aligned telemetry, affects only unrelated product functionality, produces no management-control-plane or secure mobile gateway behavior, or requires a separate detection model.
Executive Exposure Statement
The organization’s economic exposure is highest when exploitation of MDM, EPMM, endpoint-management, security-management, enterprise administration, or secure mobile gateway infrastructure creates uncertainty around whether device-management authority, mobile access paths, administrative objects, certificates, API tokens, connectors, service accounts, backend dependencies, and downstream device actions remain trustworthy. The strategic risk is not only one Ivanti EPMM flaw, one Ivanti Sentry KEV entry, one gateway appliance, one management console, one rare destination, or one endpoint alert; it is the possibility that attackers can convert trusted management or secure mobile gateway infrastructure into administrative influence, backend access uncertainty, credential and certificate exposure, downstream device-management impact, legal and compliance review, and executive uncertainty about control-plane trust restoration.
S40 — References
Vendor / Platform Documentation
· hxxps://hub[.]ivanti[.]com/s/article/Security-Advisory-Ivanti-Endpoint-Manager-Mobile-EPMM-CVE-2026-1281-CVE-2026-1340 — Ivanti Security Advisory for Endpoint Manager Mobile EPMM CVE-2026-1281 and CVE-2026-1340.
· hxxps://hub[.]ivanti[.]com/s/article/Analysis-Guidance-Ivanti-Endpoint-Manager-Mobile-EPMM-CVE-2026-1281-CVE-2026-1340 — Ivanti analysis guidance for Endpoint Manager Mobile EPMM CVE-2026-1281 and CVE-2026-1340.
· hxxps://hub[.]ivanti[.]com/s/article/Security-Advisory-Ivanti-Endpoint-Manager-Mobile-EPMM — Ivanti Security Advisory for Endpoint Manager Mobile EPMM CVE-2025-4427 and CVE-2025-4428.
· hxxps://hub[.]ivanti[.]com/s/article/May-2026-Security-Advisory-Ivanti-Endpoint-Manager-Mobile-EPMM-Multiple-CVEs — Ivanti May 2026 Security Advisory for Endpoint Manager Mobile EPMM multiple CVEs, including CVE-2026-6973.
· hxxps://www[.]ivanti[.]com/blog/topics/security-advisory — Ivanti Security Advisory channel for vendor security-update tracking, including Ivanti EPMM and Ivanti Sentry advisory context.
· hxxps://nvd[.]nist[.]gov — National Vulnerability Database reference source for CVE records, descriptions, affected products, severity context, and vulnerability metadata.
Known Exploited Vulnerabilities
· hxxps://www[.]cisa[.]gov/known-exploited-vulnerabilities-catalog — CISA Known Exploited Vulnerabilities Catalog.
Government Analysis
· hxxps://www[.]cisa[.]gov/news-events/analysis-reports/ar25-261a — CISA analysis report covering malicious listener activity associated with exploitation of CVE-2025-4427 and CVE-2025-4428 in Ivanti Endpoint Manager Mobile systems.
Security Vendor Analysis
· hxxps://kudelskisecurity[.]com/research/ivanti-epmm-cve-2026-6973-allows-rce-with-admin-credentials-under-active-exploitation — Kudelski Security analysis of CVE-2026-6973 authenticated administrative remote code execution in Ivanti EPMM under active exploitation.
· hxxps://www[.]bleepingcomputer[.]com/news/security/ivanti-fixes-epmm-zero-days-chained-in-code-execution-attacks/ — BleepingComputer reporting on the May 2025 Ivanti EPMM CVE-2025-4427 and CVE-2025-4428 chain.
· hxxps://www[.]bleepingcomputer[.]com/news/security/new-max-severity-ivanti-sentry-flaw-allows-code-execution-as-root/ — BleepingComputer reporting on Ivanti Sentry root-level code execution risk after the CVE-2026-10520 disclosure.
· hxxps://www[.]bleepingcomputer[.]com/news/security/max-severity-ivanti-sentry-vulnerability-now-exploited-in-attacks/ — BleepingComputer reporting on active exploitation of CVE-2026-10520 against Ivanti Sentry.
Threat Technique Framework
· hxxps://attack[.]mitre[.]org — MITRE ATT&CK Enterprise Matrix.
Reference Usage Note
This reference set supports the report’s focus on active exploitation of Ivanti EPMM, Ivanti Sentry, MDM, endpoint-management, security-management, enterprise administration, and secure mobile gateway control-plane infrastructure. The coverage set includes CVE-2026-10520, CVE-2026-6973, CVE-2026-1340, CVE-2026-1281, CVE-2025-4428, and CVE-2025-4427.
The CISA KEV catalog is included as the authoritative active-exploitation and remediation-priority catalog. Individual KEV search URLs and individual KEV alert URLs are intentionally omitted to avoid reference bloat.
The MITRE ATT&CK reference is included as the authoritative technique framework source. Individual ATT&CK technique URLs are intentionally omitted to avoid reference bloat.
Where multiple public sources reported the same underlying information, this section retains the oldest useful source for each distinct reference purpose and omits later duplicative reporting.
The report remains behavior-led. References are used to support exposure, exploitation urgency, remediation prioritization, and detection-readiness scope, not to convert the report into a CVE-only, IOC-only, proof-of-concept-only, malware-only, or vendor-advisory-only product.