[EXP] NGINX Rift Exploit Path Against Internet-Facing Reverse Proxy and Web Infrastructure

Report Type: EXP
Threat Category: Internet-facing web infrastructure exploitation risk / reverse proxy and NGINX-backed request-handling exploit path.
Assessment Date: May 20, 2026
Primary Impact Domain: Service continuity and customer-facing web infrastructure resilience.
Secondary Impact Domains: Cloud and Kubernetes exposure; credential and secret exposure; backend application access; operational response burden; compliance and customer-assurance risk.
Affected Asset Class: Internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent infrastructure, NGINX-backed customer-facing applications, API gateways, authentication portals, payment paths, administrative interfaces, Kubernetes ingress services, and cloud-hosted NGINX workloads.
Threat Objective Classification: Externally initiated exploit attempt with potential denial-of-service, service degradation, and conditional post-exploitation outcomes. The report classifies the activity as an exposed reverse-proxy exploit path where malformed request activity may trigger worker instability, route degradation, suspicious NGINX-context execution, unusual egress, backend probing, credential or secret access, cloud metadata interaction, Kubernetes activity, or downstream operational impact when corroborated by telemetry.
BLUF
NGINX Rift creates material enterprise risk by exposing internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent infrastructure to malformed request activity that may trigger worker instability, route-specific degradation, reverse proxy disruption, denial-of-service conditions, or follow-on host activity depending on deployment configuration and runtime exposure. The highest-risk environments are those where NGINX-backed services rely on rewrite-heavy routing, complex reverse proxy behavior, ingress paths, authentication routes, API gateways, customer-facing virtual hosts, administrative portals, payment paths, or high-dependency upstream applications.
The threat posture is elevated because successful exploitation or exploit-adjacent activity can disrupt customer access, degrade routing through critical web infrastructure, expose backend applications to abnormal access, enable suspicious execution from NGINX service context, or support outbound callback and internal expansion behavior from infrastructure that normally operates as a trusted web front door. Executive action is required to identify exposed NGINX-backed services, validate rewrite-route exposure, accelerate patching or compensating controls, preserve request and crash telemetry, and ensure response teams can distinguish scan noise from probable exploitation before customer-facing disruption or post-exploitation activity expands.
Executive Risk Translation
NGINX Rift shifts business risk from ordinary internet scanning to the reliability and trustworthiness of exposed reverse proxy and ingress infrastructure. The primary concern is not simply whether NGINX is present, but whether vulnerable or rewrite-heavy NGINX-backed services sit in front of business-critical application paths. If exploitation affects a high-value reverse proxy tier, response may expand into emergency patch validation, route-level exposure review, WAF and CDN rule changes, load balancer or ingress policy updates, service-restoration work, crash-artifact preservation, endpoint and container investigation, credential and secret review, backend application scoping, customer-impact analysis, and executive incident governance. This creates operational, financial, customer-trust, compliance, and resilience exposure beyond the first malformed request or worker crash.
S3 — Why This Matters Now
· NGINX Rift should be treated as an exposed web-infrastructure and reverse-proxy risk, not as a generic web-server alert.
· The primary enterprise concern is whether malformed request activity can interact with vulnerable rewrite behavior, destabilize NGINX workers, disrupt customer-facing access, or create a path into host, container, ingress, gateway, backend application, or cloud infrastructure.
· Internet-facing NGINX services often sit at high-trust control points, including authentication portals, API gateways, customer-facing applications, administrative interfaces, payment flows, Kubernetes ingress paths, and reverse proxy tiers.
· Service instability on a reverse proxy can create immediate business impact even when code execution is not confirmed.
· Successful exploitation or exploit-adjacent activity may require emergency coordination across web operations, infrastructure, application, cloud, Kubernetes, endpoint, identity, and incident-response teams.
· NGINX worker crashes, segmentation fault indicators, abnormal worker exits, reload failures, 500-series spikes, upstream resets, route degradation, and gateway errors require elevated attention when they align with suspicious malformed request activity against exposed rewrite-heavy paths.
· Standalone malformed requests should not be treated as confirmed compromise because internet-facing NGINX services receive high volumes of scanning, fuzzing, automated testing, crawler noise, and vulnerability validation.
· Network-only monitoring is insufficient because probable exploitation may require correlation across request logs, NGINX error logs, service-health telemetry, endpoint process lineage, file activity, outbound communication, cloud logs, Kubernetes telemetry, and downstream application behavior.
· Organizations without raw URI retention, normalized URI visibility, route mapping, source IP preservation, NGINX error-log parsing, endpoint telemetry, egress baselines, crash-artifact preservation, and exposed-service inventory face elevated risk of delayed detection and incomplete scoping.
· Static proof-of-concept request patterns may support triage, but they are insufficient as the durable detection model because request structure, encoding, route targeting, and exploit delivery methods can change quickly.
S4 — Key Judgments
· NGINX Rift is most consequential when exposed NGINX-backed infrastructure fronts customer-facing, authentication, API, administrative, payment, ingress, gateway, or high-dependency application paths.
· The strongest enterprise risk signal is suspicious malformed request activity followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, reload loops, route-specific 500-series spikes, upstream resets, gateway errors, child-process execution, unusual outbound communication, suspicious file activity, backend probing, cloud metadata interaction, or Kubernetes activity.
· Vulnerable NGINX exposure and rewrite-heavy configuration should drive patch prioritization and hunt scoping, but they should not be treated as confirmed exploitation without behavioral evidence.
· Standalone malformed requests, scan artifacts, 500-series spikes, or worker crashes are insufficient for compromise classification unless they align with vulnerable asset context or follow-on service, endpoint, network, file, cloud, Kubernetes, identity, or application signals.
· Reverse proxy and ingress infrastructure may amplify business impact because a single affected NGINX tier can disrupt multiple upstream applications, customer workflows, internal APIs, and service dependencies.
· Kubernetes and containerized NGINX deployments require elevated prioritization because pod restarts, crash loops, mounted secrets, service-account context, ingress metadata, workload identity, and node placement can affect blast-radius assessment.
· Cloud-hosted NGINX infrastructure requires egress, metadata, workload identity, security group, load balancer, and flow-log review when suspicious request activity is followed by unusual outbound or internal communication.
· Detection must remain behavior-led because public exploit strings, URI examples, proof-of-concept artifacts, filenames, hashes, and user-agent values are not durable enough for enterprise detection.
· Executive risk reduction depends on exposed asset identification, patch acceleration, route-level compensating controls, validated telemetry coverage, egress baselining, crash-artifact preservation, and response workflows for reverse proxy exploitation.
· The report should distinguish attempted exploitation, probable denial-of-service impact, probable compromise, and confirmed post-exploitation activity rather than collapsing all suspicious request activity into one severity category.
S5 — Executive Risk Summary
Business Risk
NGINX Rift can create severe operational, availability, and customer-facing risk when exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure processes malformed request activity against vulnerable rewrite-heavy routes. Risk increases when affected services front business-critical access paths such as authentication, API, payment, administrative, Kubernetes ingress, identity-adjacent, regulated, or high-dependency upstream application routes. Business impact may include reverse proxy instability, customer-facing outage, degraded application access, emergency route changes, WAF or CDN rule updates, load balancer or ingress policy changes, backend application scoping, credential review, SOC surge activity, customer assurance, and executive incident governance.
Technical Cause
The risk is driven by an exploit path involving exposed NGINX-backed request handling, rewrite-module behavior, route-specific processing, and deployment-dependent runtime conditions. The enterprise detection model should focus on malformed request activity, encoded URI expansion, abnormal delimiter density, request normalization failures, route-specific degradation, NGINX worker crashes, segmentation fault indicators, abnormal restarts, unexpected child-process execution, file or configuration activity, unusual outbound communication, internal expansion, and vulnerable asset context.
Threat Posture
The threat posture is elevated because exposed reverse proxy and ingress infrastructure is continuously probed by internet scanners, exploit operators, botnets, vulnerability researchers, and opportunistic attackers. Successful exploitation or exploit-adjacent activity may enable service disruption, crash-loop behavior, web-tier instability, payload staging, outbound callback behavior, credential or secret access, backend probing, Kubernetes service-account access, cloud metadata interaction, or lateral expansion from infrastructure that normally holds trusted access to upstream applications.
Executive Decision Requirement
Executives must require immediate identification of internet-facing NGINX-backed assets, validation of rewrite-heavy route exposure, prioritization of business-critical reverse proxy and ingress services, accelerated patching or compensating controls, and confirmation that detection teams can correlate suspicious request activity with service instability, endpoint behavior, egress, file activity, cloud telemetry, Kubernetes telemetry, and application telemetry. Response leadership should also confirm that teams can preserve request logs, error logs, crash artifacts, WAF events, load balancer telemetry, endpoint evidence, and container or Kubernetes context during emergency remediation.
S6 — Executive Cost Summary
NGINX Rift creates financial exposure primarily through reverse proxy instability, customer-facing service degradation, emergency web-infrastructure remediation, route-level exposure validation, WAF/CDN/load-balancer changes, crash and request-log forensic review, and the operational burden of determining whether suspicious request activity remained scan noise or progressed into host, container, Kubernetes, cloud, backend, credential, or application impact. The cost profile is specific to exposed NGINX-backed infrastructure because affected systems often sit directly in front of business-critical applications and may require immediate changes to routing, filtering, patching, logging, service ownership, and customer-impact workflows.
Low Impact Scenario
Rapid assessment confirms that suspicious activity is limited to scanning, probing, authorized validation, or malformed request noise against exposed NGINX-backed services. Affected services are patched, not using relevant rewrite-heavy behavior, shielded from the vulnerable request path, or protected by validated compensating controls. No worker instability, route degradation, outage condition, suspicious execution, unusual egress, backend probing, Kubernetes activity, cloud metadata access, file activity, credential exposure, or customer-facing degradation is observed.
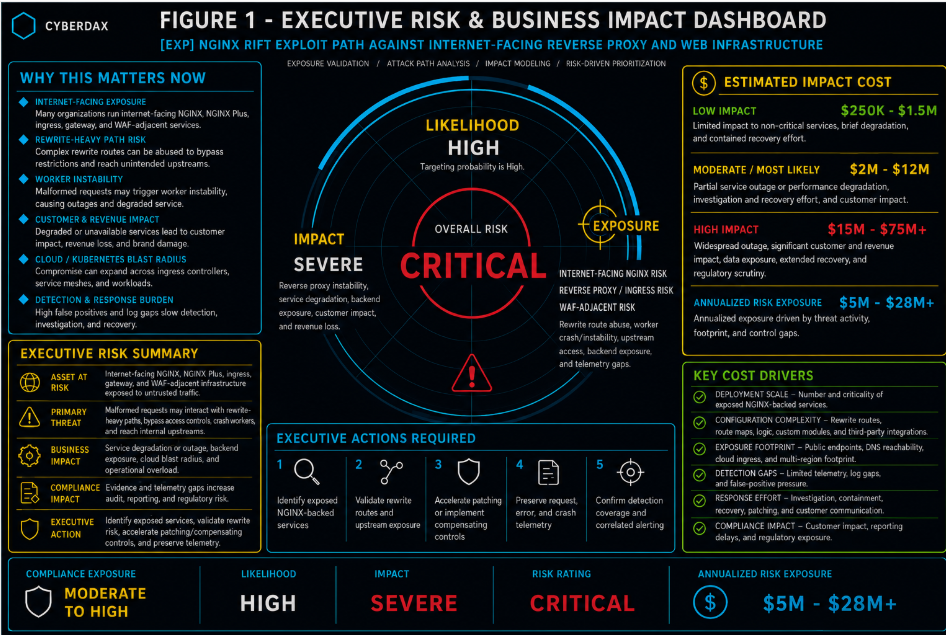
Estimated impact is $250K to $1.5M.
Cost drivers include:
· Exposed NGINX service inventory review.
· Rewrite-route and virtual-host validation.
· Patch verification and compensating-control review.
· WAF, CDN, load balancer, ingress, and gateway policy review.
· Request-log triage and scanner allowlist reconciliation.
· Targeted SOC hunting and SIEM correlation checks.
· Service-owner coordination for exposed web infrastructure.
· Executive tracking because exposed reverse proxy infrastructure remains a high-dependency business control point.
Moderate Impact Scenario
Suspicious malformed request activity is observed against exposed NGINX-backed services and is paired with route-specific degradation, elevated 500-series responses, upstream resets, gateway failures, NGINX worker instability, reload failures, container restarts, pod restarts, or limited service-health impact. No confirmed host compromise, credential exposure, lateral movement, or data access is identified, but the organization must respond as if the affected reverse proxy tier may have created customer-facing disruption or incomplete investigative confidence.
Estimated impact is $2M to $12M.
Cost drivers include:
· Emergency NGINX patching, reload validation, and configuration review.
· Rewrite-route exposure analysis for affected virtual hosts and application paths.
· WAF, CDN, load balancer, ingress, and gateway rule tuning.
· Crash-artifact preservation and NGINX error-log review.
· Service-restoration work for degraded routes, failed upstreams, gateway errors, or customer-facing access issues.
· Endpoint review for child-process execution, file activity, and service-account behavior.
· Egress baseline review for unusual DNS, proxy, firewall, NetFlow, or cloud flow activity.
· Application-owner validation for authentication, API, payment, administrative, customer portal, or high-dependency upstream routes.
· Customer assurance if availability, authentication, transaction flow, or API reliability was affected.
· Increased SOC, web operations, infrastructure, cloud, Kubernetes, and incident-response coordination.
High Impact Scenario
Confirmed or strongly suspected exploitation affects business-critical NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure and is followed by suspicious child-process execution, file activity, unusual outbound communication, backend probing, credential or secret access, Kubernetes service-account activity, cloud metadata interaction, or prolonged customer-facing service disruption. This scenario applies when the incident moves beyond request handling and service instability into probable post-exploitation, downstream exposure, or material service-continuity impact.
Estimated impact is $15M to $75M or higher.
Cost drivers include:
· Emergency failover or rebuild of affected NGINX, reverse proxy, ingress, or gateway infrastructure.
· Configuration rollback, route restoration, and validation of upstream application routing.
· WAF, CDN, load balancer, gateway, and ingress policy changes under incident conditions.
· Credential, secret, token, service-account, and cloud identity review.
· Kubernetes ingress, workload, namespace, mounted-secret, node, or service-account investigation where applicable.
· Cloud metadata, flow-log, security group, managed identity, and control-plane review where applicable.
· Backend application, internal API, identity service, database, management interface, or secret-store scoping.
· Forensic preservation of request logs, error logs, crash artifacts, endpoint telemetry, container evidence, and cloud or Kubernetes telemetry.
· Customer assurance, legal review, regulatory notification analysis, cyber insurance coordination, executive incident governance, and board-level reporting.
· Extended recovery work if customer access, authentication, API reliability, payment workflows, administrative access, or regulated service paths were affected.
S6A — Key Cost Drivers
· Number and criticality of exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, and NGINX-backed application services.
· Whether affected services front customer-facing applications, authentication portals, API gateways, payment flows, administrative interfaces, identity services, regulated data paths, or high-dependency upstream applications.
· Whether affected routes use rewrite-heavy configurations, rewrite directives, set directives, capture-based rewrites, complex routing, ingress annotations, gateway rules, or legacy application paths.
· Whether suspicious request activity caused worker crashes, segmentation fault indicators, abnormal exits, reload loops, route-specific 500-series spikes, upstream resets, gateway failures, container restarts, pod restarts, or customer-facing service degradation.
· Scope of emergency patching, NGINX configuration review, reverse proxy validation, WAF tuning, CDN rule changes, load balancer updates, ingress-controller changes, gateway policy changes, and route-level compensating controls.
· Degree of customer-facing disruption, including blocked legitimate traffic, degraded authentication access, failed API requests, payment-flow interruptions, administrative portal outages, or degraded upstream application availability.
· Availability of raw URI values, normalized URI values, host headers, forwarded headers, query strings, request identifiers, response codes, upstream response timing, source IP context, and route-level request telemetry.
· Availability of NGINX error logs, crash metadata, coredump metadata, service manager logs, container restart telemetry, pod restart telemetry, infrastructure health monitoring, and application performance telemetry.
· Availability of endpoint process lineage, command-line telemetry, file telemetry, service-account context, container context, Kubernetes metadata, and process-to-network attribution.
· Ability to correlate NGINX request activity with endpoint behavior, outbound communication, DNS lookups, proxy activity, firewall logs, NetFlow, cloud flow logs, Kubernetes audit logs, and downstream application telemetry.
· Whether unusual outbound communication, direct IP egress, suspicious DNS lookup, rare destination contact, tunneling behavior, tool retrieval, or beacon-like traffic is observed from NGINX hosts or workloads.
· Whether suspicious activity touches web-accessible directories, temporary directories, NGINX configuration paths, mounted volumes, cloud credentials, Kubernetes mounted secrets, service-account tokens, startup paths, service-unit files, or monitoring-agent paths.
· Whether backend applications, internal APIs, databases, identity services, cloud metadata endpoints, Kubernetes API servers, secret stores, CI/CD systems, artifact repositories, or management interfaces are accessed after exploit-path indicators.
· Whether affected infrastructure is containerized, Kubernetes-managed, cloud-hosted, autoscaled, ephemeral, service-mesh-connected, or managed in a way that complicates evidence preservation and source attribution.
· Whether emergency remediation causes downtime, degraded routing, reverse proxy reload failures, application routing errors, WAF false positives, blocked legitimate customer traffic, or rollback activity.
· Whether customer assurance, legal review, regulatory notification analysis, cyber insurance reporting, executive incident governance, or board-level reporting is required.
Most Likely Scenario Justification
The moderate scenario is most likely when exposed NGINX-backed infrastructure includes customer-facing applications, API gateways, authentication paths, Kubernetes ingress services, or reverse proxy tiers with incomplete route inventory, incomplete raw request visibility, incomplete error-log parsing, or limited egress baselines. The estimate moves toward the lower end when patching is rapid, rewrite exposure is limited, suspicious request activity remains scan-only, error logs show no worker instability, service health remains stable, and endpoint, network, cloud, and Kubernetes telemetry show no follow-on activity. The estimate moves toward the upper end when affected services are business-critical, route-specific degradation occurs, crash artifacts are incomplete, WAF/CDN/load-balancer changes are required under pressure, customer-facing availability is affected, or suspicious process, file, egress, backend, cloud, or Kubernetes activity appears after exploit-path indicators.
S6B — Compliance and Risk Context
Compliance Exposure Indicator
Moderate to High depending on whether suspected exploitation affected customer-facing services, authentication systems, payment workflows, regulated applications, identity-adjacent infrastructure, cloud-hosted workloads, Kubernetes ingress services, backend APIs, secrets, credentials, service accounts, or telemetry needed for reliable forensic scoping. Compliance exposure increases when service disruption, customer impact, regulated data paths, incomplete log retention, missing source IP preservation, incomplete crash evidence, or uncertain credential exposure prevents confident scoping.
Risk Register Entry
Risk Title
NGINX Rift Reverse Proxy Exploit Path and Internet-Facing Web Infrastructure Exposure
Risk Description
Adversaries may target exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure with malformed request activity that interacts with vulnerable rewrite-heavy behavior, causes worker instability or denial-of-service conditions, supports suspicious child-process execution, enables outbound callback behavior, exposes credentials or secrets, disrupts customer-facing applications, or creates downstream access paths into backend, cloud, Kubernetes, identity, or management infrastructure.
Likelihood
High.
Impact
Severe.
Risk Rating
Critical.
Annualized Risk Exposure
Estimated $5M to $28M or higher based on exposed NGINX-backed service footprint, rewrite-route exposure, customer-facing dependency, authentication or API gateway role, patch latency, WAF/CDN/load-balancer complexity, route-level telemetry completeness, service disruption potential, Kubernetes and cloud blast radius, credential or secret exposure, containment complexity, and customer or regulatory obligations.
S7 — Risk Drivers
· Internet-facing NGINX-backed services are continuously exposed to automated scanning, exploit validation, bot traffic, malformed requests, and opportunistic probing.
· Reverse proxy and ingress infrastructure often fronts multiple upstream applications, making one affected service tier capable of creating broad downstream operational impact.
· Rewrite-heavy configurations, complex routing, legacy virtual hosts, ingress paths, gateway routes, and application-specific path handling increase exploit-path uncertainty.
· Customer-facing portals, authentication flows, API gateways, payment paths, administrative interfaces, and identity-adjacent services increase business criticality.
· NGINX worker crashes, segmentation fault indicators, reload failures, and route-specific 500-series spikes can disrupt availability even when successful code execution is not confirmed.
· WAF, CDN, load balancer, gateway, ingress, and reverse proxy normalization may obscure raw request structure and complicate exploit-path reconstruction.
· Missing raw URI, normalized URI, query-string, host-header, forwarded-header, source IP, response-code, upstream-timing, and request-identifier fields weakens detection and triage.
· Missing NGINX error-log parsing, crash metadata, coredump metadata, service manager logs, container restart telemetry, or pod restart telemetry weakens instability correlation.
· Missing endpoint process lineage, command-line capture, service-account mapping, file telemetry, container context, or process-to-network attribution weakens post-exploitation assessment.
· Missing egress baselines for NGINX hosts can delay identification of callback, staging, tool retrieval, tunneling, or data-transfer behavior.
· Kubernetes ingress deployments may expose mounted secrets, service-account tokens, namespace context, workload identity, node placement, container runtime context, and backend service paths.
· Cloud-hosted NGINX infrastructure may expose metadata services, managed identities, security group context, load balancer routing, cloud flow logs, and control-plane dependencies.
· Source IP preservation failures across CDN, WAF, proxy, NAT, load balancer, gateway, and ingress layers can complicate source clustering and attacker infrastructure analysis.
· Emergency remediation may affect legitimate customer traffic when WAF, CDN, load balancer, ingress, gateway, or reverse proxy changes are made under time pressure.
· Over-reliance on proof-of-concept strings, CVE labels, single URI patterns, static exploit fragments, or vulnerable-version exposure can miss variant behavior and overstate scan noise.
S8 — Bottom Line for Executives
NGINX Rift should be treated as a high-priority reverse proxy, web infrastructure, and customer-facing service resilience risk because it can expose critical NGINX-backed infrastructure to malformed request activity, service instability, denial-of-service outcomes, and potential post-exploitation behavior. The key executive concern is not only whether vulnerable NGINX versions exist, but whether exposed reverse proxy, ingress, gateway, or WAF-adjacent services front applications whose disruption or compromise would affect customers, authentication, APIs, payment flows, administrative access, regulated data paths, cloud workloads, Kubernetes services, or high-value backend systems. Risk reduction depends on rapid asset identification, route-level exposure validation, prioritized patching, WAF/CDN/load-balancer compensating controls, validated telemetry coverage, egress baselining, crash-artifact preservation, and response workflows that can separate scan noise from probable exploitation. Organizations should prioritize this report as an infrastructure trust and service-continuity issue because reverse proxy compromise or instability can create operational disruption, customer impact, backend exposure, credential risk, compliance uncertainty, and executive incident governance requirements.
S9 — Board-Level Takeaway
NGINX Rift turns exposed NGINX-backed reverse proxy infrastructure into a potential service-disruption and downstream exposure path for customer-facing web operations. The board-level risk is that malformed request activity against business-critical NGINX, ingress, gateway, or WAF-adjacent services may degrade availability, disrupt customer workflows, expose backend dependencies, or create investigation scope across cloud, Kubernetes, endpoint, identity, and application environments. Leadership should require evidence that exposed NGINX services have been inventoried, rewrite-heavy routes have been identified, patching and compensating controls are progressing, request and crash telemetry is reliable, and response teams can detect correlated request-to-instability, request-to-execution, and request-to-egress behavior. This report supports governance decisions around internet-facing web infrastructure risk, customer-facing service resilience, cloud and Kubernetes exposure, credential containment readiness, telemetry reliability, and executive oversight of reverse proxy exploitation risk.

Figure 2
S10 — Threat Overview
NGINX Rift is an exploit path affecting internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent infrastructure where malformed request activity may interact with vulnerable rewrite behavior, route-specific processing, or deployment-dependent request handling. The primary enterprise risk is not ordinary malformed web traffic by itself. The risk emerges when suspicious request activity aligns with exposed NGINX-backed services, rewrite-heavy paths, worker instability, route degradation, abnormal process activity, unusual outbound communication, or downstream application exposure.
NGINX Rift should be treated as a web-infrastructure and reverse-proxy trust issue. Affected NGINX-backed services may sit in front of authentication portals, API gateways, customer-facing applications, payment flows, administrative interfaces, Kubernetes ingress paths, and high-dependency upstream services. In those environments, exploitation or exploit-adjacent activity can create immediate availability risk and conditional post-exploitation risk.
The report’s detection model is behavior-led. It does not treat every malformed request, 500-series spike, worker crash, or scanner artifact as compromise evidence. Detection confidence increases when malformed request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, route-specific degradation, suspicious child-process execution, unusual outbound communication, file activity, credential or secret access, backend probing, cloud metadata interaction, or Kubernetes activity.
Primary Threat Condition
The primary threat condition exists when an external actor targets exposed NGINX-backed infrastructure with malformed request activity against routes or services plausibly exposed to vulnerable rewrite behavior, and that activity is followed by service instability, route degradation, endpoint behavior, unusual egress, backend access, or other exploit-path evidence.
Enterprise Impact Model
NGINX Rift should be treated as a potential service-continuity and downstream exposure risk. The highest impact occurs when affected reverse proxy or ingress infrastructure fronts business-critical applications, authentication services, APIs, payment workflows, administrative portals, regulated data paths, cloud workloads, or Kubernetes services. Even without confirmed code execution, worker crashes and reverse proxy instability can disrupt application access, degrade customer experience, trigger emergency change activity, and force broad web-infrastructure review.
Detection and Response Relevance
Detection and response should prioritize correlation across web telemetry, NGINX error logs, route-level service health, endpoint process lineage, file activity, outbound communication, cloud flow logs, Kubernetes telemetry, and downstream application behavior. Network or request telemetry alone may identify exploit attempts, but probable compromise requires supporting evidence from host, file, egress, identity, Kubernetes, cloud, or application telemetry.
S11 — Threat Classification and Type
Threat Type
Internet-facing web infrastructure exploitation risk.
Threat Sub-Type
Reverse proxy and NGINX-backed request-handling exploit path.
Operational Classification
Externally initiated exploit attempt with potential denial-of-service, service degradation, and conditional post-exploitation outcomes.
Primary Function
Target exposed NGINX-backed infrastructure through malformed request delivery against routes or services where rewrite behavior, reverse proxy processing, ingress routing, or deployment-specific request handling may produce worker instability, service degradation, or follow-on activity.
Classification Notes
· NGINX Rift should not be classified as confirmed compromise based only on malformed HTTP requests.
· NGINX Rift should not be classified as confirmed code execution unless endpoint, process, file, outbound, or other post-exploitation evidence supports that conclusion.
· NGINX Rift may produce denial-of-service or instability outcomes even when no child-process execution is observed.
· NGINX Rift may become a broader compromise path if exploitation is followed by suspicious process execution, file activity, unusual egress, credential access, backend probing, cloud activity, or Kubernetes activity.
· The most reliable enterprise classification separates attempted exploitation, likely service impact, probable compromise, and confirmed post-exploitation.
S12 — Campaign or Activity Overview
NGINX Rift activity should be modeled as external exploit probing and possible exploitation against exposed NGINX-backed web infrastructure. The activity may begin with malformed request delivery, route probing, abnormal URI structures, encoded path expansion, repeated delimiters, capture-like route structures, uncommon methods, malformed headers, request normalization failures, or source-clustered probing against exposed services.
The activity may remain at the attempted exploitation stage when suspicious request patterns do not produce service instability or follow-on behavior. It becomes more operationally significant when suspicious request activity is followed by worker crashes, segmentation fault indicators, reload failures, route-specific 500-series spikes, upstream resets, gateway errors, container restarts, pod restarts, or health-check failures.
If exploitation progresses beyond instability, follow-on activity may include suspicious child-process execution from NGINX or related service context, file writes, configuration modification, credential or secret access, outbound communication, backend probing, Kubernetes service-account interaction, cloud metadata access, or lateral movement preparation. These follow-on behaviors should remain conditional unless supported by telemetry.
Activity Flow
· External actor probes exposed NGINX-backed services.
· Actor sends malformed requests or route-manipulation attempts against exposed paths.
· NGINX-backed service may show route degradation, worker instability, abnormal exits, or elevated error responses.
· If exploitation succeeds beyond service impact, NGINX-related process context may produce suspicious child-process execution, file activity, or outbound communication.
· Actor may attempt to access backend applications, internal APIs, credentials, secrets, Kubernetes resources, cloud metadata, or management interfaces depending on host role and available trust relationships.
· Defender confidence depends on correlation across request telemetry, service telemetry, endpoint telemetry, network telemetry, and asset context.
Operational Boundary
NGINX Rift should not be treated as a broad campaign attribution model by default. This report focuses on exploit-path behavior and enterprise detection coverage rather than attributing activity to a specific actor, malware family, or campaign unless separate intelligence supports that conclusion.
S13 — Targets and Exposure Surface
Primary Targets
· Internet-facing NGINX servers.
· NGINX Plus deployments.
· NGINX-backed reverse proxy infrastructure.
· NGINX-backed ingress controllers.
· Gateway services using NGINX-backed routing.
· WAF-adjacent NGINX services.
· Customer-facing virtual hosts.
· Authentication portals.
· API gateways and API routes.
· Payment paths and transaction workflows.
· Administrative interfaces exposed through NGINX-backed routing.
· Legacy application paths using complex rewrite behavior.
· Kubernetes ingress paths.
· Cloud-hosted NGINX workloads.
· High-dependency upstream application routes.
Highest-Risk Exposure Conditions
· Exposed services using rewrite-heavy configurations.
· Exposed routes using rewrite directives, set directives, capture-based rewrites, or complex route transformation.
· Internet-facing services with incomplete patch validation.
· NGINX tiers fronting authentication, API, payment, administrative, identity-adjacent, regulated, or customer-facing workflows.
· Reverse proxy tiers supporting multiple upstream applications.
· Ingress or gateway deployments where service instability may affect several workloads.
· Containerized NGINX services where crash, file, or process evidence may be short-lived.
· Cloud-hosted NGINX infrastructure with access to metadata services, managed identities, or sensitive backend dependencies.
· Environments where raw URI values, normalized URI values, source IP context, request identifiers, or NGINX error logs are incomplete.
Exposure Rationale
NGINX-backed infrastructure often sits at the boundary between external users and internal applications. This makes the exposure surface valuable even when exploitation produces only instability. Affected services can disrupt access to downstream applications, trigger emergency routing changes, complicate forensic scoping, or expose trusted pathways into backend services when post-exploitation behavior occurs.
S14 — Sectors / Countries Affected
Sectors Affected
· Technology and SaaS.
· Financial services.
· Healthcare and life sciences.
· Retail and e-commerce.
· Telecommunications.
· Cloud-hosted enterprises.
· Government and public sector.
· Education and research.
· Energy, manufacturing, and industrial organizations.
· Logistics, transportation, and business services.
· Organizations operating customer-facing portals, API platforms, payment workflows, or high-dependency web infrastructure.
Countries Affected
· Global.
Exposure Rationale
Exposure is global because NGINX and NGINX-backed reverse proxy infrastructure are widely deployed across public-facing web services, cloud workloads, Kubernetes ingress environments, API gateways, SaaS platforms, customer portals, administrative interfaces, and enterprise application delivery paths. Risk is highest where exposed NGINX-backed services support business-critical applications, sensitive authentication flows, revenue operations, regulated data paths, or cloud and Kubernetes trust boundaries.
S15 — Adversary Capability Profiling
NGINX Rift is useful to adversaries that can identify exposed NGINX-backed infrastructure, deliver malformed request patterns, vary URI structure or encoding, and evaluate service response, instability, or follow-on access opportunities. The probing stage does not require highly sophisticated tradecraft, but exploitation chains that move beyond instability into execution, egress, backend probing, cloud activity, Kubernetes interaction, or credential access require stronger operational capability.
Capability Level
Moderate.
Technical Sophistication
Moderate.
Infrastructure Maturity
Low to Moderate for scanning and malformed request probing.
Moderate to High when activity includes callback infrastructure, source rotation, backend probing, cloud interaction, Kubernetes activity, or stealthy post-exploitation.
Operational Scale
Potentially broad for internet-facing probing.
Targeted when actors focus on high-value reverse proxy, ingress, gateway, authentication, API, payment, administrative, or customer-facing infrastructure.
Escalation Likelihood
Moderate when activity is limited to probing, malformed requests, route degradation, or denial-of-service effects.
High when suspicious request activity is followed by child-process execution, unusual egress, file activity, credential or secret access, backend probing, Kubernetes activity, or cloud metadata interaction.
Capability Assessment
· Low-capability actors may rely on public request patterns, automated scanning, basic source rotation, and visible service-response changes.
· Moderate-capability actors may vary URI structure, encoding, delimiters, headers, timing, route targeting, and source infrastructure to evade simple request-string detection.
· Higher-capability actors may integrate NGINX Rift into broader intrusion workflows involving callback infrastructure, payload staging, backend discovery, cloud metadata access, Kubernetes service-account access, credential harvesting, or defense evasion.
· The strongest adversary value comes from targets where NGINX-backed infrastructure fronts high-trust application paths or has access to sensitive backend, cloud, container, or Kubernetes resources.
Adversary Limitation
NGINX Rift does not automatically imply successful code execution or full infrastructure compromise. Attackers may only produce scan noise, exploit attempts, worker instability, denial-of-service effects, or failed probes. Post-exploitation assessment requires corroborating evidence from process, file, egress, backend, cloud, Kubernetes, identity, or application telemetry.
S16 — Targeting Probability Assessment
Overall Targeting Probability
High for organizations with internet-facing NGINX-backed reverse proxy, ingress, gateway, API, authentication, payment, administrative, customer-facing, or high-dependency web infrastructure.
Targeting Drivers
· Widespread enterprise use of NGINX and NGINX-backed reverse proxy infrastructure.
· Internet exposure of NGINX services and ingress paths.
· Business value of customer-facing portals, APIs, authentication flows, payment paths, and administrative interfaces.
· Presence of rewrite-heavy routing or complex reverse proxy behavior.
· Delay between patch availability, configuration validation, compensating-control review, and operational remediation.
· Incomplete raw request logging or route-level telemetry.
· Ability for attackers to automate malformed request delivery and route probing.
· Potential for worker instability or denial-of-service outcomes without requiring full compromise.
· Potential for downstream access if exploitation leads to process execution, credential access, unusual egress, backend probing, cloud metadata interaction, or Kubernetes activity.
Most Likely Targets
· Customer-facing NGINX-backed web applications.
· API gateways and API routes.
· Authentication portals and identity-adjacent web services.
· Payment or transaction workflows.
· Administrative interfaces exposed through NGINX-backed routing.
· Kubernetes ingress services.
· Cloud-hosted NGINX workloads.
· Reverse proxy tiers supporting multiple upstream applications.
· Legacy application paths with complex rewrite behavior.
· High-dependency services where route degradation creates business impact.
Moderate Probability Targets
· Internal NGINX-backed services exposed through limited partner, VPN, or restricted access paths.
· Development, staging, or QA NGINX services that mirror production routing behavior.
· Lower-criticality reverse proxy services with limited customer impact but incomplete patch or logging coverage.
· NGINX-backed services protected by WAF or CDN controls where raw request visibility remains incomplete.
Lower Probability Targets
· Fully patched NGINX services with no relevant rewrite exposure.
· Non-internet-facing services with restricted access and strong route-level controls.
· NGINX services that do not front sensitive applications, customer workflows, high-value APIs, or trusted backend paths.
· Ephemeral services rebuilt from validated patched images with strong logging and egress controls.
Targeting Boundary
Targeting probability should not be treated as confirmed exploitation in any specific environment. Confirmed or probable exploitation requires observed suspicious request activity plus supporting evidence such as worker instability, route degradation, abnormal process execution, file activity, unusual egress, backend probing, cloud activity, Kubernetes activity, credential access, or downstream application anomalies.
S17 — MITRE ATT&CK Chain Flow Mapping
This mapping reflects the most likely enterprise attack path for NGINX Rift without assuming that every event produces compromise. External delivery and route probing are the primary mapped behaviors. Service instability is a plausible impact outcome. Execution, tool transfer, credential access, internal expansion, defense evasion, and service disruption beyond the initial instability are conditional and require corroborating telemetry.
Stage 1: External Exploit Delivery
The adversary targets exposed NGINX-backed infrastructure with malformed HTTP or HTTPS request activity against routes plausibly exposed to vulnerable rewrite behavior, reverse proxy processing, ingress routing, or gateway handling.
· T1190 — Exploit Public-Facing Application
Stage 2: Route Probing and Request Variation
The adversary varies request paths, encoding, delimiters, headers, methods, source infrastructure, or route targets to identify exploitable request-handling behavior or trigger instability.
· T1595.002 — Active Scanning: Vulnerability Scanning
· T1595.003 — Active Scanning: Wordlist Scanning
Stage 3: Service Instability or Denial-of-Service Outcome
Malformed request activity may cause NGINX worker instability, segmentation fault indicators, abnormal exits, reload failures, route-specific degradation, upstream resets, gateway errors, container restarts, pod restarts, or customer-facing service disruption.
· T1499 — Endpoint Denial of Service
Stage 4: Conditional Execution and Staging
If exploitation progresses beyond instability, the adversary may obtain execution from NGINX worker, reverse proxy, ingress-controller, gateway, container, or service-account context and may retrieve supporting tooling or payload material.
· T1059 — Command and Scripting Interpreter
· T1105 — Ingress Tool Transfer
Stage 5: Conditional Credential, Secret, or Trust Access
If the affected host or workload exposes sensitive material, the adversary may attempt to access credentials, API keys, service-account tokens, cloud metadata, mounted secrets, configuration files, or application secrets.
· T1552 — Unsecured Credentials
· T1552.005 — Cloud Instance Metadata API
Stage 6: Conditional Internal Expansion or Operational Impact
If usable credentials, secrets, service-account material, backend reachability, or workload trust relationships are exposed, the adversary may access backend applications, internal APIs, databases, identity services, Kubernetes APIs, management interfaces, or other sensitive internal services. If access is sustained, the adversary may impair security tooling or disrupt services.
· T1021 — Remote Services
· T1078 — Valid Accounts
· T1562.001 — Impair Defenses: Disable or Modify Tools
· T1489 — Service Stop
Mapping Boundary
This MITRE mapping should not be interpreted as evidence that every NGINX Rift event includes execution, credential access, lateral movement, cloud activity, Kubernetes activity, or sustained impact. The only behaviors that should be assumed from suspicious external activity are exploit delivery and route probing. Service instability, execution, staging, credential access, internal expansion, defense evasion, and broader impact require corroborating telemetry.
S18 — Attack Path Narrative (Signal-Aligned Execution Flow)
Attack Path Purpose
NGINX Rift is best understood as an exposed reverse proxy and web-infrastructure exploit path. The attacker does not need trusted internal access to begin the attack path; the initial activity occurs through external malformed request delivery against internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure. The critical enterprise transition occurs when suspicious request activity moves beyond scan noise and aligns with service instability, suspicious NGINX-context execution, unusual egress, file activity, backend probing, cloud or Kubernetes activity, or credential exposure.
The attack path should remain signal-aligned. A malformed request alone is not compromise evidence. A worker crash alone is not confirmed exploitation. The strongest interpretation comes from correlating request telemetry, NGINX error logs, service-health events, endpoint telemetry, network egress, file activity, cloud telemetry, Kubernetes telemetry, and downstream application behavior.
Stage 1: External Exposure and Route Selection
The attacker identifies exposed NGINX-backed infrastructure and selects routes likely to interact with rewrite-heavy behavior, reverse proxy processing, ingress routing, gateway paths, customer-facing virtual hosts, authentication flows, API routes, administrative portals, payment paths, or high-dependency upstream applications.
Signal Alignment
· Internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent service exposure.
· Requests targeting rewrite-heavy paths, legacy application routes, authentication endpoints, API paths, administrative interfaces, payment flows, or ingress paths.
· Source activity from scanners, hosting providers, cloud infrastructure, VPNs, botnets, or newly observed external sources.
· Asset context showing exposed service role, patch state, rewrite-route exposure, route ownership, upstream dependency, or business criticality.
· Exposure alone should not be treated as exploitation evidence.
Stage 2: Malformed Request Delivery and Route Probing
The attacker sends malformed or abnormal HTTP request activity against exposed NGINX-backed services. Activity may involve encoded path expansion, repeated delimiters, unusual capture-like structures, abnormal URI length, double encoding, uncommon methods, malformed headers, suspicious query structure, request normalization failures, or repeated route variation.
Signal Alignment
· Abnormal URI structure, encoded character density, delimiter density, long request paths, or malformed path construction.
· Repeated probing of virtual hosts, route groups, ingress paths, gateway routes, or rewrite-heavy locations.
· Similar request shapes across multiple exposed NGINX-backed services.
· Source clustering by IP, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent family, or request pattern.
· WAF, CDN, load balancer, ingress, gateway, or reverse proxy telemetry showing request normalization failures, blocked malformed paths, upstream reset behavior, or abnormal routing outcomes.
Stage 3: Service Instability or Route-Level Impact
If the request activity interacts with vulnerable request-handling behavior, the affected service may show NGINX worker instability, segmentation fault indicators, abnormal worker exits, reload failures, route-specific degradation, elevated 500-series responses, upstream resets, gateway errors, health-check failures, container restarts, pod restarts, or customer-facing access disruption.
Signal Alignment
· NGINX error logs showing worker process failures, abnormal exits, segmentation fault indicators, request-processing failures, or reload failures.
· Route-specific 500-series spikes, gateway errors, upstream resets, backend failures, abnormal response timing, or health-check degradation.
· Service manager logs showing restarts, failed reloads, watchdog recovery, abnormal unit exits, or repeated worker respawns.
· Container or Kubernetes telemetry showing container restarts, pod restarts, crash-loop behavior, readiness probe failures, or liveness probe failures.
· Stronger confidence when instability occurs shortly after suspicious request activity against an exposed NGINX-backed route.
· Instability should not be treated as confirmed compromise without endpoint, file, network, identity, cloud, Kubernetes, or downstream application evidence.
Stage 4: Conditional Execution From NGINX Service Context
If exploitation progresses beyond service instability, the attacker may obtain or trigger execution from NGINX worker, reverse proxy, ingress-controller, gateway, containerized NGINX, or related service-account context. This stage is conditional and should only be asserted when endpoint or workload telemetry supports it.
Signal Alignment
· Child-process execution from NGINX master, worker, ingress-controller, gateway, reverse proxy, containerized NGINX, or related service-account lineage.
· Shells, interpreters, downloaders, file-transfer utilities, network utilities, package managers, archive tools, discovery utilities, credential utilities, or service-control utilities spawned from NGINX-related context.
· Suspicious command-line arguments involving remote retrieval, encoded commands, inline script execution, temporary-directory execution, output redirection, metadata access, credential access, mounted-secret access, or writable-path execution.
· Stronger confidence when process execution follows suspicious request activity, NGINX instability, route degradation, service restart, container restart, pod restart, or error-log artifacts.
· Execution from NGINX context should be treated as probable compromise evidence only when local telemetry confirms lineage, timing, and abnormality.
Stage 5: Conditional File, Configuration, Credential, or Secret Access
After execution or suspicious service-context activity, the attacker may stage files, modify configuration, access credentials, touch mounted secrets, retrieve service-account material, or interact with sensitive directories. This stage links reverse proxy exploitation to broader host, application, cloud, Kubernetes, or backend exposure.
Signal Alignment
· File creation, modification, deletion, permission changes, ownership changes, executable-bit changes, symbolic link creation, or archive extraction from NGINX-related context.
· Activity in web-accessible directories, temporary directories, writable application paths, NGINX configuration paths, ingress paths, gateway paths, mounted volumes, container writable layers, startup paths, service-unit paths, credential paths, cloud credential paths, or Kubernetes mounted-secret paths.
· Access to service-account tokens, application secrets, cloud credentials, Kubernetes secrets, configuration files, SSH material, or other trust material available to the affected service.
· Stronger confidence when file or credential activity follows suspicious child-process execution, NGINX worker instability, route degradation, unusual outbound communication, or exploit-path request activity.
· Normal deployment, certificate renewal, package updates, service reloads, configuration management, and incident-response workflows must be accounted for during triage.
Stage 6: Conditional Outbound Communication and Backend Expansion
If exploitation enables post-exploitation activity, the attacker may initiate outbound communication, retrieve tooling, contact callback infrastructure, probe backend applications, access internal APIs, interact with identity services, query cloud metadata, access Kubernetes APIs, or move toward sensitive internal services.
Signal Alignment
· First-seen outbound connections, direct IP egress, suspicious DNS lookups, rare destination contact, unusual TLS SNI, unexpected ports, beacon-like timing, or transfer behavior from NGINX hosts or workloads.
· Outbound communication initiated by child processes spawned from NGINX-related lineage.
· Internal access from NGINX infrastructure to backend applications, internal APIs, databases, identity services, cloud metadata endpoints, Kubernetes API servers, secret stores, CI/CD systems, artifact repositories, management interfaces, or regulated data paths.
· Destination novelty, destination reputation, source asset role, segmentation deviation, backend dependency mismatch, or access outside approved service mappings.
· Stronger confidence when outbound or internal activity follows suspicious request delivery, service instability, child-process execution, file activity, or credential access.
· Backend, cloud, or Kubernetes activity should be treated as post-exploitation evidence only when it is linked to the affected NGINX host, workload, route, service account, or time window.
Stage 7: Conditional Defense Evasion, Persistence, or Operational Impact
If access is sustained, the attacker may impair security tooling, alter service configuration, establish persistence, modify startup paths, tamper with logs, disrupt services, or degrade customer-facing application delivery. This stage is conditional and should not be assumed without supporting telemetry.
Signal Alignment
· Disabling or weakening endpoint agents, audit logging, cloud agents, container security controls, monitoring agents, vulnerability scanners, or telemetry forwarding.
· Modification of NGINX configuration, reverse proxy rules, ingress definitions, gateway configuration, service-unit files, startup scripts, scheduled tasks, SSH authorized keys, container entrypoints, or deployment manifests.
· Service interruption, route failure, upstream disruption, gateway instability, workload disruption, blocked legitimate traffic, customer-facing access degradation, or extended application outage.
· Suspicious cleanup behavior, log deletion, file deletion, timestamp manipulation, evidence removal, or monitoring-agent tampering.
· Stronger confidence when persistence, defense evasion, or impact follows confirmed execution, file activity, unusual egress, credential access, backend probing, cloud activity, or Kubernetes activity.
Residual Attack Path Position
The most consequential NGINX Rift scenario is not simple malformed request exposure. The highest-risk scenario is an exposed NGINX-backed service where suspicious malformed request activity produces route-specific instability and is followed by execution from NGINX service context, file or credential activity, unusual egress, backend probing, cloud metadata access, Kubernetes service-account interaction, or operational disruption. The report’s detection model should preserve the distinction between exploit attempt, likely service impact, probable compromise, and confirmed post-exploitation.
S19 — Attack Chain Risk Amplification Summary
Risk Amplification Overview
NGINX Rift amplifies enterprise risk because exposed reverse proxy and ingress infrastructure often sits directly between external users and internal applications. A single affected NGINX-backed service can disrupt access to multiple upstream applications, create emergency routing and filtering changes, complicate source attribution, and trigger broad investigation across web, endpoint, cloud, Kubernetes, identity, and application teams. The exploit path is most dangerous when malformed request activity aligns with vulnerable rewrite-heavy behavior and produces service instability or follow-on host activity.
Amplification Factor 1: Exposed Reverse Proxy Infrastructure Becomes a Business Dependency
NGINX-backed services commonly front authentication portals, API gateways, customer-facing applications, payment flows, administrative interfaces, and high-dependency upstream applications. Instability in this tier can affect more than a single server.
Business Effect
· Customer access may degrade or fail.
· Multiple upstream applications may be affected by one reverse proxy or ingress issue.
· Emergency routing, WAF, CDN, load balancer, ingress, or gateway changes may be required.
· Executive attention increases when authentication, API, payment, customer portal, or regulated application paths are involved.
Amplification Factor 2: Service Instability Can Create Impact Without Confirmed Compromise
NGINX Rift may produce worker crashes, route-specific 500-series spikes, upstream resets, gateway errors, reload failures, container restarts, pod restarts, or health-check failures. These outcomes can create operational impact even when child-process execution is not observed.
Business Effect
· Outage response may be required before compromise is confirmed.
· Customer-facing availability can become the primary incident concern.
· Teams may need to validate service health, route behavior, upstream dependencies, and compensating controls.
· Incident classification must separate denial-of-service impact from confirmed compromise.
Amplification Factor 3: Web-Tier Trust Can Lead to Downstream Exposure
If exploitation progresses beyond instability, the affected NGINX host or workload may have access to backend applications, internal APIs, service credentials, configuration files, cloud metadata, Kubernetes secrets, service accounts, mounted volumes, or management interfaces.
Business Effect
· Investigation scope may expand from web infrastructure to backend applications and identity paths.
· Credential and secret review may be required.
· Cloud, Kubernetes, container, and application teams may need to support scoping.
· Business impact increases when the affected service fronts sensitive or regulated workflows.
Amplification Factor 4: Cloud and Kubernetes Deployments Increase Scoping Complexity
Containerized, Kubernetes-managed, cloud-hosted, autoscaled, or ephemeral NGINX deployments may lose evidence during restarts, rescheduling, node replacement, image updates, or emergency remediation. Source identity and workload ownership may also be obscured by service mesh, NAT, load balancer, CDN, or gateway layers.
Business Effect
· Evidence preservation becomes time-sensitive.
· Pod, container, node, namespace, service-account, and workload identity mapping may be required.
· Cloud flow logs, Kubernetes audit logs, ingress telemetry, and endpoint telemetry must be reconciled.
· Incomplete telemetry can increase containment, legal, and executive-governance uncertainty.
Amplification Factor 5: Request Normalization and Logging Gaps Reduce Confidence
CDN, WAF, load balancer, gateway, ingress, and reverse proxy layers may normalize, truncate, rewrite, aggregate, or discard malformed request attributes. Many environments also lack raw URI retention, normalized URI retention, source IP preservation, request identifiers, upstream timing, or route-level logging.
Business Effect
· Analysts may struggle to reconstruct exploit-path activity.
· Source clustering and attacker infrastructure analysis may be unreliable.
· Organizations may need broader hunting due to incomplete request evidence.
· Confidence in exposure, exploitation, and containment may be delayed.
Amplification Factor 6: Vulnerable Exposure Can Be Misread
NGINX presence, vulnerable-version exposure, malformed requests, 500-series errors, or worker instability should not be treated as confirmed compromise by themselves. The opposite mistake is also dangerous: lack of child-process evidence does not rule out service-impact exploitation or telemetry loss in containerized and cloud environments.
Business Effect
· Overstating scan activity as compromise can waste response effort.
· Understating route degradation or worker instability can miss active exploitation.
· Executive reporting must distinguish exposure, attempted exploitation, likely denial-of-service impact, probable compromise, and confirmed post-exploitation.
· Response prioritization depends on correlated evidence rather than single-signal interpretation.
Residual Attack Chain Position
The most consequential NGINX Rift scenario is an exposed reverse proxy or ingress service where malformed request activity produces worker instability or route degradation and is followed by execution, unusual egress, file activity, credential access, backend probing, cloud metadata interaction, Kubernetes activity, or customer-facing disruption. The risk is highest where affected infrastructure fronts business-critical applications or trusted downstream services.
S20 — Tactics, Techniques, and Procedures

Figure 3
TTP Purpose
This section defines the attacker behaviors most relevant to NGINX Rift exploitation and post-exploitation assessment. It does not repeat the full ordered MITRE chain flow from S17. Instead, it groups the practical tactics, techniques, and procedures defenders should hunt for across web telemetry, NGINX error logs, endpoint telemetry, file telemetry, network telemetry, cloud telemetry, Kubernetes telemetry, and downstream application logs.
TTP 1: External Route Probing and Malformed Request Delivery
Tactic
Reconnaissance, Initial Access.
Techniques
Active Scanning, Exploit Public-Facing Application.
Procedure
The attacker identifies exposed NGINX-backed infrastructure and sends malformed request activity against routes that may interact with rewrite-heavy behavior, reverse proxy processing, ingress routing, gateway paths, or application-specific request handling. The activity may involve abnormal URI expansion, repeated encoding, double encoding, delimiter manipulation, capture-like route structures, uncommon methods, malformed headers, suspicious query structure, source rotation, or repeated route variation.
Defensive Relevance
This behavior should be evaluated against exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, customer-facing, authentication, API, payment, administrative, or high-dependency routes. Malformed request activity is an exploit-attempt signal, not compromise evidence, unless it is paired with service instability, endpoint activity, unusual egress, file activity, backend probing, or vulnerable asset context.
TTP 2: Request-to-Instability Triggering
Tactic
Impact.
Techniques
Endpoint Denial of Service.
Procedure
The attacker’s malformed request activity may trigger NGINX worker instability, segmentation fault indicators, abnormal worker exits, reload failures, route-specific 500-series spikes, upstream resets, gateway failures, health-check failures, container restarts, pod restarts, or customer-facing service degradation. This outcome may represent denial-of-service or instability even without confirmed execution.
Defensive Relevance
Request-to-instability correlation is one of the strongest detection paths for NGINX Rift. Analysts should prioritize cases where suspicious request activity immediately precedes worker crashes, error-log artifacts, route degradation, gateway errors, upstream failures, container restarts, pod restarts, or service-health changes. Instability should be scoped separately from confirmed compromise.
TTP 3: Conditional Execution From NGINX Service Context
Tactic
Execution.
Techniques
Command and Scripting Interpreter.
Procedure
If exploitation progresses beyond instability, the attacker may obtain execution from NGINX worker, reverse proxy, ingress-controller, gateway, containerized NGINX, or related service-account context. Follow-on commands may use shells, scripting interpreters, downloaders, package managers, archive utilities, file-transfer tools, network utilities, discovery commands, credential utilities, or service-control utilities.
Defensive Relevance
Unexpected child-process execution from NGINX-related lineage is a high-priority post-exploitation signal. Confidence increases when execution follows suspicious request activity, NGINX instability, route degradation, service restart, container restart, pod restart, or error-log artifacts. Approved maintenance, deployment automation, package activity, certificate renewal, and incident-response workflows must be excluded through local context.
TTP 4: Conditional Tool Retrieval, File Activity, or Configuration Change
Tactic
Execution, Persistence, Defense Evasion.
Techniques
Ingress Tool Transfer, Create or Modify System Process, Impair Defenses.
Procedure
The attacker may retrieve payloads, stage scripts, create binaries, modify files, change permissions, alter NGINX or reverse proxy configuration, touch startup paths, modify service units, interact with mounted volumes, or tamper with monitoring paths. Activity may occur in web-accessible directories, temporary directories, writable application paths, NGINX configuration paths, ingress paths, gateway paths, mounted volumes, container writable layers, or service locations.
Defensive Relevance
File, configuration, and persistence activity should be prioritized when initiated by NGINX-related processes or service accounts and when it follows exploit-path request activity, service instability, suspicious child-process execution, or unusual egress. Normal deployment, certificate renewal, package updates, service reloads, and configuration management activity must be accounted for before escalation.
TTP 5: Conditional Outbound Communication
Tactic
Command and Control.
Techniques
Ingress Tool Transfer.
Procedure
If execution or staging succeeds, the attacker may initiate outbound communication for callback, payload retrieval, staging, tunneling, or data transfer. Activity may involve direct IP connections, rare destinations, newly observed domains, suspicious DNS lookups, unusual ports, abnormal TLS SNI, infrastructure-like domains, paste services, file-sharing services, tunneling services, or beacon-like timing.
Defensive Relevance
Outbound communication is most significant when it originates from NGINX hosts, containers, workloads, or child processes after suspicious inbound request activity, worker instability, process execution, file activity, or credential access. Analysts should compare activity against approved upstream destinations, package repositories, observability platforms, security tools, service mesh endpoints, and documented application dependencies.
TTP 6: Conditional Backend, Cloud, Kubernetes, or Credential Access
Tactic
Credential Access, Discovery, Lateral Movement.
Techniques
Unsecured Credentials, Cloud Instance Metadata API, Remote Services, Valid Accounts.
Procedure
If the affected NGINX host or workload exposes trusted material, the attacker may access credentials, API keys, service-account tokens, cloud metadata endpoints, mounted secrets, configuration files, backend applications, internal APIs, databases, identity services, Kubernetes APIs, CI/CD systems, artifact repositories, management interfaces, or regulated data paths.
Defensive Relevance
Backend, cloud, Kubernetes, and credential activity should be treated as conditional post-exploitation evidence only when linked to the affected NGINX service, workload, route, host, service account, or time window. The strongest signals include new internal access, dependency-map deviation, cloud metadata interaction, Kubernetes service-account use, mounted-secret access, sensitive path access, or credential use after exploit-path indicators.
TTP 7: Conditional Defense Evasion, Persistence, or Service Impact
Tactic
Defense Evasion, Persistence, Impact.
Techniques
Impair Defenses, Create or Modify System Process, Service Stop.
Procedure
If access is sustained, the attacker may impair security tools, alter telemetry, modify services, establish persistence, stop services, change startup behavior, tamper with logs, or disrupt application delivery. These actions depend on attacker objective, access level, host role, and available permissions.
Defensive Relevance
Defense evasion, persistence, or impact should be prioritized when it occurs after suspicious request activity, service instability, NGINX-related process execution, unusual egress, file activity, credential access, backend probing, cloud activity, or Kubernetes activity. Impact should only be asserted when observed service disruption, workload interruption, control-plane abuse, or customer-facing degradation supports that conclusion.
Defensive TTP Model
The highest-value defensive model is behavioral correlation across seven attacker behavior families: external route probing, request-to-instability triggering, conditional execution from NGINX service context, conditional tool or file activity, conditional outbound communication, conditional backend or trust-material access, and conditional defense evasion, persistence, or impact. This structure preserves technical accuracy while keeping later figures usable, especially the attack path flow, behavior signal confidence matrix, detection coverage matrix, defensive architecture, and attack economics model.
S20A — Adversary Tradecraft Summary
Tradecraft Summary
NGINX Rift tradecraft is centered on external malformed request delivery against exposed NGINX-backed infrastructure and the defender’s ability to determine whether that activity remained probing, caused service instability, or progressed into post-exploitation behavior. The most important defensive transition is the movement from malformed request activity to worker instability, and then from instability to suspicious NGINX-context execution, unusual egress, file activity, backend probing, cloud activity, Kubernetes activity, or credential access.
Primary Tradecraft Themes
· Targeting of exposed NGINX-backed reverse proxy, ingress, gateway, and WAF-adjacent infrastructure.
· Use of malformed request structures, encoded paths, delimiter manipulation, uncommon methods, abnormal headers, suspicious query structures, and route variation.
· Focus on rewrite-heavy and high-dependency routes, including customer-facing, authentication, API, payment, administrative, ingress, gateway, and upstream application paths.
· Potential triggering of worker instability, segmentation fault indicators, reload failures, route degradation, upstream resets, gateway errors, container restarts, or pod restarts.
· Conditional execution from NGINX worker, reverse proxy, ingress-controller, gateway, containerized NGINX, or service-account context.
· Conditional tool retrieval, file staging, configuration change, credential access, mounted-secret access, outbound communication, backend probing, cloud metadata interaction, Kubernetes activity, defense evasion, persistence, or operational impact.
Detection-Relevant Tradecraft
The strongest detection path is not static request-string matching. The strongest detection path is behavioral correlation across exposed asset context, malformed request activity, route-specific instability, NGINX error-log artifacts, endpoint process lineage, file activity, unusual outbound communication, backend dependency deviation, cloud activity, Kubernetes activity, and downstream application anomalies.
Operational Tradecraft Assessment
Low-capability actors may rely on public request patterns, basic scanning, obvious route probing, and visible service-response changes. Moderate-capability actors may vary encoding, path structure, delimiters, headers, methods, timing, and source infrastructure to avoid simple request-string detection. Higher-capability actors may integrate NGINX Rift into broader intrusion workflows involving callback infrastructure, payload staging, backend discovery, cloud metadata access, Kubernetes service-account access, credential harvesting, and defense evasion.
Final Tradecraft Position
NGINX Rift should be treated as an exposed web-infrastructure exploit path that can produce scan noise, service instability, denial-of-service effects, or conditional post-exploitation depending on configuration, exposure, telemetry, and attacker capability. The vulnerability is most dangerous where NGINX-backed services front customer-facing applications, authentication flows, APIs, payment paths, administrative interfaces, regulated data paths, cloud workloads, Kubernetes ingress services, or high-value backend systems. Defensive success depends on quickly distinguishing malformed request noise from request-to-instability behavior and preventing confirmed NGINX-context execution from becoming credential exposure, backend expansion, cloud or Kubernetes compromise, persistence, or customer-facing disruption.
S21 — Detection Strategy Overview
Detection Philosophy
The detection strategy for NGINX Rift must prioritize behavior-led correlation across exposed web infrastructure, reverse proxy telemetry, worker-process stability, endpoint execution, outbound network activity, and post-exploitation indicators. This report should not treat any single malformed HTTP request, NGINX worker crash, suspicious URI, or scan artifact as standalone evidence of compromise. Detection confidence increases when exploit-attempt indicators align with service instability, abnormal NGINX child-process behavior, unexpected outbound communication, suspicious file activity, or follow-on host behavior.
The primary detection objective is to identify exploitation attempts against internet-facing NGINX, reverse proxy, ingress, WAF-adjacent, and web infrastructure before attacker activity progresses from request delivery into service disruption, code execution, persistence, credential access, or downstream application compromise.
The model should remain conservative because NGINX Rift exploitation depends on vulnerable rewrite-module behavior, deployment configuration, exposed request paths, and runtime hardening posture. The report should distinguish between attempted exploitation, probable exploitation, successful exploitation, and post-exploitation activity.
Primary Detection Anchors
· Malformed HTTP requests targeting NGINX-hosted paths, rewrite-enabled locations, reverse proxy routes, ingress paths, or WAF-adjacent web services.
· Abnormal URI structures involving encoded expansion, repeated delimiters, excessive escape sequences, unusual capture-like path elements, or malformed rewrite-triggering request patterns.
· NGINX worker crashes, segmentation faults, abnormal process exits, repeated worker respawns, reload loops, or service instability following suspicious inbound request activity.
· Elevated 500-series responses, upstream failures, reverse proxy instability, or sudden error-rate changes concentrated around specific virtual hosts, routes, rewrite-heavy paths, or source clusters.
· Unexpected process creation from NGINX worker or service lineage, including shell, interpreter, downloader, scripting, package-management, archive, or system-discovery utilities.
· Outbound connections from NGINX hosts to unusual IP addresses, newly observed domains, suspicious autonomous systems, anonymization infrastructure, or infrastructure not normally contacted by edge web services.
· File creation, permission modification, web-accessible artifact placement, temporary-directory execution, service modification, or persistence behavior occurring after NGINX instability or suspicious request bursts.
· Authentication, credential-access, or lateral-movement activity originating from NGINX hosts after suspected exploitation.
Detection Prioritization Model
· Highest priority should be assigned to correlated detections where suspicious inbound HTTP activity is followed by NGINX worker instability, unexpected child-process execution, outbound communication, or suspicious file activity.
· High priority should be assigned to NGINX worker crashes or restart loops that are temporally aligned with malformed requests to rewrite-enabled or reverse-proxy paths.
· Medium priority should be assigned to repeated malformed HTTP requests from external sources when the affected deployment uses rewrite-heavy configurations or hosts high-value exposed services.
· Medium priority should be assigned to abnormal 500-series spikes, proxy failures, or route-specific instability when paired with unusual URI structures or source concentration.
· Low priority should be assigned to standalone scan noise, generic malformed requests, isolated web errors, or unauthenticated probing without corroborating service, endpoint, or outbound activity.
· Detection severity should be increased when the affected host fronts authentication portals, customer-facing applications, administrative interfaces, API gateways, Kubernetes ingress paths, WAF-adjacent services, payment flows, identity infrastructure, or high-dependency internal applications.
· Detection severity should be reduced when the asset is confirmed non-vulnerable, patched, not using affected rewrite behavior, not internet-facing, or protected by compensating controls validated against the relevant request path.
Correlation Strategy (Strict Enforcement)
· Correlate suspicious HTTP request patterns with NGINX error logs, access logs, WAF logs, reverse proxy logs, ingress telemetry, and infrastructure monitoring within a short temporal window.
· Correlate NGINX worker crash, reload, or restart events with immediately preceding external request activity from the same source, source cluster, user-agent cluster, ASN, or request pattern.
· Correlate NGINX service instability with endpoint telemetry showing child-process creation, unusual command execution, file writes, memory faults, core dumps, privilege changes, or unexpected service-account activity.
· Correlate suspected exploit attempts with outbound network activity from the NGINX host, especially first-seen destinations, direct IP connections, suspicious DNS lookups, command-and-control-like traffic, or traffic from hosts that normally operate as inbound-only edge services.
· Correlate suspected exploitation with downstream application anomalies, including upstream service errors, unexpected authentication attempts, abnormal session creation, API abuse, or backend service access from the NGINX tier.
· Correlate vulnerability-management context with detection logic, including NGINX version, NGINX Plus status, rewrite-module usage, rewrite/set directive exposure, affected virtual hosts, ASLR posture, container or host hardening, WAF coverage, and patch status.
· Do not attribute suspicious outbound traffic, service crashes, or malformed requests to NGINX Rift unless the affected host is plausibly exposed to the relevant NGINX rewrite-module attack path.
· Do not elevate generic internet scanning into probable exploitation without at least one corroborating signal from service instability, endpoint execution, outbound communication, or vulnerable configuration context.
Telemetry Prioritization
· First priority telemetry should include NGINX access logs, NGINX error logs, reverse proxy logs, WAF logs, ingress controller logs, load balancer logs, HTTP request metadata, and route-specific response telemetry.
· Second priority telemetry should include EDR process lineage, Linux audit logs, service manager logs, container runtime telemetry, command execution logs, file-modification telemetry, and memory fault or crash artifacts.
· Third priority telemetry should include DNS logs, proxy logs, egress firewall logs, NetFlow, cloud flow logs, and outbound destination reputation or first-seen destination enrichment.
· Fourth priority telemetry should include vulnerability-management data, software inventory, exposed asset inventory, configuration-management data, rewrite-rule inventories, internet-facing asset discovery, and patch validation records.
· Supporting telemetry should include uptime monitoring, infrastructure health monitoring, application performance monitoring, 500-series response analytics, upstream failure rates, and reverse proxy dependency mapping.
· Cloud and container telemetry should be prioritized when NGINX is deployed as ingress, gateway, sidecar, reverse proxy, containerized edge service, or managed load-balancing component.
Detection Design Constraints
· Detection logic must not assume that all NGINX deployments are exploitable solely because NGINX is present.
· Detection logic must distinguish generic malformed HTTP traffic from request patterns plausibly interacting with vulnerable rewrite-module behavior.
· Detection logic must account for high background noise from internet scanning, vulnerability scanners, uptime monitors, web crawlers, bot traffic, and automated exploit testing.
· Detection logic must avoid treating worker crashes as compromise evidence unless correlated with suspicious inbound request activity, vulnerable configuration context, or follow-on host behavior.
· Detection logic must avoid treating outbound traffic from an NGINX host as NGINX Rift activity unless the outbound activity follows suspicious inbound request patterns or service instability.
· Detection logic must not require confirmed remote code execution to identify exploit attempts, because denial-of-service and crash behavior may be the first observable outcome.
· Detection logic must not overfit to a single public proof-of-concept request pattern because exploit payloads, URI encoding, path structure, and request delivery methods may change quickly.
· Detection logic must support both host-based and containerized NGINX deployments, including cases where process visibility, file-system visibility, or crash artifacts are incomplete.
· Detection logic must remain adaptable to NGINX Open Source, NGINX Plus, WAF-adjacent deployments, ingress deployments, and reverse proxy architectures.
Baseline and Deployment Requirements
· Organizations should establish normal request-volume baselines for exposed NGINX virtual hosts, route groups, ingress paths, rewrite-heavy locations, and reverse proxy services.
· Organizations should establish normal 400-series and 500-series response baselines for each exposed NGINX service, with separate baselines for customer-facing, administrative, API, and authentication paths.
· Organizations should establish normal NGINX worker restart, reload, crash, segmentation fault, and service-health baselines.
· Organizations should establish normal process lineage for NGINX workers and service accounts, including expected absence of shell, interpreter, downloader, package-management, discovery, and archive utilities.
· Organizations should establish normal outbound communication patterns for NGINX hosts, including approved upstream services, update repositories, observability platforms, log forwarders, package repositories, and management endpoints.
· Organizations should maintain an inventory of internet-facing NGINX services, NGINX Plus services, reverse proxy tiers, WAF-adjacent deployments, ingress controllers, gateway services, and NGINX Instance Manager-managed assets.
· Organizations should identify which deployments use rewrite-heavy configurations, rewrite directives, set directives, capture-based rewrites, or application paths that route through complex rewrite behavior.
· Organizations should map each exposed NGINX service to owner, business function, hosted application, upstream dependency, patch status, compensating controls, and logging coverage.
· Organizations should validate whether endpoint telemetry can capture NGINX child-process creation, memory faults, file writes, service changes, and outbound communication at the required fidelity.
· Organizations should validate whether WAF, reverse proxy, ingress, and load-balancer telemetry preserves the request attributes needed for exploit-attempt correlation.
Variant Resilience Requirements
· Detection logic should match behavior classes rather than a single exploit string, public PoC artifact, request example, URI path, or user-agent value.
· Detection logic should account for encoded, double-encoded, fragmented, case-varied, path-normalized, proxy-transformed, and route-specific request variations.
· Detection logic should account for low-and-slow probing, single-request crash attempts, distributed scanning, botnet-source rotation, and source infrastructure reuse.
· Detection logic should account for exploit attempts against non-obvious paths, including rewrite-heavy application routes, API endpoints, authentication paths, legacy virtual hosts, and ingress paths.
· Detection logic should account for attacker sequencing where exploit delivery is followed by delayed callback, delayed file retrieval, delayed persistence, or manual validation.
· Detection logic should support both denial-of-service outcomes and possible code-execution outcomes, without requiring both to occur.
· Detection logic should support asset-context enrichment so that patched or non-exposed assets are deprioritized while exposed rewrite-heavy services are prioritized.
· Detection logic should include negative controls for vulnerability scanners, authorized testing, uptime monitors, synthetic transaction tools, and internal QA systems.
Operational Detection Model
· Initial triage should determine whether the affected host is internet-facing, running an affected NGINX variant, using relevant rewrite behavior, and exposed through a route capable of receiving malicious HTTP requests.
· Triage should then determine whether suspicious request activity preceded NGINX worker instability, abnormal error responses, service restarts, or process crashes.
· If instability is confirmed, triage should pivot to EDR and host telemetry to identify child-process execution, command execution, temporary-file activity, suspicious file writes, privilege changes, or service modifications.
· If host activity is suspicious, triage should pivot to DNS, proxy, firewall, NetFlow, and cloud flow logs to identify outbound communication from the affected NGINX host.
· If outbound communication is present, triage should assess whether the destination is newly observed, rare for the asset, associated with suspicious infrastructure, or inconsistent with normal NGINX service behavior.
· If post-exploitation activity is observed, triage should expand to upstream applications, authentication systems, backend services, secrets, service accounts, containers, Kubernetes namespaces, and adjacent infrastructure.
· Confirmed exploit attempts should trigger emergency patch validation, configuration review, exposure reduction, WAF rule review, egress review, and asset-owner notification.
· Confirmed compromise should trigger containment of the affected NGINX host or container, preservation of logs and crash artifacts, credential rotation for exposed service accounts, review of upstream application access, and threat-hunting expansion across similarly configured services.
· Hunt-to-alert promotion should require validated field availability, local baseline testing, false-positive review, query performance testing, exception handling, and SOC triage readiness.
S22 — Primary Detection Signals
Primary Detection Signals
· Malformed HTTP requests directed at internet-facing NGINX services, reverse proxy routes, ingress paths, gateway paths, WAF-adjacent services, or rewrite-heavy application routes.
· HTTP requests containing abnormal URI expansion, repeated encoding, excessive escape sequences, malformed path delimiters, unusual capture-like structures, or route patterns inconsistent with normal application behavior.
· Suspicious request bursts followed by NGINX worker instability, segmentation faults, abnormal worker exits, repeated worker respawns, reload loops, or service-health degradation.
· Route-specific spikes in 500-series responses, upstream failures, gateway errors, connection resets, or proxy instability following unusual external request patterns.
· NGINX error-log artifacts showing memory faults, worker process failures, request-handling exceptions, abnormal rewrite behavior, or unexpected service termination.
· Unexpected process creation from NGINX worker or service-account lineage, especially shell, interpreter, downloader, scripting, archive, package-management, or system-discovery utilities.
· New or unusual outbound network communication from NGINX hosts after suspicious inbound request activity or worker instability.
· Suspicious file writes, temporary-directory execution, web-accessible artifact placement, permission changes, service modifications, or persistence-related behavior following suspected exploit activity.
Supporting Detection Signals
· Increased request volume against rewrite-enabled paths, legacy application routes, authentication endpoints, API paths, ingress routes, or high-dependency reverse proxy services.
· External source clustering where multiple IPs, ASNs, cloud providers, VPN providers, proxy networks, or hosting providers send similar malformed requests within a short time window.
· Repeated probing of multiple virtual hosts, route groups, URI structures, or path-normalization behaviors on the same NGINX service.
· Unusual user-agent rotation, missing user-agent values, malformed headers, abnormal content lengths, uncommon HTTP methods, or request metadata inconsistent with legitimate application clients.
· WAF, load balancer, CDN, ingress, or reverse proxy telemetry showing repeated request normalization failures, blocked malformed paths, upstream reset behavior, or abnormal backend routing outcomes.
· Infrastructure monitoring showing increased CPU, memory pressure, worker churn, container restarts, pod restarts, crash-loop behavior, or abnormal health-check failures on NGINX-hosted services.
· Vulnerability-management or configuration-management context showing affected NGINX versions, exposed rewrite behavior, rewrite-heavy configurations, unpatched services, weak hardening posture, or internet-facing deployment status.
· Asset context showing that the affected NGINX service fronts customer-facing applications, authentication portals, administrative interfaces, API gateways, payment flows, identity services, Kubernetes ingress paths, or high-value internal applications.
Exploit Attempt and Instability Signals
· Suspicious HTTP request activity followed by worker crash, segmentation fault, process abnormal termination, service restart, or reverse proxy instability within a short temporal window.
· Multiple malformed request attempts against the same route or virtual host followed by elevated 500-series responses, gateway errors, upstream failures, or request-handling failures.
· Low-volume single-request anomalies that cause worker instability, container restart, pod restart, service crash, or health-check failure.
· Distributed malformed request patterns where multiple external sources deliver similar payload structures to the same exposed NGINX service.
· Repeated attempts to discover rewrite behavior through path variation, delimiter manipulation, encoded path expansion, or probing of application routes likely to trigger rewrite handling.
· Crash-loop patterns affecting NGINX workers, containers, pods, or systemd-managed services after exposure to unusual external request activity.
· Error-log sequences where request-processing failures, worker termination, memory faults, or upstream errors align with suspicious URI structures.
· Monitoring artifacts showing sudden service degradation isolated to rewrite-heavy virtual hosts, application routes, or reverse proxy paths rather than broad infrastructure failure.
Outbound Communication Signals
· First-seen outbound connections from NGINX hosts after suspicious inbound request activity, worker instability, or crash artifacts.
· Direct outbound IP connections from NGINX hosts to destinations not normally contacted by the service.
· DNS lookups from NGINX hosts to newly observed, low-reputation, algorithmic, suspicious, or infrastructure-like domains following exploit-attempt indicators.
· Egress traffic from NGINX hosts to cloud hosting providers, VPS providers, anonymization infrastructure, paste sites, file-sharing services, tunneling services, or infrastructure inconsistent with normal application dependencies.
· Outbound HTTP, HTTPS, DNS, SSH, or unusual high-port traffic from NGINX hosts that normally operate as inbound-facing reverse proxy or web-serving systems.
· Beacon-like periodic outbound communication from NGINX hosts after service instability or suspicious process execution.
· Data transfer from NGINX hosts to unusual external destinations after malformed request bursts, worker crashes, or unexpected process execution.
· Outbound communication initiated by child processes spawned from NGINX worker or service-account lineage.
Persistence and Post-Exploitation Signals (Conditional)
· Creation or modification of files in web-accessible directories, temporary directories, service directories, startup paths, cron locations, systemd locations, container-mounted paths, or writable application directories after suspected exploitation.
· Unexpected shell scripts, binaries, web-accessible artifacts, encoded payloads, archive files, downloaded tools, or staging files appearing on NGINX hosts.
· Modification of NGINX configuration, reverse proxy configuration, service-unit files, container entrypoints, startup scripts, scheduled tasks, or application routing files after suspected exploitation.
· New user accounts, SSH key additions, privilege changes, service-account abuse, token access, or credential-material access from the affected NGINX host.
· Access to environment files, secrets, service-account tokens, API keys, application configuration files, cloud metadata services, or Kubernetes service-account material after suspected exploitation.
· Suspicious package installation, tool retrieval, archive extraction, binary execution, or script execution by the NGINX service account or related worker lineage.
· Unexpected persistence behavior inside containers, pods, host-mounted volumes, or orchestration-managed NGINX deployments.
· Evidence of attacker cleanup, log tampering, file deletion, timestamp manipulation, or disabling of monitoring agents after suspected exploitation.
Lateral Movement and Expansion Signals (Conditional)
· Authentication attempts from NGINX hosts to internal systems, databases, application servers, identity services, management planes, or cloud APIs after suspected exploitation.
· Network connections from NGINX hosts to internal hosts, private address ranges, backend services, container networks, Kubernetes control-plane components, or management interfaces not normally accessed by the NGINX tier.
· Service discovery, network scanning, port scanning, directory enumeration, cloud metadata access, Kubernetes API access, or internal API probing from the affected host.
· Credential-use anomalies involving service accounts, application accounts, cloud roles, Kubernetes service accounts, or secrets accessible from NGINX-hosted environments.
· Abnormal backend application access patterns originating from the NGINX tier after suspicious inbound request activity or process execution.
· Lateral movement indicators involving SSH, RDP, SMB, WinRM, database protocols, cloud APIs, orchestration APIs, or administrative interfaces from the affected NGINX host.
· Suspicious access to upstream applications, internal APIs, identity providers, secret stores, CI/CD systems, artifact repositories, or deployment infrastructure reachable from the reverse proxy tier.
· Reuse of credentials, tokens, session material, or service-account permissions associated with the affected NGINX environment.
Signal Usage Constraints
· Standalone malformed HTTP requests should be treated as exploit-attempt indicators, not compromise evidence, unless paired with instability, endpoint activity, outbound communication, or vulnerable asset context.
· Standalone NGINX worker crashes should be treated as instability indicators, not confirmed exploitation, unless suspicious request activity or vulnerable configuration context is present.
· Standalone 500-series response spikes should not be treated as NGINX Rift activity without route-level context, source clustering, suspicious URI structures, or service-instability correlation.
· Standalone outbound communication from NGINX hosts should not be attributed to NGINX Rift unless it follows suspicious inbound request activity, worker instability, abnormal process creation, or other exploit-path evidence.
· Public proof-of-concept request patterns should be used as one signal source only and should not define the full detection model.
· Detection logic should avoid assuming reliable remote code execution when the available evidence only supports exploit attempt, worker crash, denial-of-service behavior, or service instability.
· Vulnerability scanner activity, authorized validation, emergency patch testing, uptime monitoring, synthetic transactions, CDN health checks, load balancer probes, and QA testing must be accounted for during triage.
· Signal confidence should increase only when request telemetry, service telemetry, endpoint telemetry, network telemetry, and asset-context enrichment support the same exploit-path narrative.
· Signal confidence should decrease when the asset is patched, not internet-facing, not using relevant rewrite behavior, shielded from the relevant request path, or protected by validated compensating controls.
· Hunt-to-alert promotion should occur only after local baseline validation, schema mapping, field availability review, false-positive testing, enrichment validation, exception handling, query performance testing, and SOC triage readiness are complete.
S23 — Telemetry Requirements
Endpoint and Process Execution Telemetry
· EDR telemetry must capture process lineage for NGINX master processes, worker processes, service accounts, containerized NGINX processes, ingress-controller processes, and related reverse proxy service contexts.
· Process telemetry should identify unexpected child processes spawned from NGINX worker or service lineage, including shell, interpreter, downloader, scripting, archive, package-management, discovery, network, credential-access, and file-transfer utilities.
· Linux audit telemetry should capture command execution, parent-child process relationships, user context, working directory, executed binary path, command-line arguments, process start time, process termination time, exit status, and host identity.
· Service manager telemetry should capture NGINX reloads, restarts, worker exits, abnormal service stops, failed reload attempts, watchdog recovery events, service recovery activity, and process supervision events.
· Container runtime telemetry should capture container process execution, container image identity, entrypoint changes, namespace context, mounted volumes, container exit codes, pod restarts, crash-loop behavior, and container-to-host process relationships.
· Kubernetes telemetry should capture pod restarts, container restarts, ingress controller behavior, service-account context, namespace context, workload owner, node placement, mounted secrets, mounted configuration, and abnormal process execution within NGINX-managed workloads.
· Endpoint telemetry should preserve the execution context needed to distinguish normal administrative maintenance from suspicious process execution following malformed HTTP requests, NGINX instability, or crash artifacts.
· Process telemetry should include sufficient timestamp fidelity to correlate suspicious inbound request activity with worker instability, service restarts, process creation, file writes, and outbound network activity.
Memory and Execution Telemetry
· Memory fault telemetry should capture segmentation faults, illegal instruction events, abnormal memory access, process crashes, core dump generation, kernel fault messages, exploit-mitigation events, and abnormal termination involving NGINX worker processes.
· Host telemetry should capture crash artifacts associated with nginx, NGINX Plus, ingress-controller processes, containerized NGINX processes, gateway services, or WAF-adjacent NGINX worker contexts.
· Runtime telemetry should capture abnormal process termination, signal-based exits, unexpected worker death, worker respawn behavior, repeated crash patterns, and service instability following suspicious inbound request activity.
· EDR telemetry should capture exploit-adjacent behavior when available, including abnormal execution transitions, suspicious memory behavior, exploit prevention alerts, post-crash process activity, and child-process creation after worker instability.
· Operating system logs should preserve kernel messages, audit events, service manager records, crash reports, coredump metadata, and host identifiers associated with NGINX worker instability.
· Core dump handling should preserve relevant metadata where operationally safe, including process name, timestamp, signal, user context, binary path, container context, host identifier, and service owner.
· Memory and execution telemetry should support correlation with request logs so that crash timing can be mapped to source activity, route context, request pattern, affected virtual host, and exposed service.
· Memory and execution telemetry should not be treated as sufficient by itself unless paired with suspicious request context, vulnerable asset context, service instability, or follow-on host behavior.
Crash and Fault Telemetry
· NGINX error logs must capture worker process failures, abnormal exits, segmentation faults, request-processing failures, upstream errors, rewrite-processing anomalies, reload failures, and service termination artifacts.
· System logs should capture service restarts, failed reloads, abnormal unit exits, watchdog recovery events, crash-loop behavior, repeated worker respawn patterns, resource pressure, and kernel-level fault messages.
· Infrastructure monitoring should capture availability degradation, health-check failures, increased error rates, route-specific service instability, upstream reset behavior, reverse proxy failure patterns, and sudden latency changes.
· Container and orchestration telemetry should capture pod restart counts, container exit codes, crash-loop backoff, readiness probe failures, liveness probe failures, node-level resource pressure, workload rescheduling, and restart timing.
· Application performance telemetry should capture sudden latency increases, request failure spikes, route-specific degradation, upstream dependency errors, gateway failure patterns, and backend service disruption after suspicious inbound traffic.
· Log collection should preserve enough event ordering to determine whether malformed request activity preceded instability rather than occurring after unrelated service degradation.
· Crash telemetry should support route-level and virtual-host-level analysis when multiple applications, ingress paths, gateway routes, or reverse proxy services share the same NGINX infrastructure.
· Crash and fault telemetry should be enriched with asset criticality, exposure status, patch status, rewrite-configuration status, service owner, business function, and upstream dependency information.
File and Persistence Telemetry
· File telemetry should capture new file creation, file modification, permission changes, ownership changes, file deletion, executable-bit changes, symbolic link creation, archive extraction, and suspicious file placement on NGINX hosts or containers.
· Monitoring should cover web-accessible directories, temporary directories, service directories, configuration directories, mounted volumes, writable application directories, startup paths, cron locations, systemd locations, user home directories, and log directories.
· Configuration monitoring should capture changes to NGINX configuration, reverse proxy configuration, rewrite rules, upstream routing, WAF-adjacent policy files, ingress resources, gateway configuration, service-unit files, container entrypoints, and deployment manifests.
· Endpoint telemetry should capture creation or execution of shell scripts, ELF binaries, web-accessible artifacts, archive files, encoded payloads, downloaded tools, staged payloads, and temporary execution files after suspected exploitation.
· Persistence telemetry should capture new scheduled tasks, service changes, startup-script modifications, SSH key additions, user-account changes, privilege changes, token access, credential-material access, and monitoring-agent tampering.
· Container telemetry should capture changes within writable layers, mounted secrets, mounted configuration files, host-mounted paths, persistent volumes, init containers, sidecars, and shared application directories associated with NGINX workloads.
· Cloud and orchestration telemetry should capture changes to secrets, service accounts, role bindings, ingress definitions, gateway configuration, security groups, load balancer listeners, deployment specifications, container images, and workload identities when NGINX is deployed in cloud or Kubernetes environments.
· File and persistence telemetry should be correlated with suspicious request activity, NGINX instability, process execution, outbound communication, and vulnerable asset context before being treated as likely exploitation.
Network and Outbound Communication Telemetry
· DNS telemetry should capture lookups from NGINX hosts, containers, nodes, and service accounts to newly observed domains, suspicious infrastructure, rare destinations, dynamic DNS, infrastructure-like domains, and destinations inconsistent with normal service behavior.
· Proxy telemetry should capture outbound HTTP and HTTPS activity from NGINX hosts, including destination, method, user agent, URI path, response code, bytes transferred, session duration, request timing, and first-seen destination context.
· Firewall telemetry should capture egress connections from NGINX hosts to external IP addresses, unusual ports, cloud-hosted infrastructure, anonymization infrastructure, file-sharing services, paste sites, tunneling services, and destinations outside approved dependency lists.
· NetFlow and cloud flow logs should capture outbound connection timing, destination IP, destination port, protocol, byte counts, session duration, connection direction, source interface, workload identity, and network boundary context from NGINX hosts and reverse proxy tiers.
· Network telemetry should distinguish normal upstream application communication from unusual direct outbound internet communication by NGINX hosts that normally function as inbound-facing edge services.
· Egress telemetry should support correlation with suspicious inbound request activity, worker instability, abnormal process creation, suspicious file writes, credential-access behavior, or suspected post-exploitation activity.
· Network telemetry should include destination reputation, ASN context, geolocation, first-seen timing, historical asset communication profile, known-good dependency enrichment, and source workload context when available.
· Outbound communication should not be attributed to NGINX Rift unless it aligns with vulnerable asset context and upstream exploit-path evidence.
Web and Application Telemetry (Conditional Availability)
· NGINX access logs should capture source IP, destination host, virtual host, request method, URI, query string, response code, bytes sent, user agent, referrer, upstream response time, request time, request identifier, upstream service, and route context where available.
· NGINX error logs should capture request-processing failures, rewrite-related anomalies, upstream errors, worker failures, abnormal termination messages, reload failures, configuration errors, and virtual-host context where available.
· WAF telemetry should capture blocked requests, allowed suspicious requests, normalized URI values, raw URI values, rule matches, payload inspection results, anomaly scores, source clustering, request headers, and policy actions.
· Load balancer, CDN, gateway, and reverse proxy telemetry should capture request normalization behavior, upstream resets, gateway failures, routing outcomes, source IP preservation, forwarded headers, request path, host header, TLS termination context, and backend service mapping.
· Ingress telemetry should capture ingress resource, namespace, service name, backend workload, route path, controller logs, annotation context, request outcome, source identity, and workload ownership when NGINX operates as an ingress controller.
· Application telemetry should capture downstream authentication anomalies, backend API errors, unexpected session creation, abnormal upstream access, application-specific route failures, and backend dependency failures after suspicious NGINX request activity.
· Web telemetry should preserve both raw and normalized request values where possible because exploit delivery may rely on encoding, path handling, request transformation, rewrite behavior, or route-specific processing.
· Web and application telemetry should support route-level analysis so suspected exploit attempts can be mapped to exposed rewrite-heavy locations, virtual hosts, ingress paths, gateway routes, reverse proxy services, and upstream dependencies.
Telemetry Availability Requirements
· NGINX access and error logs must be retained at sufficient fidelity to support route-level, virtual-host-level, timestamp-level, source-level, and request-pattern correlation.
· EDR or host telemetry must be available on NGINX servers, reverse proxy hosts, ingress nodes, gateway nodes, container hosts, and Kubernetes nodes where NGINX workloads are deployed.
· DNS, proxy, firewall, NetFlow, or cloud flow telemetry must be available for NGINX hosts and workloads to support outbound communication analysis.
· Vulnerability-management data must identify affected NGINX versions, NGINX Plus deployments, F5-managed NGINX products, rewrite-module exposure, patch status, compensating controls, and internet-facing exposure.
· Configuration-management data must identify rewrite-heavy deployments, exposed virtual hosts, route groups, ingress paths, gateway paths, reverse proxy tiers, WAF-adjacent services, and service ownership.
· Asset inventory must identify internet-facing NGINX services, customer-facing applications, authentication portals, API gateways, Kubernetes ingress paths, administrative interfaces, high-value upstream dependencies, and business-critical service owners.
· Logging pipelines must preserve source IP context through CDN, load balancer, reverse proxy, and ingress layers so suspicious request clusters can be investigated accurately.
· Timestamps must be normalized across web logs, host telemetry, crash telemetry, EDR telemetry, DNS logs, proxy logs, firewall logs, cloud flow logs, Kubernetes logs, and application telemetry.
· Telemetry must support correlation across request delivery, service instability, process execution, file activity, outbound communication, downstream application behavior, and vulnerability context.
· Retention windows must be sufficient to support delayed exploitation analysis, delayed outbound callback review, post-exploitation investigation, retroactive hunting, and amendment updates after new exploit patterns emerge.
Telemetry Limitations and Gaps
· Many environments may not preserve raw URI values after CDN, WAF, load balancer, ingress, reverse proxy, or application normalization.
· Some logging pipelines may truncate long URIs, omit query strings, remove encoded characters, normalize delimiters, drop malformed request fields, or aggregate request data in ways that reduce exploit-attempt visibility.
· NGINX error logs may not provide enough detail to prove rewrite-module exploitation without correlation to request telemetry, crash artifacts, vulnerable configuration context, or follow-on host behavior.
· EDR coverage may be incomplete on hardened edge systems, container hosts, minimal Linux builds, ingress nodes, appliances, managed NGINX deployments, or ephemeral workloads.
· Containerized deployments may lose file, process, or crash artifacts when pods restart, containers are rescheduled, writable layers are discarded, nodes are replaced, or crash-loop behavior overwrites useful evidence.
· Cloud and Kubernetes environments may obscure source identity, host identity, workload identity, route ownership, and request path context unless logging and enrichment are configured before exploitation.
· NAT, CDN, proxy, and load balancer layers may obscure true source IP attribution and complicate source clustering, attacker infrastructure analysis, and exploit-path reconstruction.
· High-volume internet scanning may create significant false-positive pressure for malformed HTTP request detections.
· Worker crashes may result from benign operational issues, configuration errors, resource pressure, dependency failures, patch activity, authorized testing, or unrelated application faults.
· Outbound connections may reflect legitimate observability, package updates, upstream application dependencies, health checks, administrative workflows, or approved service integrations unless asset-specific baselines are available.
· Detection confidence may remain limited where organizations lack rewrite-configuration inventory, patch validation, route mapping, exposure context, service ownership, or business-criticality enrichment.
· Investigation quality may be reduced where logs are not time-synchronized, retained, enriched, normalized, or mapped to asset ownership and service dependency context.
S24 — Detection Opportunities and Gaps
Detection Opportunities
· Organizations can identify early exploitation attempts by correlating malformed HTTP requests against exposed NGINX services with NGINX worker instability, segmentation faults, abnormal restarts, elevated 500-series responses, upstream failures, or reverse proxy degradation.
· Organizations can improve exploit-path visibility by prioritizing route-level monitoring for rewrite-heavy locations, ingress paths, gateway routes, reverse proxy services, authentication paths, API paths, customer-facing virtual hosts, and high-dependency upstream applications.
· Organizations can detect possible successful exploitation by correlating suspicious inbound request activity with unexpected child-process execution from NGINX worker, ingress-controller, gateway, or service-account lineage.
· Organizations can identify post-exploitation behavior by correlating NGINX instability with file writes, temporary-directory execution, configuration changes, service modifications, credential-material access, monitoring-agent tampering, and outbound communication.
· Organizations can reduce false positives by enriching detections with NGINX version, NGINX Plus status, F5-managed NGINX product status, patch state, rewrite-module exposure, exposed route context, service owner, asset criticality, internet exposure, and compensating-control status.
· Organizations can use WAF, CDN, load balancer, reverse proxy, gateway, and ingress telemetry to identify abnormal request normalization behavior, source clustering, malformed path patterns, upstream resets, gateway failure patterns, and route-specific service degradation.
· Organizations can identify exploit validation activity by tracking repeated malformed request attempts from common source clusters, cloud-hosted infrastructure, VPS providers, scanner infrastructure, suspicious autonomous systems, or rotating external infrastructure.
· Organizations can improve detection resilience by matching behavior classes rather than relying on one public proof-of-concept string, request path, payload shape, user-agent value, URI pattern, or exploit demonstration.
· Organizations can use crash and service-health telemetry to detect denial-of-service outcomes even when endpoint telemetry does not show child-process execution or confirmed code execution.
· Organizations can use outbound DNS, proxy, firewall, NetFlow, and cloud flow telemetry to identify callback, staging, tool retrieval, command-and-control, or data-transfer behavior from NGINX hosts after suspected exploit activity.
· Organizations can use Kubernetes and container telemetry to identify pod restarts, crash-loop behavior, abnormal process execution, mounted-secret access, service-account abuse, workload modification, ingress changes, and internal service probing in ingress or containerized NGINX environments.
· Organizations can use configuration inventory to prioritize exposed rewrite-heavy services for monitoring, patch validation, compensating controls, emergency response, and post-disclosure retroactive hunting.
· Organizations can use service dependency mapping to determine whether exposed NGINX services front authentication systems, payment flows, customer portals, API gateways, administrative interfaces, internal applications, or regulated data paths.
· Organizations can use retroactive hunting when new exploit variants, request patterns, vendor advisories, public proof-of-concept changes, or exploitation telemetry emerge after the initial disclosure.
High-Value Detection Paths
· Suspicious external HTTP request activity followed by NGINX worker crash, segmentation fault, abnormal restart, elevated error rate, or route-specific degradation.
· Suspicious malformed request activity followed by child-process execution from NGINX worker, ingress-controller, gateway, or service-account lineage.
· Suspicious request burst against rewrite-heavy routes followed by outbound communication from the affected NGINX host, container, workload, node, or reverse proxy tier.
· Route-specific 500-series spike or reverse proxy instability paired with abnormal URI structures, source clustering, request normalization failures, or repeated access to rewrite-heavy paths.
· Worker crash, container restart, or pod restart followed by file writes, temporary execution, configuration modification, credential access, monitoring-agent tampering, or persistence behavior.
· Ingress-controller or gateway instability followed by Kubernetes service-account access, mounted-secret access, workload modification, role-binding changes, internal service probing, or abnormal API access.
· Exposed NGINX service with vulnerable version and relevant rewrite configuration receiving repeated malformed request attempts from external infrastructure.
· Public exploit-pattern activity observed across multiple NGINX assets, virtual hosts, ingress paths, gateway routes, or reverse proxy services within a short time window.
· Suspicious inbound request activity followed by access to upstream applications, authentication services, backend APIs, cloud metadata services, secrets, or internal management interfaces.
· Sudden NGINX service instability on a business-critical exposed service where normal deployment activity, patching, resource pressure, and authorized testing have been ruled out.
Detection Gaps
· Detection coverage may be limited where organizations do not retain raw URI values, normalized URI values, query strings, request identifiers, host headers, source IP context, forwarded headers, upstream timing, request timing, or route-level request metadata.
· Detection coverage may be limited where CDN, WAF, load balancer, reverse proxy, gateway, or ingress layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes before logging.
· Detection coverage may be limited where NGINX error logs do not preserve worker crash detail, segmentation fault artifacts, virtual-host context, request context, upstream context, reload failure information, or worker termination metadata.
· Detection coverage may be limited where endpoint or EDR telemetry is unavailable on NGINX hosts, ingress nodes, container hosts, gateway nodes, hardened edge systems, appliances, managed NGINX deployments, or ephemeral workloads.
· Detection coverage may be limited where containerized NGINX deployments lose crash, file, process, runtime, or workload evidence during pod restart, rescheduling, crash-loop behavior, image replacement, node rotation, or emergency remediation.
· Detection coverage may be limited where organizations lack rewrite-configuration inventory, exposed route mapping, virtual-host ownership, patch validation, service dependency mapping, compensating-control status, or business-criticality enrichment.
· Detection coverage may be limited where outbound network telemetry cannot reliably distinguish normal upstream communication from unusual direct internet egress by NGINX hosts, containers, nodes, or workloads.
· Detection coverage may be limited where NAT, CDN, proxy, load balancer, or shared egress layers obscure true source identity, source clustering, user-agent patterns, attacker infrastructure reuse, and request sequencing.
· Detection coverage may be limited where service restarts, worker crashes, pod restarts, or elevated 500-series responses are common due to routine operational issues, resource pressure, deployment activity, misconfiguration, dependency failures, or authorized testing.
· Detection coverage may be limited where organizations lack synchronized timestamps across request logs, error logs, EDR telemetry, crash telemetry, DNS logs, proxy logs, firewall logs, cloud flow logs, Kubernetes logs, container runtime logs, and application telemetry.
· Detection coverage may be limited where web infrastructure telemetry is retained for short periods and cannot support delayed callback analysis, retroactive hunting, amendment-driven exploit-pattern review, or post-incident reconstruction.
· Detection coverage may be limited where public proof-of-concept indicators are used as the primary detection method instead of broader behavior-led correlation.
· Detection coverage may be limited where source IP preservation fails across chained infrastructure, making it difficult to distinguish a single exploit operator from shared CDN, proxy, scanner, or cloud infrastructure.
· Detection coverage may be limited where managed NGINX, appliance-based, or WAF-adjacent deployments restrict host access, core dump access, shell visibility, file-system visibility, or process telemetry.
False-Positive Pressure Points
· Internet-wide vulnerability scanning, automated exploit testing, bot traffic, malformed crawler traffic, fuzzing, and opportunistic probing may generate request patterns similar to early exploit attempts.
· Authorized vulnerability scanning, emergency patch validation, QA testing, synthetic transactions, uptime monitoring, CDN health checks, load balancer probes, and application testing may create benign malformed request or error-rate artifacts.
· Application bugs, configuration errors, upstream dependency failures, resource exhaustion, deployment changes, patch activity, certificate changes, and operational maintenance may cause NGINX restarts, worker exits, or 500-series response increases.
· Legitimate administrative activity may produce NGINX reloads, service restarts, configuration changes, temporary files, package activity, container replacement, deployment updates, or outbound connections to approved repositories and observability platforms.
· Normal reverse proxy behavior may include outbound communication to upstream applications, backend services, logging pipelines, package repositories, security tools, monitoring platforms, internal APIs, identity services, and health-check destinations.
· Container rescheduling, pod restarts, readiness probe failures, liveness probe failures, node pressure, deployment rollouts, autoscaling, and image updates may resemble instability unless correlated with suspicious inbound request activity.
· CDN, WAF, load balancer, gateway, and ingress normalization may alter request patterns in ways that make benign and malicious traffic difficult to distinguish without raw and normalized request visibility.
· Source IP clustering may be unreliable when traffic passes through shared proxies, NAT, CDN infrastructure, VPN services, cloud providers, security scanners, or enterprise egress gateways.
· Security tools and web testing platforms may intentionally generate malformed paths, encoded requests, abnormal methods, unusual headers, or replayed exploit patterns during authorized validation.
· High-traffic public applications may produce route-specific error spikes from benign client behavior, release defects, backend instability, or traffic surges that resemble exploit-driven degradation.
False-Negative Pressure Points
· Exploit attempts may use encoded, double-encoded, fragmented, case-varied, normalized, low-volume, single-request, or route-specific payloads that do not match public proof-of-concept patterns.
· Exploit attempts may target obscure rewrite-heavy routes, legacy application paths, API routes, ingress paths, gateway routes, virtual hosts, or backend-facing paths that are not included in high-priority monitoring.
· Successful exploitation may not produce obvious child-process execution if the observable outcome is worker crash, denial of service, memory corruption without visible process creation, or delayed post-exploitation activity.
· Successful exploitation may use living-off-the-land commands, existing service permissions, approved outbound channels, normal-looking process names, or trusted administrative paths to reduce detection visibility.
· Attackers may delay outbound communication, rotate infrastructure, use common cloud providers, use direct IP connections, reuse permitted egress paths, or stage through approved application dependencies to avoid immediate callback detection.
· Attackers may tamper with logs, delete temporary files, avoid persistence, operate in memory, disable monitoring, or rely on ephemeral containers where evidence is lost after restart.
· Edge, appliance-based, and managed deployments may restrict EDR visibility, shell visibility, file-system visibility, core dump access, or host-level telemetry.
· Short retention windows may prevent investigation when new exploit details emerge after the initial request, crash, callback, or post-exploitation event.
· Incomplete asset inventory may cause exposed rewrite-heavy services to be excluded from monitoring, patch validation, compensating-control review, or priority triage.
· Incomplete source IP preservation may prevent analysts from connecting related attempts across CDN, proxy, load balancer, gateway, and ingress layers.
· Insufficient configuration inventory may prevent analysts from determining whether a suspicious route is plausibly exposed to vulnerable rewrite behavior.
· Weak egress visibility may prevent analysts from distinguishing attacker callback behavior from normal upstream communication or observability traffic.
Operational Gaps
· Some organizations may not know which NGINX services are internet-facing, business-critical, reverse proxy front doors, WAF-adjacent, ingress-controlled, gateway-based, or tied to high-value upstream applications.
· Some organizations may not maintain an inventory of rewrite-heavy configurations, rewrite directives, set directives, capture-based routing, virtual-host mappings, ingress rules, gateway routes, or route-specific exposure.
· Some organizations may lack service-owner mapping, which can delay triage, patch validation, compensating-control decisions, exposure reduction, and business-impact assessment.
· Some organizations may not retain enough NGINX access-log or error-log detail to reconstruct exploit-path activity.
· Some organizations may not have EDR coverage on hardened edge systems, minimal Linux builds, container nodes, managed appliances, Kubernetes ingress environments, or short-lived workloads.
· Some organizations may lack egress baselines for NGINX hosts, making it difficult to distinguish legitimate upstream communication from attacker callback, staging, tool retrieval, or data-transfer behavior.
· Some organizations may not collect cloud, Kubernetes, ingress, gateway, or workload telemetry at a level sufficient to identify service-account abuse, mounted-secret access, workload changes, internal service probing, or role-binding modification.
· Some organizations may lack tested incident-response workflows for public-facing reverse proxy exploitation, causing delays in containment, evidence preservation, credential rotation, upstream application review, and customer-impact assessment.
· Some organizations may rely on patch status alone without validating whether vulnerable routes, rewrite behavior, compensating controls, exposed infrastructure, and route-level protections are actually covered.
· Some organizations may lack a safe process for preserving crash artifacts, core dump metadata, container evidence, WAF logs, and request telemetry during emergency remediation.
· Some organizations may not have a tested process for correlating web telemetry with endpoint, network, container, Kubernetes, and application telemetry during time-sensitive exploitation events.
· Some organizations may not have pre-approved emergency change windows for exposed reverse proxy, ingress, gateway, or WAF-adjacent infrastructure.
Detection Engineering Opportunities
· Build correlation logic that links suspicious request patterns, affected asset context, service instability, endpoint execution, outbound communication, file activity, and downstream application behavior into a single exploit-path model.
· Build route-aware detections that prioritize rewrite-heavy locations, exposed virtual hosts, ingress paths, gateway routes, authentication flows, API routes, administrative paths, and high-value reverse proxy services.
· Build crash-to-request correlation detections that identify suspicious external requests preceding worker exits, segmentation faults, crash loops, container restarts, pod restarts, or elevated error rates.
· Build process-lineage detections for shell, interpreter, downloader, scripting, package-management, archive, network, file-transfer, credential-access, discovery, and persistence utilities spawned from NGINX worker, ingress-controller, gateway, or service-account context.
· Build outbound communication detections for first-seen destinations, rare destinations, direct IP connections, unusual ports, infrastructure-like domains, suspicious ASNs, unapproved egress, and non-baselined communication from NGINX hosts.
· Build file and persistence detections for new artifacts, executable files, temporary execution, configuration changes, mounted-secret access, service modifications, scheduled-task changes, role-binding changes, and monitoring-agent tampering after suspected exploitation.
· Build container and Kubernetes detections for crash-loop behavior, abnormal process execution, mounted-secret access, service-account abuse, workload modification, ingress changes, role-binding changes, and internal service probing after suspicious ingress activity.
· Build vulnerability-context enrichment using NGINX version, NGINX Plus status, F5-managed NGINX product status, patch state, rewrite exposure, internet exposure, asset criticality, route ownership, and service ownership.
· Build exception handling for approved scanners, emergency validation, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, QA testing, deployment workflows, patch activity, and known administrative maintenance.
· Build retroactive hunting queries that can be updated when public exploit patterns, vendor advisories, observed exploitation details, or amendment-relevant indicators change.
· Build confidence-scored hunting logic that separates exploit attempts, likely denial-of-service impact, probable compromise, and confirmed post-exploitation behavior.
· Build dependency-aware detections that prioritize NGINX assets fronting authentication portals, API gateways, customer applications, administrative services, payment flows, and regulated data paths.
Detection Confidence Model
· High-confidence detection requires suspicious inbound request activity, plausible vulnerable asset context, and at least one corroborating signal from service instability, endpoint execution, outbound communication, file activity, credential access, downstream application behavior, or container and Kubernetes activity.
· Medium-confidence detection applies when suspicious inbound request activity targets an exposed rewrite-heavy NGINX service and is paired with route-level error spikes, upstream failures, source clustering, request normalization anomalies, or worker instability.
· Low-confidence detection applies when malformed HTTP traffic is observed without vulnerable configuration context, service instability, endpoint activity, outbound communication, route-level impact, or affected asset enrichment.
· Detection confidence should increase when the affected host is internet-facing, unpatched, rewrite-heavy, business-critical, WAF-adjacent, ingress-facing, gateway-facing, or responsible for authentication, API, payment, administrative, identity, or customer-facing services.
· Detection confidence should decrease when the asset is patched, not internet-facing, not using relevant rewrite behavior, shielded from the relevant request path, or associated with authorized testing, known benign scanner activity, deployment activity, or maintenance.
· Successful exploitation assessment should require more than malformed request activity or worker crash evidence. It should include follow-on process execution, file activity, outbound communication, credential access, persistence, lateral movement, container activity, Kubernetes activity, or downstream application impact.
· Denial-of-service assessment may be supported by suspicious request activity followed by worker crashes, service restarts, elevated error rates, route degradation, container restarts, pod restarts, or repeated availability failures, even when code execution is not observed.
· Attempted exploitation assessment may be supported by suspicious request activity against plausibly vulnerable exposed paths, but should remain lower confidence until instability, process activity, outbound traffic, or configuration context increases confidence.
Hunt-to-Alert Promotion Opportunities
· Promote request-to-crash correlation logic when NGINX access logs, NGINX error logs, route context, source context, request identifiers, timestamp fidelity, and worker crash telemetry are locally validated.
· Promote process-lineage logic when EDR or host telemetry reliably captures parent process, child process, command line, user context, working directory, binary path, host identity, and service-account context for NGINX workers.
· Promote outbound communication logic when DNS, proxy, firewall, NetFlow, or cloud flow telemetry can reliably identify NGINX host egress, workload egress, node egress, first-seen destinations, and approved dependency baselines.
· Promote file and persistence logic when file telemetry can reliably monitor web-accessible directories, temporary directories, configuration paths, mounted volumes, startup locations, service locations, log directories, and container writable layers.
· Promote container and Kubernetes logic when restart telemetry, workload identity, service-account context, namespace context, mounted-secret access, volume context, process execution, ingress metadata, and workload ownership are available.
· Promote vulnerability-context logic when asset inventory, exposure status, patch state, rewrite exposure, route ownership, service-owner mapping, service criticality, and compensating-control status are validated.
· Promote route-aware web telemetry logic when raw URI values, normalized URI values, host headers, forwarded headers, request identifiers, upstream timing, route mapping, and virtual-host context are preserved.
· Keep PoC-derived request patterns in hunt mode unless they are paired with resilient behavior logic, asset context, false-positive controls, and validated local telemetry.
· Keep broad malformed-request logic in hunt mode unless it is constrained by exposed asset context, rewrite exposure, source clustering, route-level effects, or corroborating instability.
· Keep broad crash or restart logic in hunt mode unless it is tied to suspicious request activity, vulnerable asset context, or follow-on host, network, file, container, or application behavior.
S25 — Ultra-Tuned Detection Engineering Rules
NDR / Network Behavioral Analytics
Detection Viability Assessment
NDR / Network Behavioral Analytics has three rules for this EXP report.
· NDR / Network Behavioral Analytics is viable for detecting suspicious network behavior associated with externally reachable NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent infrastructure exposed to the NGINX Rift exploit path.
· NDR / Network Behavioral Analytics is strongest where network-flow telemetry, DNS telemetry, proxy telemetry, firewall telemetry, HTTP metadata, WAF telemetry, load balancer telemetry, ingress telemetry, asset inventory, exposed-service tagging, route mapping, destination enrichment, scanner allowlists, approved-egress baselines, and SIEM correlation can be combined.
· NDR / Network Behavioral Analytics can identify suspicious sequencing between malformed inbound HTTP activity, route-specific degradation, NGINX-backed service instability, unusual outbound communication, and internal expansion toward upstream applications, identity services, databases, Kubernetes services, cloud metadata services, management interfaces, or other sensitive backend infrastructure.
· NDR / Network Behavioral Analytics is not a standalone source for confirming successful NGINX Rift exploitation because rewrite-module execution, worker memory corruption, local process creation, crash artifacts, and host-level post-exploitation activity may not be directly visible in network telemetry.
· NDR / Network Behavioral Analytics rules should be correlated with NGINX access logs, NGINX error logs, WAF logs, load balancer logs, ingress telemetry, endpoint process telemetry, EDR telemetry, host crash telemetry, file telemetry, DNS telemetry, proxy logs, firewall logs, cloud flow logs, Kubernetes telemetry, vulnerability-management context, and configuration-management context before classifying activity as confirmed compromise.
· NDR / Network Behavioral Analytics detection content should be treated as high-value behavioral coverage for exploit-attempt identification, suspicious request sequencing, abnormal egress from reverse proxy infrastructure, and downstream exposure assessment, not direct exploit confirmation by itself.
Rule
Suspicious Malformed HTTP Activity Against Exposed NGINX or Reverse Proxy Infrastructure
Rule Format
NDR behavioral analytics rule suitable for network-flow, firewall, proxy, DNS, WAF, load balancer, ingress, gateway, CDN, HTTP metadata, asset-inventory, exposed-service classification, NGINX-backed service tagging, route mapping, scanner allowlisting, response-code correlation, destination-service enrichment, and SIEM correlation after asset tagging, exposed-route validation, request-field validation, source-enrichment validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious malformed inbound HTTP or HTTPS activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure.
· Identify possible exploit probing, validation attempts, malformed request delivery, route-specific request manipulation, or exploit-path adaptation against exposed NGINX-backed services.
· Prioritize activity involving abnormal URI shape, encoded path expansion, repeated delimiters, request normalization failures, unusual route variation, uncommon methods, malformed headers, or repeated targeting of rewrite-heavy routes.
· Support early identification of attempted exploitation without relying on a single exploit string, static exploit fragment, vulnerable-version exposure alone, or direct inspection of worker memory state.
· This rule does not prove successful exploitation, code execution, service compromise, credential compromise, or data exposure without supporting NGINX error-log, endpoint, crash, outbound, file, identity, application, or validated downstream evidence.
Detection Logic
· Identify inbound HTTP or HTTPS activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, or NGINX-backed application infrastructure.
· Prioritize requests to rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, legacy application paths, customer-facing virtual hosts, administrative portals, or high-dependency upstream application routes.
· Prioritize abnormal request characteristics involving excessive URI length, repeated encoding, double encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, capture-like route structures, uncommon methods, malformed headers, unusual content length, suspicious query structure, or request normalization failure.
· Increase confidence when suspicious request activity is source-clustered by IP, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent pattern, route pattern, request shape, or repeated activity across multiple NGINX-backed services.
· Increase confidence when suspicious request activity is followed by elevated 500-series responses, upstream reset behavior, gateway errors, backend failure, health-check failure, route-specific degradation, or abnormal response timing.
· Increase confidence when similar request patterns are observed across multiple exposed NGINX services, virtual hosts, ingress paths, gateway routes, reverse proxy tiers, or customer-facing applications within a short time window.
· Increase confidence when affected assets are unpatched, internet-facing, rewrite-heavy, business-critical, WAF-adjacent, ingress-facing, gateway-facing, or fronting authentication, API, payment, administrative, identity, or customer-facing services.
· Reduce severity for approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, sanctioned security testing, and known benign scanner activity when behavior is consistent with source, asset, route, and time window.
· Do not classify malformed HTTP activity as confirmed exploitation without corroborating service instability, NGINX error-log artifacts, endpoint process activity, suspicious outbound communication, file activity, credential access, downstream application anomalies, or validated crash evidence.
· Do not treat vulnerable-version exposure, NGINX presence, internet exposure, malformed traffic, or exploit-path request similarity as compromise evidence by itself.
Required Telemetry
· Network-flow telemetry.
· Firewall logs.
· Proxy logs where available.
· DNS logs where available.
· NDR HTTP metadata where available.
· WAF telemetry where available.
· CDN telemetry where available.
· Load balancer telemetry where available.
· Gateway telemetry where available.
· Ingress telemetry where available.
· Source IP.
· Source ASN.
· Source geolocation.
· Source hosting-provider context.
· Source reputation.
· Source user agent where available.
· Destination IP.
· Destination hostname.
· Destination virtual host.
· Destination service identity.
· Destination asset identity.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Request method where available.
· Raw URI where available.
· Normalized URI where available.
· Query string where available.
· HTTP host where available.
· TLS SNI where available.
· Response code where available.
· Upstream response code where available.
· Request duration where available.
· Upstream response time where available.
· Request size or URI length where available.
· Connection count.
· Route or application mapping where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Rewrite-heavy route inventory where available.
· Patch status where available.
· Vulnerability-management context where available.
· Approved scanner inventory.
· Approved testing source inventory.
· CDN, load balancer, health-check, uptime-monitoring, and synthetic-monitoring allowlists.
· NGINX error-log correlation where available.
· EDR or host telemetry correlation where available.
· SIEM enrichment where available.
· Change-management, patch-validation, and incident-response context.
Engineering Implementation Instructions
· Build asset groups for internet-facing NGINX servers, NGINX Plus servers, reverse proxy tiers, ingress controllers, gateway services, WAF-adjacent services, NGINX-backed applications, and high-value NGINX-backed exposed web infrastructure.
· Build route groups for rewrite-heavy paths, authentication paths, API paths, customer-facing virtual hosts, administrative portals, ingress paths, gateway routes, legacy routes, and high-dependency upstream application paths.
· Validate whether raw URI, normalized URI, query string, host header, forwarded headers, response code, upstream response code, request timing, request size, source IP, source ASN, and user-agent fields are available in the NDR, WAF, load balancer, proxy, gateway, or SIEM telemetry.
· Use request-shape analytics rather than a single exploit string, public demonstration artifact, or static exploit fragment.
· Add source clustering by IP, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent family, request shape, route target, and time window.
· Add route-level response correlation for 500-series spikes, upstream resets, gateway errors, backend failures, abnormal response timing, and health-check degradation as confidence-increasing conditions rather than the only detection path.
· Add affected-asset enrichment for NGINX version, NGINX Plus status, patch state, rewrite exposure, exposed service role, business criticality, WAF-adjacent status, ingress status, gateway status, and hosted application sensitivity.
· Use shorter correlation windows for suspicious malformed requests followed by immediate 500-series spikes, upstream resets, gateway failures, or service degradation.
· Use moderate correlation windows for repeated route probing, distributed source clustering, repeated request-shape reuse, or activity across multiple NGINX-backed services.
· Use longer correlation windows for delayed exploitation validation, repeated infrastructure reuse, and retroactive hunting after exploit-pattern amendments.
· Tune severity based on exposed-service criticality, rewrite exposure, request abnormality, source reputation, source clustering, route sensitivity, response impact, scanner status, patch state, and correlated instability.
· Avoid broad suppression for cloud providers, hosting providers, VPN providers, scanners, CDNs, or security platforms without validation because legitimate testing infrastructure and attacker infrastructure may overlap.
· Use change-management records, approved testing records, emergency patch validation, incident-response records, scanner schedules, synthetic-monitoring records, and load balancer health-check context as triage evidence before classifying activity as suspicious or probable exploitation.
· Validate all environment variables, asset groups, route groups, source-enrichment fields, request-shape fields, response fields, scanner allowlists, timing windows, and local parser behavior before production deployment.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to suspicious malformed request activity against exposed NGINX-backed infrastructure rather than static exploit strings, vulnerable-version exposure, or NGINX presence alone.
· The rule remains useful if the initial exploit pattern changes but the activity still involves abnormal route targeting, encoded request variation, request-shape anomalies, source clustering, or route-specific service impact.
· The score is supported by the durability of exposed asset identity, route context, malformed request behavior, source clustering, response-code correlation, upstream reset behavior, and affected-service enrichment.
· The score is constrained by TLS inspection gaps, request normalization by CDN or WAF layers, incomplete URI visibility, scanner noise, incomplete rewrite-route inventory, and the inability of NDR alone to observe local worker memory corruption or process execution.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on NDR placement, HTTP metadata fidelity, source IP preservation, WAF or load balancer integration, route mapping, exposed asset tagging, response-code visibility, scanner allowlists, and affected-service enrichment.
· Operational confidence is reduced where TLS encryption, CDN normalization, WAF transformation, proxy chaining, load balancer aggregation, or incomplete logging obscures original request structure.
· Operational confidence is reduced where internet-facing services receive high volumes of scanner traffic, fuzzing, bot traffic, malformed crawler traffic, synthetic monitoring, or authorized validation.
· Full-telemetry confidence improves when request anomalies are enriched with NGINX access logs, NGINX error logs, WAF telemetry, load balancer telemetry, ingress logs, EDR telemetry, service-health data, patch context, rewrite-route context, and change-management records.
· Even under full telemetry conditions, this rule should support exploit-attempt escalation and investigation rather than standalone confirmation of successful NGINX Rift exploitation.
Limitations
· This rule detects suspicious malformed request activity against exposed NGINX-backed infrastructure, not successful exploitation by itself.
· Encrypted traffic may limit URI, header, query-string, and request-shape visibility.
· CDN, WAF, load balancer, ingress, gateway, or reverse proxy layers may normalize, truncate, rewrite, aggregate, or discard malformed request attributes before they reach NDR telemetry.
· Legitimate scanning, emergency validation, penetration testing, synthetic monitoring, uptime monitoring, load balancer probes, and CDN health checks may produce malformed request or error-rate artifacts.
· NGINX error responses and route-specific failures may result from benign application bugs, deployment activity, dependency failures, resource pressure, configuration errors, or maintenance.
· Missing rewrite-route inventory may prevent accurate prioritization of vulnerable or high-risk paths.
· Exploit-path request patterns may change quickly and should not define the full rule.
· Confirmation requires correlation with NGINX error-log artifacts, crash telemetry, endpoint process lineage, suspicious outbound communication, file activity, credential access, downstream application anomalies, or validated service-impact evidence.
Detection Query Pattern
NDR malformed-request query pattern requiring platform syntax validation, exposed NGINX asset tagging, rewrite-route context validation, request-field validation, response-field validation, source-enrichment validation, scanner allowlist validation, timing-window tuning, and environment-specific allowlisting before production deployment.
NetworkEvent AS InboundRequest
WHERE InboundRequest.Direction = "Inbound"
AND InboundRequest.DestinationAsset IN ASSET_GROUP(
"Internet Facing NGINX Servers",
"Internet Facing NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"NGINX Backed Customer Facing Applications",
"High Value NGINX Backed Exposed Web Infrastructure"
)
AND (
InboundRequest.RequestPath IN ROUTE_GROUP(
"Rewrite Heavy Routes",
"Authentication Paths",
"API Paths",
"Ingress Paths",
"Gateway Routes",
"Legacy Application Paths",
"Administrative Portals",
"Customer Facing Virtual Hosts"
)
OR InboundRequest.DestinationAsset.Exposure = "internet_facing"
)
AND (
InboundRequest.UriLength >= ENV_NGINX_URI_LENGTH_ANOMALY_THRESHOLD
OR InboundRequest.EncodedCharacterCount >= ENV_NGINX_ENCODING_DENSITY_THRESHOLD
OR InboundRequest.DelimiterDensity >= ENV_NGINX_DELIMITER_DENSITY_THRESHOLD
OR InboundRequest.PathExpansionScore >= ENV_NGINX_PATH_EXPANSION_THRESHOLD
OR InboundRequest.RequestNormalizationResult IN ANY (
"failed",
"ambiguous",
"rewritten",
"truncated",
"malformed"
)
OR InboundRequest.Method NOT IN ENV_APPROVED_METHODS_FOR_ROUTE
OR InboundRequest.HeaderAnomalyScore >= ENV_HEADER_ANOMALY_THRESHOLD
)
AND (
InboundRequest.SourceReputation IN ANY (
"high_risk",
"suspicious",
"scanner",
"unknown",
"newly_observed"
)
OR InboundRequest.SourceASN IN WATCHLIST(
"Scanner Infrastructure",
"Bulletproof Hosting",
"Unusual Cloud Hosting",
"Known Exploit Infrastructure"
)
OR COUNT_SIMILAR_EVENTS(
InboundRequest.SourceIP,
InboundRequest.RequestShape,
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_REQUEST_CLUSTER_THRESHOLD
OR COUNT_DISTINCT_DESTINATIONS(
InboundRequest.SourceIP,
"NGINX Backed Assets",
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_MULTI_ASSET_PROBE_THRESHOLD
)
AND OPTIONAL_CONFIDENCE_INCREASE WITHIN ENV_NGINX_REQUEST_IMPACT_WINDOW (
WebEvent.ResponseCode >= 500
OR WebEvent.UpstreamReset = true
OR WebEvent.GatewayError = true
OR WebEvent.RouteErrorRate >= ENV_ROUTE_ERROR_RATE_THRESHOLD
OR HealthEvent.ServiceDegradation = true
OR HealthEvent.BackendFailure = true
)
AND InboundRequest.SourceIP NOT IN ASSET_GROUP(
"Approved Vulnerability Scanners",
"Approved Security Testing Sources",
"Approved Emergency Validation Sources",
"Approved Synthetic Monitoring Sources",
"Approved Uptime Monitoring Sources",
"Approved CDN Health Check Sources",
"Approved Load Balancer Probe Sources"
)
AND NOT ChangeContext IN ANY (
"approved_patch_validation",
"approved_penetration_test",
"approved_incident_response_activity",
"approved_qa_testing",
"approved_synthetic_monitoring",
"approved_load_balancer_health_check"
)
Rule
Unusual Outbound Communication From NGINX or Reverse Proxy Infrastructure After Exploit-Path Indicators
Rule Format
NDR behavioral egress-correlation rule suitable for network-flow, firewall, proxy, DNS, EDR-network, endpoint-enriched NDR, workload-aware NDR, container-aware NDR, asset-inventory, exposed-service classification, approved-egress baseline, destination-enrichment, ingress or gateway context, and SIEM correlation after NGINX asset tagging, workload tagging, dependency-baseline validation, destination-enrichment validation, exploit-path correlation validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect unusual outbound communication from NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, container, node, or workload infrastructure after suspicious exploit-path indicators.
· Identify possible callback, command-and-control, payload retrieval, staging, tool download, direct egress, tunneling, or data-transfer behavior from infrastructure that normally operates as an inbound-facing web or reverse proxy tier.
· Prioritize outbound communication involving rare, newly observed, low-reputation, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unusual cloud, direct IP, unusual port, or previously unseen destinations.
· Support investigation of possible successful exploitation without assuming that all outbound communication from NGINX infrastructure is malicious.
· This rule does not prove successful exploitation, code execution, host compromise, credential compromise, or data exfiltration without supporting endpoint, file, crash, identity, application, or validated data-flow evidence.
Detection Logic
· Identify outbound communication from NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, container, node, or workload infrastructure.
· Prioritize outbound communication that occurs shortly after suspicious malformed inbound request activity, route-specific error spikes, upstream reset behavior, gateway failures, worker instability, crash indicators, health-check failures, or NGINX-backed service degradation.
· Prioritize destinations that are rare for the asset, newly observed, low-reputation, unknown external, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unapproved cloud, direct IP, unusual port, or inconsistent with approved service-dependency baselines.
· Increase confidence when outbound communication originates from assets that normally function as inbound-facing reverse proxies, ingress controllers, gateway services, WAF-adjacent services, or web-serving infrastructure.
· Increase confidence when outbound communication is linked through process-aware enrichment to NGINX, a shell, scripting interpreter, downloader, package manager, file-transfer utility, network utility, or suspicious child process from NGINX service context.
· Increase confidence when outbound communication follows NGINX worker instability, segmentation fault indicators, reload failure, container restart, pod restart, route degradation, or repeated gateway errors.
· Increase confidence when outbound activity includes direct IP communication, unusual TLS SNI, abnormal user agent, unexpected protocol, high byte count, repeated beacon-like timing, abnormal session duration, or transfer behavior inconsistent with normal reverse proxy operation.
· Increase confidence when the same destination, domain, ASN, tunnel provider, hosting provider, or infrastructure cluster is contacted by multiple NGINX-backed assets after similar suspicious inbound request activity.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, documented internal APIs, and sanctioned administrative workflows when behavior is consistent with the asset, service, dependency, and time window.
· Do not classify outbound communication as confirmed NGINX Rift exploitation without corroborating inbound exploit-path activity, endpoint process lineage, crash telemetry, file activity, identity telemetry, downstream application anomalies, or validated data-flow evidence.
· Do not treat destination novelty, direct IP communication, unusual port usage, or NGINX asset identity as compromise evidence by itself.
Required Telemetry
· Network-flow telemetry.
· Firewall logs.
· DNS logs.
· Proxy logs where available.
· EDR network telemetry where available.
· NDR session metadata.
· Source IP.
· Source asset identity.
· Source hostname.
· Source workload identity where available.
· Source container identity where available.
· Source node identity where available.
· Source service identity where available.
· Destination IP.
· Destination domain.
· Destination hostname.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Session duration.
· Byte count.
· Connection count.
· TLS SNI where available.
· HTTP host where available.
· User agent where available.
· Destination reputation.
· Destination category.
· Destination ASN.
· Destination geolocation.
· Destination first-seen timestamp.
· Domain age where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Container and Kubernetes workload inventory where available.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, and management destinations.
· Prior suspicious inbound request context.
· NGINX service instability context where available.
· NGINX error-log correlation where available.
· Endpoint process correlation where available.
· File telemetry correlation where available.
· Identity-provider correlation where available.
· Application telemetry correlation where available.
· Change-management, testing, incident-response, and maintenance-window context.
Engineering Implementation Instructions
· Build asset groups for NGINX servers, NGINX Plus servers, reverse proxy tiers, ingress controllers, gateway services, WAF-adjacent services, NGINX-backed application hosts, containerized NGINX workloads, Kubernetes nodes hosting ingress workloads, and high-value NGINX-backed exposed web infrastructure.
· Build approved egress baselines for each NGINX-backed service, including upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, and management endpoints.
· Validate how the environment identifies NGINX asset role through asset inventory, network placement, workload labels, Kubernetes metadata, cloud tags, endpoint enrichment, SIEM enrichment, or service ownership mapping.
· Add enrichment for destination reputation, destination category, destination first-seen timestamp, domain age, ASN, hosting provider, VPN provider, cloud provider, tunnel provider, sanctioned-service status, source asset role, workload identity, service criticality, and business function.
· Correlate suspicious outbound communication with inbound events involving malformed request activity, abnormal request shape, route-specific error spikes, upstream reset behavior, gateway failure, suspicious source clustering, worker instability, service degradation, or crash indicators.
· Use shorter correlation windows for suspicious inbound request activity followed by immediate outbound communication, DNS lookup, direct IP connection, command-line retrieval, or rare destination contact.
· Use moderate correlation windows for route instability, worker crash indicators, service degradation, or container restart followed by outbound communication.
· Use longer correlation windows for delayed callback, repeated destination contact, repeated infrastructure reuse, or recurring activity across multiple NGINX-backed assets.
· Tune severity based on destination novelty, destination reputation, destination category, protocol, port, byte count, session duration, beacon timing, source asset criticality, ingress or gateway exposure, process attribution, and prior exploit-path indicators.
· Avoid broad suppression for cloud providers, CDNs, developer platforms, package repositories, update infrastructure, tunneling services, or hosting providers without validation because attacker infrastructure and legitimate service dependencies may overlap.
· Use change-management records, approved maintenance records, package-update records, monitoring records, security-tool activity, and incident-response records as triage evidence before classifying activity as suspicious or probable compromise.
· Validate all environment variables, asset groups, approved-destination lists, enrichment fields, process joins, workload joins, dependency baselines, timing windows, and local parser behavior before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to unusual outbound communication from NGINX-backed infrastructure after exploit-path indicators rather than static exploit strings, vulnerable-version exposure, or generic egress alone.
· The rule remains useful if the initial exploit delivery changes but the activity still produces callback, staging, tool retrieval, direct egress, command-and-control, tunneling, or data-transfer behavior from reverse proxy infrastructure.
· The score is supported by the durability of source asset role, destination novelty, destination reputation, egress baseline deviation, timing, prior exploit-path context, and correlation with endpoint, file, crash, identity, or application signals.
· The score is constrained by normal NGINX communication with upstream applications, observability platforms, update repositories, logging systems, security tooling, internal APIs, service mesh endpoints, and cloud infrastructure.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on NDR egress visibility, DNS visibility, proxy visibility, asset tagging, workload identity, approved-destination baselines, destination-enrichment quality, and availability of prior exploit-path context.
· Operational confidence is reduced where outbound traffic is NATed, service-mesh-obscured, proxy-chained, aggregated, or not attributable to specific NGINX hosts, workloads, containers, nodes, or service identities.
· Operational confidence is reduced where NGINX infrastructure routinely communicates with broad upstream services, SaaS services, cloud platforms, update repositories, monitoring systems, and internal APIs without stable baselines.
· Full-telemetry confidence improves when unusual egress is enriched with NGINX access logs, NGINX error logs, EDR process lineage, command-line capture, file telemetry, crash telemetry, identity-provider records, application telemetry, Kubernetes telemetry, cloud flow logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for possible compromise or post-exploitation activity, but confirmed compromise still requires corroborating host, identity, file, application, or validated data-flow evidence.
Limitations
· This rule detects suspicious outbound communication after exploit-path indicators, not successful exploitation by itself.
· Legitimate NGINX infrastructure may communicate with upstream applications, backend services, observability platforms, security tools, update repositories, package repositories, internal APIs, and management endpoints.
· NAT, service mesh, proxy chaining, cloud networking, load balancers, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress.
· Destination reputation may be incomplete or misleading for newly created, compromised, shared, or legitimate cloud-hosted infrastructure.
· Encrypted traffic may limit content visibility and prevent confirmation of command-and-control, retrieval, staging, or exfiltration content.
· The rule may miss attacks that remain local, use approved destinations, delay callbacks, use common cloud providers, or communicate only through permitted service dependencies.
· Confirmation requires correlation with inbound exploit-path indicators, endpoint process lineage, crash telemetry, file activity, credential access, downstream application anomalies, identity telemetry, or validated data movement.
Detection Query Pattern
NDR egress-correlation query pattern requiring platform syntax validation, NGINX asset tagging, workload identity validation, approved-egress validation, destination-enrichment validation, exploit-path context validation, endpoint-to-network correlation validation, timing-window tuning, and environment-specific allowlisting before production deployment.
NetworkEvent AS EgressEvent
WHERE EgressEvent.SourceAsset IN ASSET_GROUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"NGINX Backed Application Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Web Infrastructure"
)
AND EgressEvent.Direction = "Outbound"
AND (
EgressEvent.DestinationFirstSeen WITHIN ENV_NEW_DESTINATION_WINDOW
OR EgressEvent.DestinationDomainAge <= ENV_NEW_DOMAIN_AGE_WINDOW
OR EgressEvent.DestinationReputation IN ANY (
"high_risk",
"suspicious",
"rare",
"newly_observed",
"unknown"
)
OR EgressEvent.DestinationCategory IN ANY (
"temporary_hosting",
"paste_service",
"file_sharing",
"tunneling",
"dynamic_dns",
"unapproved_cloud_storage",
"unknown_external",
"infrastructure_like"
)
OR EgressEvent.DestinationPort NOT IN ENV_APPROVED_NGINX_EGRESS_PORTS
OR EgressEvent.ByteCount >= ENV_NGINX_EGRESS_VOLUME_THRESHOLD
OR EgressEvent.SessionPattern IN ANY (
"beacon_like",
"unusual_duration",
"repeated_rare_destination",
"direct_ip_connection",
"unusual_tls_sni"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_EXPLOIT_EGRESS_WINDOW (
InboundRequest.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Source Clustered NGINX Probe",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route"
)
OR WebEvent.EventType IN ANY (
"Route Specific 500 Spike",
"Upstream Reset Spike",
"Gateway Failure Spike",
"Backend Failure Spike",
"NGINX Backed Service Degradation"
)
OR HealthEvent.EventType IN ANY (
"NGINX Worker Instability",
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND EgressEvent.DestinationIP NOT IN ASSET_GROUP(
"Approved Upstream Application Destinations",
"Approved Observability Destinations",
"Approved Log Forwarding Destinations",
"Approved Package Repository Destinations",
"Approved Update Repository Destinations",
"Approved Corporate Proxy Destinations",
"Approved Security Tool Destinations",
"Approved Monitoring Destinations",
"Approved Service Mesh Destinations",
"Approved Management Destinations"
)
AND NOT ChangeContext IN ANY (
"approved_patch_activity",
"approved_service_maintenance",
"approved_nginx_reload",
"approved_package_update",
"approved_monitoring_activity",
"approved_security_testing",
"approved_incident_response_activity",
"approved_deployment_activity"
)
Rule
Internal Expansion Toward Backend, Identity, Kubernetes, Cloud Metadata, or Management Services From NGINX Infrastructure After Exploit-Path Indicators
Rule Format
NDR behavioral expansion-correlation rule suitable for network-flow, firewall, proxy, DNS, endpoint-enriched NDR, workload-aware NDR, east-west visibility, container-aware NDR, Kubernetes-aware NDR, asset-inventory, backend dependency mapping, sensitive-destination mapping, identity enrichment, segmentation context, cloud metadata context, and SIEM correlation after NGINX asset tagging, backend dependency validation, sensitive destination tagging, workload identity validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect unusual internal communication from NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, container, node, or workload infrastructure after suspicious exploit-path indicators.
· Identify possible internal expansion, backend probing, service discovery, cloud metadata access, Kubernetes API access, identity-system access, secret-store access, database probing, management-interface access, or movement toward upstream application infrastructure.
· Prioritize activity involving new, unusual, elevated, or high-risk communication with sensitive backend systems outside documented NGINX service dependencies.
· Support investigation of possible post-exploitation expansion without assuming that every backend connection from NGINX infrastructure is malicious.
· This rule does not prove successful exploitation, lateral movement, credential compromise, cloud compromise, Kubernetes compromise, or data exfiltration without supporting endpoint, identity, cloud, Kubernetes, application, file, or validated data-flow evidence.
Detection Logic
· Identify internal network communication from NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, container, node, or workload infrastructure.
· Prioritize activity that occurs shortly after suspicious malformed inbound request activity, route-specific instability, upstream reset behavior, gateway failure, worker instability, crash indicators, unusual outbound communication, or other exploit-path context.
· Identify new, unusual, elevated, or high-risk communication from NGINX infrastructure to backend applications, internal APIs, databases, identity services, cloud metadata services, Kubernetes APIs, secret stores, CI/CD systems, artifact repositories, management interfaces, administrative services, or private address ranges outside expected dependencies.
· Increase confidence when the destination system is not normally accessed by the NGINX host, workload, route, application, service owner, or network segment.
· Increase confidence when network activity suggests port scanning, connection sweeps, service discovery, abnormal protocol use, metadata probing, internal API probing, database probing, Kubernetes API access, secret access, or management-interface exploration.
· Increase confidence when internal expansion follows suspicious inbound request activity, worker instability, route-specific error spikes, unusual outbound communication, file activity, credential-access behavior, or endpoint alerts.
· Increase confidence when similar internal expansion behavior appears across multiple NGINX-backed assets after similar malformed request activity or source-clustered probing.
· Increase confidence when the affected NGINX asset fronts authentication systems, API gateways, payment flows, customer applications, administrative portals, regulated data paths, or high-value upstream services.
· Reduce severity when internal communication matches documented upstream routing, service mesh behavior, health checks, backend dependencies, deployment automation, monitoring workflows, administrative maintenance, or approved incident-response activity.
· Do not classify backend access as confirmed compromise without corroborating endpoint process lineage, identity telemetry, Kubernetes telemetry, cloud telemetry, application telemetry, file telemetry, or validated data-flow evidence.
· Do not treat internal communication from NGINX infrastructure as malicious by itself because reverse proxy and ingress tiers routinely communicate with backend services.
Required Telemetry
· East-west network-flow telemetry.
· Firewall logs.
· DNS logs.
· Proxy logs where available.
· EDR network telemetry where available.
· NDR session metadata.
· Source IP.
· Source asset identity.
· Source hostname.
· Source workload identity where available.
· Source container identity where available.
· Source node identity where available.
· Source namespace where available.
· Source service identity where available.
· Destination IP.
· Destination hostname.
· Destination asset identity.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Session duration.
· Byte count.
· Connection count.
· Destination service category.
· Destination sensitivity.
· Network segment.
· Segmentation zone.
· Known upstream dependency mapping.
· Backend application mapping.
· Internal API mapping.
· Database destination mapping.
· Identity-service destination mapping.
· Kubernetes API destination mapping.
· Cloud metadata endpoint mapping.
· Secrets-management destination mapping.
· CI/CD destination mapping.
· Artifact repository destination mapping.
· Management-interface destination mapping.
· Administrative-service destination mapping.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Container and Kubernetes workload inventory where available.
· Prior exploit-path indicators from inbound request, route instability, crash, or egress detections.
· Identity-provider telemetry where available.
· Kubernetes audit telemetry where available.
· Cloud-control-plane telemetry where available.
· Application telemetry where available.
· Change-management, deployment, testing, and incident-response context.
Engineering Implementation Instructions
· Build asset groups for NGINX servers, NGINX Plus servers, reverse proxy tiers, ingress controllers, gateway services, WAF-adjacent services, containerized NGINX workloads, Kubernetes nodes hosting ingress workloads, and high-value NGINX-backed exposed web infrastructure.
· Build sensitive destination groups for backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secret stores, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Establish dependency baselines for each NGINX route, virtual host, ingress path, gateway service, upstream application, workload, namespace, node, and service owner.
· Correlate sensitive internal access with inbound events involving malformed request activity, suspicious source clustering, request normalization failure, route-specific error spikes, upstream reset behavior, gateway failure, worker instability, service degradation, unusual outbound communication, and endpoint alert context.
· Add enrichment for destination sensitivity, application criticality, identity-system exposure, database sensitivity, Kubernetes namespace sensitivity, cloud account sensitivity, secret-store access, service owner, business function, and segmentation zone.
· Use shorter correlation windows for suspicious inbound request activity followed by immediate internal probing, metadata access, Kubernetes API access, database probing, or management-interface access.
· Use moderate correlation windows for service instability followed by new backend access, unusual protocol use, connection sweeps, or repeated access to sensitive internal systems.
· Use longer correlation windows for delayed expansion, token reuse, repeated backend contact, or repeated internal activity across multiple NGINX-backed assets.
· Tune severity based on destination sensitivity, access novelty, protocol, port, connection volume, byte count, source asset role, service criticality, segmentation violation, exploit-path context, and correlated downstream identity or application activity.
· Avoid broad suppression for backend services, internal APIs, databases, identity systems, cloud endpoints, Kubernetes services, or management interfaces because legitimate dependency and attacker expansion paths may overlap.
· Use deployment records, backend dependency maps, service ownership records, change-management records, approved testing records, approved incident-response records, and service mesh context as triage evidence before classifying activity as suspicious or probable compromise.
· Validate all environment variables, asset groups, sensitive-destination mappings, dependency baselines, identity joins, Kubernetes joins, cloud joins, route mappings, segmentation context, and timing windows before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to internal expansion from NGINX-backed infrastructure after exploit-path indicators rather than static exploit indicators or generic internal traffic.
· The rule remains useful if the initial exploit vector changes but the activity still produces abnormal backend probing, service discovery, metadata access, Kubernetes access, secret-store access, management-interface access, or movement toward sensitive internal services.
· The score is supported by the durability of source asset role, sensitive destination identity, dependency deviation, segmentation context, access novelty, timing, and correlation with inbound request, instability, egress, endpoint, identity, Kubernetes, cloud, or application signals.
· The score is constrained by normal reverse proxy communication with upstream applications, incomplete dependency maps, service mesh abstraction, NAT, Kubernetes networking, cloud networking, and the need for accurate sensitive-destination mapping.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on east-west visibility, dependency mapping, segmentation context, workload identity, sensitive-destination mapping, route ownership, source asset tagging, and prior exploit-path context.
· Operational confidence is reduced where reverse proxy, ingress, gateway, service mesh, Kubernetes, and cloud networking obscure source identity or make backend communication appear uniform.
· Operational confidence is reduced where NGINX infrastructure routinely accesses broad backend services, internal APIs, identity systems, cloud endpoints, or management interfaces without stable baselines.
· Full-telemetry confidence improves when internal expansion events are enriched with NGINX access logs, NGINX error logs, EDR process lineage, command-line capture, file telemetry, identity-provider events, Kubernetes audit logs, cloud-control-plane logs, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for possible post-exploitation movement, but confirmed compromise still requires corroborating endpoint, identity, Kubernetes, cloud, application, file, or data-flow evidence.
Limitations
· This rule detects suspicious internal expansion from NGINX infrastructure after exploit-path indicators, not successful exploitation by itself.
· NGINX, reverse proxy, ingress, and gateway infrastructure commonly communicates with backend applications, internal APIs, databases, service mesh endpoints, monitoring systems, identity services, and administrative infrastructure.
· The rule requires accurate NGINX asset tagging, backend dependency mapping, sensitive-destination mapping, and segmentation context to remain reliable.
· Missing workload identity, service mesh visibility, Kubernetes metadata, or cloud metadata may prevent attribution of internal activity to the affected NGINX workload.
· Existing service dependencies, health checks, deployment workflows, and approved automation may make suspicious access appear routine without strong baselines.
· Low-volume probing, delayed expansion, token reuse, approved protocol use, or access through permitted backend paths may reduce detection visibility.
· The rule may miss attacks that remain local, avoid sensitive destinations, use already common backend services, or operate entirely through documented upstream dependencies.
· Confirmation requires correlation with endpoint process lineage, identity anomalies, Kubernetes activity, cloud activity, application anomalies, file activity, credential access, or validated data movement.
Detection Query Pattern
NDR internal-expansion query pattern requiring platform syntax validation, NGINX asset tagging, sensitive-destination mapping, backend dependency validation, workload identity validation, exploit-path context validation, access-baseline validation, timing-window tuning, and environment-specific allowlisting before production deployment.
NetworkEvent AS ExpansionEvent
WHERE ExpansionEvent.SourceAsset IN ASSET_GROUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Web Infrastructure"
)
AND ExpansionEvent.Direction IN ANY (
"Internal",
"East West",
"Outbound To Private Network"
)
AND ExpansionEvent.DestinationAsset IN ASSET_GROUP(
"Backend Applications",
"Internal APIs",
"Databases",
"Identity Services",
"Kubernetes API Servers",
"Cloud Metadata Endpoints",
"Secrets Managers",
"CI CD Systems",
"Artifact Repositories",
"Management Interfaces",
"Administrative Services",
"Regulated Data Paths",
"Sensitive Internal Services"
)
AND (
ExpansionEvent.AccessPattern IN ANY (
"new_for_source_asset",
"new_for_workload",
"new_for_route",
"rare_for_source_asset",
"rare_for_service_owner",
"unusual_time_window",
"unusual_connection_volume",
"unusual_destination_sequence",
"segmentation_policy_deviation"
)
OR ExpansionEvent.ConnectionCount >= ENV_NGINX_INTERNAL_EXPANSION_VOLUME_THRESHOLD
OR ExpansionEvent.ByteCount >= ENV_NGINX_INTERNAL_DATA_VOLUME_THRESHOLD
OR ExpansionEvent.DestinationSensitivity IN ANY (
"identity",
"secrets",
"database",
"kubernetes_control_plane",
"cloud_metadata",
"management",
"production",
"regulated_data",
"deployment"
)
OR ExpansionEvent.Protocol NOT IN ENV_APPROVED_NGINX_BACKEND_PROTOCOLS
)
AND EVENT_NEAR WITHIN ENV_NGINX_EXPANSION_CORRELATION_WINDOW (
InboundRequest.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Source Clustered NGINX Probe",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route"
)
OR WebEvent.EventType IN ANY (
"Route Specific 500 Spike",
"Upstream Reset Spike",
"Gateway Failure Spike",
"Backend Failure Spike",
"NGINX Backed Service Degradation"
)
OR HealthEvent.EventType IN ANY (
"NGINX Worker Instability",
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
OR EgressEvent.EventType IN ANY (
"Unusual Outbound Communication From NGINX Infrastructure",
"Rare Destination Contact From Reverse Proxy Tier",
"Direct IP Egress From NGINX Host",
"Suspicious DNS Lookup From NGINX Workload"
)
)
AND NOT ExpansionEvent.DestinationAsset IN DEPENDENCY_MAP(
ExpansionEvent.SourceAsset,
"Approved NGINX Upstream Dependencies"
)
AND NOT ChangeContext IN ANY (
"approved_deployment_activity",
"approved_service_mesh_activity",
"approved_backend_health_check",
"approved_security_testing",
"approved_incident_response_activity",
"approved_nginx_maintenance",
"approved_application_release",
"approved_administrative_workflow"
)
SentinelOne
Detection Viability Assessment
SentinelOne has three rules for this EXP report.
· SentinelOne is viable for detecting suspicious endpoint, workload, process, file, and process-network behavior after NGINX Rift exploit-path activity reaches host, container, ingress-controller, gateway, or service-account execution context.
· SentinelOne is strongest where process lineage, command-line telemetry, endpoint file-event telemetry where enabled, endpoint network telemetry or process-to-network enrichment where available, service telemetry, user context, container context, workload identity, Kubernetes metadata, asset tagging, NGINX service classification, approved-maintenance context, and SIEM correlation can be combined.
· SentinelOne can identify suspicious sequencing between NGINX worker instability, unexpected child-process execution, suspicious command execution, file or configuration changes, credential-material access, mounted-secret access, service modification, persistence behavior, and unusual outbound communication from NGINX-backed infrastructure.
· SentinelOne is not a standalone source for confirming the initial malformed HTTP exploit request because raw request shape, rewrite-route handling, WAF normalization, ingress routing, load balancer behavior, and reverse proxy path context may not be visible in endpoint telemetry.
· SentinelOne rules should be correlated with NGINX access logs, NGINX error logs, WAF logs, load balancer logs, ingress telemetry, NDR telemetry, DNS telemetry, proxy logs, firewall logs, cloud flow logs, Kubernetes telemetry, vulnerability-management context, configuration-management context, and change-management context before classifying activity as confirmed NGINX Rift compromise.
· SentinelOne detection content should be treated as high-value behavioral coverage for probable execution, post-exploitation activity, suspicious process lineage, file-system activity, credential-material access, and endpoint-to-network behavior, not direct proof of exploit delivery by itself.
Rule
Unexpected Child Process Execution From NGINX Worker, Ingress, Gateway, or Service-Account Lineage
Rule Format
SentinelOne behavioral process-lineage rule suitable for process telemetry where available, command-line telemetry where enabled, parent-child process relationships, ancestor process chains, service-account context, endpoint asset tagging, NGINX process identification, ingress-controller process identification, gateway service identification, container context where available, workload identity where available, endpoint network enrichment where available, endpoint file-event telemetry where enabled, NGINX error-log enrichment, and SIEM correlation after process-name validation, parent-process validation, service-account mapping, asset tagging, command-line normalization, container-context validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
Detect unexpected child-process execution from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or related service-account lineage.
· Identify possible post-exploitation execution involving shell, interpreter, downloader, package manager, archive utility, file-transfer utility, network utility, discovery command, credential utility, permission-modification utility, service-control utility, or persistence tooling spawned from NGINX-related context.
· Prioritize activity where NGINX service lineage executes commands inconsistent with normal web-serving, reverse proxy, ingress, gateway, or WAF-adjacent behavior.
· Support investigation of possible successful exploitation without relying on malformed request strings, static exploit fragments, vulnerable-version exposure alone, or endpoint visibility into rewrite-module memory handling.
· This rule does not prove NGINX Rift exploitation, code execution from the vulnerability, credential compromise, lateral movement, or data exfiltration without supporting request telemetry, crash telemetry, NGINX error-log artifacts, outbound communication, file activity, identity telemetry, or validated downstream evidence.
Detection Logic
Identify child-process creation where the parent or ancestor process is associated with NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent service context, containerized NGINX workload, or related service account.
· Require the event to involve an internet-facing NGINX-backed asset, an NGINX-related service-account context, or correlation with NGINX exploit-path indicators such as suspicious request activity, route degradation, worker instability, error-log artifacts, service restart, container restart, pod restart, or request-normalization failure.
· Prioritize shell, interpreter, downloader, network utility, file-transfer utility, package manager, archive utility, discovery utility, credential utility, permission-modification utility, service-management utility, or persistence-related execution.
· Increase confidence when the child process is spawned by nginx, an NGINX worker process, an NGINX master process, an ingress-controller process, a gateway service process, a reverse proxy service process, a containerized NGINX process, or a service account normally used only for web-serving, reverse proxy, ingress, or gateway activity.
· Increase confidence when command-line arguments include remote retrieval, encoded commands, inline script execution, temporary-directory execution, unusual output redirection, credential access, cloud metadata access, Kubernetes service-account access, archive extraction, permission modification, or execution from writable directories.
· Increase confidence when suspicious child-process execution follows NGINX worker instability, segmentation fault indicators, service restart, container restart, pod restart, route-specific degradation, NGINX error-log artifacts, suspicious inbound request activity, or request-normalization failure against an exposed NGINX-backed route.
· Increase confidence when suspicious child-process execution occurs on an internet-facing, unpatched, rewrite-heavy, ingress-facing, gateway-facing, WAF-adjacent, customer-facing, authentication-facing, API-facing, administrative, or business-critical NGINX-backed asset.
· Increase confidence when the same process pattern appears across multiple NGINX-backed assets, ingress nodes, gateway services, containers, or workloads within a short time window.
· Increase confidence when child-process execution is followed by outbound communication, suspicious DNS lookup, file writes, configuration modification, credential-material access, mounted-secret access, service modification, persistence behavior, or internal service probing.
· Reduce severity for approved administrative maintenance, package updates, deployment automation, container lifecycle activity, health checks, security testing, incident-response activity, certificate renewal, configuration management, and documented operational workflows when behavior is consistent with user, host, workload, and time window.
· Do not classify child-process execution as confirmed NGINX Rift compromise without corroborating exploit-path context, crash evidence, request telemetry, outbound communication, file activity, identity anomalies, Kubernetes activity, cloud activity, or downstream application impact.
· Do not treat NGINX presence, service restart, container restart, pod restart, or child-process creation as compromise evidence by itself.
Required Telemetry
SentinelOne process telemetry where available.
· Command-line telemetry where enabled.
· Parent process name.
· Parent process path.
· Ancestor process chain where available.
· Child process name.
· Child process path.
· Process start time.
· Process end time where available.
· Process user.
· Service-account context.
· Working directory.
· Executed binary hash where available.
· Executed binary signature status where available.
· Process integrity or privilege context where available.
· Endpoint hostname.
· Endpoint asset ID.
· Endpoint role.
· Endpoint exposure context.
· NGINX server asset tag.
· NGINX Plus server asset tag.
· Reverse proxy asset tag.
· Ingress-controller asset tag.
· Gateway service asset tag.
· WAF-adjacent service asset tag.
· Internet-facing NGINX-backed asset tag.
· Rewrite-heavy route context where available.
· Container workload context where available.
· Kubernetes namespace where available.
· Kubernetes pod where available.
· Kubernetes node where available.
· Container image identity where available.
· Endpoint file-event telemetry where enabled.
· Endpoint network connection telemetry or process-to-network enrichment where available.
· DNS telemetry where available.
· NGINX service restart context where available.
· NGINX worker crash context where available.
· NGINX error-log correlation where available.
· WAF, ingress, load balancer, gateway, or SIEM exploit-path context where available.
· Change-management, deployment, maintenance, certificate-renewal, testing, and incident-response context.
Engineering Implementation Instructions
Build asset groups for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy hosts, NGINX-backed ingress-controller hosts, NGINX-backed gateway hosts, WAF-adjacent NGINX hosts, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build process groups for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, reverse proxy service processes, WAF-adjacent NGINX processes, and related service-account contexts.
· Build suspicious child-process groups for shells, scripting interpreters, downloaders, network utilities, file-transfer tools, package managers, archive tools, discovery commands, credential utilities, permission-modification tools, service-control tools, and persistence-related binaries.
· Validate exact process names, process paths, parent-process depth, ancestor process behavior, service account names, command-line capture, container process representation, workload labels, and Kubernetes metadata in the local SentinelOne deployment.
· Correlate suspicious process lineage with NGINX instability, service restarts, container restarts, pod restarts, suspicious request activity, WAF events, NGINX error logs, gateway failures, ingress telemetry, NDR events, or SIEM exploit-path context where available.
· Use shorter correlation windows for NGINX worker instability, service restart, or suspicious request activity followed by shell, interpreter, downloader, file-transfer utility, network utility, or credential utility execution.
· Use moderate correlation windows for suspicious process execution followed by file writes, credential access, mounted-secret access, outbound communication, internal service probing, or service modification.
· Use longer correlation windows for delayed payload staging, repeated process patterns across assets, repeated execution from writable paths, recurring activity after suspicious request clusters, or similar activity across multiple NGINX-backed assets.
· Tune severity based on parent process lineage, command-line risk, process rarity, user context, service-account context, writable-path execution, asset exposure, service criticality, rewrite exposure, route sensitivity, destination contact, and correlated exploit-path evidence.
· Avoid broad suppression for package managers, shell usage, deployment tools, security tools, administrative commands, or container lifecycle activity without validation because legitimate maintenance and attacker execution may overlap.
· Use change-management records, approved maintenance records, deployment records, package-update records, certificate-renewal records, approved security testing, approved incident-response activity, container lifecycle events, and known automation as triage evidence before classifying activity as probable compromise.
· Validate all process groups, asset groups, service-account mappings, command-line fields, container mappings, workload labels, timing windows, local exceptions, and SentinelOne query syntax before production deployment.
DRI Assessment
DRI
9.0 / 10
· The rule is behaviorally anchored to suspicious child-process execution from NGINX-related lineage rather than static exploit strings, malformed request content, vulnerable-version exposure, or NGINX presence alone.
· The rule remains useful if the initial exploit-delivery pattern changes but successful exploitation still results in abnormal command execution from NGINX, ingress, gateway, reverse proxy, container, or service-account context.
· The score is supported by the durability of parent-child process relationships, command-line behavior, service-account context, process rarity, asset role, writable-path execution, and correlation with file, network, crash, request, identity, Kubernetes, or cloud telemetry.
· The score is constrained by incomplete agent coverage, limited command-line capture, container abstraction, service wrapper behavior, process lineage truncation, managed NGINX deployments, and legitimate administrative or deployment activity that may occasionally spawn child processes from service context.
TCR Assessment
Operational TCR
8.0 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on SentinelOne agent coverage, command-line fidelity, process ancestry depth, service-account mapping, container context, workload identity, asset tagging, and local administrative workflow baselines.
· Operational confidence is reduced where NGINX runs inside ephemeral containers, managed appliances, hardened edge systems, minimal Linux builds, or cloud-managed services with limited endpoint visibility.
· Operational confidence is reduced where deployment automation, maintenance scripts, package updates, certificate renewal, configuration management, or security tools legitimately execute child processes from NGINX-adjacent service contexts.
· Full-telemetry confidence improves when process-lineage events are enriched with NGINX access logs, NGINX error logs, worker crash artifacts, WAF events, load balancer telemetry, ingress telemetry, NDR egress, DNS logs, file telemetry, identity telemetry, Kubernetes telemetry, cloud logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for probable exploitation or post-exploitation behavior, but confirmed compromise still requires corroborating exploit-path, endpoint, network, file, identity, application, or validated impact evidence.
Limitations
This rule detects suspicious process execution from NGINX-related lineage, not the initial exploit request itself.
· Legitimate maintenance, package updates, deployment automation, certificate renewal, configuration management, security tooling, container lifecycle operations, and incident-response activity may create child-process behavior that resembles attacker execution.
· Missing command-line telemetry may reduce confidence in determining whether execution is suspicious.
· Containerized deployments may obscure parent-child lineage, process paths, service accounts, workload identity, or Kubernetes context.
· Managed NGINX deployments, appliances, and hardened edge systems may lack SentinelOne visibility.
· The rule may miss attacks that cause denial of service only, remain in memory without spawning child processes, use already-approved service binaries in expected ways, or abuse trusted operational tooling.
· Confirmation requires correlation with suspicious request activity, NGINX error logs, crash artifacts, file activity, outbound communication, credential access, downstream anomalies, Kubernetes activity, cloud activity, or validated data movement.
Detection Query Pattern
SentinelOne process-lineage query pattern requiring platform syntax validation, NGINX asset tagging, process-name validation, service-account validation, command-line capture validation, container-context validation, endpoint-to-network correlation validation, timing-window tuning, and environment-specific allowlisting before production deployment.
EndpointProcessEvent AS ProcessEvent
WHERE ProcessEvent.EndpointAsset IN ASSET_GROUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Hosts",
"NGINX Backed Ingress Controller Hosts",
"NGINX Backed Gateway Hosts",
"WAF Adjacent NGINX Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND ProcessEvent.ParentOrAncestorProcess IN PROCESS_GROUP(
"NGINX Master Processes",
"NGINX Worker Processes",
"NGINX Plus Processes",
"Ingress Controller Processes",
"Gateway Service Processes",
"Reverse Proxy Service Processes",
"WAF Adjacent NGINX Processes"
)
AND ProcessEvent.ChildProcess IN PROCESS_GROUP(
"Shells",
"Script Interpreters",
"Downloaders",
"Network Utilities",
"File Transfer Utilities",
"Package Managers",
"Archive Utilities",
"Discovery Utilities",
"Credential Utilities",
"Permission Modification Utilities",
"Service Control Utilities",
"Persistence Utilities"
)
AND (
ProcessEvent.EndpointAsset.Exposure = "internet_facing"
OR ProcessEvent.User IN USER_GROUP(
"NGINX Service Accounts",
"Reverse Proxy Service Accounts",
"Ingress Controller Service Accounts",
"Gateway Service Accounts"
)
OR EVENT_NEAR WITHIN ENV_NGINX_ENDPOINT_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR HealthEvent.EventType IN ANY (
"NGINX Worker Instability",
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
)
)
AND (
ProcessEvent.CommandLine CONTAINS_ANY ENV_SUSPICIOUS_NGINX_CHILD_PROCESS_ARGUMENTS
OR ProcessEvent.WorkingDirectory IN PATH_GROUP(
"Temporary Directories",
"Writable Web Directories",
"Container Writable Layers",
"Mounted Volumes",
"Unusual Execution Paths"
)
OR ProcessEvent.ProcessRarity IN ANY (
"new_for_host",
"rare_for_host",
"new_for_service_account",
"rare_for_service_account"
)
OR ProcessEvent.ExecutionPattern IN ANY (
"encoded_command",
"remote_retrieval",
"inline_script_execution",
"output_redirection",
"metadata_service_access",
"credential_material_access",
"mounted_secret_access"
)
)
AND NOT ProcessEvent.ChangeContext IN ANY (
"approved_deployment_activity",
"approved_package_update",
"approved_nginx_maintenance",
"approved_security_testing",
"approved_incident_response_activity",
"approved_container_lifecycle_activity",
"approved_certificate_renewal",
"approved_configuration_management",
"approved_administrative_workflow"
)
Rule
Suspicious File, Configuration, Credential, or Persistence Activity From NGINX Service Context
Rule Format
SentinelOne behavioral file-and-persistence rule suitable for endpoint file-event telemetry where enabled, process lineage, command-line telemetry where enabled, service-account context, configuration monitoring, credential-material access telemetry where available, container writable-layer visibility where available, Kubernetes mounted-volume context where available, endpoint asset tagging, NGINX path inventory, expected-change baselines, and SIEM correlation after NGINX path validation, sensitive-path validation, service-account mapping, writable-path baseline validation, configuration-path validation, container-path validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
Detect suspicious file, configuration, credential, or persistence behavior from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or related service-account context.
· Identify possible web-accessible artifact placement, temporary payload staging, configuration modification, credential-material access, mounted-secret access, cloud credential access, service modification, startup modification, scheduled-task creation, or persistence setup after suspected exploit-path activity.
· Prioritize activity involving writable directories, web-accessible paths, temporary directories, configuration paths, mounted volumes, secrets, service-account tokens, service-unit paths, startup paths, scheduled-task locations, or container writable layers.
· Support investigation of possible post-exploitation behavior without assuming that all NGINX-related file activity is malicious.
· This rule does not prove NGINX Rift exploitation, persistence, credential compromise, lateral movement, or data exfiltration without supporting process lineage, request telemetry, crash telemetry, outbound communication, identity telemetry, Kubernetes telemetry, cloud telemetry, or validated downstream evidence.
Detection Logic
Identify file, configuration, credential, or persistence activity initiated by NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or related service-account context.
· Prioritize new file creation, file modification, permission changes, ownership changes, executable-bit changes, archive extraction, symbolic link creation, service modification, startup modification, scheduled-task creation, SSH key modification, credential-file access, mounted-secret access, cloud credential access, service-account token access, or monitoring-agent tampering.
· Prioritize access to web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration paths, reverse proxy configuration paths, ingress configuration paths, gateway configuration paths, secrets, service-account tokens, cloud credential files, Kubernetes mounted secrets, service-unit locations, startup locations, scheduled-task locations, and monitoring-agent paths.
· Increase confidence when file activity follows suspicious child-process execution, NGINX worker instability, container restart, pod restart, suspicious inbound request activity, route-specific degradation, request-normalization failure, NGINX error-log artifacts, or unusual outbound communication.
· Increase confidence when file activity includes staged payloads, shell scripts, ELF binaries, encoded content, archive files, downloaded tools, web-accessible artifacts, modified service units, new startup entries, credential access, mounted-secret access, or configuration changes inconsistent with approved deployment workflows.
· Increase confidence when file changes occur under service-account context, from NGINX-related process lineage, in writable directories, in mounted volumes, in container writable layers, or across multiple NGINX-backed assets in a similar pattern.
· Increase confidence when file activity is followed by outbound communication, process execution, internal probing, identity anomalies, Kubernetes activity, cloud-control-plane activity, or downstream application anomalies.
· Reduce severity when file or configuration changes match expected package-managed NGINX configuration writes, package-managed module updates, approved certificate-renewal writes, approved certificate-store updates, approved deployment automation, approved configuration management, approved service reloads, or approved container image updates.
· Reduce severity for approved deployments, configuration management, patch activity, package updates, container image updates, certificate renewal, security testing, incident-response activity, service reloads, and documented administrative maintenance when behavior is consistent with source, user, host, workload, and time window.
· Do not classify file or configuration activity as confirmed compromise without corroborating exploit-path context, process lineage, crash evidence, outbound communication, credential access, identity telemetry, Kubernetes telemetry, cloud telemetry, or downstream impact.
· Do not treat NGINX configuration changes, package-managed config writes, certificate-renewal writes, file writes, service reloads, or container image updates as malicious by itself because these may occur during normal deployment and maintenance workflows.
Required Telemetry
SentinelOne endpoint file-event telemetry where enabled.
· SentinelOne process telemetry where available.
· Command-line telemetry where enabled.
· Parent process name.
· Parent process path.
· Ancestor process chain where available.
· Process user.
· Service-account context.
· File path.
· File name.
· File extension.
· File hash where available.
· File creation time.
· File modification time.
· File permission changes.
· File ownership changes.
· Executable-bit changes.
· Symbolic link creation where available.
· Archive extraction where available.
· File signature status where available.
· Web-accessible path inventory.
· Temporary directory inventory.
· Writable application path inventory.
· NGINX configuration path inventory.
· Reverse proxy configuration path inventory.
· Ingress configuration path inventory.
· Gateway configuration path inventory.
· Startup path inventory.
· Cron path inventory.
· Systemd path inventory.
· SSH material path inventory.
· Credential-material path inventory.
· Cloud credential path inventory.
· Kubernetes mounted-secret path inventory where available.
· Mounted volume context where available.
· Container writable-layer context where available.
· Endpoint hostname.
· Endpoint asset ID.
· Endpoint role.
· Endpoint exposure context.
· Container workload context where available.
· Kubernetes namespace where available.
· Kubernetes pod where available.
· Kubernetes node where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Endpoint network connection telemetry or process-to-network enrichment where available.
· NGINX error-log correlation where available.
· SIEM exploit-path context where available.
· Change-management, deployment, certificate-renewal, package-management, testing, and incident-response context.
Engineering Implementation Instructions
Build asset groups for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy hosts, NGINX-backed ingress-controller hosts, NGINX-backed gateway hosts, WAF-adjacent NGINX hosts, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build process groups for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, reverse proxy service processes, WAF-adjacent NGINX processes, and related service-account contexts.
· Build sensitive path groups for web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration directories, reverse proxy configuration directories, ingress configuration paths, gateway configuration paths, service-unit paths, startup locations, cron paths, SSH material paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, and monitoring-agent paths.
· Build expected-change baselines for deployments, configuration management, package-managed NGINX configuration writes, package-managed module updates, certificate renewal, certificate-store updates, package updates, container image updates, service reloads, security testing, incident-response activity, and administrative maintenance.
· Correlate suspicious file activity with NGINX process lineage, service-account context, child-process execution, worker instability, route degradation, suspicious inbound request activity, outbound communication, NGINX error-log artifacts, or SIEM exploit-path context.
· Use shorter correlation windows for child-process execution followed by file creation, credential access, mounted-secret access, permission changes, or temporary execution.
· Use moderate correlation windows for NGINX instability followed by configuration modification, web-accessible artifact placement, mounted-secret access, service modification, cloud credential access, package-unexpected configuration writes, or certificate-path writes outside approved renewal windows.
· Use longer correlation windows for delayed persistence, recurring file changes, repeated activity across multiple NGINX-backed assets, recurring suspicious activity after exploit-path indicators, or delayed staging after suspicious request clusters.
· Tune severity based on file path sensitivity, file type, executable status, service-account context, process lineage, asset exposure, business criticality, timing, change-management status, mounted-secret context, cloud credential context, package-management context, certificate-renewal context, and correlated outbound or identity activity.
· Avoid broad suppression for configuration management, package activity, certificate renewal, container image changes, service reloads, or deployment automation without validation because normal operations and attacker persistence may overlap.
· Use change-management records, deployment records, certificate-renewal records, package-management records, package-update records, approved security testing, approved incident-response activity, and known automation as triage evidence before classifying activity as suspicious or probable compromise.
· Validate all path groups, process groups, service-account mappings, container path mappings, mounted-volume mappings, file telemetry fields, expected-change baselines, timing windows, local exceptions, and SentinelOne query syntax before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious file, configuration, credential, and persistence activity from NGINX service context rather than static malware signatures, exploit strings, or vulnerable-version exposure.
· The rule remains useful if the initial exploit-delivery pattern changes but post-exploitation activity still involves staging files, modifying configuration, accessing credentials, touching mounted secrets, accessing cloud credentials, or establishing persistence from NGINX-related context.
· The score is supported by the durability of sensitive path access, process lineage, service-account context, file operation type, writable-path behavior, credential-path access, configuration modification, and correlation with process, network, crash, request, identity, Kubernetes, or cloud telemetry.
· The score is constrained by legitimate deployment activity, configuration management, package-managed NGINX configuration writes, certificate renewal, package updates, service reloads, container image changes, normal file churn, and incomplete path visibility in containers, managed environments, or appliance-like deployments.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on SentinelOne file telemetry fidelity, path visibility, process attribution, service-account mapping, sensitive path inventories, container context, expected-change baselines, package-management context, certificate-renewal context, and local deployment workflow mapping.
· Operational confidence is reduced where deployments, certificate renewals, configuration management, service reloads, package updates, or container updates produce frequent file changes under NGINX-related paths.
· Operational confidence is reduced where mounted volumes, container writable layers, ephemeral pods, managed infrastructure, or appliance-like deployments obscure file ownership and process attribution.
· Full-telemetry confidence improves when file activity is enriched with process lineage, command-line capture, NGINX access logs, NGINX error logs, crash telemetry, outbound communication, identity telemetry, Kubernetes telemetry, cloud telemetry, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for post-exploitation activity, but confirmed compromise still requires corroborating exploit-path, endpoint, network, identity, application, or validated impact evidence.
Limitations
This rule detects suspicious file, configuration, credential, or persistence activity from NGINX-related context, not the initial exploit request itself.
· Legitimate deployment automation, configuration management, certificate renewal, package-managed configuration writes, package updates, service reloads, container image replacement, and incident-response actions may create similar file activity.
· Containerized deployments may lose file evidence when pods restart, writable layers are discarded, nodes are replaced, or workloads are rescheduled.
· Managed or appliance-based NGINX deployments may not expose file telemetry to SentinelOne.
· Missing process attribution may prevent confirmation that file activity originated from NGINX service context.
· The rule may miss attacks that remain memory-only, avoid file writes, use existing files, operate through approved deployment paths, or abuse existing service permissions without creating new artifacts.
· Confirmation requires correlation with process lineage, suspicious request activity, NGINX error logs, crash artifacts, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, or validated downstream impact.
Detection Query Pattern
SentinelOne file-and-persistence query pattern requiring platform syntax validation, NGINX asset tagging, sensitive-path validation, service-account mapping, process-lineage validation, container-path validation, expected-change baseline validation, timing-window tuning, and environment-specific allowlisting before production deployment.
EndpointFileEvent AS FileEvent
WHERE FileEvent.EndpointAsset IN ASSET_GROUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Hosts",
"NGINX Backed Ingress Controller Hosts",
"NGINX Backed Gateway Hosts",
"WAF Adjacent NGINX Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
FileEvent.InitiatingProcess IN PROCESS_GROUP(
"NGINX Master Processes",
"NGINX Worker Processes",
"NGINX Plus Processes",
"Ingress Controller Processes",
"Gateway Service Processes",
"Reverse Proxy Service Processes",
"WAF Adjacent NGINX Processes"
)
OR FileEvent.InitiatingUser IN USER_GROUP(
"NGINX Service Accounts",
"Reverse Proxy Service Accounts",
"Ingress Controller Service Accounts",
"Gateway Service Accounts"
)
)
AND FileEvent.Path IN PATH_GROUP(
"Web Accessible Directories",
"Temporary Directories",
"Writable Application Paths",
"Mounted Volumes",
"NGINX Configuration Paths",
"Reverse Proxy Configuration Paths",
"Ingress Configuration Paths",
"Gateway Configuration Paths",
"Service Unit Paths",
"Startup Paths",
"Cron Paths",
"SSH Material Paths",
"Credential Material Paths",
"Cloud Credential Paths",
"Kubernetes Mounted Secret Paths",
"Container Writable Layers",
"Monitoring Agent Paths"
)
AND (
FileEvent.Operation IN ANY (
"create",
"modify",
"delete",
"permission_change",
"ownership_change",
"executable_bit_set",
"symbolic_link_created",
"archive_extracted",
"credential_read",
"secret_read"
)
OR FileEvent.FileType IN ANY (
"shell_script",
"elf_binary",
"archive",
"encoded_payload",
"web_accessible_artifact",
"credential_file",
"service_unit",
"startup_script"
)
OR FileEvent.Sensitivity IN ANY (
"credential_material",
"service_account_token",
"cloud_credential",
"kubernetes_secret",
"nginx_configuration",
"reverse_proxy_configuration",
"startup_or_persistence_location"
)
)
AND OPTIONAL_CONFIDENCE_INCREASE WITHIN ENV_NGINX_FILE_ACTIVITY_WINDOW (
ProcessEvent.EventType IN ANY (
"Suspicious Child Process From NGINX Lineage",
"Shell Spawned From NGINX Context",
"Downloader Spawned From NGINX Context",
"Interpreter Spawned From NGINX Context",
"Credential Utility Spawned From NGINX Context"
)
OR WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR NetworkEvent.EventType IN ANY (
"Unusual Outbound Communication From NGINX Infrastructure",
"Rare Destination Contact From Reverse Proxy Tier",
"Direct IP Egress From NGINX Host"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit"
)
)
AND NOT FileEvent.ChangeContext IN ANY (
"approved_deployment_activity",
"approved_configuration_management",
"approved_certificate_renewal",
"approved_certificate_store_update",
"approved_package_managed_nginx_config_write",
"approved_package_managed_module_update",
"approved_package_update",
"approved_nginx_maintenance",
"approved_security_testing",
"approved_incident_response_activity",
"approved_container_image_update",
"approved_service_reload",
"approved_administrative_workflow"
)
Rule
Suspicious Outbound Network Activity Initiated by NGINX-Related Child Processes
Rule Format
SentinelOne behavioral process-network correlation rule suitable for endpoint network telemetry or process-to-network enrichment where available, process lineage, command-line telemetry where enabled, destination enrichment, DNS enrichment where available, service-account context, container context where available, workload identity where available, NGINX asset tagging, approved-egress baselines, exploit-path correlation, and SIEM correlation after process-to-network validation, destination-enrichment validation, approved-destination mapping, workload-context validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
Detect outbound network activity initiated by suspicious child processes spawned from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or related service-account lineage.
· Identify possible callback, payload retrieval, tool download, command-and-control, staging, tunneling, direct IP communication, or data transfer from endpoint processes associated with NGINX exploitation context.
· Prioritize network activity involving rare, newly observed, low-reputation, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unusual cloud, direct IP, unusual port, infrastructure-like, or non-baselined destinations.
· Support investigation of possible post-exploitation communication without assuming that all NGINX host egress is malicious.
· This rule does not prove NGINX Rift exploitation, host compromise, credential compromise, lateral movement, or data exfiltration without supporting process lineage, request telemetry, crash telemetry, file activity, identity telemetry, Kubernetes telemetry, cloud telemetry, or validated data-flow evidence.
Detection Logic
Identify outbound network connections initiated by processes spawned from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or related service-account lineage.
· Prioritize outbound network activity initiated by shell, interpreter, downloader, network utility, file-transfer utility, package manager, archive utility, discovery utility, credential utility, or suspicious child process from NGINX context.
· Prioritize destinations that are rare for the asset, newly observed, low-reputation, unknown external, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unapproved cloud, direct IP, unusual port, or outside approved NGINX dependency baselines.
· Increase confidence when the process network activity follows NGINX worker instability, suspicious request activity, route-specific degradation, segmentation fault indicators, service restart, container restart, pod restart, file writes, credential-material access, mounted-secret access, or suspicious file activity.
· Increase confidence when outbound activity includes direct IP communication, unusual TLS SNI, abnormal user agent, unexpected protocol, high byte count, repeated beacon-like timing, abnormal session duration, command-line retrieval behavior, or destination reuse across multiple affected assets.
· Increase confidence when the same destination, domain, ASN, hosting provider, tunnel provider, or infrastructure cluster is contacted by multiple NGINX-backed assets after similar exploit-path indicators.
· Increase confidence when outbound activity is initiated by a child process with suspicious command-line arguments, unusual working directory, writable-path execution, encoded command behavior, rare process lineage, or service-account context.
· Reduce severity for approved upstream applications, package repositories, update repositories, observability platforms, log forwarders, security tooling, management endpoints, service mesh endpoints, deployment automation, and documented administrative workflows when behavior is consistent with asset, user, service, and time window.
· Do not classify outbound process-network activity as confirmed compromise without corroborating exploit-path context, file activity, crash telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, downstream application anomalies, or validated data-flow evidence.
· Do not treat outbound traffic from an NGINX host as malicious by itself because reverse proxy infrastructure may legitimately communicate with upstream services and operational tooling.
Required Telemetry
SentinelOne endpoint network telemetry or process-to-network enrichment where available.
· SentinelOne process telemetry where available.
· Command-line telemetry where enabled.
· Parent process name.
· Parent process path.
· Ancestor process chain where available.
· Initiating process name.
· Initiating process path.
· Process user.
· Service-account context.
· Working directory.
· Destination IP.
· Destination domain.
· Destination hostname.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Session duration.
· Byte count.
· Connection count.
· TLS SNI where available.
· HTTP host where available.
· User agent where available.
· Destination reputation.
· Destination category.
· Destination ASN.
· Destination geolocation.
· Destination first-seen timestamp.
· Domain age where available.
· Endpoint hostname.
· Endpoint asset ID.
· Endpoint role.
· Endpoint exposure context.
· Container workload context where available.
· Kubernetes namespace where available.
· Kubernetes pod where available.
· Kubernetes node where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, and management destinations.
· Prior suspicious inbound request context where available.
· NGINX service instability context where available.
· File telemetry correlation where available.
· Identity-provider correlation where available.
· Kubernetes telemetry where available.
· Cloud telemetry where available.
· SIEM exploit-path context where available.
· Change-management, testing, incident-response, and maintenance-window context.
Engineering Implementation Instructions
Build asset groups for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy hosts, NGINX-backed ingress-controller hosts, NGINX-backed gateway hosts, WAF-adjacent NGINX hosts, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build process groups for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, reverse proxy service processes, WAF-adjacent NGINX processes, suspicious child processes, shells, interpreters, downloaders, file-transfer tools, network utilities, package managers, and credential utilities.
· Build approved destination groups for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and documented internal services.
· Validate process-to-network attribution in SentinelOne for host-based, containerized, Kubernetes, ingress-controller, gateway, and reverse proxy deployments.
· Add enrichment for destination reputation, destination category, destination first-seen timestamp, domain age, ASN, hosting provider, VPN provider, cloud provider, tunnel provider, sanctioned-service status, source asset role, workload identity, service criticality, and business function.
· Correlate outbound process-network activity with suspicious child-process execution, NGINX instability, service restart, container restart, pod restart, suspicious inbound request activity, route-specific degradation, file activity, credential access, mounted-secret access, NGINX error-log artifacts, or SIEM exploit-path context.
· Use shorter correlation windows for suspicious process execution followed by immediate DNS lookup, direct IP connection, rare destination contact, command-line retrieval, or tunneling behavior.
· Use moderate correlation windows for NGINX instability, file activity, credential access, or mounted-secret access followed by outbound process-network communication.
· Use longer correlation windows for delayed callback, repeated destination contact, repeated infrastructure reuse, or recurring activity across multiple NGINX-backed assets.
· Tune severity based on process lineage, command line, destination novelty, destination reputation, protocol, port, byte count, session duration, source asset criticality, exposed role, prior exploit-path context, service-account context, and approved dependency status.
· Avoid broad suppression for cloud providers, CDNs, repositories, package infrastructure, update services, security tools, service mesh endpoints, or management endpoints without validation because legitimate dependencies and attacker infrastructure may overlap.
· Use change-management records, approved maintenance records, package-update records, monitoring records, security-tool activity, deployment records, and incident-response records as triage evidence before classifying activity as suspicious or probable compromise.
· Validate all process groups, asset groups, approved-destination lists, enrichment fields, process-to-network joins, workload context, dependency baselines, timing windows, local parser behavior, and SentinelOne query syntax before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to outbound network activity initiated by suspicious NGINX-related child processes rather than generic host egress, static exploit indicators, malformed request content, or vulnerable-version exposure.
· The rule remains useful if the exploit-delivery pattern changes but post-exploitation activity still produces callback, staging, tool retrieval, command-and-control, tunneling, direct IP communication, or data-transfer behavior from NGINX-related process context.
· The score is supported by the durability of process-to-network attribution, parent-child lineage, destination novelty, destination reputation, approved egress baselines, service-account context, workload context, and correlation with file, crash, request, identity, Kubernetes, or cloud telemetry.
· The score is constrained by legitimate update activity, package retrieval, observability traffic, incomplete process-to-network attribution, encrypted traffic, approved cloud-provider use, container abstraction, service-mesh abstraction, and normal reverse proxy dependencies.
TCR Assessment
Operational TCR
8.0 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on process-to-network attribution, destination enrichment, approved egress baselines, command-line fidelity, asset tagging, service-account mapping, container context, workload identity, and availability of prior exploit-path context.
· Operational confidence is reduced where outbound traffic is attributed only to host identity rather than initiating process, container, workload, or service account.
· Operational confidence is reduced where NGINX infrastructure routinely contacts broad cloud platforms, update repositories, package repositories, SaaS services, monitoring systems, service mesh endpoints, and internal APIs without stable baselines.
· Full-telemetry confidence improves when process-network events are enriched with NGINX access logs, NGINX error logs, crash telemetry, WAF events, NDR flow telemetry, file telemetry, identity-provider events, Kubernetes telemetry, cloud logs, application telemetry, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for post-exploitation communication, but confirmed compromise still requires corroborating exploit-path, endpoint, identity, file, application, or validated data-flow evidence.
Limitations
This rule detects suspicious outbound communication initiated by NGINX-related child processes, not the initial exploit request itself.
· Legitimate package updates, repository access, observability traffic, security tooling, deployment automation, service mesh traffic, management workflows, and incident-response activity may create similar outbound patterns.
· Missing process-to-network attribution may reduce confidence or make the rule dependent on host-level egress instead of initiating-process evidence.
· NAT, service mesh, proxy chaining, cloud networking, and container networking may obscure destination attribution or source workload identity.
· Destination reputation may be incomplete or misleading for newly created, compromised, shared, or legitimate cloud-hosted infrastructure.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common cloud providers, use permitted service dependencies, or blend into normal upstream communication.
· Confirmation requires correlation with suspicious request activity, process lineage, crash artifacts, file activity, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application impact, or validated data movement.
Detection Query Pattern
SentinelOne process-network correlation query pattern requiring platform syntax validation, NGINX asset tagging, process-to-network attribution validation, approved-egress validation, destination-enrichment validation, exploit-path context validation, workload identity validation, timing-window tuning, and environment-specific allowlisting before production deployment.
EndpointNetworkEvent AS NetworkEvent
WHERE NetworkEvent.EndpointAsset IN ASSET_GROUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Hosts",
"NGINX Backed Ingress Controller Hosts",
"NGINX Backed Gateway Hosts",
"WAF Adjacent NGINX Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND NetworkEvent.Direction = "Outbound"
AND NetworkEvent.InitiatingProcess IN PROCESS_GROUP(
"Shells Spawned From NGINX Context",
"Interpreters Spawned From NGINX Context",
"Downloaders Spawned From NGINX Context",
"Network Utilities Spawned From NGINX Context",
"File Transfer Utilities Spawned From NGINX Context",
"Package Managers Spawned From NGINX Context",
"Credential Utilities Spawned From NGINX Context",
"Suspicious NGINX Child Processes"
)
AND (
NetworkEvent.DestinationFirstSeen WITHIN ENV_NEW_DESTINATION_WINDOW
OR NetworkEvent.DestinationDomainAge <= ENV_NEW_DOMAIN_AGE_WINDOW
OR NetworkEvent.DestinationReputation IN ANY (
"high_risk",
"suspicious",
"rare",
"newly_observed",
"unknown"
)
OR NetworkEvent.DestinationCategory IN ANY (
"temporary_hosting",
"paste_service",
"file_sharing",
"tunneling",
"dynamic_dns",
"unapproved_cloud_storage",
"unknown_external",
"infrastructure_like"
)
OR NetworkEvent.DestinationPort NOT IN ENV_APPROVED_NGINX_EGRESS_PORTS
OR NetworkEvent.ByteCount >= ENV_NGINX_PROCESS_EGRESS_VOLUME_THRESHOLD
OR NetworkEvent.SessionPattern IN ANY (
"beacon_like",
"unusual_duration",
"repeated_rare_destination",
"direct_ip_connection",
"unusual_tls_sni"
)
)
AND OPTIONAL_CONFIDENCE_INCREASE WITHIN ENV_NGINX_PROCESS_NETWORK_CORRELATION_WINDOW (
ProcessEvent.EventType IN ANY (
"Suspicious Child Process From NGINX Lineage",
"Shell Spawned From NGINX Context",
"Downloader Spawned From NGINX Context",
"Interpreter Spawned From NGINX Context",
"Credential Utility Spawned From NGINX Context"
)
OR FileEvent.EventType IN ANY (
"Suspicious File Activity From NGINX Context",
"Credential Material Access From NGINX Context",
"Mounted Secret Access From NGINX Context",
"Web Accessible Artifact Created From NGINX Context"
)
OR WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit"
)
)
AND NetworkEvent.DestinationIP NOT IN ASSET_GROUP(
"Approved Upstream Application Destinations",
"Approved Observability Destinations",
"Approved Log Forwarding Destinations",
"Approved Package Repository Destinations",
"Approved Update Repository Destinations",
"Approved Corporate Proxy Destinations",
"Approved Security Tool Destinations",
"Approved Monitoring Destinations",
"Approved Service Mesh Destinations",
"Approved Management Destinations"
)
AND NOT NetworkEvent.ChangeContext IN ANY (
"approved_patch_activity",
"approved_service_maintenance",
"approved_nginx_reload",
"approved_package_update",
"approved_monitoring_activity",
"approved_security_testing",
"approved_incident_response_activity",
"approved_deployment_activity"
)
Splunk
Detection Viability Assessment
Splunk has three rules for this EXP report.
· Splunk is viable for detecting NGINX Rift exploit-path activity because it can correlate NGINX access logs, NGINX error logs, WAF logs, load balancer logs, ingress telemetry, endpoint telemetry, DNS logs, proxy logs, firewall logs, NetFlow, cloud flow logs, Kubernetes telemetry, vulnerability-management context, asset inventory, route mapping, and change-management context.
· Splunk is strongest where Common Information Model normalization, sourcetype validation, index mapping, field extraction, asset enrichment, route-level context, scanner allowlists, approved egress baselines, endpoint process telemetry, and web-to-host correlation are available.
· Splunk can identify suspicious sequencing between malformed request activity, rewrite-route targeting, route-specific error spikes, NGINX worker instability, abnormal child-process execution, file or configuration changes, unusual outbound communication, and downstream backend access.
· Splunk is not a standalone source for confirming successful NGINX Rift exploitation unless the required web, endpoint, crash, network, file, and asset-context telemetry is available and correlated.
· Splunk rules should be treated as high-value correlation content for exploit-attempt detection, probable exploitation, post-exploitation behavior, and downstream exposure assessment, not as proof of compromise from any single log source.
· Splunk detections must be validated against local indexes, sourcetypes, field mappings, timestamp normalization, parser behavior, asset models, route mappings, scanner allowlists, dependency baselines, expected-change baselines, and deployment workflows before production alerting.
Rule
Suspicious NGINX Rewrite-Path Request Activity With Optional Service-Instability Correlation
Rule Format
Splunk correlation rule suitable for NGINX access logs, NGINX error logs, WAF telemetry, CDN telemetry, load balancer telemetry, ingress telemetry, gateway logs, infrastructure health logs, asset inventory, vulnerability-management context, route mapping, scanner allowlists, and SIEM correlation after SPL syntax translation, sourcetype validation, index validation, field extraction validation, route-context validation, timestamp normalization, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious malformed HTTP or HTTPS request activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure.
· Identify possible exploit probing, malformed request delivery, rewrite-path manipulation, route-specific request variation, or exploit-path adaptation against exposed NGINX-backed services.
· Prioritize suspicious request behavior that is strengthened by NGINX worker instability, segmentation fault indicators, abnormal worker exits, restart loops, route-specific 500-series spikes, upstream reset behavior, gateway failures, or backend degradation.
· Support early identification of attempted exploitation and likely denial-of-service outcomes without relying on a single exploit string, static request fragment, vulnerable-version exposure alone, or direct inspection of worker memory state.
· This rule does not prove successful exploitation, code execution, host compromise, credential compromise, or data exposure without supporting endpoint, file, network, identity, application, or validated downstream evidence.
Detection Logic
· Identify inbound HTTP or HTTPS activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, or NGINX-backed application infrastructure.
· Prioritize request activity involving excessive URI length, repeated encoding, double encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, unusual route variation, capture-like route structures, uncommon methods, malformed headers, suspicious query structure, or request normalization failure.
· Prioritize requests against rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, legacy application paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream application routes.
· Increase confidence when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, NGINX reload failures, service restarts, container restarts, pod restarts, or route-specific service degradation.
· Increase confidence when suspicious request activity is followed by elevated 500-series responses, upstream reset spikes, gateway errors, backend failures, abnormal request timing, or health-check degradation.
· Increase confidence when similar request patterns are observed across multiple exposed NGINX-backed services, virtual hosts, ingress paths, gateway routes, or reverse proxy tiers within a short time window.
· Increase confidence when affected assets are internet-facing, unpatched, rewrite-heavy, WAF-adjacent, ingress-facing, gateway-facing, business-critical, or fronting authentication, API, payment, administrative, identity, or customer-facing services.
· Reduce severity for approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, sanctioned security testing, and known benign scanner activity when behavior is consistent with source, route, asset, and time window.
· Do not classify suspicious request activity as confirmed compromise without corroborating endpoint process activity, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated impact evidence.
· Do not treat NGINX presence, internet exposure, vulnerable-version context, malformed requests, route-specific errors, or worker instability as compromise evidence by itself.
Required Telemetry
· Splunk indexes containing NGINX access logs.
· Splunk indexes containing NGINX error logs.
· WAF logs where available.
· CDN logs where available.
· Load balancer logs where available.
· Gateway logs where available.
· Ingress controller logs where available.
· Infrastructure health logs where available.
· Container restart or pod restart telemetry where available.
· Source IP.
· Source ASN where available.
· Source geolocation where available.
· Source reputation where available after enrichment validation.
· Destination IP.
· Destination hostname.
· Destination virtual host.
· Destination service identity after field extraction validation.
· Destination asset identity after enrichment validation.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Request method where available.
· Raw URI where available.
· Normalized URI where available.
· Query string where available.
· HTTP host where available.
· TLS SNI where available.
· User agent where available.
· Response code where available.
· Upstream response code where available after field extraction validation.
· Request duration where available.
· Upstream response time where available after field extraction validation.
· Request size or URI length where available.
· NGINX worker crash indicators where available after error-log parsing validation.
· NGINX segmentation fault indicators where available after error-log parsing validation.
· NGINX abnormal worker exit indicators where available after error-log parsing validation.
· Route or application mapping where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Rewrite-heavy route inventory where available.
· Patch status where available.
· Vulnerability-management context where available.
· Approved scanner inventory.
· Approved testing source inventory.
· Change-management, patch-validation, maintenance, and incident-response context.
Engineering Implementation Instructions
· Build Splunk asset lookups for internet-facing NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy infrastructure, NGINX-backed ingress controllers, NGINX-backed gateway services, WAF-adjacent NGINX services, customer-facing NGINX-backed applications, and high-value NGINX-backed exposed infrastructure.
· Build route lookups for rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway routes, legacy application paths, administrative portals, customer-facing virtual hosts, and high-dependency upstream application paths.
· Validate local indexes and sourcetypes for NGINX access logs, NGINX error logs, WAF logs, load balancer logs, gateway logs, ingress logs, CDN logs, infrastructure health logs, container telemetry, and Kubernetes telemetry.
· Validate field extractions for source IP, destination asset, virtual host, URI, normalized URI, query string, response code, upstream response code, request timing, upstream timing, user agent, TLS SNI, error message, worker process ID, and service identity.
· Normalize timestamps across web logs, NGINX error logs, WAF logs, load balancer logs, infrastructure health logs, endpoint telemetry, and cloud or container telemetry.
· Use request-shape analytics rather than a single exploit string, public demonstration artifact, or static request fragment.
· Add source clustering by IP, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent family, request shape, route target, and time window.
· Add route-level service-impact correlation for 500-series spikes, upstream resets, gateway errors, backend failures, NGINX worker crashes, abnormal worker exits, service restarts, container restarts, pod restarts, and health-check degradation.
· Treat response degradation and crash evidence as confidence-increasing signals rather than the only detection path.
· Add affected-asset enrichment for NGINX version, NGINX Plus status, patch state, rewrite exposure, exposed service role, business criticality, WAF-adjacent status, ingress status, gateway status, and hosted application sensitivity.
· Use shorter correlation windows for suspicious malformed requests followed by immediate worker instability, route degradation, upstream resets, gateway failures, or service degradation.
· Use moderate correlation windows for repeated route probing, distributed source clustering, repeated request-shape reuse, or activity across multiple NGINX-backed services.
· Use longer correlation windows for delayed exploitation validation, repeated infrastructure reuse, and retroactive hunting after amendment-relevant exploit-path changes.
· Tune severity based on exposed-service criticality, rewrite exposure, request abnormality, source reputation, source clustering, route sensitivity, response impact, scanner status, patch state, and correlated instability.
· Validate scanner allowlists, testing allowlists, synthetic-monitoring allowlists, health-check sources, change-management records, and incident-response context before production deployment.
· Validate final SPL syntax, macro behavior, lookup names, accelerated data model availability, and local performance impact before enabling scheduled alerting.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious request activity against exposed NGINX-backed infrastructure with optional service-instability correlation rather than static exploit strings, vulnerable-version exposure, or NGINX presence alone.
· The rule remains useful if the initial exploit-path request changes but activity still involves rewrite-route targeting, abnormal request shape, source clustering, route-specific errors, or worker instability.
· The score is supported by the durability of NGINX access logs, NGINX error logs, response-code behavior, route context, source clustering, asset enrichment, and worker instability artifacts.
· The score is constrained by TLS visibility gaps, proxy and WAF normalization, incomplete URI preservation, missing route mapping, scanner noise, incomplete NGINX error-log parsing, and uneven sourcetype normalization across edge layers.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on NGINX access-log fidelity, NGINX error-log fidelity, sourcetype quality, timestamp normalization, source IP preservation, route mapping, scanner allowlists, and affected-service enrichment.
· Operational confidence is reduced where CDN, WAF, load balancer, ingress, gateway, or reverse proxy layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Operational confidence is reduced where internet-facing services receive high volumes of scanner traffic, fuzzing, malformed crawler traffic, synthetic monitoring, authorized validation, or health-check activity.
· Full-telemetry confidence improves when request anomalies are enriched with NGINX error logs, WAF telemetry, load balancer telemetry, ingress telemetry, NDR events, endpoint telemetry, crash artifacts, patch context, rewrite-route context, and change-management records.
· Under full telemetry conditions, this rule provides strong escalation evidence for attempted exploitation or likely denial-of-service impact, but confirmed compromise still requires corroborating endpoint, file, network, identity, application, or validated impact evidence.
Limitations
· This rule detects suspicious request activity and optional service-instability correlation, not successful code execution by itself.
· NGINX worker crashes, 500-series spikes, gateway failures, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, misconfiguration, package updates, or maintenance.
· CDN, WAF, load balancer, ingress, gateway, or proxy normalization may obscure original request shape.
· Raw URI and normalized URI may be unavailable, truncated, or inconsistently parsed.
· Approved scanners, emergency validation, penetration testing, synthetic monitoring, uptime monitoring, CDN health checks, and load balancer probes may produce similar request and error artifacts.
· Missing rewrite-route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· Confirmation requires correlation with endpoint process lineage, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated data movement.
Detection Query Pattern
Splunk correlation query pattern requiring SPL syntax translation, SPL syntax validation, index validation, sourcetype validation, field extraction validation, NGINX asset tagging, rewrite-route context validation, request-field validation, error-log parsing validation, scanner allowlist validation, timing-window tuning, and environment-specific allowlisting before production deployment.
SplunkEvent AS InboundRequest
WHERE InboundRequest.index IN ENV_NGINX_WEB_INDEXES
AND InboundRequest.sourcetype IN ENV_NGINX_ACCESS_SOURCETYPES
AND InboundRequest.DestinationAsset IN LOOKUP(
"Internet Facing NGINX Servers",
"Internet Facing NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"NGINX Backed Customer Facing Applications",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
InboundRequest.RequestPath IN LOOKUP(
"Rewrite Heavy Routes",
"Authentication Paths",
"API Paths",
"Ingress Paths",
"Gateway Routes",
"Legacy Application Paths",
"Administrative Portals",
"Customer Facing Virtual Hosts"
)
OR InboundRequest.DestinationAsset.Exposure = "internet_facing"
)
AND (
InboundRequest.UriLength >= ENV_NGINX_URI_LENGTH_ANOMALY_THRESHOLD
OR InboundRequest.EncodedCharacterCount >= ENV_NGINX_ENCODING_DENSITY_THRESHOLD
OR InboundRequest.DelimiterDensity >= ENV_NGINX_DELIMITER_DENSITY_THRESHOLD
OR InboundRequest.PathExpansionScore >= ENV_NGINX_PATH_EXPANSION_THRESHOLD
OR InboundRequest.RequestNormalizationResult IN ANY (
"failed",
"ambiguous",
"rewritten",
"truncated",
"malformed"
)
OR InboundRequest.Method NOT IN ENV_APPROVED_METHODS_FOR_ROUTE
OR InboundRequest.HeaderAnomalyScore >= ENV_HEADER_ANOMALY_THRESHOLD
)
AND (
InboundRequest.SourceReputation IN ANY (
"high_risk",
"suspicious",
"scanner",
"unknown",
"newly_observed"
)
OR InboundRequest.SourceASN IN WATCHLIST(
"Scanner Infrastructure",
"Bulletproof Hosting",
"Unusual Cloud Hosting",
"Known Exploit Infrastructure"
)
OR COUNT_SIMILAR_EVENTS(
InboundRequest.SourceIP,
InboundRequest.RequestShape,
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_REQUEST_CLUSTER_THRESHOLD
OR COUNT_DISTINCT_DESTINATIONS(
InboundRequest.SourceIP,
"NGINX Backed Assets",
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_MULTI_ASSET_PROBE_THRESHOLD
)
AND OPTIONAL_CONFIDENCE_INCREASE WITHIN ENV_NGINX_REQUEST_IMPACT_WINDOW (
ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR WebEvent.EventType IN ANY (
"Route Specific 500 Spike",
"Upstream Reset Spike",
"Gateway Failure Spike",
"Backend Failure Spike",
"NGINX Backed Service Degradation"
)
OR HealthEvent.EventType IN ANY (
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND InboundRequest.SourceIP NOT IN LOOKUP(
"Approved Vulnerability Scanners",
"Approved Security Testing Sources",
"Approved Emergency Validation Sources",
"Approved Synthetic Monitoring Sources",
"Approved Uptime Monitoring Sources",
"Approved CDN Health Check Sources",
"Approved Load Balancer Probe Sources"
)
AND NOT ChangeContext IN ANY (
"approved_patch_validation",
"approved_penetration_test",
"approved_incident_response_activity",
"approved_qa_testing",
"approved_synthetic_monitoring",
"approved_load_balancer_health_check",
"approved_nginx_maintenance"
)
Rule
NGINX Exploit-Path Activity Followed by Suspicious Process, File, or Service Behavior
Rule Format
Splunk multi-source correlation rule suitable for NGINX access logs, NGINX error logs, EDR process telemetry where available, Linux audit telemetry where available, SentinelOne telemetry where available, endpoint file-event telemetry where enabled, service manager logs where available, container runtime logs where available, Kubernetes telemetry where available, asset inventory, route context, service-account mapping, change-management context, and SIEM correlation after SPL syntax translation, index validation, sourcetype validation, field extraction validation, endpoint-to-web correlation validation, process-lineage validation, path mapping, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious process, file, configuration, credential, or service behavior on NGINX-backed infrastructure after exploit-path request activity or NGINX instability.
· Identify possible probable exploitation or post-exploitation behavior involving unexpected child processes, temporary execution, file staging, configuration modification, credential-material access, mounted-secret access, service modification, or persistence activity.
· Prioritize host and workload behavior occurring after suspicious request activity, route-specific errors, NGINX worker instability, segmentation fault indicators, service restarts, container restarts, or pod restarts.
· Support investigation of probable compromise without assuming that every service restart, child process, or file change on NGINX infrastructure is malicious.
· This rule does not prove successful exploitation, persistence, credential compromise, lateral movement, or data exfiltration without supporting endpoint, network, identity, Kubernetes, cloud, application, or validated data-flow evidence.
Detection Logic
· Identify suspicious process, file, configuration, credential, or service behavior on NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Prioritize child-process execution from NGINX master processes, NGINX worker processes, ingress-controller processes, gateway service processes, reverse proxy processes, WAF-adjacent NGINX processes, or related service-account context.
· Prioritize file activity involving web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration paths, reverse proxy configuration paths, ingress configuration paths, gateway configuration paths, service-unit paths, startup paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, or monitoring-agent paths.
· Increase confidence when process or file activity follows suspicious request activity, rewrite-route request anomalies, route-specific 500-series spikes, upstream reset behavior, gateway failures, NGINX worker crash indicators, segmentation fault indicators, container restarts, pod restarts, or service degradation.
· Increase confidence when suspicious process behavior includes shell execution, interpreter execution, downloader use, file-transfer utility use, archive utility use, package-manager execution, discovery utility use, credential utility use, service-control utility use, encoded command execution, remote retrieval, temporary-directory execution, or writable-path execution.
· Increase confidence when file activity includes staged payloads, shell scripts, ELF binaries, encoded content, archive files, downloaded tools, web-accessible artifacts, modified service units, new startup entries, credential access, mounted-secret access, or configuration changes inconsistent with approved deployment workflows.
· Increase confidence when endpoint behavior is followed by unusual outbound communication, internal service probing, identity anomalies, Kubernetes activity, cloud activity, or downstream application anomalies.
· Reduce severity when activity matches approved deployment automation, package-managed NGINX configuration writes, package-managed module updates, certificate-renewal writes, certificate-store updates, service reloads, container image updates, configuration management, security testing, incident-response workflows, or known administrative maintenance.
· Do not classify endpoint behavior as confirmed compromise without corroborating exploit-path context, request telemetry, crash evidence, network telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application telemetry, or validated downstream impact.
· Do not treat NGINX service restarts, child-process creation, file writes, package updates, configuration changes, or certificate activity as malicious by itself.
Required Telemetry
· Splunk indexes containing NGINX access logs.
· Splunk indexes containing NGINX error logs.
· EDR process telemetry where available.
· SentinelOne telemetry where available.
· Linux audit telemetry where available.
· Service manager logs where available.
· Endpoint file-event telemetry where enabled.
· Container runtime logs where available.
· Kubernetes telemetry where available.
· Endpoint hostname.
· Endpoint asset ID.
· Endpoint role.
· Endpoint exposure context.
· Parent process name after field extraction validation.
· Parent process path after field extraction validation.
· Ancestor process chain where available.
· Child process name after field extraction validation.
· Child process path after field extraction validation.
· Command-line telemetry where enabled.
· Process user.
· Service-account context after field extraction validation.
· Working directory where available.
· File path after field extraction validation.
· File name where available.
· File hash where available.
· File operation after field extraction validation.
· File sensitivity where available after enrichment validation.
· NGINX service restart context.
· NGINX worker crash context where available after error-log parsing validation.
· NGINX segmentation fault context where available after error-log parsing validation.
· Container restart context where available.
· Pod restart context where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Sensitive path inventory.
· Expected-change baselines.
· Change-management, deployment, certificate-renewal, package-management, testing, and incident-response context.
Engineering Implementation Instructions
· Build Splunk asset lookups for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy hosts, NGINX-backed ingress-controller hosts, NGINX-backed gateway hosts, WAF-adjacent NGINX hosts, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build process lookups for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, reverse proxy service processes, WAF-adjacent NGINX processes, suspicious child processes, shells, interpreters, downloaders, file-transfer tools, network utilities, package managers, credential utilities, service-control utilities, and persistence utilities.
· Build sensitive path lookups for web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration directories, reverse proxy configuration directories, ingress configuration paths, gateway configuration paths, service-unit paths, startup locations, cron paths, SSH material paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, and monitoring-agent paths.
· Build expected-change lookups for approved deployment activity, configuration management, package-managed NGINX configuration writes, package-managed module updates, certificate renewal, certificate-store updates, package updates, container image updates, service reloads, security testing, incident-response activity, and administrative maintenance.
· Validate indexes and sourcetypes for web telemetry, error logs, process telemetry, file telemetry, service logs, container logs, Kubernetes logs, and vulnerability context.
· Validate field extractions for process name, parent process, command line, process user, file path, file operation, service account, container identity, workload identity, host identity, route context, error-log context, and timestamp.
· Correlate suspicious host activity with NGINX exploit-path indicators, including malformed request activity, rewrite-route anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, container restarts, pod restarts, and NGINX error-log artifacts.
· Use shorter correlation windows for worker instability or suspicious request activity followed by shell, interpreter, downloader, network utility, file-transfer utility, credential utility, or suspicious file activity.
· Use moderate correlation windows for NGINX instability followed by configuration modification, credential access, mounted-secret access, service modification, file staging, or outbound communication.
· Use longer correlation windows for delayed payload staging, recurring file changes, repeated process behavior, or recurring activity across multiple NGINX-backed assets.
· Tune severity based on process lineage, command-line risk, file path sensitivity, service-account context, asset exposure, route sensitivity, business criticality, change-management status, expected-change context, and correlated network or identity activity.
· Validate all lookups, field extractions, timing windows, expected-change controls, macro behavior, data model acceleration assumptions, and local parser behavior before production deployment.
DRI Assessment
DRI
9.0 / 10
· The rule is behaviorally anchored to suspicious host activity after NGINX exploit-path indicators rather than static exploit strings or vulnerable-version exposure.
· The rule remains useful if the initial exploit request changes but successful exploitation still results in abnormal child-process execution, file staging, credential access, service modification, or persistence behavior.
· The score is supported by durable process lineage, file path sensitivity, service-account context, error-log correlation, request-to-host sequencing, asset role, and expected-change controls.
· The score is constrained by missing endpoint telemetry, incomplete command-line capture, limited file telemetry, container abstraction, managed infrastructure, process lineage truncation, legitimate deployment activity, and uneven endpoint sourcetype normalization.
TCR Assessment
Operational TCR
8.0 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on process telemetry fidelity, file telemetry fidelity, NGINX error-log parsing, endpoint asset tagging, service-account mapping, sensitive path inventories, expected-change baselines, and request-to-host correlation.
· Operational confidence is reduced where endpoint telemetry is incomplete, command-line capture is disabled, container metadata is missing, or managed infrastructure obscures process and file activity.
· Operational confidence is reduced where deployments, package updates, configuration management, service reloads, certificate renewals, or container image updates create frequent file and process changes under NGINX-related paths.
· Full-telemetry confidence improves when host activity is enriched with NGINX access logs, NGINX error logs, WAF logs, NDR telemetry, DNS logs, proxy logs, firewall logs, Kubernetes telemetry, cloud telemetry, identity-provider records, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for probable exploitation or post-exploitation behavior, but confirmed compromise still requires corroborating network, identity, application, cloud, Kubernetes, or validated impact evidence.
Limitations
· This rule detects suspicious host behavior after exploit-path indicators, not the initial exploit request by itself.
· Legitimate deployment automation, package updates, configuration management, certificate renewal, service reloads, container lifecycle activity, and incident-response actions may produce similar process or file behavior.
· Missing endpoint telemetry may prevent confirmation that suspicious behavior occurred under NGINX-related context.
· Containerized deployments may obscure parent-child process lineage, file ownership, mounted-volume context, and workload identity.
· Managed or appliance-based NGINX deployments may not expose sufficient endpoint telemetry.
· The rule may miss attacks that produce denial-of-service only, remain memory-only, avoid file writes, use approved binaries, or operate through expected deployment paths.
· Confirmation requires correlation with request telemetry, NGINX error logs, crash artifacts, outbound communication, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated downstream impact.
Detection Query Pattern
Splunk web-to-host correlation query pattern requiring SPL syntax translation, SPL syntax validation, index validation, sourcetype validation, field extraction validation, endpoint-to-web correlation validation, NGINX asset tagging, process-lineage validation, sensitive-path validation, expected-change baseline validation, timing-window tuning, and environment-specific allowlisting before production deployment.
SplunkEvent AS HostEvent
WHERE HostEvent.index IN ENV_ENDPOINT_AND_HOST_INDEXES
AND HostEvent.EndpointAsset IN LOOKUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Hosts",
"NGINX Backed Ingress Controller Hosts",
"NGINX Backed Gateway Hosts",
"WAF Adjacent NGINX Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
HostEvent.ParentOrAncestorProcess IN LOOKUP(
"NGINX Master Processes",
"NGINX Worker Processes",
"NGINX Plus Processes",
"Ingress Controller Processes",
"Gateway Service Processes",
"Reverse Proxy Service Processes",
"WAF Adjacent NGINX Processes"
)
OR HostEvent.ProcessUser IN LOOKUP(
"NGINX Service Accounts",
"Reverse Proxy Service Accounts",
"Ingress Controller Service Accounts",
"Gateway Service Accounts"
)
)
AND (
HostEvent.ChildProcess IN LOOKUP(
"Shells",
"Script Interpreters",
"Downloaders",
"Network Utilities",
"File Transfer Utilities",
"Package Managers",
"Archive Utilities",
"Discovery Utilities",
"Credential Utilities",
"Permission Modification Utilities",
"Service Control Utilities",
"Persistence Utilities"
)
OR HostEvent.FilePath IN LOOKUP(
"Web Accessible Directories",
"Temporary Directories",
"Writable Application Paths",
"Mounted Volumes",
"NGINX Configuration Paths",
"Reverse Proxy Configuration Paths",
"Ingress Configuration Paths",
"Gateway Configuration Paths",
"Service Unit Paths",
"Startup Paths",
"Cron Paths",
"Credential Material Paths",
"Cloud Credential Paths",
"Kubernetes Mounted Secret Paths",
"Container Writable Layers",
"Monitoring Agent Paths"
)
OR HostEvent.EventType IN ANY (
"suspicious_process_execution",
"suspicious_file_write",
"credential_material_access",
"mounted_secret_access",
"service_modification",
"persistence_activity"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_WEB_TO_HOST_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR HealthEvent.EventType IN ANY (
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND NOT HostEvent.ChangeContext IN ANY (
"approved_deployment_activity",
"approved_configuration_management",
"approved_certificate_renewal",
"approved_certificate_store_update",
"approved_package_managed_nginx_config_write",
"approved_package_managed_module_update",
"approved_package_update",
"approved_nginx_maintenance",
"approved_security_testing",
"approved_incident_response_activity",
"approved_container_image_update",
"approved_service_reload",
"approved_administrative_workflow"
)
Rule
NGINX Exploit-Path Activity Followed by Unusual Egress or Backend Access
Rule Format
Splunk multi-source network-correlation rule suitable for NGINX access logs, NGINX error logs, DNS logs, proxy logs, firewall logs, NetFlow where available, cloud flow logs where available, NDR events where available, endpoint network telemetry where available, WAF logs, load balancer logs, ingress logs, asset inventory, approved egress baselines, backend dependency mapping, sensitive-destination mapping, destination enrichment, and SIEM correlation after SPL syntax translation, index validation, sourcetype validation, field extraction validation, dependency-baseline validation, destination-enrichment validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect unusual outbound communication or backend access from NGINX-backed infrastructure after exploit-path request activity, service instability, or suspicious host behavior.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, data transfer, backend probing, internal service discovery, cloud metadata access, Kubernetes API access, identity-system access, or management-interface access.
· Prioritize activity involving rare destinations, newly observed destinations, suspicious destination categories, non-baselined egress, direct IP communication, unusual ports, or sensitive backend access outside documented NGINX dependencies.
· Support investigation of possible post-exploitation communication or internal expansion without assuming that all NGINX egress or backend access is malicious.
· This rule does not prove successful exploitation, command-and-control, lateral movement, credential compromise, cloud compromise, Kubernetes compromise, or data exfiltration without supporting endpoint, identity, application, cloud, Kubernetes, or validated data-flow evidence.
Detection Logic
· Identify outbound or internal network communication from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Prioritize communication occurring after suspicious malformed request activity, rewrite-route request anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, suspicious child-process execution, file activity, credential access, or mounted-secret access.
· Prioritize destinations that are rare for the asset, newly observed, low-reputation, unknown external, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unapproved cloud, direct IP, unusual port, or outside approved NGINX dependency baselines.
· Prioritize internal destinations involving backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, regulated data paths, or sensitive internal services.
· Increase confidence when unusual egress or backend access is initiated by suspicious NGINX-related child processes, service-account context, containerized NGINX workload, ingress-controller workload, or gateway-hosting node.
· Increase confidence when the same destination, domain, ASN, tunnel provider, hosting provider, backend destination, or infrastructure cluster is contacted by multiple NGINX-backed assets after similar exploit-path indicators.
· Increase confidence when traffic includes direct IP communication, unusual TLS SNI, abnormal user agent, unexpected protocol, high byte count, repeated beacon-like timing, abnormal session duration, connection sweeps, service discovery, metadata probing, or access to destinations outside dependency maps.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, backend health checks, monitoring systems, security tooling, deployment automation, administrative workflows, and known operational maintenance.
· Reduce severity when egress or backend access matches documented service mesh traffic, approved backend dependency maps, known health-check behavior, expected observability flows, approved deployment automation, approved incident-response activity, normal application release activity, or validated service-owner workflow.
· Do not classify egress or backend access as confirmed compromise without corroborating exploit-path context, endpoint process lineage, file activity, crash telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application anomalies, or validated data-flow evidence.
· Do not treat outbound communication or internal backend access from NGINX infrastructure as malicious by itself because reverse proxy and ingress tiers routinely communicate with upstream services.
Required Telemetry
· Splunk indexes containing DNS logs.
· Splunk indexes containing proxy logs.
· Splunk indexes containing firewall logs.
· NetFlow or flow telemetry where available.
· Cloud flow logs where available.
· NDR events where available.
· Endpoint network telemetry where available.
· NGINX access logs.
· NGINX error logs.
· WAF logs where available.
· Load balancer logs where available.
· Ingress logs where available.
· Source IP.
· Source asset identity after enrichment validation.
· Source hostname.
· Source workload identity where available.
· Source container identity where available.
· Source node identity where available.
· Source service identity where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Session duration where available.
· Byte count where available.
· Connection count where available.
· TLS SNI where available.
· HTTP host where available.
· User agent where available.
· Destination reputation where available after enrichment validation.
· Destination category where available after enrichment validation.
· Destination ASN where available.
· Destination geolocation where available.
· Destination first-seen timestamp where available after enrichment validation.
· Domain age where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, and service-mesh destinations.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Prior suspicious inbound request context.
· NGINX service instability context.
· Endpoint process correlation where available.
· File telemetry correlation where available.
· Identity-provider correlation where available.
· Kubernetes telemetry where available.
· Cloud-control-plane telemetry where available.
· Change-management, testing, incident-response, service-owner, and maintenance-window context.
Engineering Implementation Instructions
· Build Splunk asset lookups for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy infrastructure, NGINX-backed ingress controllers, NGINX-backed gateway services, WAF-adjacent NGINX services, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build approved destination lookups for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and documented internal services.
· Build sensitive destination lookups for backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Validate indexes and sourcetypes for DNS logs, proxy logs, firewall logs, NetFlow, cloud flow logs, NDR events, endpoint network telemetry, NGINX access logs, NGINX error logs, WAF logs, load balancer logs, ingress logs, and Kubernetes telemetry.
· Validate field extractions for source asset, destination asset, destination domain, destination port, protocol, directionality, byte count, session duration, TLS SNI, HTTP host, user agent, destination reputation, destination category, first-seen destination, workload identity, and service identity.
· Establish known-good egress baselines and backend dependency maps for each NGINX route, virtual host, ingress path, gateway route, upstream application, workload, namespace, node, and service owner.
· Correlate unusual egress or backend access with malformed request activity, rewrite-route anomalies, NGINX error-log artifacts, route-specific degradation, worker instability, service restarts, suspicious host behavior, credential access, mounted-secret access, and file activity.
· Use shorter correlation windows for suspicious request or host activity followed by immediate DNS lookup, direct IP connection, rare destination contact, internal probing, metadata access, or command-line retrieval.
· Use moderate correlation windows for NGINX instability followed by outbound communication, backend access, service discovery, or access to sensitive destinations.
· Use longer correlation windows for delayed callback, delayed expansion, repeated infrastructure reuse, repeated backend access, or repeated activity across multiple NGINX-backed assets.
· Tune severity based on destination novelty, destination reputation, destination category, protocol, port, byte count, session duration, source asset criticality, route sensitivity, dependency deviation, sensitive-destination access, prior exploit-path context, service-owner context, and change-management status.
· Validate all lookups, dependency baselines, field extractions, timing windows, expected-change controls, macro behavior, data model acceleration assumptions, and local parser behavior before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to unusual egress or backend access after NGINX exploit-path indicators rather than generic outbound traffic or static exploit indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, data transfer, backend probing, metadata access, Kubernetes access, or internal service discovery.
· The score is supported by durable source asset role, destination novelty, dependency deviation, sensitive destination identity, timing, prior exploit-path context, and correlation with process, file, crash, identity, Kubernetes, cloud, or application telemetry.
· The score is constrained by normal NGINX upstream communication, broad cloud and SaaS usage, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, and incomplete process-to-network attribution.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on egress visibility, east-west visibility, DNS visibility, proxy visibility, destination enrichment, asset tagging, workload identity, dependency baselines, sensitive-destination mapping, and prior exploit-path context.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX hosts, workloads, containers, nodes, or service identities.
· Operational confidence is reduced where NGINX infrastructure routinely communicates with broad upstream services, cloud platforms, SaaS services, update repositories, monitoring platforms, internal APIs, and management endpoints without stable baselines.
· Full-telemetry confidence improves when network events are enriched with NGINX access logs, NGINX error logs, EDR process lineage, file telemetry, crash telemetry, WAF events, NDR telemetry, identity-provider events, Kubernetes telemetry, cloud-control-plane logs, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for possible post-exploitation communication or internal expansion, but confirmed compromise still requires corroborating endpoint, identity, application, Kubernetes, cloud, file, or validated data-flow evidence.
Limitations
· This rule detects unusual egress or backend access after exploit-path indicators, not successful exploitation by itself.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, and internal services.
· NAT, service mesh, proxy chaining, cloud networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· Destination reputation may be incomplete or misleading for newly created, compromised, shared, or legitimate cloud-hosted infrastructure.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common cloud providers, or communicate through permitted service dependencies.
· Confirmation requires correlation with endpoint process lineage, file activity, credential access, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated data movement.
Detection Query Pattern
Splunk network-correlation query pattern requiring SPL syntax translation, SPL syntax validation, index validation, sourcetype validation, field extraction validation, NGINX asset tagging, approved-egress validation, backend dependency validation, sensitive-destination mapping, destination-enrichment validation, exploit-path context validation, timing-window tuning, and environment-specific allowlisting before production deployment.
SplunkEvent AS NetworkEvent
WHERE NetworkEvent.index IN ENV_NETWORK_AND_FLOW_INDEXES
AND NetworkEvent.SourceAsset IN LOOKUP(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND NetworkEvent.Direction IN ANY (
"Outbound",
"Internal",
"East West",
"Outbound To Private Network"
)
AND (
NetworkEvent.DestinationFirstSeen WITHIN ENV_NEW_DESTINATION_WINDOW
OR NetworkEvent.DestinationDomainAge <= ENV_NEW_DOMAIN_AGE_WINDOW
OR NetworkEvent.DestinationReputation IN ANY (
"high_risk",
"suspicious",
"rare",
"newly_observed",
"unknown"
)
OR NetworkEvent.DestinationCategory IN ANY (
"temporary_hosting",
"paste_service",
"file_sharing",
"tunneling",
"dynamic_dns",
"unapproved_cloud_storage",
"unknown_external",
"infrastructure_like"
)
OR NetworkEvent.DestinationAsset IN LOOKUP(
"Backend Applications",
"Internal APIs",
"Databases",
"Identity Services",
"Kubernetes API Servers",
"Cloud Metadata Endpoints",
"Secrets Managers",
"CI CD Systems",
"Artifact Repositories",
"Management Interfaces",
"Administrative Services",
"Regulated Data Paths",
"Sensitive Internal Services"
)
OR NetworkEvent.DestinationPort NOT IN ENV_APPROVED_NGINX_EGRESS_PORTS
OR NetworkEvent.ByteCount >= ENV_NGINX_NETWORK_VOLUME_THRESHOLD
OR NetworkEvent.SessionPattern IN ANY (
"beacon_like",
"unusual_duration",
"repeated_rare_destination",
"direct_ip_connection",
"unusual_tls_sni",
"connection_sweep",
"service_discovery_pattern",
"metadata_access_pattern"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_NETWORK_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR HostEvent.EventType IN ANY (
"Suspicious Child Process From NGINX Lineage",
"Suspicious File Activity From NGINX Context",
"Credential Material Access From NGINX Context",
"Mounted Secret Access From NGINX Context"
)
)
AND NetworkEvent.DestinationIP NOT IN LOOKUP(
"Approved Upstream Application Destinations",
"Approved Observability Destinations",
"Approved Log Forwarding Destinations",
"Approved Package Repository Destinations",
"Approved Update Repository Destinations",
"Approved Corporate Proxy Destinations",
"Approved Security Tool Destinations",
"Approved Monitoring Destinations",
"Approved Service Mesh Destinations",
"Approved Management Destinations"
)
AND NOT NetworkEvent.DestinationAsset IN DEPENDENCY_MAP(
NetworkEvent.SourceAsset,
"Approved NGINX Upstream Dependencies"
)
AND NOT ChangeContext IN ANY (
"approved_patch_activity",
"approved_service_maintenance",
"approved_nginx_reload",
"approved_package_update",
"approved_monitoring_activity",
"approved_security_testing",
"approved_incident_response_activity",
"approved_deployment_activity",
"approved_backend_health_check",
"approved_service_mesh_activity",
"approved_observability_flow",
"approved_application_release"
)
Elastic
Detection Viability Assessment
Elastic has three rules for this EXP report.
· Elastic is viable for detecting NGINX Rift exploit-path activity where Elastic can correlate web telemetry, NGINX error logs, Elastic Defend endpoint telemetry, network telemetry, DNS telemetry, proxy telemetry, cloud logs, Kubernetes telemetry, asset inventory, route context, vulnerability-management context, and change-management context.
· Elastic is strongest where ECS field normalization, data-stream validation, index-pattern validation, ingest-pipeline validation, endpoint process telemetry, endpoint file-event telemetry, endpoint network telemetry, NGINX asset tagging, exposed-service classification, route mapping, approved scanner allowlists, expected-change baselines, and SIEM correlation can be combined.
· Elastic can identify suspicious sequencing between malformed request activity, rewrite-route targeting, route-specific service degradation, NGINX worker instability, abnormal process execution, suspicious file or configuration activity, unusual outbound communication, and downstream backend access.
· Elastic is not a standalone source for confirming successful NGINX Rift exploitation unless request telemetry, error-log telemetry, endpoint telemetry, network telemetry, and asset context are available and correlated.
· Elastic rules should be treated as high-value behavioral coverage for exploit-attempt detection, probable exploitation, post-exploitation activity, and downstream exposure assessment, not as proof of compromise from a single log source.
· Elastic detections must be validated against local indices, data streams, ECS mappings, ingest pipelines, field availability, timestamp normalization, asset enrichment, route mapping, scanner allowlists, dependency baselines, expected-change baselines, and deployment workflows before production alerting.
Rule
Suspicious NGINX Rewrite-Path Request Activity With Optional Service-Instability Correlation
Rule Format
Elastic correlation rule suitable for NGINX access logs, NGINX error logs, Elastic Agent integrations, Elastic Defend telemetry where available, WAF telemetry, CDN telemetry, load balancer telemetry, ingress telemetry, gateway logs, infrastructure health logs, asset inventory, vulnerability-management context, route mapping, scanner allowlists, and SIEM correlation after EQL or KQL syntax translation, Elastic rule syntax validation, ECS mapping validation, index-pattern validation, data-stream validation, ingest-pipeline validation, field extraction validation, route-context validation, timestamp normalization, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious malformed HTTP or HTTPS request activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure.
· Identify possible exploit probing, malformed request delivery, rewrite-path manipulation, route-specific request variation, or exploit-path adaptation against exposed NGINX-backed services.
· Prioritize suspicious request behavior that is strengthened by NGINX worker instability, segmentation fault indicators, abnormal worker exits, restart loops, route-specific 500-series spikes, upstream reset behavior, gateway failures, or backend degradation.
· Support early identification of attempted exploitation and likely denial-of-service outcomes without relying on a single exploit string, static request fragment, vulnerable-version exposure alone, or direct inspection of worker memory state.
· This rule does not prove successful exploitation, code execution, host compromise, credential compromise, or data exposure without supporting endpoint, file, network, identity, application, Kubernetes, cloud, or validated downstream evidence.
Detection Logic
· Identify inbound HTTP or HTTPS activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, or NGINX-backed application infrastructure.
· Prioritize request activity involving excessive URI length, repeated encoding, double encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, unusual route variation, capture-like route structures, uncommon methods, malformed headers, suspicious query structure, or request normalization failure.
· Prioritize requests against rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, legacy application paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream application routes.
· Increase confidence when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, NGINX reload failures, service restarts, container restarts, pod restarts, or route-specific service degradation.
· Increase confidence when suspicious request activity is followed by elevated 500-series responses, upstream reset spikes, gateway errors, backend failures, abnormal request timing, or health-check degradation.
· Increase confidence when similar request patterns are observed across multiple exposed NGINX-backed services, virtual hosts, ingress paths, gateway routes, or reverse proxy tiers within a short time window.
· Increase confidence when affected assets are internet-facing, unpatched, rewrite-heavy, WAF-adjacent, ingress-facing, gateway-facing, business-critical, or fronting authentication, API, payment, administrative, identity, or customer-facing services.
· Reduce severity for approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, sanctioned security testing, and known benign scanner activity when behavior is consistent with source, route, asset, and time window.
· Do not classify suspicious request activity as confirmed compromise without corroborating endpoint process activity, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated impact evidence.
· Do not treat NGINX presence, internet exposure, vulnerable-version context, malformed requests, route-specific errors, or worker instability as compromise evidence by itself.
Required Telemetry
· Elastic indices or data streams containing NGINX access logs.
· Elastic indices or data streams containing NGINX error logs.
· WAF logs where available.
· CDN logs where available.
· Load balancer logs where available.
· Gateway logs where available.
· Ingress controller logs where available.
· Infrastructure health logs where available.
· Container restart or pod restart telemetry where available.
· Source IP.
· Source ASN where available.
· Source geolocation where available.
· Source reputation where available after enrichment validation.
· Destination IP.
· Destination hostname.
· Destination virtual host.
· Destination service identity after ECS mapping validation.
· Destination asset identity after enrichment validation.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Request method where available.
· Raw URI where available.
· Normalized URI where available.
· Query string where available.
· HTTP host where available.
· TLS SNI where available.
· User agent where available.
· Response code where available.
· Upstream response code where available after ECS mapping validation.
· Request duration where available.
· Upstream response time where available after ECS mapping validation.
· Request size or URI length where available.
· NGINX worker crash indicators where available after error-log parsing validation.
· NGINX segmentation fault indicators where available after error-log parsing validation.
· NGINX abnormal worker exit indicators where available after error-log parsing validation.
· Route or application mapping where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Rewrite-heavy route inventory where available.
· Patch status where available.
· Vulnerability-management context where available.
· Approved scanner inventory.
· Approved testing source inventory.
· Change-management, patch-validation, maintenance, and incident-response context.
Engineering Implementation Instructions
· Build Elastic asset enrichments for internet-facing NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy infrastructure, NGINX-backed ingress controllers, NGINX-backed gateway services, WAF-adjacent NGINX services, customer-facing NGINX-backed applications, and high-value NGINX-backed exposed infrastructure.
· Build route enrichments for rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway routes, legacy application paths, administrative portals, customer-facing virtual hosts, and high-dependency upstream application paths.
· Validate local indices, data streams, and index patterns for NGINX access logs, NGINX error logs, WAF logs, load balancer logs, gateway logs, ingress logs, CDN logs, infrastructure health logs, container telemetry, and Kubernetes telemetry.
· Validate ECS mappings and ingest-pipeline output for source IP, destination asset, virtual host, URI, normalized URI, query string, response code, upstream response code, request timing, upstream timing, user agent, TLS SNI, error message, worker process ID, and service identity.
· Normalize timestamps across web logs, NGINX error logs, WAF logs, load balancer logs, infrastructure health logs, endpoint telemetry, and cloud or container telemetry.
· Use request-shape analytics rather than a single exploit string, public demonstration artifact, or static request fragment.
· Add source clustering by IP, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent family, request shape, route target, and time window.
· Add route-level service-impact correlation for 500-series spikes, upstream resets, gateway errors, backend failures, NGINX worker crashes, abnormal worker exits, service restarts, container restarts, pod restarts, and health-check degradation.
· Treat response degradation and crash evidence as confidence-increasing signals rather than the only detection path.
· Add affected-asset enrichment for NGINX version, NGINX Plus status, patch state, rewrite exposure, exposed service role, business criticality, WAF-adjacent status, ingress status, gateway status, and hosted application sensitivity.
· Use shorter correlation windows for suspicious malformed requests followed by immediate worker instability, route degradation, upstream resets, gateway failures, or service degradation.
· Use moderate correlation windows for repeated route probing, distributed source clustering, repeated request-shape reuse, or activity across multiple NGINX-backed services.
· Use longer correlation windows for delayed exploitation validation, repeated infrastructure reuse, and retroactive hunting after amendment-relevant exploit-path changes.
· Tune severity based on exposed-service criticality, rewrite exposure, request abnormality, source reputation, source clustering, route sensitivity, response impact, scanner status, patch state, and correlated instability.
· Validate scanner allowlists, testing allowlists, synthetic-monitoring allowlists, health-check sources, change-management records, and incident-response context before production deployment.
· Validate final EQL or KQL syntax, Elastic rule type, runtime fields, enrich policies, index patterns, data-stream coverage, rule execution performance, and local alert-volume impact before enabling scheduled alerting.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious request activity against exposed NGINX-backed infrastructure with optional service-instability correlation rather than static exploit strings, vulnerable-version exposure, or NGINX presence alone.
· The rule remains useful if the initial exploit-path request changes but activity still involves rewrite-route targeting, abnormal request shape, source clustering, route-specific errors, or worker instability.
· The score is supported by the durability of NGINX access logs, NGINX error logs, response-code behavior, route context, source clustering, asset enrichment, and worker instability artifacts.
· The score is constrained by TLS visibility gaps, proxy and WAF normalization, incomplete URI preservation, missing route mapping, scanner noise, incomplete NGINX error-log parsing, and uneven ECS normalization across edge layers.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on NGINX access-log fidelity, NGINX error-log fidelity, ECS mapping quality, timestamp normalization, source IP preservation, route mapping, scanner allowlists, and affected-service enrichment.
· Operational confidence is reduced where CDN, WAF, load balancer, ingress, gateway, or reverse proxy layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Operational confidence is reduced where internet-facing services receive high volumes of scanner traffic, fuzzing, malformed crawler traffic, synthetic monitoring, authorized validation, or health-check activity.
· Full-telemetry confidence improves when request anomalies are enriched with NGINX error logs, WAF telemetry, load balancer telemetry, ingress telemetry, NDR events, endpoint telemetry, crash artifacts, patch context, rewrite-route context, and change-management records.
· Under full telemetry conditions, this rule provides strong escalation evidence for attempted exploitation or likely denial-of-service impact, but confirmed compromise still requires corroborating endpoint, file, network, identity, application, Kubernetes, cloud, or validated impact evidence.
Limitations
· This rule detects suspicious request activity and optional service-instability correlation, not successful code execution by itself.
· NGINX worker crashes, 500-series spikes, gateway failures, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, misconfiguration, package updates, or maintenance.
· CDN, WAF, load balancer, ingress, gateway, or proxy normalization may obscure original request shape.
· Raw URI and normalized URI may be unavailable, truncated, or inconsistently parsed.
· Approved scanners, emergency validation, penetration testing, synthetic monitoring, uptime monitoring, CDN health checks, and load balancer probes may produce similar request and error artifacts.
· Missing rewrite-route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· Confirmation requires correlation with endpoint process lineage, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated data movement.
Detection Query Pattern
Elastic correlation query pattern requiring EQL or KQL syntax translation, Elastic rule syntax validation, index-pattern validation, data-stream validation, ECS field mapping validation, NGINX asset tagging, rewrite-route context validation, request-field validation, error-log parsing validation, scanner allowlist validation, timing-window tuning, and environment-specific allowlisting before production deployment.
ElasticEvent AS InboundRequest
WHERE InboundRequest.index IN ENV_NGINX_WEB_INDICES
AND InboundRequest.data_stream.dataset IN ENV_NGINX_ACCESS_DATASETS
AND InboundRequest.DestinationAsset IN ENRICHMENT(
"Internet Facing NGINX Servers",
"Internet Facing NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"NGINX Backed Customer Facing Applications",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
InboundRequest.RequestPath IN ENRICHMENT(
"Rewrite Heavy Routes",
"Authentication Paths",
"API Paths",
"Ingress Paths",
"Gateway Routes",
"Legacy Application Paths",
"Administrative Portals",
"Customer Facing Virtual Hosts"
)
OR InboundRequest.DestinationAsset.Exposure = "internet_facing"
)
AND (
InboundRequest.UriLength >= ENV_NGINX_URI_LENGTH_ANOMALY_THRESHOLD
OR InboundRequest.EncodedCharacterCount >= ENV_NGINX_ENCODING_DENSITY_THRESHOLD
OR InboundRequest.DelimiterDensity >= ENV_NGINX_DELIMITER_DENSITY_THRESHOLD
OR InboundRequest.PathExpansionScore >= ENV_NGINX_PATH_EXPANSION_THRESHOLD
OR InboundRequest.RequestNormalizationResult IN ANY (
"failed",
"ambiguous",
"rewritten",
"truncated",
"malformed"
)
OR InboundRequest.Method NOT IN ENV_APPROVED_METHODS_FOR_ROUTE
OR InboundRequest.HeaderAnomalyScore >= ENV_HEADER_ANOMALY_THRESHOLD
)
AND (
InboundRequest.SourceReputation IN ANY (
"high_risk",
"suspicious",
"scanner",
"unknown",
"newly_observed"
)
OR InboundRequest.SourceASN IN WATCHLIST(
"Scanner Infrastructure",
"Bulletproof Hosting",
"Unusual Cloud Hosting",
"Known Exploit Infrastructure"
)
OR COUNT_SIMILAR_EVENTS(
InboundRequest.SourceIP,
InboundRequest.RequestShape,
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_REQUEST_CLUSTER_THRESHOLD
OR COUNT_DISTINCT_DESTINATIONS(
InboundRequest.SourceIP,
"NGINX Backed Assets",
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_MULTI_ASSET_PROBE_THRESHOLD
)
AND OPTIONAL_CONFIDENCE_INCREASE WITHIN ENV_NGINX_REQUEST_IMPACT_WINDOW (
ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR WebEvent.EventType IN ANY (
"Route Specific 500 Spike",
"Upstream Reset Spike",
"Gateway Failure Spike",
"Backend Failure Spike",
"NGINX Backed Service Degradation"
)
OR HealthEvent.EventType IN ANY (
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND InboundRequest.SourceIP NOT IN ENRICHMENT(
"Approved Vulnerability Scanners",
"Approved Security Testing Sources",
"Approved Emergency Validation Sources",
"Approved Synthetic Monitoring Sources",
"Approved Uptime Monitoring Sources",
"Approved CDN Health Check Sources",
"Approved Load Balancer Probe Sources"
)
AND NOT ChangeContext IN ANY (
"approved_patch_validation",
"approved_penetration_test",
"approved_incident_response_activity",
"approved_qa_testing",
"approved_synthetic_monitoring",
"approved_load_balancer_health_check",
"approved_nginx_maintenance"
)
Rule
NGINX Exploit-Path Activity Followed by Suspicious Process, File, or Service Behavior
Rule Format
Elastic multi-source correlation rule suitable for NGINX access logs, NGINX error logs, Elastic Defend process telemetry where available, Linux audit telemetry where available, endpoint file-event telemetry where enabled, service manager logs where available, container runtime logs where available, Kubernetes telemetry where available, asset inventory, route context, service-account mapping, change-management context, and SIEM correlation after EQL or KQL syntax translation, Elastic rule syntax validation, index-pattern validation, data-stream validation, ECS field mapping validation, endpoint-to-web correlation validation, process-lineage validation, path mapping, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious process, file, configuration, credential, or service behavior on NGINX-backed infrastructure after exploit-path request activity or NGINX instability.
· Identify possible probable exploitation or post-exploitation behavior involving unexpected child processes, temporary execution, file staging, configuration modification, credential-material access, mounted-secret access, service modification, or persistence activity.
· Prioritize host and workload behavior occurring after suspicious request activity, route-specific errors, NGINX worker instability, segmentation fault indicators, service restarts, container restarts, or pod restarts.
· Support investigation of probable compromise without assuming that every service restart, child process, or file change on NGINX infrastructure is malicious.
· This rule does not prove successful exploitation, persistence, credential compromise, lateral movement, or data exfiltration without supporting endpoint, network, identity, Kubernetes, cloud, application, or validated data-flow evidence.
Detection Logic
· Identify suspicious process, file, configuration, credential, or service behavior on NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Prioritize child-process execution from NGINX master processes, NGINX worker processes, ingress-controller processes, gateway service processes, reverse proxy processes, WAF-adjacent NGINX processes, or related service-account context.
· Prioritize file activity involving web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration paths, reverse proxy configuration paths, ingress configuration paths, gateway configuration paths, service-unit paths, startup paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, or monitoring-agent paths.
· Increase confidence when process or file activity follows suspicious request activity, rewrite-route request anomalies, route-specific 500-series spikes, upstream reset behavior, gateway failures, NGINX worker crash indicators, segmentation fault indicators, container restarts, pod restarts, or service degradation.
· Increase confidence when suspicious process behavior includes shell execution, interpreter execution, downloader use, file-transfer utility use, archive utility use, package-manager execution, discovery utility use, credential utility use, service-control utility use, encoded command execution, remote retrieval, temporary-directory execution, or writable-path execution.
· Increase confidence when file activity includes staged payloads, shell scripts, ELF binaries, encoded content, archive files, downloaded tools, web-accessible artifacts, modified service units, new startup entries, credential access, mounted-secret access, or configuration changes inconsistent with approved deployment workflows.
· Increase confidence when endpoint behavior is followed by unusual outbound communication, internal service probing, identity anomalies, Kubernetes activity, cloud activity, or downstream application anomalies.
· Reduce severity when activity matches approved deployment automation, package-managed NGINX configuration writes, package-managed module updates, certificate-renewal writes, certificate-store updates, service reloads, container image updates, configuration management, security testing, incident-response workflows, or known administrative maintenance.
· Do not classify endpoint behavior as confirmed compromise without corroborating exploit-path context, request telemetry, crash evidence, network telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application telemetry, or validated downstream impact.
· Do not treat NGINX service restarts, child-process creation, file writes, package updates, configuration changes, or certificate activity as malicious by itself.
Required Telemetry
· Elastic indices or data streams containing NGINX access logs.
· Elastic indices or data streams containing NGINX error logs.
· Elastic Defend process telemetry where available.
· Linux audit telemetry where available.
· Service manager logs where available.
· Endpoint file-event telemetry where enabled.
· Container runtime logs where available.
· Kubernetes telemetry where available.
· Endpoint hostname.
· Endpoint asset ID.
· Endpoint role.
· Endpoint exposure context.
· Parent process name after ECS mapping validation.
· Parent process path after ECS mapping validation.
· Ancestor process chain where available.
· Child process name after ECS mapping validation.
· Child process path after ECS mapping validation.
· Command-line telemetry where enabled.
· Process user.
· Service-account context after ECS mapping validation.
· Working directory where available.
· File path after ECS mapping validation.
· File name where available.
· File hash where available.
· File operation after ECS mapping validation.
· File sensitivity where available after enrichment validation.
· NGINX service restart context.
· NGINX worker crash context where available after error-log parsing validation.
· NGINX segmentation fault context where available after error-log parsing validation.
· Container restart context where available.
· Pod restart context where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Sensitive path inventory.
· Expected-change baselines.
· Change-management, deployment, certificate-renewal, package-management, testing, and incident-response context.
Engineering Implementation Instructions
· Build Elastic asset enrichments for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy hosts, NGINX-backed ingress-controller hosts, NGINX-backed gateway hosts, WAF-adjacent NGINX hosts, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build process enrichments for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, reverse proxy service processes, WAF-adjacent NGINX processes, suspicious child processes, shells, interpreters, downloaders, file-transfer tools, network utilities, package managers, credential utilities, service-control utilities, and persistence utilities.
· Build sensitive path enrichments for web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration directories, reverse proxy configuration directories, ingress configuration paths, gateway configuration paths, service-unit paths, startup locations, cron paths, SSH material paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, and monitoring-agent paths.
· Build expected-change enrichments for approved deployment activity, configuration management, package-managed NGINX configuration writes, package-managed module updates, certificate renewal, certificate-store updates, package updates, container image updates, service reloads, security testing, incident-response activity, and administrative maintenance.
· Validate indices, data streams, and index patterns for web telemetry, error logs, process telemetry, file telemetry, service logs, container logs, Kubernetes logs, and vulnerability context.
· Validate ECS mappings for process name, parent process, command line, process user, file path, file operation, service account, container identity, workload identity, host identity, route context, error-log context, and timestamp.
· Correlate suspicious host activity with NGINX exploit-path indicators, including malformed request activity, rewrite-route anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, container restarts, pod restarts, and NGINX error-log artifacts.
· Use shorter correlation windows for worker instability or suspicious request activity followed by shell, interpreter, downloader, network utility, file-transfer utility, credential utility, or suspicious file activity.
· Use moderate correlation windows for NGINX instability followed by configuration modification, credential access, mounted-secret access, service modification, file staging, or outbound communication.
· Use longer correlation windows for delayed payload staging, recurring file changes, repeated process behavior, or recurring activity across multiple NGINX-backed assets.
· Tune severity based on process lineage, command-line risk, file path sensitivity, service-account context, asset exposure, route sensitivity, business criticality, change-management status, expected-change context, and correlated network or identity activity.
· Validate all enrichments, ECS mappings, timing windows, expected-change controls, rule execution behavior, event-correlation behavior, and local parser behavior before production deployment.
DRI Assessment
DRI
9.0 / 10
· The rule is behaviorally anchored to suspicious host activity after NGINX exploit-path indicators rather than static exploit strings or vulnerable-version exposure.
· The rule remains useful if the initial exploit request changes but successful exploitation still results in abnormal child-process execution, file staging, credential access, service modification, or persistence behavior.
· The score is supported by durable process lineage, file path sensitivity, service-account context, error-log correlation, request-to-host sequencing, asset role, and expected-change controls.
· The score is constrained by missing endpoint telemetry, incomplete command-line capture, limited file telemetry, container abstraction, managed infrastructure, process lineage truncation, legitimate deployment activity, and uneven ECS normalization.
TCR Assessment
Operational TCR
8.0 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on process telemetry fidelity, file telemetry fidelity, NGINX error-log parsing, endpoint asset tagging, service-account mapping, sensitive path inventories, expected-change baselines, and request-to-host correlation.
· Operational confidence is reduced where endpoint telemetry is incomplete, command-line capture is disabled, container metadata is missing, or managed infrastructure obscures process and file activity.
· Operational confidence is reduced where deployments, package updates, configuration management, service reloads, certificate renewals, or container image updates create frequent file and process changes under NGINX-related paths.
· Full-telemetry confidence improves when host activity is enriched with NGINX access logs, NGINX error logs, WAF logs, NDR telemetry, DNS logs, proxy logs, firewall logs, Kubernetes telemetry, cloud telemetry, identity-provider records, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for probable exploitation or post-exploitation behavior, but confirmed compromise still requires corroborating network, identity, application, cloud, Kubernetes, or validated impact evidence.
Limitations
· This rule detects suspicious host behavior after exploit-path indicators, not the initial exploit request by itself.
· Legitimate deployment automation, package updates, configuration management, certificate renewal, service reloads, container lifecycle activity, and incident-response actions may produce similar process or file behavior.
· Missing endpoint telemetry may prevent confirmation that suspicious behavior occurred under NGINX-related context.
· Containerized deployments may obscure parent-child process lineage, file ownership, mounted-volume context, and workload identity.
· Managed or appliance-based NGINX deployments may not expose sufficient endpoint telemetry.
· The rule may miss attacks that produce denial-of-service only, remain memory-only, avoid file writes, use approved binaries, or operate through expected deployment paths.
· Confirmation requires correlation with request telemetry, NGINX error logs, crash artifacts, outbound communication, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated downstream impact.
Detection Query Pattern
Elastic web-to-host correlation query pattern requiring EQL or KQL syntax translation, Elastic rule syntax validation, index-pattern validation, data-stream validation, ECS field mapping validation, endpoint-to-web correlation validation, NGINX asset tagging, process-lineage validation, sensitive-path validation, expected-change baseline validation, timing-window tuning, and environment-specific allowlisting before production deployment.
ElasticEvent AS HostEvent
WHERE HostEvent.index IN ENV_ENDPOINT_AND_HOST_INDICES
AND HostEvent.EndpointAsset IN ENRICHMENT(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Hosts",
"NGINX Backed Ingress Controller Hosts",
"NGINX Backed Gateway Hosts",
"WAF Adjacent NGINX Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
HostEvent.ParentOrAncestorProcess IN ENRICHMENT(
"NGINX Master Processes",
"NGINX Worker Processes",
"NGINX Plus Processes",
"Ingress Controller Processes",
"Gateway Service Processes",
"Reverse Proxy Service Processes",
"WAF Adjacent NGINX Processes"
)
OR HostEvent.ProcessUser IN ENRICHMENT(
"NGINX Service Accounts",
"Reverse Proxy Service Accounts",
"Ingress Controller Service Accounts",
"Gateway Service Accounts"
)
)
AND (
HostEvent.ChildProcess IN ENRICHMENT(
"Shells",
"Script Interpreters",
"Downloaders",
"Network Utilities",
"File Transfer Utilities",
"Package Managers",
"Archive Utilities",
"Discovery Utilities",
"Credential Utilities",
"Permission Modification Utilities",
"Service Control Utilities",
"Persistence Utilities"
)
OR HostEvent.FilePath IN ENRICHMENT(
"Web Accessible Directories",
"Temporary Directories",
"Writable Application Paths",
"Mounted Volumes",
"NGINX Configuration Paths",
"Reverse Proxy Configuration Paths",
"Ingress Configuration Paths",
"Gateway Configuration Paths",
"Service Unit Paths",
"Startup Paths",
"Cron Paths",
"Credential Material Paths",
"Cloud Credential Paths",
"Kubernetes Mounted Secret Paths",
"Container Writable Layers",
"Monitoring Agent Paths"
)
OR HostEvent.EventType IN ANY (
"suspicious_process_execution",
"suspicious_file_write",
"credential_material_access",
"mounted_secret_access",
"service_modification",
"persistence_activity"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_WEB_TO_HOST_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR HealthEvent.EventType IN ANY (
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND NOT HostEvent.ChangeContext IN ANY (
"approved_deployment_activity",
"approved_configuration_management",
"approved_certificate_renewal",
"approved_certificate_store_update",
"approved_package_managed_nginx_config_write",
"approved_package_managed_module_update",
"approved_package_update",
"approved_nginx_maintenance",
"approved_security_testing",
"approved_incident_response_activity",
"approved_container_image_update",
"approved_service_reload",
"approved_administrative_workflow"
)
Rule
NGINX Exploit-Path Activity Followed by Unusual Egress or Backend Access
Rule Format
Elastic multi-source network-correlation rule suitable for NGINX access logs, NGINX error logs, DNS logs, proxy logs, firewall logs, network flow telemetry where available, cloud flow logs where available, NDR events where available, endpoint network telemetry where available, WAF logs, load balancer logs, ingress logs, asset inventory, approved egress baselines, backend dependency mapping, sensitive-destination mapping, destination enrichment, and SIEM correlation after EQL or KQL syntax translation, Elastic rule syntax validation, index-pattern validation, data-stream validation, ECS field mapping validation, dependency-baseline validation, destination-enrichment validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect unusual outbound communication or backend access from NGINX-backed infrastructure after exploit-path request activity, service instability, or suspicious host behavior.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, data transfer, backend probing, internal service discovery, cloud metadata access, Kubernetes API access, identity-system access, or management-interface access.
· Prioritize activity involving rare destinations, newly observed destinations, suspicious destination categories, non-baselined egress, direct IP communication, unusual ports, or sensitive backend access outside documented NGINX dependencies.
· Support investigation of possible post-exploitation communication or internal expansion without assuming that all NGINX egress or backend access is malicious.
· This rule does not prove successful exploitation, command-and-control, lateral movement, credential compromise, cloud compromise, Kubernetes compromise, or data exfiltration without supporting endpoint, identity, application, cloud, Kubernetes, or validated data-flow evidence.
Detection Logic
· Identify outbound or internal network communication from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Prioritize communication occurring after suspicious malformed request activity, rewrite-route request anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, suspicious child-process execution, file activity, credential access, or mounted-secret access.
· Prioritize destinations that are rare for the asset, newly observed, low-reputation, unknown external, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unapproved cloud, direct IP, unusual port, or outside approved NGINX dependency baselines.
· Prioritize internal destinations involving backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, regulated data paths, or sensitive internal services.
· Increase confidence when unusual egress or backend access is initiated by suspicious NGINX-related child processes, service-account context, containerized NGINX workload, ingress-controller workload, or gateway-hosting node.
· Increase confidence when the same destination, domain, ASN, tunnel provider, hosting provider, backend destination, or infrastructure cluster is contacted by multiple NGINX-backed assets after similar exploit-path indicators.
· Increase confidence when traffic includes direct IP communication, unusual TLS SNI, abnormal user agent, unexpected protocol, high byte count, repeated beacon-like timing, abnormal session duration, connection sweeps, service discovery, metadata probing, or access to destinations outside dependency maps.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, backend health checks, monitoring systems, security tooling, deployment automation, administrative workflows, and known operational maintenance.
· Reduce severity when egress or backend access matches documented service mesh traffic, approved backend dependency maps, known health-check behavior, expected observability flows, approved deployment automation, approved incident-response activity, normal application release activity, or validated service-owner workflow.
· Do not classify egress or backend access as confirmed compromise without corroborating exploit-path context, endpoint process lineage, file activity, crash telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application anomalies, or validated data-flow evidence.
· Do not treat outbound communication or internal backend access from NGINX infrastructure as malicious by itself because reverse proxy and ingress tiers routinely communicate with upstream services.
Required Telemetry
· Elastic indices or data streams containing DNS logs.
· Elastic indices or data streams containing proxy logs.
· Elastic indices or data streams containing firewall logs.
· Network flow telemetry where available.
· Cloud flow logs where available.
· NDR events where available.
· Endpoint network telemetry where available.
· NGINX access logs.
· NGINX error logs.
· WAF logs where available.
· Load balancer logs where available.
· Ingress logs where available.
· Source IP.
· Source asset identity after enrichment validation.
· Source hostname.
· Source workload identity where available.
· Source container identity where available.
· Source node identity where available.
· Source service identity where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Timestamp.
· Session duration where available.
· Byte count where available.
· Connection count where available.
· TLS SNI where available.
· HTTP host where available.
· User agent where available.
· Destination reputation where available after enrichment validation.
· Destination category where available after enrichment validation.
· Destination ASN where available.
· Destination geolocation where available.
· Destination first-seen timestamp where available after enrichment validation.
· Domain age where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, and service-mesh destinations.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Prior suspicious inbound request context.
· NGINX service instability context.
· Endpoint process correlation where available.
· File telemetry correlation where available.
· Identity-provider correlation where available.
· Kubernetes telemetry where available.
· Cloud-control-plane telemetry where available.
· Change-management, testing, incident-response, service-owner, and maintenance-window context.
Engineering Implementation Instructions
· Build Elastic asset enrichments for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy infrastructure, NGINX-backed ingress controllers, NGINX-backed gateway services, WAF-adjacent NGINX services, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build approved destination enrichments for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and documented internal services.
· Build sensitive destination enrichments for backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Validate indices, data streams, and index patterns for DNS logs, proxy logs, firewall logs, network flow telemetry, cloud flow logs, NDR events, endpoint network telemetry, NGINX access logs, NGINX error logs, WAF logs, load balancer logs, ingress logs, and Kubernetes telemetry.
· Validate ECS mappings for source asset, destination asset, destination domain, destination port, protocol, directionality, byte count, session duration, TLS SNI, HTTP host, user agent, destination reputation, destination category, first-seen destination, workload identity, and service identity.
· Establish known-good egress baselines and backend dependency maps for each NGINX route, virtual host, ingress path, gateway route, upstream application, workload, namespace, node, and service owner.
· Correlate unusual egress or backend access with malformed request activity, rewrite-route anomalies, NGINX error-log artifacts, route-specific degradation, worker instability, service restarts, suspicious host behavior, credential access, mounted-secret access, and file activity.
· Use shorter correlation windows for suspicious request or host activity followed by immediate DNS lookup, direct IP connection, rare destination contact, internal probing, metadata access, or command-line retrieval.
· Use moderate correlation windows for NGINX instability followed by outbound communication, backend access, service discovery, or access to sensitive destinations.
· Use longer correlation windows for delayed callback, delayed expansion, repeated infrastructure reuse, repeated backend access, or repeated activity across multiple NGINX-backed assets.
· Tune severity based on destination novelty, destination reputation, destination category, protocol, port, byte count, session duration, source asset criticality, route sensitivity, dependency deviation, sensitive-destination access, prior exploit-path context, service-owner context, and change-management status.
· Validate all enrichments, dependency baselines, ECS mappings, timing windows, expected-change controls, rule execution behavior, event-correlation behavior, and local parser behavior before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to unusual egress or backend access after NGINX exploit-path indicators rather than generic outbound traffic or static exploit indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, data transfer, backend probing, metadata access, Kubernetes access, or internal service discovery.
· The score is supported by durable source asset role, destination novelty, dependency deviation, sensitive destination identity, timing, prior exploit-path context, and correlation with process, file, crash, identity, Kubernetes, cloud, or application telemetry.
· The score is constrained by normal NGINX upstream communication, broad cloud and SaaS usage, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, and incomplete process-to-network attribution.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on egress visibility, east-west visibility, DNS visibility, proxy visibility, destination enrichment, asset tagging, workload identity, dependency baselines, sensitive-destination mapping, and prior exploit-path context.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX hosts, workloads, containers, nodes, or service identities.
· Operational confidence is reduced where NGINX infrastructure routinely communicates with broad upstream services, cloud platforms, SaaS services, update repositories, monitoring platforms, internal APIs, and management endpoints without stable baselines.
· Full-telemetry confidence improves when network events are enriched with NGINX access logs, NGINX error logs, EDR process lineage, file telemetry, crash telemetry, WAF events, NDR telemetry, identity-provider events, Kubernetes telemetry, cloud-control-plane logs, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for possible post-exploitation communication or internal expansion, but confirmed compromise still requires corroborating endpoint, identity, application, Kubernetes, cloud, file, or validated data-flow evidence.
Limitations
· This rule detects unusual egress or backend access after exploit-path indicators, not successful exploitation by itself.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, and internal services.
· NAT, service mesh, proxy chaining, cloud networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· Destination reputation may be incomplete or misleading for newly created, compromised, shared, or legitimate cloud-hosted infrastructure.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common cloud providers, or communicate through permitted service dependencies.
· Confirmation requires correlation with endpoint process lineage, file activity, credential access, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated data movement.
Detection Query Pattern
Elastic network-correlation query pattern requiring EQL or KQL syntax translation, Elastic rule syntax validation, index-pattern validation, data-stream validation, ECS field mapping validation, NGINX asset tagging, approved-egress validation, backend dependency validation, sensitive-destination mapping, destination-enrichment validation, exploit-path context validation, timing-window tuning, and environment-specific allowlisting before production deployment.
ElasticEvent AS NetworkEvent
WHERE NetworkEvent.index IN ENV_NETWORK_AND_FLOW_INDICES
AND NetworkEvent.SourceAsset IN ENRICHMENT(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND NetworkEvent.Direction IN ANY (
"Outbound",
"Internal",
"East West",
"Outbound To Private Network"
)
AND (
NetworkEvent.DestinationFirstSeen WITHIN ENV_NEW_DESTINATION_WINDOW
OR NetworkEvent.DestinationDomainAge <= ENV_NEW_DOMAIN_AGE_WINDOW
OR NetworkEvent.DestinationReputation IN ANY (
"high_risk",
"suspicious",
"rare",
"newly_observed",
"unknown"
)
OR NetworkEvent.DestinationCategory IN ANY (
"temporary_hosting",
"paste_service",
"file_sharing",
"tunneling",
"dynamic_dns",
"unapproved_cloud_storage",
"unknown_external",
"infrastructure_like"
)
OR NetworkEvent.DestinationAsset IN ENRICHMENT(
"Backend Applications",
"Internal APIs",
"Databases",
"Identity Services",
"Kubernetes API Servers",
"Cloud Metadata Endpoints",
"Secrets Managers",
"CI CD Systems",
"Artifact Repositories",
"Management Interfaces",
"Administrative Services",
"Regulated Data Paths",
"Sensitive Internal Services"
)
OR NetworkEvent.DestinationPort NOT IN ENV_APPROVED_NGINX_EGRESS_PORTS
OR NetworkEvent.ByteCount >= ENV_NGINX_NETWORK_VOLUME_THRESHOLD
OR NetworkEvent.SessionPattern IN ANY (
"beacon_like",
"unusual_duration",
"repeated_rare_destination",
"direct_ip_connection",
"unusual_tls_sni",
"connection_sweep",
"service_discovery_pattern",
"metadata_access_pattern"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_NETWORK_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR HostEvent.EventType IN ANY (
"Suspicious Child Process From NGINX Lineage",
"Suspicious File Activity From NGINX Context",
"Credential Material Access From NGINX Context",
"Mounted Secret Access From NGINX Context"
)
)
AND NetworkEvent.DestinationIP NOT IN ENRICHMENT(
"Approved Upstream Application Destinations",
"Approved Observability Destinations",
"Approved Log Forwarding Destinations",
"Approved Package Repository Destinations",
"Approved Update Repository Destinations",
"Approved Corporate Proxy Destinations",
"Approved Security Tool Destinations",
"Approved Monitoring Destinations",
"Approved Service Mesh Destinations",
"Approved Management Destinations"
)
AND NOT NetworkEvent.DestinationAsset IN DEPENDENCY_MAP(
NetworkEvent.SourceAsset,
"Approved NGINX Upstream Dependencies"
)
AND NOT ChangeContext IN ANY (
"approved_patch_activity",
"approved_service_maintenance",
"approved_nginx_reload",
"approved_package_update",
"approved_monitoring_activity",
"approved_security_testing",
"approved_incident_response_activity",
"approved_deployment_activity",
"approved_backend_health_check",
"approved_service_mesh_activity",
"approved_observability_flow",
"approved_application_release"
)
QRadar
Detection Viability Assessment
QRadar has three rules for this EXP report.
· QRadar is viable for detecting NGINX Rift exploit-path activity where QRadar can correlate web telemetry, NGINX access logs, NGINX error logs, WAF events, load balancer events, ingress telemetry, endpoint events, DNS events, proxy events, firewall events, flow records, cloud flow logs, Kubernetes events, vulnerability-management context, asset inventory, route context, reference sets, building blocks, and change-management context.
· QRadar is strongest where DSM parsing, custom property extraction, log source validation, flow-source validation, asset enrichment, exposed-service classification, route mapping, scanner allowlists, approved-destination reference sets, expected-change reference sets, event-to-flow correlation, and SIEM offense tuning can be combined.
· QRadar can identify suspicious sequencing between malformed request activity, rewrite-route targeting, route-specific service degradation, NGINX worker instability, suspicious process or file behavior, unusual outbound communication, and downstream backend access.
· QRadar is not a standalone source for confirming successful NGINX Rift exploitation unless request telemetry, error-log telemetry, endpoint telemetry, flow telemetry, asset context, and change-management context are available and correlated.
· QRadar rules should be treated as high-value behavioral coverage for exploit-attempt detection, probable exploitation, post-exploitation activity, and downstream exposure assessment, not as proof of compromise from a single event source or flow source.
· QRadar detections must be validated against local log sources, DSM mappings, custom properties, QID mappings, flow fields, reference sets, building blocks, offense rules, asset profiles, timing windows, dependency baselines, expected-change baselines, and SOC triage procedures before production alerting.
Rule
Suspicious NGINX Rewrite-Path Request Activity With Optional Service-Instability Correlation
Rule Format
QRadar correlation rule suitable for NGINX access logs, NGINX error logs, WAF events, CDN events, load balancer events, ingress telemetry, gateway logs, infrastructure health events, asset inventory, vulnerability-management context, route mapping, scanner reference sets, and SIEM correlation after AQL translation, QRadar rule syntax validation, DSM validation, custom property validation, QID mapping validation, log source validation, route-context validation, timestamp normalization, timing-window tuning, offense-rule tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious malformed HTTP or HTTPS request activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure.
· Identify possible exploit probing, malformed request delivery, rewrite-path manipulation, route-specific request variation, or exploit-path adaptation against exposed NGINX-backed services.
· Prioritize suspicious request behavior that is strengthened by NGINX worker instability, segmentation fault indicators, abnormal worker exits, restart loops, route-specific 500-series spikes, upstream reset behavior, gateway failures, or backend degradation.
· Support early identification of attempted exploitation and likely denial-of-service outcomes without relying on a single exploit string, static request fragment, vulnerable-version exposure alone, or direct inspection of worker memory state.
· This rule does not prove successful exploitation, code execution, host compromise, credential compromise, or data exposure without supporting endpoint, file, flow, identity, application, Kubernetes, cloud, or validated downstream evidence.
Detection Logic
· Identify inbound HTTP or HTTPS activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, or NGINX-backed application infrastructure.
· Prioritize request activity involving excessive URI length, repeated encoding, double encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, unusual route variation, capture-like route structures, uncommon methods, malformed headers, suspicious query structure, or request normalization failure.
· Prioritize requests against rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, legacy application paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream application routes.
· Increase confidence when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, NGINX reload failures, service restarts, container restarts, pod restarts, or route-specific service degradation.
· Increase confidence when suspicious request activity is followed by elevated 500-series responses, upstream reset spikes, gateway errors, backend failures, abnormal request timing, or health-check degradation.
· Increase confidence when similar request patterns are observed across multiple exposed NGINX-backed services, virtual hosts, ingress paths, gateway routes, or reverse proxy tiers within a short time window.
· Increase confidence when affected assets are internet-facing, unpatched, rewrite-heavy, WAF-adjacent, ingress-facing, gateway-facing, business-critical, or fronting authentication, API, payment, administrative, identity, or customer-facing services.
· Reduce severity for approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, sanctioned security testing, and known benign scanner activity when behavior is consistent with source, route, asset, and time window.
· Do not classify suspicious request activity as confirmed compromise without corroborating endpoint process activity, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated impact evidence.
· Do not treat NGINX presence, internet exposure, vulnerable-version context, malformed requests, route-specific errors, or worker instability as compromise evidence by itself.
Required Telemetry
· QRadar log sources containing NGINX access logs.
· QRadar log sources containing NGINX error logs.
· WAF events where available.
· CDN events where available.
· Load balancer events where available.
· Gateway events where available.
· Ingress controller events where available.
· Infrastructure health events where available.
· Container restart or pod restart events where available.
· Source IP.
· Source ASN where available.
· Source geolocation where available.
· Source reputation where available after enrichment validation.
· Destination IP.
· Destination hostname.
· Destination virtual host.
· Destination service identity after custom property validation.
· Destination asset identity after asset-profile validation.
· Destination port.
· Protocol.
· Directionality.
· Event timestamp.
· Request method where available.
· Raw URI where available.
· Normalized URI where available.
· Query string where available.
· HTTP host where available.
· TLS SNI where available.
· User agent where available.
· Response code where available.
· Upstream response code where available after custom property validation.
· Request duration where available.
· Upstream response time where available after custom property validation.
· Request size or URI length where available.
· NGINX worker crash indicators where available after error-log parsing validation.
· NGINX segmentation fault indicators where available after error-log parsing validation.
· NGINX abnormal worker exit indicators where available after error-log parsing validation.
· Route or application mapping where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Rewrite-heavy route inventory where available.
· Patch status where available.
· Vulnerability-management context where available.
· Approved scanner reference sets.
· Approved testing source reference sets.
· Change-management, patch-validation, maintenance, and incident-response context.
Engineering Implementation Instructions
· Build QRadar reference sets for internet-facing NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy infrastructure, NGINX-backed ingress controllers, NGINX-backed gateway services, WAF-adjacent NGINX services, customer-facing NGINX-backed applications, and high-value NGINX-backed exposed infrastructure.
· Build route reference sets for rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway routes, legacy application paths, administrative portals, customer-facing virtual hosts, and high-dependency upstream application paths.
· Validate QRadar log sources and DSM parsing for NGINX access logs, NGINX error logs, WAF events, load balancer events, gateway events, ingress events, CDN events, infrastructure health events, container telemetry, and Kubernetes telemetry.
· Validate custom properties for source IP, destination asset, virtual host, URI, normalized URI, query string, response code, upstream response code, request timing, upstream timing, user agent, TLS SNI, error message, worker process ID, and service identity.
· Normalize timestamps across web logs, NGINX error logs, WAF events, load balancer events, infrastructure health events, endpoint events, and cloud or container events.
· Use request-shape analytics rather than a single exploit string, public demonstration artifact, or static request fragment.
· Add source clustering by IP, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent family, request shape, route target, and time window.
· Add route-level service-impact correlation for 500-series spikes, upstream resets, gateway errors, backend failures, NGINX worker crashes, abnormal worker exits, service restarts, container restarts, pod restarts, and health-check degradation.
· Treat response degradation and crash evidence as confidence-increasing signals rather than the only detection path.
· Add affected-asset enrichment for NGINX version, NGINX Plus status, patch state, rewrite exposure, exposed service role, business criticality, WAF-adjacent status, ingress status, gateway status, and hosted application sensitivity.
· Use shorter correlation windows for suspicious malformed requests followed by immediate worker instability, route degradation, upstream resets, gateway failures, or service degradation.
· Use moderate correlation windows for repeated route probing, distributed source clustering, repeated request-shape reuse, or activity across multiple NGINX-backed services.
· Use longer correlation windows for delayed exploitation validation, repeated infrastructure reuse, and retroactive hunting after amendment-relevant exploit-path changes.
· Tune offense magnitude based on exposed-service criticality, rewrite exposure, request abnormality, source reputation, source clustering, route sensitivity, response impact, scanner status, patch state, and correlated instability.
· Validate scanner allowlists, testing allowlists, synthetic-monitoring allowlists, health-check sources, change-management records, and incident-response context before production deployment.
· Validate final QRadar rule logic, AQL translation, reference-set names, custom property availability, building-block behavior, offense aggregation, and local performance impact before enabling production alerting.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious request activity against exposed NGINX-backed infrastructure with optional service-instability correlation rather than static exploit strings, vulnerable-version exposure, or NGINX presence alone.
· The rule remains useful if the initial exploit-path request changes but activity still involves rewrite-route targeting, abnormal request shape, source clustering, route-specific errors, or worker instability.
· The score is supported by the durability of NGINX access logs, NGINX error logs, response-code behavior, route context, source clustering, asset enrichment, and worker instability artifacts.
· The score is constrained by TLS visibility gaps, proxy and WAF normalization, incomplete URI preservation, missing route mapping, scanner noise, incomplete NGINX error-log parsing, and uneven DSM or custom-property normalization across edge layers.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on NGINX access-log fidelity, NGINX error-log fidelity, DSM parsing quality, custom property extraction, timestamp normalization, source IP preservation, route mapping, scanner allowlists, and affected-service enrichment.
· Operational confidence is reduced where CDN, WAF, load balancer, ingress, gateway, or reverse proxy layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Operational confidence is reduced where internet-facing services receive high volumes of scanner traffic, fuzzing, malformed crawler traffic, synthetic monitoring, authorized validation, or health-check activity.
· Full-telemetry confidence improves when request anomalies are enriched with NGINX error logs, WAF events, load balancer events, ingress telemetry, NDR events, endpoint telemetry, crash artifacts, patch context, rewrite-route context, and change-management records.
· Under full telemetry conditions, this rule provides strong escalation evidence for attempted exploitation or likely denial-of-service impact, but confirmed compromise still requires corroborating endpoint, file, flow, identity, application, Kubernetes, cloud, or validated impact evidence.
Limitations
· This rule detects suspicious request activity and optional service-instability correlation, not successful code execution by itself.
· NGINX worker crashes, 500-series spikes, gateway failures, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, misconfiguration, package updates, or maintenance.
· CDN, WAF, load balancer, ingress, gateway, or proxy normalization may obscure original request shape.
· Raw URI and normalized URI may be unavailable, truncated, or inconsistently parsed.
· Approved scanners, emergency validation, penetration testing, synthetic monitoring, uptime monitoring, CDN health checks, and load balancer probes may produce similar request and error artifacts.
· Missing rewrite-route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· Confirmation requires correlation with endpoint process lineage, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated data movement.
Detection Query Pattern
QRadar correlation query pattern requiring AQL translation, QRadar rule syntax validation, DSM validation, log source validation, custom property validation, QID mapping validation, NGINX asset reference-set validation, rewrite-route context validation, request-field validation, error-log parsing validation, scanner allowlist validation, timing-window tuning, and environment-specific allowlisting before production deployment.
QRadarEvent AS InboundRequest
WHERE InboundRequest.LogSource IN REFERENCE_SET(
"NGINX Access Log Sources"
)
AND InboundRequest.DestinationAsset IN REFERENCE_SET(
"Internet Facing NGINX Servers",
"Internet Facing NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"NGINX Backed Customer Facing Applications",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
InboundRequest.RequestPath IN REFERENCE_SET(
"Rewrite Heavy Routes",
"Authentication Paths",
"API Paths",
"Ingress Paths",
"Gateway Routes",
"Legacy Application Paths",
"Administrative Portals",
"Customer Facing Virtual Hosts"
)
OR InboundRequest.DestinationAsset.Exposure = "internet_facing"
)
AND (
InboundRequest.UriLength >= ENV_NGINX_URI_LENGTH_ANOMALY_THRESHOLD
OR InboundRequest.EncodedCharacterCount >= ENV_NGINX_ENCODING_DENSITY_THRESHOLD
OR InboundRequest.DelimiterDensity >= ENV_NGINX_DELIMITER_DENSITY_THRESHOLD
OR InboundRequest.PathExpansionScore >= ENV_NGINX_PATH_EXPANSION_THRESHOLD
OR InboundRequest.RequestNormalizationResult IN ANY (
"failed",
"ambiguous",
"rewritten",
"truncated",
"malformed"
)
OR InboundRequest.Method NOT IN ENV_APPROVED_METHODS_FOR_ROUTE
OR InboundRequest.HeaderAnomalyScore >= ENV_HEADER_ANOMALY_THRESHOLD
)
AND (
InboundRequest.SourceReputation IN ANY (
"high_risk",
"suspicious",
"scanner",
"unknown",
"newly_observed"
)
OR InboundRequest.SourceASN IN REFERENCE_SET(
"Scanner Infrastructure",
"Bulletproof Hosting",
"Unusual Cloud Hosting",
"Known Exploit Infrastructure"
)
OR COUNT_SIMILAR_EVENTS(
InboundRequest.SourceIP,
InboundRequest.RequestShape,
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_REQUEST_CLUSTER_THRESHOLD
OR COUNT_DISTINCT_DESTINATIONS(
InboundRequest.SourceIP,
"NGINX Backed Assets",
ENV_NGINX_REQUEST_CLUSTER_WINDOW
) >= ENV_NGINX_MULTI_ASSET_PROBE_THRESHOLD
)
AND OPTIONAL_CONFIDENCE_INCREASE WITHIN ENV_NGINX_REQUEST_IMPACT_WINDOW (
ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR WebEvent.EventType IN ANY (
"Route Specific 500 Spike",
"Upstream Reset Spike",
"Gateway Failure Spike",
"Backend Failure Spike",
"NGINX Backed Service Degradation"
)
OR HealthEvent.EventType IN ANY (
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND InboundRequest.SourceIP NOT IN REFERENCE_SET(
"Approved Vulnerability Scanners",
"Approved Security Testing Sources",
"Approved Emergency Validation Sources",
"Approved Synthetic Monitoring Sources",
"Approved Uptime Monitoring Sources",
"Approved CDN Health Check Sources",
"Approved Load Balancer Probe Sources"
)
AND NOT ChangeContext IN ANY (
"approved_patch_validation",
"approved_penetration_test",
"approved_incident_response_activity",
"approved_qa_testing",
"approved_synthetic_monitoring",
"approved_load_balancer_health_check",
"approved_nginx_maintenance"
)
Rule
NGINX Exploit-Path Activity Followed by Suspicious Process, File, or Service Behavior
Rule Format
QRadar multi-source correlation rule suitable for NGINX access logs, NGINX error logs, endpoint process events where available, Linux audit events where available, EDR events where available, file-event telemetry where enabled, service manager events where available, container runtime events where available, Kubernetes events where available, asset inventory, route context, service-account mapping, change-management context, and SIEM correlation after AQL translation, QRadar rule syntax validation, DSM validation, log source validation, custom property validation, endpoint-to-web correlation validation, process-lineage validation, path mapping, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious process, file, configuration, credential, or service behavior on NGINX-backed infrastructure after exploit-path request activity or NGINX instability.
· Identify possible probable exploitation or post-exploitation behavior involving unexpected child processes, temporary execution, file staging, configuration modification, credential-material access, mounted-secret access, service modification, or persistence activity.
· Prioritize host and workload behavior occurring after suspicious request activity, route-specific errors, NGINX worker instability, segmentation fault indicators, service restarts, container restarts, or pod restarts.
· Support investigation of probable compromise without assuming that every service restart, child process, or file change on NGINX infrastructure is malicious.
· This rule does not prove successful exploitation, persistence, credential compromise, lateral movement, or data exfiltration without supporting endpoint, flow, identity, Kubernetes, cloud, application, or validated data-flow evidence.
Detection Logic
· Identify suspicious process, file, configuration, credential, or service behavior on NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Prioritize child-process execution from NGINX master processes, NGINX worker processes, ingress-controller processes, gateway service processes, reverse proxy processes, WAF-adjacent NGINX processes, or related service-account context.
· Prioritize file activity involving web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration paths, reverse proxy configuration paths, ingress configuration paths, gateway configuration paths, service-unit paths, startup paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, or monitoring-agent paths.
· Increase confidence when process or file activity follows suspicious request activity, rewrite-route request anomalies, route-specific 500-series spikes, upstream reset behavior, gateway failures, NGINX worker crash indicators, segmentation fault indicators, container restarts, pod restarts, or service degradation.
· Increase confidence when suspicious process behavior includes shell execution, interpreter execution, downloader use, file-transfer utility use, archive utility use, package-manager execution, discovery utility use, credential utility use, service-control utility use, encoded command execution, remote retrieval, temporary-directory execution, or writable-path execution.
· Increase confidence when file activity includes staged payloads, shell scripts, ELF binaries, encoded content, archive files, downloaded tools, web-accessible artifacts, modified service units, new startup entries, credential access, mounted-secret access, or configuration changes inconsistent with approved deployment workflows.
· Increase confidence when endpoint behavior is followed by unusual outbound communication, internal service probing, identity anomalies, Kubernetes activity, cloud activity, or downstream application anomalies.
· Reduce severity when activity matches approved deployment automation, package-managed NGINX configuration writes, package-managed module updates, certificate-renewal writes, certificate-store updates, service reloads, container image updates, configuration management, security testing, incident-response workflows, or known administrative maintenance.
· Do not classify endpoint behavior as confirmed compromise without corroborating exploit-path context, request telemetry, crash evidence, flow telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application telemetry, or validated downstream impact.
· Do not treat NGINX service restarts, child-process creation, file writes, package updates, configuration changes, or certificate activity as malicious by itself.
Required Telemetry
· QRadar log sources containing NGINX access logs.
· QRadar log sources containing NGINX error logs.
· Endpoint process events where available.
· Linux audit events where available.
· EDR events where available.
· Service manager events where available.
· File-event telemetry where enabled.
· Container runtime events where available.
· Kubernetes events where available.
· Endpoint hostname.
· Endpoint asset ID.
· Endpoint role.
· Endpoint exposure context.
· Parent process name after custom property validation.
· Parent process path after custom property validation.
· Ancestor process chain where available.
· Child process name after custom property validation.
· Child process path after custom property validation.
· Command-line telemetry where enabled.
· Process user.
· Service-account context after custom property validation.
· Working directory where available.
· File path after custom property validation.
· File name where available.
· File hash where available.
· File operation after custom property validation.
· File sensitivity where available after enrichment validation.
· NGINX service restart context.
· NGINX worker crash context where available after error-log parsing validation.
· NGINX segmentation fault context where available after error-log parsing validation.
· Container restart context where available.
· Pod restart context where available.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Internet-facing NGINX-backed asset inventory.
· Sensitive path inventory.
· Expected-change baselines.
· Change-management, deployment, certificate-renewal, package-management, testing, and incident-response context.
Engineering Implementation Instructions
· Build QRadar reference sets for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy hosts, NGINX-backed ingress-controller hosts, NGINX-backed gateway hosts, WAF-adjacent NGINX hosts, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build process reference sets or building blocks for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, reverse proxy service processes, WAF-adjacent NGINX processes, suspicious child processes, shells, interpreters, downloaders, file-transfer tools, network utilities, package managers, credential utilities, service-control utilities, and persistence utilities.
· Build sensitive path reference sets or building blocks for web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration directories, reverse proxy configuration directories, ingress configuration paths, gateway configuration paths, service-unit paths, startup locations, cron paths, SSH material paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, and monitoring-agent paths.
· Build expected-change reference sets for approved deployment activity, configuration management, package-managed NGINX configuration writes, package-managed module updates, certificate renewal, certificate-store updates, package updates, container image updates, service reloads, security testing, incident-response activity, and administrative maintenance.
· Validate QRadar log sources and DSM mappings for web telemetry, error logs, process telemetry, file telemetry, service logs, container logs, Kubernetes logs, and vulnerability context.
· Validate custom properties for process name, parent process, command line, process user, file path, file operation, service account, container identity, workload identity, host identity, route context, error-log context, and timestamp.
· Correlate suspicious host activity with NGINX exploit-path indicators, including malformed request activity, rewrite-route anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, container restarts, pod restarts, and NGINX error-log artifacts.
· Use shorter correlation windows for worker instability or suspicious request activity followed by shell, interpreter, downloader, network utility, file-transfer utility, credential utility, or suspicious file activity.
· Use moderate correlation windows for NGINX instability followed by configuration modification, credential access, mounted-secret access, service modification, file staging, or outbound communication.
· Use longer correlation windows for delayed payload staging, recurring file changes, repeated process behavior, or recurring activity across multiple NGINX-backed assets.
· Tune offense magnitude based on process lineage, command-line risk, file path sensitivity, service-account context, asset exposure, route sensitivity, business criticality, change-management status, expected-change context, and correlated network or identity activity.
· Validate all reference sets, building blocks, custom properties, timing windows, expected-change controls, offense aggregation behavior, event-correlation behavior, and local parser behavior before production deployment.
DRI Assessment
DRI
9.0 / 10
· The rule is behaviorally anchored to suspicious host activity after NGINX exploit-path indicators rather than static exploit strings or vulnerable-version exposure.
· The rule remains useful if the initial exploit request changes but successful exploitation still results in abnormal child-process execution, file staging, credential access, service modification, or persistence behavior.
· The score is supported by durable process lineage, file path sensitivity, service-account context, error-log correlation, request-to-host sequencing, asset role, and expected-change controls.
· The score is constrained by missing endpoint telemetry, incomplete command-line capture, limited file telemetry, container abstraction, managed infrastructure, process lineage truncation, legitimate deployment activity, and uneven DSM or custom-property normalization.
TCR Assessment
Operational TCR
8.0 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on process telemetry fidelity, file telemetry fidelity, NGINX error-log parsing, endpoint asset tagging, service-account mapping, sensitive path inventories, expected-change baselines, and request-to-host correlation.
· Operational confidence is reduced where endpoint telemetry is incomplete, command-line capture is disabled, container metadata is missing, or managed infrastructure obscures process and file activity.
· Operational confidence is reduced where deployments, package updates, configuration management, service reloads, certificate renewals, or container image updates create frequent file and process changes under NGINX-related paths.
· Full-telemetry confidence improves when host activity is enriched with NGINX access logs, NGINX error logs, WAF events, NDR telemetry, DNS events, proxy events, firewall events, Kubernetes telemetry, cloud telemetry, identity-provider records, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for probable exploitation or post-exploitation behavior, but confirmed compromise still requires corroborating network, identity, application, cloud, Kubernetes, or validated impact evidence.
Limitations
· This rule detects suspicious host behavior after exploit-path indicators, not the initial exploit request by itself.
· Legitimate deployment automation, package updates, configuration management, certificate renewal, service reloads, container lifecycle activity, and incident-response actions may produce similar process or file behavior.
· Missing endpoint telemetry may prevent confirmation that suspicious behavior occurred under NGINX-related context.
· Containerized deployments may obscure parent-child process lineage, file ownership, mounted-volume context, and workload identity.
· Managed or appliance-based NGINX deployments may not expose sufficient endpoint telemetry.
· The rule may miss attacks that produce denial-of-service only, remain memory-only, avoid file writes, use approved binaries, or operate through expected deployment paths.
· Confirmation requires correlation with request telemetry, NGINX error logs, crash artifacts, outbound communication, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated downstream impact.
Detection Query Pattern
QRadar web-to-host correlation query pattern requiring AQL translation, QRadar rule syntax validation, DSM validation, log source validation, custom property validation, endpoint-to-web correlation validation, NGINX asset reference-set validation, process-lineage validation, sensitive-path validation, expected-change baseline validation, timing-window tuning, and environment-specific allowlisting before production deployment.
QRadarEvent AS HostEvent
WHERE HostEvent.LogSource IN REFERENCE_SET(
"Endpoint And Host Log Sources"
)
AND HostEvent.EndpointAsset IN REFERENCE_SET(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Hosts",
"NGINX Backed Ingress Controller Hosts",
"NGINX Backed Gateway Hosts",
"WAF Adjacent NGINX Hosts",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND (
HostEvent.ParentOrAncestorProcess IN REFERENCE_SET(
"NGINX Master Processes",
"NGINX Worker Processes",
"NGINX Plus Processes",
"Ingress Controller Processes",
"Gateway Service Processes",
"Reverse Proxy Service Processes",
"WAF Adjacent NGINX Processes"
)
OR HostEvent.ProcessUser IN REFERENCE_SET(
"NGINX Service Accounts",
"Reverse Proxy Service Accounts",
"Ingress Controller Service Accounts",
"Gateway Service Accounts"
)
)
AND (
HostEvent.ChildProcess IN REFERENCE_SET(
"Shells",
"Script Interpreters",
"Downloaders",
"Network Utilities",
"File Transfer Utilities",
"Package Managers",
"Archive Utilities",
"Discovery Utilities",
"Credential Utilities",
"Permission Modification Utilities",
"Service Control Utilities",
"Persistence Utilities"
)
OR HostEvent.FilePath IN REFERENCE_SET(
"Web Accessible Directories",
"Temporary Directories",
"Writable Application Paths",
"Mounted Volumes",
"NGINX Configuration Paths",
"Reverse Proxy Configuration Paths",
"Ingress Configuration Paths",
"Gateway Configuration Paths",
"Service Unit Paths",
"Startup Paths",
"Cron Paths",
"Credential Material Paths",
"Cloud Credential Paths",
"Kubernetes Mounted Secret Paths",
"Container Writable Layers",
"Monitoring Agent Paths"
)
OR HostEvent.EventType IN ANY (
"suspicious_process_execution",
"suspicious_file_write",
"credential_material_access",
"mounted_secret_access",
"service_modification",
"persistence_activity"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_WEB_TO_HOST_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR HealthEvent.EventType IN ANY (
"NGINX Service Restart",
"Ingress Controller Restart",
"Gateway Service Degradation",
"Container Restart",
"Pod Restart"
)
)
AND NOT HostEvent.ChangeContext IN ANY (
"approved_deployment_activity",
"approved_configuration_management",
"approved_certificate_renewal",
"approved_certificate_store_update",
"approved_package_managed_nginx_config_write",
"approved_package_managed_module_update",
"approved_package_update",
"approved_nginx_maintenance",
"approved_security_testing",
"approved_incident_response_activity",
"approved_container_image_update",
"approved_service_reload",
"approved_administrative_workflow"
)
Rule
NGINX Exploit-Path Activity Followed by Unusual Egress or Backend Access
Rule Format
QRadar multi-source event-and-flow correlation rule suitable for NGINX access logs, NGINX error logs, DNS events, proxy events, firewall events, network flow telemetry where available, cloud flow logs where available, NDR events where available, endpoint network telemetry where available, WAF events, load balancer events, ingress events, asset inventory, approved egress baselines, backend dependency mapping, sensitive-destination mapping, destination enrichment, and SIEM correlation after AQL translation, QRadar rule syntax validation, DSM validation, log source validation, flow-source validation, custom property validation, dependency-baseline validation, destination-enrichment validation, timing-window tuning, and environment-specific allowlisting.
Detection Purpose
· Detect unusual outbound communication or backend access from NGINX-backed infrastructure after exploit-path request activity, service instability, or suspicious host behavior.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, data transfer, backend probing, internal service discovery, cloud metadata access, Kubernetes API access, identity-system access, or management-interface access.
· Prioritize activity involving rare destinations, newly observed destinations, suspicious destination categories, non-baselined egress, direct IP communication, unusual ports, or sensitive backend access outside documented NGINX dependencies.
· Support investigation of possible post-exploitation communication or internal expansion without assuming that all NGINX egress or backend access is malicious.
· This rule does not prove successful exploitation, command-and-control, lateral movement, credential compromise, cloud compromise, Kubernetes compromise, or data exfiltration without supporting endpoint, identity, application, cloud, Kubernetes, or validated data-flow evidence.
Detection Logic
· Identify outbound or internal network communication from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Prioritize communication occurring after suspicious malformed request activity, rewrite-route request anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, suspicious child-process execution, file activity, credential access, or mounted-secret access.
· Prioritize destinations that are rare for the asset, newly observed, low-reputation, unknown external, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unapproved cloud, direct IP, unusual port, or outside approved NGINX dependency baselines.
· Prioritize internal destinations involving backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, regulated data paths, or sensitive internal services.
· Increase confidence when unusual egress or backend access is initiated by suspicious NGINX-related child processes, service-account context, containerized NGINX workload, ingress-controller workload, or gateway-hosting node.
· Increase confidence when the same destination, domain, ASN, tunnel provider, hosting provider, backend destination, or infrastructure cluster is contacted by multiple NGINX-backed assets after similar exploit-path indicators.
· Increase confidence when traffic includes direct IP communication, unusual TLS SNI, abnormal user agent, unexpected protocol, high byte count, repeated beacon-like timing, abnormal session duration, connection sweeps, service discovery, metadata probing, or access to destinations outside dependency maps.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, backend health checks, monitoring systems, security tooling, deployment automation, administrative workflows, and known operational maintenance.
· Reduce severity when egress or backend access matches documented service mesh traffic, approved backend dependency maps, known health-check behavior, expected observability flows, approved deployment automation, approved incident-response activity, normal application release activity, or validated service-owner workflow.
· Do not classify egress or backend access as confirmed compromise without corroborating exploit-path context, endpoint process lineage, file activity, crash telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application anomalies, or validated data-flow evidence.
· Do not treat outbound communication or internal backend access from NGINX infrastructure as malicious by itself because reverse proxy and ingress tiers routinely communicate with upstream services.
Required Telemetry
· QRadar log sources containing DNS events.
· QRadar log sources containing proxy events.
· QRadar log sources containing firewall events.
· QRadar flow records where available.
· Cloud flow logs where available.
· NDR events where available.
· Endpoint network telemetry where available.
· NGINX access logs.
· NGINX error logs.
· WAF events where available.
· Load balancer events where available.
· Ingress events where available.
· Source IP.
· Source asset identity after asset-profile validation.
· Source hostname.
· Source workload identity where available.
· Source container identity where available.
· Source node identity where available.
· Source service identity where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Event timestamp.
· Flow start time where available.
· Flow end time where available.
· Session duration where available.
· Byte count where available.
· Connection count where available.
· TLS SNI where available.
· HTTP host where available.
· User agent where available.
· Destination reputation where available after enrichment validation.
· Destination category where available after enrichment validation.
· Destination ASN where available.
· Destination geolocation where available.
· Destination first-seen timestamp where available after enrichment validation.
· Domain age where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, and service-mesh destinations.
· NGINX asset inventory.
· NGINX Plus asset inventory.
· Reverse proxy asset inventory.
· Ingress-controller asset inventory.
· Gateway asset inventory.
· WAF-adjacent service inventory.
· Prior suspicious inbound request context.
· NGINX service instability context.
· Endpoint process correlation where available.
· File telemetry correlation where available.
· Identity-provider correlation where available.
· Kubernetes telemetry where available.
· Cloud-control-plane telemetry where available.
· Change-management, testing, incident-response, service-owner, and maintenance-window context.
Engineering Implementation Instructions
· Build QRadar reference sets for NGINX servers, NGINX Plus servers, NGINX-backed reverse proxy infrastructure, NGINX-backed ingress controllers, NGINX-backed gateway services, WAF-adjacent NGINX services, containerized NGINX workloads, Kubernetes nodes hosting NGINX ingress, and high-value NGINX-backed exposed infrastructure.
· Build approved destination reference sets for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and documented internal services.
· Build sensitive destination reference sets for backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Validate QRadar log sources, flow sources, DSM mappings, custom properties, and QID mappings for DNS events, proxy events, firewall events, network flow telemetry, cloud flow logs, NDR events, endpoint network telemetry, NGINX access logs, NGINX error logs, WAF events, load balancer events, ingress events, and Kubernetes telemetry.
· Validate custom properties for source asset, destination asset, destination domain, destination port, protocol, directionality, byte count, session duration, TLS SNI, HTTP host, user agent, destination reputation, destination category, first-seen destination, workload identity, and service identity.
· Establish known-good egress baselines and backend dependency maps for each NGINX route, virtual host, ingress path, gateway route, upstream application, workload, namespace, node, and service owner.
· Correlate unusual egress or backend access with malformed request activity, rewrite-route anomalies, NGINX error-log artifacts, route-specific degradation, worker instability, service restarts, suspicious host behavior, credential access, mounted-secret access, and file activity.
· Use shorter correlation windows for suspicious request or host activity followed by immediate DNS lookup, direct IP connection, rare destination contact, internal probing, metadata access, or command-line retrieval.
· Use moderate correlation windows for NGINX instability followed by outbound communication, backend access, service discovery, or access to sensitive destinations.
· Use longer correlation windows for delayed callback, delayed expansion, repeated infrastructure reuse, repeated backend access, or repeated activity across multiple NGINX-backed assets.
· Tune offense magnitude based on destination novelty, destination reputation, destination category, protocol, port, byte count, session duration, source asset criticality, route sensitivity, dependency deviation, sensitive-destination access, prior exploit-path context, service-owner context, and change-management status.
· Validate all reference sets, dependency baselines, custom properties, timing windows, expected-change controls, flow-source coverage, offense aggregation behavior, event-correlation behavior, and local parser behavior before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to unusual egress or backend access after NGINX exploit-path indicators rather than generic outbound traffic or static exploit indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, data transfer, backend probing, metadata access, Kubernetes access, or internal service discovery.
· The score is supported by durable source asset role, destination novelty, dependency deviation, sensitive destination identity, timing, prior exploit-path context, and correlation with process, file, crash, identity, Kubernetes, cloud, or application telemetry.
· The score is constrained by normal NGINX upstream communication, broad cloud and SaaS usage, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, incomplete process-to-network attribution, and uneven event-to-flow correlation.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on egress visibility, east-west visibility, DNS visibility, proxy visibility, flow-source coverage, destination enrichment, asset tagging, workload identity, dependency baselines, sensitive-destination mapping, and prior exploit-path context.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX hosts, workloads, containers, nodes, or service identities.
· Operational confidence is reduced where NGINX infrastructure routinely communicates with broad upstream services, cloud platforms, SaaS services, update repositories, monitoring platforms, internal APIs, and management endpoints without stable baselines.
· Full-telemetry confidence improves when network activity is enriched with NGINX access logs, NGINX error logs, EDR process lineage, file telemetry, crash telemetry, WAF events, NDR telemetry, identity-provider events, Kubernetes telemetry, cloud-control-plane logs, application logs, and change-management context.
· Under full telemetry conditions, this rule provides strong escalation evidence for possible post-exploitation communication or internal expansion, but confirmed compromise still requires corroborating endpoint, identity, application, Kubernetes, cloud, file, or validated data-flow evidence.
Limitations
· This rule detects unusual egress or backend access after exploit-path indicators, not successful exploitation by itself.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, and internal services.
· NAT, service mesh, proxy chaining, cloud networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· Destination reputation may be incomplete or misleading for newly created, compromised, shared, or legitimate cloud-hosted infrastructure.
· QRadar flow records may lack the process attribution needed to confirm whether traffic originated from NGINX-related child-process context.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common cloud providers, or communicate through permitted service dependencies.
· Confirmation requires correlation with endpoint process lineage, file activity, credential access, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated data movement.
Detection Query Pattern
QRadar event-and-flow correlation query pattern requiring AQL translation, QRadar rule syntax validation, DSM validation, log source validation, flow-source validation, custom property validation, NGINX asset reference-set validation, approved-egress validation, backend dependency validation, sensitive-destination mapping, destination-enrichment validation, exploit-path context validation, timing-window tuning, and environment-specific allowlisting before production deployment.
QRadarFlow AS NetworkEvent
WHERE NetworkEvent.FlowSource IN REFERENCE_SET(
"Network And Flow Sources"
)
AND NetworkEvent.SourceAsset IN REFERENCE_SET(
"NGINX Servers",
"NGINX Plus Servers",
"NGINX Backed Reverse Proxy Infrastructure",
"NGINX Backed Ingress Controllers",
"NGINX Backed Gateway Services",
"WAF Adjacent NGINX Services",
"Containerized NGINX Workloads",
"Kubernetes Nodes Hosting NGINX Ingress",
"High Value NGINX Backed Exposed Infrastructure"
)
AND NetworkEvent.Direction IN ANY (
"Outbound",
"Internal",
"East West",
"Outbound To Private Network"
)
AND (
NetworkEvent.DestinationFirstSeen WITHIN ENV_NEW_DESTINATION_WINDOW
OR NetworkEvent.DestinationDomainAge <= ENV_NEW_DOMAIN_AGE_WINDOW
OR NetworkEvent.DestinationReputation IN ANY (
"high_risk",
"suspicious",
"rare",
"newly_observed",
"unknown"
)
OR NetworkEvent.DestinationCategory IN ANY (
"temporary_hosting",
"paste_service",
"file_sharing",
"tunneling",
"dynamic_dns",
"unapproved_cloud_storage",
"unknown_external",
"infrastructure_like"
)
OR NetworkEvent.DestinationAsset IN REFERENCE_SET(
"Backend Applications",
"Internal APIs",
"Databases",
"Identity Services",
"Kubernetes API Servers",
"Cloud Metadata Endpoints",
"Secrets Managers",
"CI CD Systems",
"Artifact Repositories",
"Management Interfaces",
"Administrative Services",
"Regulated Data Paths",
"Sensitive Internal Services"
)
OR NetworkEvent.DestinationPort NOT IN ENV_APPROVED_NGINX_EGRESS_PORTS
OR NetworkEvent.ByteCount >= ENV_NGINX_NETWORK_VOLUME_THRESHOLD
OR NetworkEvent.SessionPattern IN ANY (
"beacon_like",
"unusual_duration",
"repeated_rare_destination",
"direct_ip_connection",
"unusual_tls_sni",
"connection_sweep",
"service_discovery_pattern",
"metadata_access_pattern"
)
)
AND EVENT_NEAR WITHIN ENV_NGINX_NETWORK_CORRELATION_WINDOW (
WebEvent.EventType IN ANY (
"Malformed Request To NGINX Backed Asset",
"Suspicious Request Shape Against Rewrite Route",
"Repeated Encoded Request Against NGINX Route",
"Request Normalization Failure",
"Malformed Request Pattern Against Rewrite Enabled Route",
"Route Specific 500 Spike",
"NGINX Backed Service Degradation"
)
OR ErrorLogEvent.EventType IN ANY (
"NGINX Worker Crash Indicator",
"NGINX Segmentation Fault Indicator",
"NGINX Abnormal Worker Exit",
"NGINX Reload Failure"
)
OR HostEvent.EventType IN ANY (
"Suspicious Child Process From NGINX Lineage",
"Suspicious File Activity From NGINX Context",
"Credential Material Access From NGINX Context",
"Mounted Secret Access From NGINX Context"
)
)
AND NetworkEvent.DestinationIP NOT IN REFERENCE_SET(
"Approved Upstream Application Destinations",
"Approved Observability Destinations",
"Approved Log Forwarding Destinations",
"Approved Package Repository Destinations",
"Approved Update Repository Destinations",
"Approved Corporate Proxy Destinations",
"Approved Security Tool Destinations",
"Approved Monitoring Destinations",
"Approved Service Mesh Destinations",
"Approved Management Destinations"
)
AND NOT NetworkEvent.DestinationAsset IN DEPENDENCY_MAP(
NetworkEvent.SourceAsset,
"Approved NGINX Upstream Dependencies"
)
AND NOT ChangeContext IN ANY (
"approved_patch_activity",
"approved_service_maintenance",
"approved_nginx_reload",
"approved_package_update",
"approved_monitoring_activity",
"approved_security_testing",
"approved_incident_response_activity",
"approved_deployment_activity",
"approved_backend_health_check",
"approved_service_mesh_activity",
"approved_observability_flow",
"approved_application_release"
)
SIGMA
Detection Viability Assessment
SIGMA has three rules for this EXP report.
· SIGMA is viable as a portable detection-rule format for this report because the core behavior can be expressed through NGINX access logs, NGINX error logs, endpoint process creation, parent-child process lineage, command-line telemetry, file telemetry, network telemetry, and correlated SIEM context.
· SIGMA is strongest where NGINX access logs, NGINX error logs, webserver telemetry, process creation telemetry, full command-line capture, file telemetry, host identity, source and destination enrichment, route context, and SIEM normalization are available.
· SIGMA can provide portable behavioral patterns for suspicious NGINX rewrite-path request activity, NGINX exploit-path activity followed by suspicious child-process execution, and NGINX exploit-path activity followed by unusual egress or backend access.
· SIGMA is suitable for this behavior model because the strongest detection logic is behavior-led and can be translated across SIEM, EDR, NDR, and cloud-native platforms after environment-specific field mapping.
· SIGMA rules should not depend on public proof-of-concept payloads, exact exploit strings, exploit labels, vulnerable-version exposure alone, internet exposure alone, or NGINX presence alone.
· SIGMA detection content should be treated as portable detection logic that requires backend-specific conversion, field mapping, route validation, asset enrichment, correlation support validation, and environment tuning before production deployment.
· The second and third SIGMA rules should be implemented as correlation patterns when the target backend supports multi-event correlation. If the backend does not support that correlation natively, they should be implemented as paired SIGMA rules plus SIEM-level correlation logic.
Rule
Suspicious NGINX Rewrite-Path Request Activity Against Exposed NGINX-Backed Infrastructure
Rule Format
SIGMA behavioral webserver rule suitable for NGINX access logs, NGINX error logs, WAF telemetry, load balancer telemetry, ingress telemetry, gateway telemetry, route mapping, exposed-asset tagging, scanner allowlisting, source-risk enrichment, service-instability enrichment, and SIEM conversion after NGINX log-source validation, field mapping, rewrite-route validation, exposed-service mapping, error-log parsing validation, timing-window support validation, and environment-specific allowlisting.
Detection Purpose
· Detect suspicious malformed HTTP or HTTPS request activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure.
· Identify possible exploit probing, malformed request delivery, rewrite-path manipulation, route-specific request variation, request-shape fuzzing, or exploit-path adaptation against exposed NGINX-backed services.
· Prioritize request activity involving abnormal URI length, repeated encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, uncommon methods, request-normalization failures, or suspicious query structure.
· Increase confidence when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, reload failures, route-specific 500-series spikes, upstream reset spikes, gateway failures, or NGINX-backed service degradation.
· Support portable behavior-led detection without relying on proof-of-concept syntax, static exploit strings, vulnerable-version exposure alone, or NGINX presence alone.
· This rule does not prove successful exploitation by itself; confirmation requires correlation with endpoint process activity, file activity, crash artifacts, outbound network behavior, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated downstream impact evidence.
Detection Logic
· Identify inbound request activity targeting exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, or NGINX-backed application infrastructure.
· Detect request-shape anomalies involving excessive URI length, repeated encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, suspicious query structure, uncommon methods, ambiguous request parsing, or request-normalization failure.
· Prioritize requests against rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway routes, administrative portals, customer-facing virtual hosts, and high-dependency upstream application routes.
· Increase confidence when the source is newly observed, scanner-like, high-risk, unusual for the protected service, associated with suspicious hosting, or clustered across multiple exposed NGINX-backed services.
· Increase confidence when correlated NGINX error logs show worker crashes, segmentation fault indicators, abnormal worker exits, reload failures, route-specific 500-series spikes, upstream reset spikes, gateway failures, or NGINX-backed service degradation.
· Increase confidence when similar request-shape activity appears across multiple exposed NGINX-backed services, virtual hosts, ingress paths, gateway routes, or reverse proxy tiers within a short time window.
· Reduce severity for approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, sanctioned security testing, and known benign scanner activity.
· Do not classify suspicious request activity as confirmed compromise without corroborating endpoint process activity, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated impact evidence.
· Do not treat NGINX presence, internet exposure, vulnerable-version context, malformed requests, route-specific errors, or worker instability as compromise evidence by itself.
Required Telemetry
· NGINX access logs.
· NGINX error logs.
· WAF events where available.
· CDN events where available.
· Load balancer events where available.
· Gateway events where available.
· Ingress controller events where available.
· Infrastructure health events where available.
· Container restart or pod restart events where available.
· Source IP.
· Source ASN where available.
· Source geolocation where available.
· Source reputation where available after enrichment validation.
· Destination IP.
· Destination hostname.
· Destination virtual host.
· Destination service identity after field mapping validation.
· Destination asset identity after enrichment validation.
· Destination port.
· Protocol.
· Directionality.
· Event timestamp.
· Request method where available.
· Raw URI where available.
· Normalized URI where available.
· Query string where available.
· HTTP host where available.
· TLS SNI where available.
· User agent where available.
· Response code where available.
· Upstream response code where available after field mapping validation.
· Request duration where available.
· Upstream response time where available after field mapping validation.
· Request size or URI length where available.
· NGINX worker crash indicators where available after error-log parsing validation.
· NGINX segmentation fault indicators where available after error-log parsing validation.
· NGINX abnormal worker exit indicators where available after error-log parsing validation.
· Route or application mapping where available.
· Internet-facing NGINX-backed asset inventory.
· Rewrite-heavy route inventory where available.
· Patch status where available.
· Vulnerability-management context where available.
· Approved scanner allowlists.
· Approved testing source allowlists.
· Change-management, patch-validation, maintenance, and incident-response context.
Engineering Implementation Instructions
· Convert the SIGMA rule into the target SIEM, WAF analytics, or webserver detection backend only after validating supported fields and log-source mappings.
· Normalize NGINX access-log, NGINX error-log, WAF, load balancer, ingress, gateway, CDN, infrastructure health, container, and Kubernetes telemetry into the target backend.
· Build exposed-asset mappings for internet-facing NGINX servers, NGINX Plus servers, NGINX-backed reverse proxies, NGINX-backed ingress controllers, NGINX-backed gateways, WAF-adjacent NGINX services, and customer-facing NGINX-backed applications.
· Build route mappings for rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway routes, administrative portals, customer-facing virtual hosts, and high-dependency upstream application paths.
· Build source allowlists for approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, load balancer probes, CDN health checks, sanctioned security testing, and known benign scanner activity.
· Validate field mappings for URI, normalized URI, request method, source IP, destination host, virtual host, response code, upstream response code, request duration, upstream response time, user agent, TLS SNI, and error-log event reason.
· Treat source-risk and service-instability signals as confidence-increasing components unless the local backend intentionally converts them into stricter high-confidence variants.
· Use shorter correlation windows for request-shape anomalies followed by immediate worker instability, 500-series spikes, upstream resets, gateway errors, or service degradation.
· Use moderate correlation windows for repeated source activity, multi-route probing, route-specific degradation, or clustered scanning across multiple exposed services.
· Avoid broad suppression for scanners, CDNs, cloud providers, load balancers, or security tools without validation because attacker infrastructure and legitimate traffic may overlap.
· Validate converted query syntax, case sensitivity, backend wildcard handling, regex support, route enrichment, scanner allowlists, timing-window behavior, and environment-specific exceptions before production deployment.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to suspicious request-shape activity against exposed NGINX-backed infrastructure rather than static exploit strings, vulnerable-version exposure, or NGINX presence alone.
· The rule remains useful if the initial exploit-path request changes but activity still involves abnormal request shape, rewrite-route targeting, source clustering, request-normalization failure, route-specific errors, or worker instability.
· The score is supported by portable webserver logic, route context, request-shape analytics, source-risk enrichment, response-code behavior, NGINX error-log artifacts, and service-instability correlation.
· The score is constrained by backend-specific field availability, inconsistent URI preservation, proxy or WAF normalization, incomplete error-log parsing, limited SIGMA-native correlation support, and required backend translation.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on successful SIGMA conversion, NGINX access-log fidelity, NGINX error-log fidelity, URI preservation, route mapping, exposed-asset tagging, scanner allowlists, and timestamp normalization.
· Operational confidence is reduced where CDN, WAF, load balancer, ingress, gateway, or reverse proxy layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Operational confidence is reduced where the target backend cannot support sequence correlation, source clustering, custom URI-shape scoring, optional confidence-increase logic, or route-context lookups.
· Full-telemetry confidence improves when translated rules are enriched with NGINX error logs, WAF events, load balancer telemetry, ingress telemetry, NDR events, endpoint telemetry, crash artifacts, patch context, route context, and change-management records.
· Under full telemetry conditions, this rule provides strong portable coverage for attempted exploitation or likely denial-of-service impact, but confirmed compromise still requires corroborating endpoint, file, network, identity, application, Kubernetes, cloud, or validated impact evidence.
Limitations
· This rule detects suspicious request-shape activity against exposed NGINX-backed infrastructure, not successful exploitation by itself.
· SIGMA conversion quality varies by SIEM, schema, log source, and backend query language.
· NGINX worker crashes, 500-series spikes, gateway failures, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, misconfiguration, package updates, or maintenance.
· CDN, WAF, load balancer, ingress, gateway, or proxy normalization may obscure original request shape.
· Raw URI and normalized URI may be unavailable, truncated, or inconsistently parsed.
· Missing rewrite-route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· The rule may miss attacks that use low-noise request patterns, common scanner infrastructure, approved sources, or backend-specific request transformations.
· Confirmation requires correlation with endpoint process lineage, file activity, outbound communication, credential access, identity anomalies, Kubernetes activity, cloud activity, downstream application anomalies, or validated data movement.
Detection Query Pattern
SIGMA webserver request-shape pattern requiring backend conversion, field mapping validation, platform syntax validation, exposed NGINX asset mapping, rewrite-route validation, scanner allowlisting, source-risk enrichment, service-instability correlation support, and environment-specific allowlisting before production deployment.
title: Suspicious NGINX Rewrite Path Request Activity Against Exposed NGINX Backed Infrastructure
id: ENV-SIGMA-NGINX-RIFT-REWRITE-PATH-REQUEST-ACTIVITY
status: experimental
description: Detects suspicious request-shape activity against exposed NGINX-backed infrastructure with optional source-risk and service-instability confidence components.
logsource:
category: webserver
product: nginx
detection:
selection_nginx_exposed_asset:
DestinationAssetCategory|contains:
- internet_facing_nginx
- nginx_reverse_proxy
- nginx_ingress
- nginx_gateway
- waf_adjacent_nginx
selection_rewrite_or_sensitive_route:
UrlPath|contains:
- rewrite_heavy_route
- authentication_path
- api_path
- ingress_path
- gateway_route
- administrative_portal
- customer_facing_virtual_host
selection_request_shape_path:
UrlOriginal|re:
- ENV_ABNORMAL_URI_LENGTH_OR_EXPANSION_PATTERN
- ENV_REPEATED_ENCODING_PATTERN
- ENV_ABNORMAL_DELIMITER_DENSITY_PATTERN
- ENV_MALFORMED_PATH_STRUCTURE_PATTERN
selection_request_shape_method:
HttpRequestMethod:
- ENV_UNCOMMON_METHOD_FOR_ROUTE
selection_request_shape_reason:
EventReason:
- request_normalization_failed
- malformed_request
- ambiguous_request
confidence_source_risk:
SourceRisk|contains:
- high_risk_source
- scanner_source
- newly_observed_source
- unusual_cloud_hosting
- known_exploit_infrastructure
confidence_service_instability:
EventAction|contains:
- nginx_worker_crash
- nginx_segmentation_fault
- nginx_abnormal_worker_exit
- nginx_reload_failure
- route_specific_500_spike
- upstream_reset_spike
- gateway_failure_spike
- nginx_backed_service_degradation
filter_approved_sources:
SourceContext|contains:
- approved_vulnerability_scanner
- approved_security_testing_source
- approved_synthetic_monitoring_source
- approved_load_balancer_probe_source
- approved_cdn_health_check_source
- approved_patch_validation_source
condition: selection_nginx_exposed_asset and selection_rewrite_or_sensitive_route and 1 of selection_request_shape_* and not filter_approved_sources
fields:
· UtcTime
· SourceIp
· SourceRisk
· DestinationIp
· DestinationHost
· DestinationAssetCategory
· UrlOriginal
· UrlPath
· HttpRequestMethod
· HttpResponseStatusCode
· UserAgent
· EventReason
· EventAction
falsepositives:
· Approved vulnerability scanning
· Approved emergency patch validation
· QA testing
· Synthetic monitoring
· Load balancer health checks
· CDN health checks
· Approved security testing
level: high
Rule
NGINX Exploit-Path Activity Followed by Suspicious Child Process Execution
Rule Format
SIGMA behavioral process-creation rule suitable for endpoint process telemetry, command-line telemetry, parent-child process lineage, NGINX service-account context, exposed NGINX asset tagging, operating-system normalization, and SIEM conversion after NGINX process mapping, service-account validation, child-process category validation, field mapping, exploit-path correlation validation, expected-change allowlisting, and environment-specific tuning.
Detection Purpose
· Detect suspicious child-process execution from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, or WAF-adjacent infrastructure after NGINX exploit-path activity.
· Identify possible post-exploitation command execution involving shells, scripting interpreters, network utilities, file-transfer utilities, archive utilities, credential utilities, service-control utilities, package managers, or administrative tools.
· Prioritize suspicious child-process execution that follows suspicious request activity, rewrite-route anomalies, NGINX worker instability, route-specific 500-series spikes, upstream resets, gateway failures, or NGINX-backed service degradation.
· Support portable behavior-led detection without relying on proof-of-concept syntax, static payload strings, vulnerable-version exposure alone, or NGINX presence alone.
· This rule does not prove successful exploitation by itself; confirmation requires correlation with request telemetry, crash artifacts, command behavior, file activity, network activity, credential access, identity anomalies, Kubernetes activity, cloud activity, or validated downstream impact.
Detection Logic
· Identify process creation where NGINX, NGINX Plus, ingress-controller, reverse proxy, gateway service, or related NGINX service-account context is associated with the parent process or execution context.
· Detect child processes involving shells, scripting interpreters, network utilities, file-transfer tools, archive utilities, credential utilities, service-control utilities, package managers, or administrative utilities.
· Increase confidence when command-line arguments show remote retrieval, encoded execution, temporary-directory execution, credential access, metadata service access, writable-path execution, privilege-oriented actions, or service modification.
· Increase confidence when the process event occurs on exposed NGINX-backed infrastructure, containerized NGINX workloads, NGINX ingress nodes, gateway nodes, or WAF-adjacent NGINX systems.
· Increase confidence when process execution occurs shortly after suspicious rewrite-route request activity, malformed request activity, route-specific 500-series spikes, upstream reset spikes, gateway failures, NGINX worker crashes, segmentation fault indicators, abnormal worker exits, or service degradation.
· Increase confidence when child-process execution is followed by outbound communication, sensitive file access, mounted-secret access, credential access, persistence behavior, internal service probing, Kubernetes activity, or cloud-control-plane activity.
· Reduce severity for approved deployment automation, configuration management, package-managed NGINX updates, certificate renewal, service reloads, approved security testing, approved incident-response activity, and known administrative maintenance.
· Do not classify child-process execution as confirmed compromise without corroborating exploit-path request context, crash evidence, file activity, network behavior, identity anomalies, Kubernetes activity, cloud activity, or validated downstream impact.
· Do not broadly suppress NGINX child-process activity because administrative tooling, deployment tooling, and attacker execution may use overlapping utilities.
Required Telemetry
· Endpoint process creation telemetry.
· Parent process name.
· Parent process path.
· Child process name.
· Child process path.
· Full command line.
· Process hash.
· User identity.
· Service-account context.
· Host identity.
· Host asset category.
· Working directory.
· Timestamp.
· Process start time.
· Process tree or causal process lineage.
· NGINX access logs.
· NGINX error logs.
· File telemetry where available.
· Network telemetry where available.
· Script execution telemetry where available.
· Container runtime telemetry where available.
· Kubernetes telemetry where available.
· Exposed NGINX asset tagging.
· NGINX process mapping.
· NGINX service-account mapping.
· Known-good deployment and maintenance allowlists.
· SIEM or EDR field normalization for parent process, child process, command line, working directory, user, host, asset category, and timestamp.
· Identity, Kubernetes, cloud, application, and NDR enrichment where available.
· Change-management, testing, incident-response, certificate-renewal, package-management, and approved automation context.
Engineering Implementation Instructions
· Convert the SIGMA rule into the target SIEM or EDR query language only after validating supported fields and log-source mappings.
· Normalize process telemetry across Linux hosts, containerized workloads, Kubernetes nodes, ingress systems, reverse proxy hosts, and gateway infrastructure.
· Build process identity mappings for NGINX master processes, NGINX worker processes, NGINX Plus processes, ingress-controller processes, gateway service processes, and WAF-adjacent NGINX service contexts.
· Build NGINX service-account mappings for reverse proxy, ingress, gateway, WAF-adjacent, and containerized NGINX workloads.
· Build high-risk child-process categories for shells, scripting engines, network utilities, file-transfer utilities, archive utilities, credential utilities, service-control utilities, package managers, administrative utilities, and persistence-capable utilities.
· Build exposed NGINX asset groups and NGINX-backed infrastructure asset groups in the target SIEM or EDR platform.
· Correlate SIGMA-derived process alerts with suspicious rewrite-route request activity, malformed request activity, NGINX worker instability, route-specific 500-series spikes, upstream reset spikes, gateway failures, and NGINX-backed service degradation where available.
· Use shorter correlation windows for suspicious request activity followed by immediate shell, interpreter, network utility, credential utility, or file-transfer execution.
· Use moderate correlation windows for worker instability followed by child-process execution, outbound communication, sensitive file access, mounted-secret access, or persistence behavior.
· Use longer correlation windows for delayed post-exploitation behavior, repeated child-process execution, repeated infrastructure contact, or similar activity across multiple NGINX-backed assets.
· Avoid broad allowlisting for shells, interpreters, package managers, service utilities, file-transfer tools, or network utilities because these tools are both legitimate administrative dependencies and common attacker execution paths.
· Validate converted query syntax, field mappings, case sensitivity, platform path differences, container path differences, process naming differences, expected-change allowlists, and environment-specific tuning before production deployment.
DRI Assessment
DRI
8.5 / 10
· The rule is behaviorally anchored to suspicious child-process execution from NGINX-backed infrastructure after exploit-path activity, which is a durable detection point for this report’s post-exploitation model.
· The rule remains useful if the specific request pattern changes but successful exploitation still results in NGINX-associated shell, interpreter, network utility, credential utility, service-control, or file-transfer execution.
· The score is supported by portable process-lineage logic, command-line visibility, child-process category, service-account context, exposed-asset tagging, working-directory context, file activity, network activity, and request-to-host correlation.
· The score is constrained by SIGMA conversion quality, SIEM-specific field availability, endpoint log-source differences, command-line capture gaps, container abstraction, process-lineage gaps, legitimate administrative automation, and required backend correlation.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
9.0 / 10
· Operational confidence depends on successful SIGMA conversion, process-lineage fidelity, command-line capture, exposed NGINX asset tagging, NGINX process mapping, service-account mapping, child-process baseline quality, expected-change allowlisting, and SIEM normalization.
· Operational confidence is reduced where the target platform does not preserve parent-child process lineage, command-line data, working directory, service-account context, reliable process naming, or asset role.
· Operational confidence is reduced where NGINX infrastructure routinely uses shell scripts, package managers, service utilities, certificate-renewal automation, configuration management, deployment automation, or administrative tooling as part of sanctioned workflows.
· Full-telemetry confidence improves when SIGMA-derived process alerts are correlated with suspicious request activity, NGINX error logs, crash artifacts, file telemetry, network telemetry, blocked control events, credential-access behavior, identity-provider records, Kubernetes activity, cloud activity, application telemetry, and NDR telemetry.
· Under full telemetry conditions, this rule provides strong portable evidence of suspicious post-exploitation execution but should still be correlated before classifying activity as confirmed exploitation.
Limitations
· This rule detects suspicious NGINX-associated child-process behavior, not successful exploitation by itself.
· SIGMA conversion quality varies by SIEM, EDR, schema, log source, and backend query language.
· NGINX infrastructure may legitimately spawn or trigger scripts, package managers, certificate-renewal utilities, service-control utilities, configuration-management tools, deployment tooling, and administrative automation.
· Missing parent-child process lineage may prevent reliable attribution to NGINX or related service-account context.
· Missing command-line capture may reduce confidence in command-risk assessment.
· Missing request or error-log telemetry may reduce confidence in exploit-path correlation.
· Containerized deployments may obscure parent process, service-account context, mounted-volume context, and workload identity.
· The rule may miss attacks that avoid obvious child processes, use approved automation, remain memory-only, abuse existing processes, or operate through common administrative tools.
· Confirmation requires correlation with exploit-path request context, crash evidence, command behavior, file activity, outbound network behavior, credential access, identity anomalies, Kubernetes activity, cloud activity, or other endpoint evidence.
Detection Query Pattern
SIGMA behavioral process-creation pattern requiring backend conversion, field mapping validation, platform syntax validation, NGINX process mapping, service-account validation, exposed NGINX asset tagging, exploit-path correlation, child-process category validation, operating-system normalization, and environment-specific allowlisting before production deployment.
title: NGINX Exploit Path Followed By Suspicious Child Process Execution
id: ENV-SIGMA-NGINX-RIFT-CHILD-PROCESS-EXECUTION
status: experimental
description: Detects suspicious child-process execution from NGINX-backed infrastructure when correlated with preceding NGINX exploit-path indicators.
correlation: required
logsource:
category: process_creation
product: linux
detection:
selection_nginx_asset_context:
HostAssetCategory|contains:
- internet_facing_nginx
- nginx_reverse_proxy
- nginx_ingress
- nginx_gateway
- waf_adjacent_nginx
- containerized_nginx_workload
selection_nginx_parent:
ParentImage|contains:
- nginx
- nginx_plus
- ingress-controller
- reverse-proxy
- gateway-service
selection_nginx_service_account:
User|contains:
- ENV_NGINX_SERVICE_ACCOUNT
- ENV_REVERSE_PROXY_SERVICE_ACCOUNT
- ENV_INGRESS_SERVICE_ACCOUNT
- ENV_GATEWAY_SERVICE_ACCOUNT
selection_child_process:
Image|endswith:
- /sh
- /bash
- /dash
- /zsh
- /python
- /python3
- /perl
- /ruby
- /php
- /curl
- /wget
- /nc
- /ncat
- /socat
- /chmod
- /chown
- /systemctl
- /crontab
- /tar
- /unzip
selection_risk_command:
CommandLine|contains:
- curl
- wget
- base64
- chmod
- chown
- /tmp
- /var/tmp
- credentials
- token
- secret
- metadata
- authorized_keys
- crontab
- systemctl
filter_expected_change:
ChangeContext|contains:
- approved_deployment_activity
- approved_configuration_management
- approved_certificate_renewal
- approved_package_managed_nginx_config_write
- approved_package_update
- approved_service_reload
- approved_security_testing
- approved_incident_response_activity
condition: selection_nginx_asset_context and (selection_nginx_parent or selection_nginx_service_account) and selection_child_process and selection_risk_command and not filter_expected_change
fields:
· UtcTime
· Computer
· User
· HostAssetCategory
· ParentImage
· ParentCommandLine
· Image
· CommandLine
· CurrentDirectory
· Hashes
falsepositives:
· Approved deployment automation
· Configuration management
· Certificate renewal
· Package-managed NGINX updates
· Service reloads
· Approved security testing
· Approved incident response activity
level: high
Rule
NGINX Exploit-Path Activity Followed by Unusual Egress or Backend Access
Rule Format
SIGMA portable network-correlation pattern suitable for network connection telemetry, DNS telemetry, proxy telemetry, firewall telemetry, endpoint-network telemetry, NDR telemetry, cloud flow logs, NGINX access logs, NGINX error logs, exposed NGINX asset tagging, destination enrichment, backend dependency mapping, and SIEM correlation after field mapping, dependency-map validation, exploit-path correlation validation, timing-window support validation, and environment-specific tuning.
Detection Purpose
· Detect unusual outbound communication or backend access from NGINX-backed infrastructure after NGINX exploit-path activity, service instability, or suspicious host-side behavior.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, data transfer, backend probing, internal service discovery, cloud metadata access, Kubernetes API access, identity-system access, or management-interface access.
· Prioritize communication involving rare destinations, newly observed destinations, suspicious destination categories, non-baselined egress, direct IP communication, unusual ports, or sensitive backend access outside documented NGINX dependencies.
· Support portable escalation from suspicious request or host behavior to higher-confidence compromise assessment.
· This rule does not prove successful exploitation by itself; confirmation requires correlation with exploit-path request context, suspicious host behavior, endpoint process lineage, file activity, credential access, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated data-flow evidence.
Detection Logic
· Identify outbound or internal network communication from NGINX, NGINX Plus, reverse proxy, ingress-controller, gateway, WAF-adjacent, containerized NGINX, or NGINX-backed infrastructure.
· Detect communication to rare, newly observed, low-reputation, unknown external, infrastructure-like, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, unapproved cloud, direct IP, unusual port, or non-baselined destinations.
· Detect internal communication to sensitive backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, regulated data paths, or sensitive internal services.
· Increase confidence when activity follows suspicious malformed request activity, rewrite-route request anomalies, route-specific error spikes, NGINX worker instability, segmentation fault indicators, service restarts, suspicious child-process execution, file activity, credential access, or mounted-secret access.
· Increase confidence when unusual egress or backend access is initiated by suspicious NGINX-related child processes, service-account context, containerized NGINX workloads, ingress-controller workloads, or gateway-hosting nodes.
· Increase confidence when the same destination, domain, ASN, tunnel provider, hosting provider, backend destination, or infrastructure cluster is contacted by multiple NGINX-backed assets after similar exploit-path indicators.
· Increase confidence when traffic includes direct IP communication, unusual TLS SNI, abnormal user agent, unexpected protocol, high byte count, repeated beacon-like timing, abnormal session duration, connection sweeps, service discovery, metadata probing, or access to destinations outside dependency maps.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, backend health checks, monitoring systems, security tooling, deployment automation, administrative workflows, and known operational maintenance.
· Do not classify egress or backend access as confirmed compromise without corroborating exploit-path context, endpoint process lineage, file activity, crash telemetry, identity telemetry, Kubernetes telemetry, cloud telemetry, application anomalies, or validated data-flow evidence.
· Do not treat outbound communication or internal backend access from NGINX infrastructure as malicious by itself because reverse proxy and ingress tiers routinely communicate with upstream services.
Required Telemetry
· DNS events where available.
· Proxy events where available.
· Firewall events where available.
· Network flow telemetry where available.
· Cloud flow logs where available.
· NDR events where available.
· Endpoint network telemetry where available.
· NGINX access logs.
· NGINX error logs.
· WAF events where available.
· Load balancer events where available.
· Ingress events where available.
· Source IP.
· Source asset identity after enrichment validation.
· Source hostname.
· Source asset category.
· Source workload identity where available.
· Source container identity where available.
· Source node identity where available.
· Source service identity where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Event timestamp.
· Session duration where available.
· Byte count where available.
· Connection count where available.
· TLS SNI where available.
· HTTP host where available.
· User agent where available.
· Destination reputation where available after enrichment validation.
· Destination category where available after enrichment validation.
· Destination ASN where available.
· Destination geolocation where available.
· Destination first-seen timestamp where available after enrichment validation.
· Domain age where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, and service-mesh destinations.
· Prior suspicious inbound request context.
· NGINX service instability context.
· Endpoint process correlation where available.
· File telemetry correlation where available.
· Identity-provider correlation where available.
· Kubernetes telemetry where available.
· Cloud-control-plane telemetry where available.
· Change-management, testing, incident-response, service-owner, and maintenance-window context.
Engineering Implementation Instructions
· Treat this detection as a portable correlation pattern, not as a guaranteed single-rule SIGMA deployment.
· If the target backend supports multi-event correlation, convert the pattern into a correlation rule joining NGINX exploit-path context with unusual egress or backend access by source asset, source service, workload identity, destination, route, virtual host, or time window.
· If the target backend does not support multi-event correlation, deploy paired rules for suspicious NGINX request activity, suspicious NGINX host behavior, and unusual NGINX egress, then correlate those alerts in the SIEM or case-management workflow.
· Build exposed NGINX source groups for internet-facing NGINX servers, NGINX Plus servers, reverse proxies, ingress controllers, gateways, WAF-adjacent NGINX services, containerized NGINX workloads, and Kubernetes nodes hosting NGINX ingress.
· Build approved destination maps for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and documented internal services.
· Build sensitive destination maps for backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secrets managers, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Correlate unusual egress or backend access with suspicious request activity, NGINX error logs, crash artifacts, suspicious child-process execution, file telemetry, credential access, Kubernetes events, cloud-control-plane events, identity-provider events, and application anomalies.
· Use shorter correlation windows for exploit-path request activity followed by immediate rare-destination egress, backend probing, metadata access, or suspicious outbound communication.
· Use moderate correlation windows for worker instability followed by unusual egress, backend access, or internal service discovery.
· Use longer correlation windows for delayed callback, repeated destination contact, repeated backend probing, token reuse, cloud access, or repeated behavior across multiple NGINX-backed assets.
· Avoid broad suppression for cloud providers, package repositories, service mesh infrastructure, observability systems, or upstream applications because attacker activity may use the same infrastructure categories.
· Validate converted query syntax, source asset mapping, destination enrichment, dependency maps, network directionality, NAT behavior, service mesh behavior, timing-window behavior, and environment-specific allowlists before production deployment.
DRI Assessment
DRI
8.0 / 10
· The rule is behaviorally anchored to unusual egress or backend access from NGINX-backed infrastructure after exploit-path indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, data transfer, backend probing, metadata access, Kubernetes access, or internal service discovery.
· The score is supported by source asset role, destination novelty, destination sensitivity, dependency deviation, timing, prior exploit-path context, service-account context, and correlation with process, file, crash, identity, Kubernetes, cloud, or application telemetry.
· The score is constrained by normal NGINX upstream communication, broad cloud and SaaS usage, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, process-to-network attribution gaps, and backend conversion limits.
TCR Assessment
Operational TCR
7.0 / 10
Full-Telemetry TCR
8.5 / 10
· Operational confidence depends on successful SIGMA conversion, egress visibility, east-west visibility, DNS visibility, proxy visibility, destination enrichment, asset tagging, workload identity, dependency baselines, sensitive-destination mapping, and prior exploit-path correlation.
· Operational confidence is reduced where the target backend cannot support reliable network-sequence logic, dependency-map exclusions, first-seen destination logic, destination reputation enrichment, or service-owner context.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX hosts, workloads, containers, nodes, or service identities.
· Full-telemetry confidence improves when network events are correlated with NGINX access logs, NGINX error logs, endpoint process lineage, file telemetry, crash telemetry, WAF events, NDR telemetry, identity-provider events, Kubernetes telemetry, cloud-control-plane logs, application logs, and change-management context.
· Under full telemetry conditions, this pattern provides useful portable escalation evidence for possible post-exploitation communication or internal expansion, especially when unusual egress or backend access follows suspicious request or host-side indicators.
Limitations
· This rule detects unusual egress or backend access after NGINX exploit-path activity, not successful exploitation by itself.
· SIGMA conversion quality varies by SIEM, NDR, schema, log source, and backend query language.
· Some target platforms may not support network, dependency-map, or multi-event correlation without custom correlation searches.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, and internal services.
· NAT, service mesh, proxy chaining, cloud networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common cloud providers, or communicate through permitted service dependencies.
· Confirmation requires correlation with exploit-path context, endpoint process lineage, file activity, credential access, identity anomalies, Kubernetes activity, cloud activity, application anomalies, or validated data movement.
Detection Query Pattern
SIGMA portable network-correlation pattern requiring backend conversion, field mapping validation, platform syntax validation, source asset mapping, destination enrichment, dependency-map validation, sensitive-destination validation, exploit-path correlation, timing-window support, and environment-specific allowlisting before production deployment.
title: NGINX Exploit Path Followed By Unusual Egress Or Backend Access
id: ENV-SIGMA-NGINX-RIFT-EGRESS-OR-BACKEND-ACCESS
status: experimental
description: Portable correlation pattern for unusual egress or sensitive backend access from NGINX-backed infrastructure after NGINX exploit-path activity, service instability, or suspicious host-side behavior.
correlation: required
logsource:
category: network_connection
detection:
selection_nginx_source:
SourceAssetCategory|contains:
- nginx_server
- nginx_reverse_proxy
- nginx_ingress
- nginx_gateway
- waf_adjacent_nginx
- containerized_nginx_workload
selection_suspicious_destination:
DestinationCategory|contains:
- rare_destination
- newly_observed_destination
- dynamic_dns
- temporary_hosting
- paste_service
- file_sharing
- tunneling
- unapproved_cloud
- direct_ip
- unknown_external
selection_sensitive_backend:
DestinationAssetCategory|contains:
- backend_application
- internal_api
- database
- identity_service
- kubernetes_api
- cloud_metadata_endpoint
- secrets_manager
- ci_cd_system
- artifact_repository
- management_interface
- regulated_data_path
selection_session_behavior:
EventReason|contains:
- beacon_like
- unusual_duration
- repeated_rare_destination
- connection_sweep
- service_discovery_pattern
- metadata_access_pattern
filter_approved_destinations:
DestinationContext|contains:
- approved_upstream_application
- approved_observability_destination
- approved_log_forwarding_destination
- approved_package_repository
- approved_update_repository
- approved_security_tool
- approved_service_mesh
- approved_management_destination
- approved_backend_health_check
filter_expected_change:
ChangeContext|contains:
- approved_patch_activity
- approved_service_maintenance
- approved_nginx_reload
- approved_package_update
- approved_monitoring_activity
- approved_security_testing
- approved_incident_response_activity
- approved_deployment_activity
- approved_application_release
condition: selection_nginx_source and (selection_suspicious_destination or selection_sensitive_backend or selection_session_behavior) and not filter_approved_destinations and not filter_expected_change
fields:
· UtcTime
· SourceIp
· SourceHost
· SourceAssetCategory
· DestinationIp
· DestinationHost
· DestinationPort
· DestinationCategory
· DestinationAssetCategory
· NetworkDirection
· NetworkBytes
· EventReason
· ChangeContext
falsepositives:
· Approved upstream application communication
· Service mesh traffic
· Backend health checks
· Observability flows
· Deployment automation
· Security tooling
· Approved incident response activity
level: high
YARA
Detection Viability Assessment
YARA has zero rules for this EXP report.
· YARA is not viable as a deployed rule system for this report at this stage because the NGINX Rift activity model is centered on exploit-path behavior, malformed request activity, service instability, process execution, network egress, and backend access rather than a stable malware, webshell, dropper, exploit binary, memory artifact, or file artifact.
· No durable file signature, byte pattern, string set, embedded marker, compiled artifact, webshell family, post-exploitation tool, or payload sample has been established as a reliable detection anchor for this report.
· YARA should not be forced into this S25 body because doing so would create weak or misleading artifact detection based on proof-of-concept fragments, exploit labels, public writeup strings, NGINX configuration text, generic shell commands, or vulnerable-version context.
· YARA may become viable in a future amendment if confirmed exploitation produces stable artifacts such as a webshell, ELF payload, loader, dropper, memory-resident implant with extractable strings, malicious NGINX module, staged script, encoded payload, or repeatable attacker toolmark.
· Until such artifacts exist, the correct detection coverage remains behavior-led across NDR / Network Behavioral Analytics, SentinelOne, Splunk, Elastic, QRadar, SIGMA, AWS, Azure, and GCP.
Final Outcome
No YARA rules are deployed or proposed for this EXP report.
AWS
Required AWS Data Sources and Field Assumptions
· AWS WAF logs for internet-facing NGINX-backed applications where enabled.
· CloudFront standard or real-time logs where CloudFront fronts NGINX-backed origins.
· Application Load Balancer access logs for AWS-exposed NGINX-backed target groups.
· NGINX access logs and NGINX error logs exported to S3, CloudWatch Logs, OpenSearch, or the customer SIEM.
· AWS Config or equivalent cloud asset inventory for ALB, CloudFront, EC2, ECS, EKS, target group, security group, route, tag, account, region, exposure, and ownership context.
· EC2 metadata and tagging for workload owner, environment, internet exposure, business criticality, and production status.
· ECS inventory where applicable, including cluster, service, task ARN, task role, container image, network mode, and workload ownership.
· EKS inventory where applicable, including cluster name, node group, namespace, service account, ingress controller, node role, workload identity, and workload criticality.
· VPC Flow Logs for outbound, east-west, backend, and metadata-path visibility where enabled.
· Route 53 Resolver query logs for DNS activity from NGINX-backed workloads where enabled.
· CloudTrail or CloudTrail Lake for IAM, STS, Secrets Manager, SSM, EC2, EKS, ECS, KMS, S3, ECR, and control-plane activity.
· GuardDuty findings where available for suspicious credential use, instance compromise indicators, anomalous API behavior, metadata access, unusual role activity, or suspicious network behavior.
· Security Hub findings where available for consolidated cloud-risk and detection context.
· Role-to-workload mapping that links IAM roles, instance profiles, ECS task roles, EKS service accounts, EC2 instances, EKS nodes, ECS tasks, ingress workloads, reverse proxies, gateways, and high-value NGINX-backed services.
· Approved automation context for expected source IPs, scanners, user agents, IAM roles, service principals, deployment systems, observability systems, backup workflows, security tooling, and maintenance windows.
· All query patterns must be adapted to the customer’s AWS Organizations structure, Security Hub aggregation model, Config coverage, tagging taxonomy, CloudTrail Lake event data store, WAF and ALB export schema, CloudFront logging model, ECS and EKS architecture, IAM role model, NGINX logging model, SIEM export format, and approved automation baseline before deployment.
Rule 1
AWS-Exposed NGINX Rewrite-Path Request and Service-Instability Prioritization
Rule Format
· AWS Athena, AWS WAF, CloudFront, Application Load Balancer, AWS Config, and NGINX log enrichment query pattern for exposed NGINX-backed request-shape and instability prioritization.
Detection Purpose
· Identify AWS-exposed NGINX-backed services receiving suspicious request-shape activity consistent with rewrite-path probing, malformed request delivery, route-specific request variation, request-shape fuzzing, or exploit-path adaptation.
· Prioritize suspicious request activity where the target is internet-facing, business-critical, WAF-adjacent, CloudFront-fronted, ALB-exposed, EKS ingress-backed, ECS-backed, or tied to high-value application routes.
· Increase priority when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, route-specific 500-series spikes, ALB target 5xx spikes, upstream reset behavior, ECS task restarts, EKS pod restarts, or NGINX-backed service degradation.
· Support triage, hunt scoping, workload owner notification, route review, patch validation, and host telemetry collection.
· This rule does not detect confirmed exploitation by itself.
Detection Logic
· Identify AWS WAF, CloudFront, ALB, API Gateway where applicable, or NGINX access-log events targeting AWS-exposed NGINX-backed infrastructure.
· Correlate request activity with AWS Config, EC2, ECS, EKS, ALB, CloudFront, and tagging context to confirm that the destination service is NGINX-backed and externally reachable.
· Detect suspicious request-shape indicators such as abnormal URI length, repeated encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, suspicious query structure, uncommon methods, ambiguous request parsing, or request-normalization failure.
· Increase priority when the request targets rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream application routes.
· Increase priority when the same source, ASN, hosting provider, route pattern, user agent, or request shape appears across multiple NGINX-backed assets, CloudFront distributions, ALBs, accounts, or regions.
· Increase priority when suspicious request activity aligns with NGINX error-log instability, ALB target errors, ECS task restarts, EKS pod restarts, or application health degradation.
· Use request-shape and instability evidence as exploitation-priority evidence only.
· Require workload telemetry, process telemetry, outbound egress, cloud-control-plane activity, or other corroborating behavior before labeling the case as suspected exploitation.
· Suppress approved vulnerability scanning, patch validation, QA testing, synthetic monitoring, load balancer probes, CDN health checks, sanctioned security testing, and documented incident-response activity before escalation.
Required Telemetry
· AWS WAF logs.
· CloudFront logs where applicable.
· Application Load Balancer access logs.
· API Gateway access logs where applicable.
· NGINX access logs.
· NGINX error logs.
· AWS Config resource inventory.
· EC2 instance metadata and tags.
· ECS service and task inventory where applicable.
· EKS cluster, ingress, node, pod, and namespace context where applicable.
· CloudFront distribution and origin mapping.
· ALB listener, rule, target group, and target mapping.
· Route or application mapping where available.
· Source IP.
· Forwarded IP.
· ASN.
· Geolocation.
· User agent.
· Request method.
· URI.
· Query string.
· Host header.
· Status code.
· Target status code.
· Request duration.
· Target response time.
· NGINX worker crash indicators.
· NGINX segmentation fault indicators.
· NGINX abnormal worker exit indicators.
· NGINX upstream reset indicators.
· Route-specific 500-series indicators.
· Service-degradation indicators.
· Approved scanner, synthetic monitoring, patch validation, load balancer probe, CDN health check, QA, testing, incident-response, and security-tooling context.
Engineering Implementation Instructions
· Confirm AWS WAF, CloudFront, ALB, and NGINX log coverage for all internet-facing NGINX-backed services.
· Confirm AWS Config and asset inventory coverage across relevant AWS accounts and regions.
· Map CloudFront distributions, ALBs, target groups, ECS services, EKS ingress services, and EC2 instances back to NGINX-backed application owners.
· Build route maps for rewrite-heavy routes, authentication paths, API paths, gateway paths, ingress paths, administrative portals, customer-facing virtual hosts, and high-dependency upstream routes.
· Normalize forwarded-IP handling so source attribution is not confused by CloudFront, WAF, ALB, NAT, proxy, or service mesh behavior.
· Parse NGINX error logs for worker instability, segmentation fault indicators, abnormal worker exits, reload failures, upstream resets, and route-specific service degradation.
· Join suspicious request activity to NGINX error-log and AWS workload-health indicators within a short request-to-instability correlation window.
· Add allowlists for approved scanners, synthetic monitoring, QA testing, patch validation, load balancer probes, CDN health checks, approved security testing, and incident-response activity.
· Do not generate an exploitation alert from malformed requests, NGINX exposure, vulnerable-version context, or service instability alone.
· Use this rule to drive triage priority, route review, host telemetry collection, workload owner notification, and correlation with post-request workload or cloud activity.
Production-Readiness Requirements
· Validate AWS Organizations account and region coverage for all AWS-exposed NGINX-backed services.
· Validate AWS WAF, CloudFront, ALB, API Gateway where applicable, NGINX access-log, and NGINX error-log availability.
· Validate exact Athena table names, S3 partitions, timestamp parsing, URI fields, forwarded-IP fields, WAF action fields, ALB target fields, CloudFront distribution fields, and NGINX error-log parsing.
· Validate AWS Config asset joins for CloudFront distributions, ALBs, target groups, ECS services, EKS ingress services, EC2 instances, hostnames, service ownership, route profiles, and internet-facing status.
· Validate approved scanner lists, synthetic monitoring sources, load balancer probe sources, CDN health checks, patch-validation sources, QA sources, and incident-response sources.
· Validate request-to-instability correlation windows, false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on AWS account coverage, WAF and CloudFront logging maturity, ALB logging coverage, NGINX log availability, ECS and EKS visibility, route inventory quality, workload criticality, exposed-service volume, and SOC operating model. Scaling must not weaken the requirement for corroborating behavior before suspected NGINX Rift exploitation is declared.
DRI Assessment
DRI
8.0 / 10
· The rule is anchored to suspicious request-shape activity and service-instability correlation against AWS-exposed NGINX-backed infrastructure.
· The score is constrained because request-shape and instability signals do not prove successful exploitation.
· The rule is resilient to exploit modification because it does not rely on proof-of-concept strings or a single static request fragment.
· The rule remains valuable for prioritizing exposed services, hunt scoping, route review, telemetry collection, and escalation into workload or cloud-control-plane analysis.
TCR Assessment
Operational TCR
7.8 / 10
Full-Telemetry TCR
8.8 / 10
· Operational confidence depends on AWS WAF logging, CloudFront logging, ALB logging, NGINX access-log fidelity, NGINX error-log fidelity, AWS Config accuracy, route mapping, scanner allowlists, source attribution, and finding freshness.
· Operational confidence is reduced where CloudFront, WAF, ALB, ingress, gateway, or reverse proxy layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Full-telemetry confidence improves when WAF, CloudFront, ALB, NGINX access logs, NGINX error logs, ECS, EKS, EC2, route context, workload ownership, and endpoint telemetry are centrally correlated.
Limitations
· Suspicious request-shape activity is not exploitation evidence by itself.
· NGINX worker instability, ALB target errors, ECS task restarts, EKS pod restarts, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, scaling events, misconfiguration, package updates, or maintenance.
· CloudFront, WAF, ALB, ingress, gateway, proxy, or service mesh normalization may obscure original request shape.
· Forwarded-IP handling may complicate source attribution.
· Missing NGINX error logs may prevent confirmation of service-instability correlation.
· Missing route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· Workload telemetry is required to assess whether exploitation likely occurred.
Detection Query Pattern
-- AWS Athena / WAF / CloudFront / ALB / Config / NGINX enrichment pattern.
-- Table and field names must be adapted to the customer export model.
WITH suspicious_requests AS (
SELECT
event_time,
account_id,
region,
source_ip,
forwarded_for,
user_agent,
http_method,
host_header,
uri_path,
query_string,
status_code,
target_status_code,
request_duration,
target_processing_time,
distribution_id,
load_balancer_arn,
target_group_arn,
rule_id,
action
FROM aws_edge_http_logs
WHERE (
LENGTH(uri_path) >= 1024
OR uri_path REGEXP '(%25|%2e|%2f|%5c|%u[0-9a-fA-F]{4})'
OR uri_path REGEXP '([/._-].){12,}'
OR uri_path REGEXP '(%2f.%2f|%252f|%255c|\.\.|//)'
OR query_string REGEXP '(\{|\}|\[|\]|%7b|%7d|%5b|%5d|;|\|)'
OR http_method NOT IN ('GET','POST','HEAD','OPTIONS','PUT','PATCH','DELETE')
)
AND source_ip NOT IN (
SELECT approved_source_ip
FROM approved_scanner_and_monitoring_sources
)
),
nginx_backed_assets AS (
SELECT
account_id,
region,
resource_id,
resource_type,
load_balancer_arn,
target_group_arn,
cloudfront_distribution_id,
hostname,
service_name,
workload_type,
workload_owner,
environment,
asset_criticality,
internet_facing,
route_profile,
tags
FROM aws_nginx_backed_asset_inventory
WHERE internet_facing = true
),
service_instability AS (
SELECT
event_time,
account_id,
region,
hostname,
service_name,
event_type,
error_message,
status_code,
route_path
FROM nginx_error_and_health_events
WHERE event_type IN (
'nginx_worker_crash',
'nginx_segmentation_fault',
'nginx_abnormal_worker_exit',
'nginx_reload_failure',
'route_specific_500_spike',
'alb_target_5xx_spike',
'upstream_reset_spike',
'ecs_task_restart',
'eks_pod_restart',
'nginx_backed_service_degradation'
)
)
SELECT
sr.event_time,
sr.account_id,
sr.region,
sr.source_ip,
sr.forwarded_for,
sr.user_agent,
sr.http_method,
sr.host_header,
sr.uri_path,
sr.query_string,
sr.status_code,
sr.target_status_code,
nba.hostname,
nba.service_name,
nba.workload_type,
nba.workload_owner,
nba.environment,
nba.asset_criticality,
nba.route_profile,
si.event_type AS correlated_instability,
si.error_message AS instability_detail,
CASE
WHEN si.event_type IS NOT NULL
AND nba.asset_criticality IN ('critical','high') THEN 'high'
WHEN nba.route_profile IN ('rewrite-heavy','authentication','api','administrative','customer-facing') THEN 'high'
WHEN nba.environment = 'production' THEN 'medium'
ELSE 'triage'
END AS priority
FROM suspicious_requests sr
JOIN nginx_backed_assets nba
ON sr.account_id = nba.account_id
AND sr.region = nba.region
AND (
sr.target_group_arn = nba.target_group_arn
OR sr.distribution_id = nba.cloudfront_distribution_id
OR sr.host_header = nba.hostname
)
LEFT JOIN service_instability si
ON nba.account_id = si.account_id
AND nba.region = si.region
AND nba.hostname = si.hostname
AND si.event_time BETWEEN sr.event_time AND sr.event_time + INTERVAL '30' MINUTE;
Rule 2
Post-Exploitation AWS Workload, Credential, and Control-Plane Activity After Suspected NGINX Exploit-Path Activity
Rule Format
· CloudTrail Lake, GuardDuty, VPC Flow Logs, Route 53 Resolver logs, ECS, EKS, EC2, NGINX error-log, and workload-to-role correlation pattern.
Detection Purpose
· Detect AWS workload, credential, metadata, or control-plane behavior that may follow successful exploitation of AWS-hosted NGINX-backed infrastructure.
· Identify cloud-side blast-radius indicators such as STS activity, IAM role use, Secrets Manager access, SSM command execution, KMS decrypt activity, S3 access, EKS API activity, ECS task activity, EC2 metadata access, security group modification, snapshot activity, or role-assumption behavior after suspected NGINX exploit-path activity.
· Prioritize activity from IAM roles, instance profiles, ECS task roles, EKS service accounts, EC2 instances, or containerized workloads associated with exposed NGINX-backed services.
· Treat the alert as stronger when paired with suspicious NGINX request activity, NGINX service instability, workload process execution, credential access, or unusual egress.
· This rule does not detect the exploit primitive directly.
Detection Logic
· Identify suspicious AWS API activity from IAM roles, instance profiles, access keys, ECS task roles, EKS service accounts, or assumed-role sessions associated with NGINX-backed workloads.
· Prioritize STS, IAM, Secrets Manager, SSM, EC2, EKS, ECS, KMS, S3, and ECR activity occurring after suspected NGINX exploit-path activity, GuardDuty findings, suspicious metadata access, abnormal source IP, unusual user agent, or unexpected session behavior.
· Increase priority when the IAM role belongs to an internet-facing NGINX service, NGINX reverse proxy, ECS NGINX service, EKS NGINX ingress workload, EC2-hosted NGINX service, gateway tier, or high-value production workload.
· Increase priority when the activity includes Secrets Manager reads, SSM command execution, STS role activity, KMS decrypt, S3 object access, EKS credential or cluster activity, security group changes, access-key creation, snapshot or volume activity, or metadata-driven credential use.
· Treat the alert as stronger when paired with host-level process execution, abnormal privilege transition, suspicious child-process behavior, file staging, credential access, outbound egress, or NGINX error-log instability.
· Do not label AWS control-plane activity as confirmed NGINX Rift exploitation without workload-side or host-side corroboration.
· Suppress approved automation, deployment systems, observability systems, backup workflows, security tooling, maintenance windows, and known administrative role use before escalation.
Required Telemetry
· CloudTrail or CloudTrail Lake management events.
· CloudTrail data events where relevant and enabled.
· GuardDuty findings where available.
· Security Hub findings where available.
· IAM role and instance profile mapping.
· ECS task role mapping.
· EKS service-account and node-role mapping.
· EC2 instance and workload inventory.
· NGINX-backed workload inventory.
· AWS WAF, CloudFront, ALB, and NGINX exploit-path context.
· Source IP.
· User agent.
· Access key.
· Assumed role.
· Session issuer.
· Event source.
· Event name.
· Request parameters.
· Response elements.
· Account.
· Region.
· Secrets Manager, SSM, EC2, EKS, ECS, KMS, S3, ECR, STS, and IAM API event visibility.
· VPC Flow Logs and Route 53 Resolver logs where available.
· Approved cloud automation source IPs, user agents, roles, accounts, and maintenance context.
· Host compromise or endpoint telemetry enrichment where available.
Engineering Implementation Instructions
· Map IAM roles, instance profiles, ECS task roles, EKS service accounts, and assumed-role sessions back to EC2 instances, ECS services, EKS workloads, ingress controllers, reverse proxies, gateways, and high-value NGINX-backed services.
· Validate CloudTrail coverage across all accounts and regions.
· Validate CloudTrail data-event coverage for Secrets Manager, S3, KMS, and other sensitive services where required and operationally approved.
· Enable and aggregate GuardDuty findings where available.
· Establish expected role behavior for production NGINX workloads, ingress workloads, gateway services, ECS services, EKS service accounts, CI systems, deployment roles, backup roles, observability roles, and SSM-managed instances.
· Prioritize activity from NGINX-backed workloads where unusual API behavior follows suspicious request activity, service instability, workload process execution, or unusual egress.
· Add allowlists for approved automation, deployment systems, backup jobs, observability systems, security tooling, SSM maintenance windows, and known administrative role use.
· Correlate with host, workload, or NGINX telemetry before declaring suspected NGINX Rift exploitation.
Production-Readiness Requirements
· Validate CloudTrail Lake event data store coverage, CloudTrail management events, and required CloudTrail data events for Secrets Manager, S3, KMS, ECR, and other sensitive services.
· Validate GuardDuty and Security Hub aggregation across all relevant accounts and regions.
· Validate exact CloudTrail Lake table name, event source fields, event name fields, userIdentity structure, sessionIssuer ARN parsing, access key fields, source IP fields, user agent fields, request parameter parsing, and response element parsing.
· Validate IAM role-to-workload joins for EC2 instance profiles, ECS task roles, EKS service accounts, assumed-role sessions, reverse proxies, ingress services, gateways, and NGINX-backed workloads.
· Validate approved automation sources, deployment roles, backup roles, observability roles, SSM maintenance windows, security-tooling identities, and administrative role baselines.
· Validate exploit-path correlation inputs from WAF, CloudFront, ALB, NGINX logs, service-instability events, workload process telemetry, egress telemetry, and GuardDuty findings.
· Validate false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on environment size, AWS account coverage, CloudTrail Lake maturity, IAM role mapping quality, ECS and EKS visibility, NGINX workload inventory, cloud context, Linux telemetry maturity, CI/CD exposure, and SOC operating model. Scaling must not weaken the behavioral evidence requirement for suspected NGINX Rift exploitation.
DRI Assessment
DRI
8.4 / 10
· The rule is anchored to post-exploitation cloud activity and credential-use behavior rather than static exploit artifacts.
· The rule remains useful if the initial exploit request changes because it focuses on cloud-side consequences of compromised NGINX-backed workload credentials.
· The score is constrained because AWS control-plane events do not directly prove the NGINX exploit path.
· The rule is strong when tied to NGINX-backed workload context, request-shape evidence, service-instability evidence, and host or workload compromise indicators.
TCR Assessment
Operational TCR
7.7 / 10
Full-Telemetry TCR
8.7 / 10
· Operational confidence depends on CloudTrail coverage, GuardDuty coverage, IAM role mapping, instance-profile attribution, ECS and EKS workload attribution, NGINX workload inventory, approved automation baselines, and enrichment quality.
· Operational confidence is reduced where CloudTrail data events are not enabled, ECS and EKS role mapping is incomplete, or NGINX-backed workload ownership is not centrally tracked.
· Full-telemetry confidence improves when CloudTrail, GuardDuty, Security Hub, Config, ECS, EKS, IAM, WAF, ALB, NGINX logs, VPC Flow Logs, Route 53 Resolver logs, and host telemetry are centrally correlated.
Limitations
· AWS control-plane activity may follow many compromise paths and is not unique to NGINX Rift.
· CloudTrail cannot directly observe local NGINX exploitation, memory corruption, local process execution, or workload compromise.
· Legitimate automation, deployment pipelines, SSM activity, backup operations, observability tooling, and security tooling may generate overlapping API activity.
· Instance profile, task role, EKS service account, and assumed-role mapping must be accurate to connect cloud activity to NGINX-backed workloads.
· Host or workload telemetry is required for high-confidence NGINX Rift exploitation assessment.
Detection Query Pattern
-- CloudTrail Lake SQL pattern.
-- Event data store, table names, role-to-workload mapping, and NGINX exploit-path context must be adapted per environment.
SELECT
ct.eventTime,
ct.recipientAccountId,
ct.awsRegion,
ct.eventSource,
ct.eventName,
ct.userIdentity.type AS identity_type,
ct.userIdentity.arn AS identity_arn,
ct.userIdentity.accessKeyId AS access_key_id,
ct.userIdentity.sessionContext.sessionIssuer.arn AS session_issuer_arn,
ct.sourceIPAddress,
ct.userAgent,
ct.requestParameters,
ct.responseElements,
nwm.instance_id,
nwm.task_arn,
nwm.pod_name,
nwm.namespace,
nwm.workload_type,
nwm.service_name,
nwm.asset_criticality,
nwm.exposure_state,
nwm.nginx_role,
nwm.last_suspected_request_time,
nwm.last_service_instability_time
FROM <cloudtrail_lake_event_data_store> ct
JOIN nginx_workload_role_map nwm
ON ct.userIdentity.sessionContext.sessionIssuer.arn = nwm.iam_role_arn
WHERE
ct.eventSource IN (
'sts.amazonaws.com',
'iam.amazonaws.com',
'secretsmanager.amazonaws.com',
'ssm.amazonaws.com',
'ec2.amazonaws.com',
'eks.amazonaws.com',
'ecs.amazonaws.com',
'kms.amazonaws.com',
's3.amazonaws.com',
'ecr.amazonaws.com'
)
AND ct.eventName IN (
'AssumeRole',
'GetCallerIdentity',
'GetSecretValue',
'PutParameter',
'GetParameter',
'GetParameters',
'SendCommand',
'StartSession',
'CreateAccessKey',
'AttachUserPolicy',
'AttachRolePolicy',
'CreatePolicyVersion',
'ModifyInstanceAttribute',
'AuthorizeSecurityGroupIngress',
'CreateSnapshot',
'CopySnapshot',
'CreateVolume',
'AttachVolume',
'DescribeCluster',
'UpdateClusterConfig',
'RunTask',
'ExecuteCommand',
'Decrypt',
'ListBuckets',
'GetObject',
'PutObject',
'GetAuthorizationToken'
)
AND (
nwm.nginx_role IN (
'internet-facing-nginx',
'reverse-proxy',
'ingress-controller',
'gateway',
'waf-adjacent-nginx'
)
OR nwm.asset_criticality IN ('critical','high')
OR nwm.workload_type IN ('ec2-nginx','ecs-nginx','eks-ingress','containerized-nginx')
)
AND (
nwm.last_suspected_request_time IS NOT NULL
OR nwm.last_service_instability_time IS NOT NULL
)
AND (
ct.sourceIPAddress NOT IN (
SELECT approved_source_ip
FROM approved_cloud_admin_sources
)
OR ct.userAgent NOT IN (
SELECT approved_user_agent
FROM approved_cloud_automation_user_agents
)
);
Rule 3
Unusual AWS Egress, Backend Access, or Metadata Activity After Suspected NGINX Exploit-Path Activity
Rule Format
· AWS Athena, VPC Flow Logs, Route 53 Resolver, ALB, NGINX, GuardDuty, and workload-to-destination correlation pattern.
Detection Purpose
· Detect unusual egress, backend access, DNS activity, metadata access, or internal service probing from AWS-hosted NGINX-backed infrastructure after suspected exploit-path request activity or service instability.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, backend probing, internal service discovery, metadata credential access, data transfer, or sensitive dependency access.
· Prioritize traffic from internet-facing NGINX-backed services, ECS NGINX services, EKS ingress workloads, EC2-hosted reverse proxies, gateways, and WAF-adjacent NGINX systems.
· Treat the alert as stronger when paired with suspicious request activity, NGINX worker instability, suspicious workload execution, GuardDuty findings, CloudTrail anomalies, or sensitive backend access.
· This rule does not prove exploitation by itself.
Detection Logic
· Identify outbound, east-west, backend, metadata, or DNS activity from NGINX-backed AWS workloads.
· Prioritize traffic to rare destinations, newly observed destinations, dynamic DNS, temporary hosting, paste services, file-sharing services, tunneling services, unapproved cloud services, direct IP destinations, unusual ports, or unknown external destinations.
· Prioritize internal access to backend applications, internal APIs, databases, identity services, EKS APIs, EC2 metadata endpoints, Secrets Manager endpoints, SSM endpoints, KMS endpoints, S3 endpoints, ECR endpoints, CI/CD systems, artifact repositories, management interfaces, administrative services, or regulated data paths.
· Increase priority when the activity occurs after suspicious request-shape activity, NGINX service instability, workload process execution, credential access, mounted-secret access, GuardDuty findings, or CloudTrail anomalies.
· Increase priority when similar destination activity appears across multiple NGINX-backed assets after similar exploit-path indicators.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, health checks, deployment automation, security tooling, approved AWS API use, and known operational maintenance.
· Do not classify egress, backend access, metadata access, or DNS activity as confirmed compromise without corroborating exploit-path context, process lineage, file activity, credential access, CloudTrail evidence, IAM anomalies, Kubernetes telemetry, application anomalies, or validated data-flow evidence.
Required Telemetry
· VPC Flow Logs.
· Route 53 Resolver query logs where enabled.
· Proxy events where available.
· Firewall telemetry where available.
· GuardDuty findings where available.
· NDR events where available.
· Endpoint network telemetry where available.
· CloudTrail management events.
· CloudTrail data events where relevant and enabled.
· NGINX access logs.
· NGINX error logs.
· AWS WAF logs where available.
· ALB access logs where available.
· Source IP.
· Source ENI.
· Source instance ID where available.
· Source task ARN where available.
· Source pod, namespace, node, or workload identity where available.
· Source IAM role where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Session duration.
· Byte count.
· Connection count.
· DNS query name where available.
· Destination reputation where available.
· Destination category where available.
· Destination first-seen timestamp where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, AWS API, and service-mesh destinations.
· Prior suspicious inbound request context.
· NGINX service-instability context.
· Workload process correlation where available.
· CloudTrail correlation where available.
· Change-management, testing, incident-response, service-owner, deployment, and maintenance-window context.
Engineering Implementation Instructions
· Map VPC Flow Log ENIs, source IPs, task ENIs, pod IPs, and instance IDs back to NGINX-backed workloads.
· Build AWS source groups for internet-facing NGINX EC2 hosts, ECS NGINX services, EKS NGINX ingress workloads, reverse proxies, gateways, WAF-adjacent NGINX services, and containerized NGINX workloads.
· Build approved destination maps for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and approved AWS APIs.
· Build sensitive destination maps for backend applications, internal APIs, databases, identity services, EKS APIs, EC2 metadata endpoints, Secrets Manager, SSM Parameter Store, KMS, S3, ECR, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Correlate unusual egress, backend access, metadata access, and DNS activity with suspicious request activity, NGINX error logs, crash artifacts, suspicious child-process execution, file telemetry, credential access, GuardDuty findings, CloudTrail events, and application anomalies.
· Use shorter correlation windows for exploit-path request activity followed by immediate rare-destination egress, backend probing, metadata access, DNS activity, or suspicious outbound communication.
· Use moderate correlation windows for worker instability followed by unusual egress, backend access, metadata access, or internal service discovery.
· Use longer correlation windows for delayed callback, repeated destination contact, repeated backend probing, token reuse, cloud access, or repeated behavior across multiple NGINX-backed assets.
· Avoid broad suppression for AWS services, cloud providers, package repositories, service mesh infrastructure, observability systems, or upstream applications because attacker activity may use the same infrastructure categories.
· Validate converted query syntax, source asset mapping, ENI-to-workload mapping, IAM role mapping, destination enrichment, dependency maps, network directionality, NAT behavior, service mesh behavior, DNS visibility, timing-window behavior, and environment-specific allowlists before production deployment.
Production-Readiness Requirements
· Validate VPC Flow Log coverage, Route 53 Resolver query logging, NAT architecture, service mesh behavior, proxy behavior, and network directionality for all NGINX-backed AWS workloads.
· Validate exact Athena table names, VPC Flow Log fields, Route 53 Resolver fields, ENI fields, source IP fields, task ENI mappings, pod IP mappings, instance ID joins, timestamp parsing, partitions, byte-count fields, packet fields, DNS query fields, and destination enrichment fields.
· Validate ENI-to-workload joins for EC2, ECS, EKS, task ENIs, pod IPs, node identities, IAM roles, namespaces, and service owners.
· Validate destination enrichment, approved destination lists, backend dependency maps, sensitive destination maps, metadata endpoint detection, approved AWS API destinations, and service-owner baselines.
· Validate exploit-path correlation inputs from WAF, CloudFront, ALB, NGINX logs, service-instability events, workload process telemetry, CloudTrail events, and GuardDuty findings.
· Validate false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on VPC Flow Log coverage, Route 53 Resolver logging, ECS and EKS workload mapping, ENI attribution, NGINX workload inventory, NAT architecture, service mesh design, destination enrichment, cloud context, and SOC operating model. Scaling must not weaken the requirement for exploit-path or workload-side correlation before suspected NGINX Rift exploitation is declared.
DRI Assessment
DRI
8.0 / 10
· The rule is anchored to unusual egress, backend access, metadata activity, and DNS behavior after suspected NGINX exploit-path indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, backend probing, metadata access, internal service discovery, or data-transfer behavior.
· The score is supported by source workload context, destination novelty, destination sensitivity, dependency deviation, timing, prior exploit-path context, and correlation with process, file, GuardDuty, CloudTrail, Kubernetes, or application telemetry.
· The score is constrained by normal NGINX upstream communication, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, and limited process-to-network attribution.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
8.6 / 10
· Operational confidence depends on VPC Flow Log coverage, Route 53 Resolver visibility, ENI-to-workload mapping, ECS and EKS source attribution, destination enrichment, dependency baselines, sensitive-destination mapping, NGINX exploit-path correlation, and approved destination baselines.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX workloads, ENIs, tasks, pods, nodes, IAM roles, or service identities.
· Full-telemetry confidence improves when network events are correlated with NGINX access logs, NGINX error logs, endpoint process lineage, file telemetry, crash telemetry, AWS WAF events, ALB events, GuardDuty findings, CloudTrail events, EKS telemetry, application logs, and change-management context.
Limitations
· Unusual egress, backend access, metadata access, or DNS activity is not exploitation evidence by itself.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, metadata endpoints, and AWS APIs.
· NAT, service mesh, proxy chaining, AWS networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common AWS services, or communicate through permitted service dependencies.
· Confirmation requires correlation with exploit-path context, workload process lineage, file activity, credential access, IAM anomalies, EKS activity, CloudTrail activity, application anomalies, or validated data movement.
Detection Query Pattern
-- AWS Athena / VPC Flow Logs / Route 53 Resolver / workload enrichment pattern.
-- Table and field names must be adapted to the customer export model.
WITH nginx_sources AS (
SELECT
account_id,
region,
workload_id,
instance_id,
task_arn,
pod_name,
namespace,
eni_id,
private_ip,
iam_role_arn,
service_name,
workload_type,
nginx_role,
asset_criticality,
environment,
last_suspected_request_time,
last_service_instability_time
FROM nginx_backed_workload_inventory
WHERE nginx_role IN (
'internet-facing-nginx',
'reverse-proxy',
'ingress-controller',
'gateway',
'waf-adjacent-nginx'
)
),
network_activity AS (
SELECT
start_time,
end_time,
account_id,
region,
interface_id,
srcaddr,
dstaddr,
dstport,
protocol,
action,
bytes,
packets,
direction
FROM vpc_flow_logs
WHERE action = 'ACCEPT'
),
dns_activity AS (
SELECT
query_time,
account_id,
region,
srcaddr,
query_name,
response_code
FROM route53_resolver_query_logs
),
destination_context AS (
SELECT
destination_ip,
destination_domain,
destination_category,
destination_asset_type,
approved_context,
first_seen_time,
sensitivity
FROM destination_enrichment
)
SELECT
na.start_time,
ns.account_id,
ns.region,
ns.service_name,
ns.workload_type,
ns.nginx_role,
ns.instance_id,
ns.task_arn,
ns.pod_name,
ns.namespace,
ns.iam_role_arn,
na.srcaddr,
na.dstaddr,
na.dstport,
na.protocol,
na.bytes,
da.query_name,
dc.destination_domain,
dc.destination_category,
dc.destination_asset_type,
dc.sensitivity,
CASE
WHEN dc.destination_asset_type IN (
'database',
'identity_service',
'secrets_manager',
'metadata_endpoint',
'management_interface',
'regulated_data_path'
) THEN 'high'
WHEN dc.destination_category IN (
'rare_destination',
'newly_observed_destination',
'dynamic_dns',
'temporary_hosting',
'paste_service',
'file_sharing',
'tunneling',
'unknown_external'
) THEN 'high'
WHEN ns.asset_criticality IN ('critical','high') THEN 'medium'
ELSE 'triage'
END AS priority
FROM network_activity na
JOIN nginx_sources ns
ON na.interface_id = ns.eni_id
OR na.srcaddr = ns.private_ip
LEFT JOIN dns_activity da
ON na.account_id = da.account_id
AND na.region = da.region
AND na.srcaddr = da.srcaddr
AND da.query_time BETWEEN na.start_time - INTERVAL '5' MINUTE
AND na.start_time + INTERVAL '5' MINUTE
LEFT JOIN destination_context dc
ON na.dstaddr = dc.destination_ip
OR da.query_name = dc.destination_domain
WHERE (
ns.last_suspected_request_time IS NOT NULL
OR ns.last_service_instability_time IS NOT NULL
)
AND (
dc.approved_context IS NULL
OR dc.approved_context NOT IN (
'approved_upstream_application',
'approved_observability_destination',
'approved_log_forwarding_destination',
'approved_package_repository',
'approved_update_repository',
'approved_security_tool',
'approved_service_mesh',
'approved_management_destination',
'approved_backend_health_check',
'approved_aws_api_use'
)
)
AND (
dc.destination_category IN (
'rare_destination',
'newly_observed_destination',
'dynamic_dns',
'temporary_hosting',
'paste_service',
'file_sharing',
'tunneling',
'unknown_external'
)
OR dc.destination_asset_type IN (
'database',
'identity_service',
'secrets_manager',
'metadata_endpoint',
'management_interface',
'regulated_data_path'
)
OR na.dstport NOT IN (80, 443, 53, 123)
OR na.bytes >= 10485760
);
Azure
Required Azure Data Sources and Field Assumptions
· Azure Front Door, Application Gateway, Web Application Firewall, Load Balancer, and ingress telemetry where Azure-exposed NGINX-backed services are fronted by Azure-native edge, gateway, or load-balancing services.
· NGINX access logs and NGINX error logs exported to Log Analytics, Microsoft Sentinel, Event Hub, Storage, or the customer SIEM.
· Azure Resource Graph inventory for VM, VMSS, AKS node, container host, public IP, load balancer, application gateway, Front Door, network security group, route, tag, subscription, resource group, exposure, ownership, and workload context.
· Azure VM and VMSS metadata and tagging for workload owner, environment, internet exposure, business criticality, production status, and managed identity context.
· AKS inventory where applicable, including cluster name, node pool, node resource group, namespace ownership, ingress controller context, managed identity, workload identity, and workload criticality.
· Azure Activity Logs for subscription, resource, role assignment, VM, network, AKS, Key Vault, Storage, and control-plane activity.
· Microsoft Entra ID sign-in and audit logs where available for service principal activity, managed identity activity, app registrations, conditional access context, and role assignment changes.
· Microsoft Defender for Cloud alerts where available for suspicious VM behavior, credential access, unusual workload activity, suspicious container behavior, or compromised resource indicators.
· Defender for Endpoint telemetry where available for process creation, command-line execution, network activity, file activity, credential access, and post-exploitation workload behavior.
· Key Vault diagnostic logs, Storage diagnostic logs, Azure Monitor logs, NSG flow logs, Azure Firewall logs, and DNS logs where available.
· Managed identity mapping that links system-assigned and user-assigned managed identities to Azure VMs, VMSS instances, AKS nodes, container hosts, ingress workloads, reverse proxies, gateways, CI runners, and high-value NGINX-backed workloads.
· Approved automation context for expected source IPs, scanners, user agents, managed identities, service principals, deployment systems, observability systems, backup workflows, security tooling, and maintenance windows.
· All query patterns must be adapted to the customer’s Azure tenant structure, management group hierarchy, subscription model, Defender coverage, Resource Graph schema, Front Door and Application Gateway logging model, AKS architecture, managed identity model, Sentinel workspace design, diagnostic settings, NGINX logging model, SIEM export format, and approved automation baseline before deployment.
Rule 1
Azure-Exposed NGINX Rewrite-Path Request and Service-Instability Prioritization
Rule Format
· Azure Front Door, Application Gateway WAF, Application Gateway access logs, Azure Resource Graph, Log Analytics, Microsoft Sentinel KQL, and NGINX log enrichment query pattern for exposed NGINX-backed request-shape and instability prioritization.
Detection Purpose
· Identify Azure-exposed NGINX-backed services receiving suspicious request-shape activity consistent with rewrite-path probing, malformed request delivery, route-specific request variation, request-shape fuzzing, or exploit-path adaptation.
· Prioritize suspicious request activity where the target is internet-facing, business-critical, WAF-adjacent, Front Door-fronted, Application Gateway-exposed, AKS ingress-backed, VM-hosted, VMSS-hosted, or tied to high-value application routes.
· Increase priority when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, route-specific 500-series spikes, Application Gateway backend 5xx spikes, upstream reset behavior, AKS pod restarts, VMSS instance instability, or NGINX-backed service degradation.
· Support triage, hunt scoping, workload owner notification, route review, patch validation, and host telemetry collection.
· This rule does not detect confirmed exploitation by itself.
Detection Logic
· Identify Azure Front Door, Application Gateway WAF, Application Gateway access, Load Balancer where applicable, or NGINX access-log events targeting Azure-exposed NGINX-backed infrastructure.
· Correlate request activity with Azure Resource Graph, VM, VMSS, AKS, Application Gateway, Front Door, public IP, and tagging context to confirm that the destination service is NGINX-backed and externally reachable.
· Detect suspicious request-shape indicators such as abnormal URI length, repeated encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, suspicious query structure, uncommon methods, ambiguous request parsing, or request-normalization failure.
· Increase priority when the request targets rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream application routes.
· Increase priority when the same source, ASN, hosting provider, route pattern, user agent, or request shape appears across multiple NGINX-backed assets, Front Door profiles, Application Gateways, subscriptions, or regions.
· Increase priority when suspicious request activity aligns with NGINX error-log instability, Application Gateway backend errors, AKS pod restarts, VM or VMSS service instability, or application health degradation.
· Use request-shape and instability evidence as exploitation-priority evidence only.
· Require workload telemetry, process telemetry, outbound egress, Azure control-plane activity, Defender for Endpoint evidence, or other corroborating behavior before labeling the case as suspected exploitation.
· Suppress approved vulnerability scanning, patch validation, QA testing, synthetic monitoring, load balancer probes, CDN health checks, sanctioned security testing, and documented incident-response activity before escalation.
Required Telemetry
· Azure Front Door logs where applicable.
· Application Gateway access logs.
· Application Gateway WAF logs where enabled.
· Azure Load Balancer telemetry where applicable.
· NGINX access logs.
· NGINX error logs.
· Azure Resource Graph inventory.
· Azure VM and VMSS metadata and tags.
· AKS cluster, ingress, node, pod, namespace, and workload context where applicable.
· Front Door profile, endpoint, route, and origin mapping.
· Application Gateway listener, rule, backend pool, and backend target mapping.
· Public IP and DNS mapping where available.
· Route or application mapping where available.
· Source IP.
· Forwarded IP.
· ASN.
· Geolocation.
· User agent.
· Request method.
· URI.
· Query string.
· Host header.
· Status code.
· Backend status code.
· Request duration.
· Backend response time.
· NGINX worker crash indicators.
· NGINX segmentation fault indicators.
· NGINX abnormal worker exit indicators.
· NGINX upstream reset indicators.
· Route-specific 500-series indicators.
· Service-degradation indicators.
· Approved scanner, synthetic monitoring, patch validation, load balancer probe, CDN health check, QA, testing, incident-response, and security-tooling context.
Engineering Implementation Instructions
· Confirm Azure Front Door, Application Gateway, WAF, Load Balancer where applicable, and NGINX log coverage for all internet-facing NGINX-backed services.
· Confirm Azure Resource Graph and asset inventory coverage across relevant tenants, management groups, subscriptions, and resource groups.
· Map Front Door profiles, Application Gateways, backend pools, AKS ingress services, VMSS instances, and VMs back to NGINX-backed application owners.
· Build route maps for rewrite-heavy routes, authentication paths, API paths, gateway paths, ingress paths, administrative portals, customer-facing virtual hosts, and high-dependency upstream routes.
· Normalize forwarded-IP handling so source attribution is not confused by Front Door, WAF, Application Gateway, Load Balancer, NAT, proxy, or service mesh behavior.
· Parse NGINX error logs for worker instability, segmentation fault indicators, abnormal worker exits, reload failures, upstream resets, and route-specific service degradation.
· Join suspicious request activity to NGINX error-log and Azure workload-health indicators within a short request-to-instability correlation window.
· Add allowlists for approved scanners, synthetic monitoring, QA testing, patch validation, load balancer probes, CDN health checks, approved security testing, and incident-response activity.
· Do not generate an exploitation alert from malformed requests, NGINX exposure, vulnerable-version context, or service instability alone.
· Use this rule to drive triage priority, route review, host telemetry collection, workload owner notification, and correlation with post-request workload or cloud activity.
Production-Readiness Requirements
· Validate Azure tenant, management group, subscription, and resource group coverage for all Azure-exposed NGINX-backed services.
· Validate Azure Front Door, Application Gateway, WAF, Load Balancer where applicable, NGINX access-log, and NGINX error-log availability.
· Validate exact Log Analytics and Sentinel table names, diagnostic settings, timestamp parsing, URI fields, forwarded-IP fields, WAF action fields, backend pool fields, Front Door endpoint fields, Application Gateway backend fields, and NGINX error-log parsing.
· Validate Azure Resource Graph asset joins for Front Door profiles, Application Gateways, backend pools, AKS ingress services, VMSS instances, VMs, hostnames, service ownership, route profiles, and internet-facing status.
· Validate approved scanner lists, synthetic monitoring sources, load balancer probe sources, CDN health checks, patch-validation sources, QA sources, and incident-response sources.
· Validate request-to-instability correlation windows, false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on Azure subscription coverage, Front Door and Application Gateway logging maturity, WAF logging coverage, NGINX log availability, AKS visibility, VM and VMSS visibility, route inventory quality, workload criticality, exposed-service volume, and SOC operating model. Scaling must not weaken the requirement for corroborating behavior before suspected NGINX Rift exploitation is declared.
DRI Assessment
DRI
8.0 / 10
· The rule is anchored to suspicious request-shape activity and service-instability correlation against Azure-exposed NGINX-backed infrastructure.
· The score is constrained because request-shape and instability signals do not prove successful exploitation.
· The rule is resilient to exploit modification because it does not rely on proof-of-concept strings or a single static request fragment.
· The rule remains valuable for prioritizing exposed services, hunt scoping, route review, telemetry collection, and escalation into workload or cloud-control-plane analysis.
TCR Assessment
Operational TCR
7.8 / 10
Full-Telemetry TCR
8.8 / 10
· Operational confidence depends on Azure Front Door logging, Application Gateway logging, WAF logging, NGINX access-log fidelity, NGINX error-log fidelity, Resource Graph accuracy, route mapping, scanner allowlists, source attribution, and finding freshness.
· Operational confidence is reduced where Front Door, WAF, Application Gateway, ingress, gateway, proxy, or service mesh layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Full-telemetry confidence improves when Front Door, Application Gateway, WAF, NGINX access logs, NGINX error logs, AKS, VM, VMSS, route context, workload ownership, Defender for Endpoint, and Azure Activity Logs are centrally correlated.
Limitations
· Suspicious request-shape activity is not exploitation evidence by itself.
· NGINX worker instability, Application Gateway backend errors, AKS pod restarts, VM or VMSS service instability, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, scaling events, misconfiguration, package updates, or maintenance.
· Front Door, WAF, Application Gateway, ingress, gateway, proxy, or service mesh normalization may obscure original request shape.
· Forwarded-IP handling may complicate source attribution.
· Missing NGINX error logs may prevent confirmation of service-instability correlation.
· Missing route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· Workload telemetry is required to assess whether exploitation likely occurred.
Detection Query Pattern
// Sentinel / Log Analytics / Azure Resource Graph / NGINX enrichment pattern.
// Table and field names must be adapted to the customer workspace, diagnostic settings, and export model.
let SuspiciousRequests =
AzureDiagnostics
| where Category in~ ("FrontDoorAccessLog", "ApplicationGatewayAccessLog", "ApplicationGatewayFirewallLog")
| extend
SourceIp = tostring(clientIP_s),
ForwardedFor = tostring(requestHeader_x_forwarded_for_s),
UserAgent = tostring(userAgent_s),
HttpMethod = tostring(httpMethod_s),
HostHeader = tostring(host_s),
UriPath = tostring(requestUri_s),
QueryString = tostring(query_s),
StatusCode = toint(httpStatus_d),
BackendStatusCode = toint(backendStatusCode_d),
RequestDuration = todouble(timeTaken_d),
ResourceId = tolower(ResourceId),
EventTime = TimeGenerated
| where strlen(UriPath) >= 1024
or UriPath matches regex @"(%25|%2e|%2f|%5c|%u[0-9a-fA-F]{4})"
or UriPath matches regex @"([/.-].){12,}"
or UriPath matches regex @"(%2f.%2f|%252f|%255c|..|//)"
or QueryString matches regex @"({|}||%7b|%7d|%5b|%5d|;||)"
or HttpMethod !in~ ("GET","POST","HEAD","OPTIONS","PUT","PATCH","DELETE")
| where SourceIp !in~ (dynamic(["<approved_scanner_ip_1>", "<approved_scanner_ip_2>"]));
let NginxBackedAssets =
Resources
| extend ResourceId = tolower(id)
| extend Environment = tostring(tags.environment)
| extend WorkloadOwner = tostring(tags.owner)
| extend AssetCriticality = tostring(tags.criticality)
| extend RouteProfile = tostring(tags.route_profile)
| extend InternetFacing = tostring(tags.internet_facing)
| extend NginxBacked = tostring(tags.nginx_backed)
| where NginxBacked =~ "true"
| where InternetFacing =~ "true"
| project
SubscriptionId = subscriptionId,
ResourceGroup = resourceGroup,
ResourceId,
ResourceName = name,
ResourceType = type,
Location = location,
Environment,
WorkloadOwner,
AssetCriticality,
RouteProfile,
InternetFacing;
let ServiceInstability =
NginxErrorAndHealthEvents
| where EventType in~ (
"nginx_worker_crash",
"nginx_segmentation_fault",
"nginx_abnormal_worker_exit",
"nginx_reload_failure",
"route_specific_500_spike",
"application_gateway_backend_5xx_spike",
"upstream_reset_spike",
"aks_pod_restart",
"nginx_backed_service_degradation"
)
| project
InstabilityTime = TimeGenerated,
ResourceId = tolower(ResourceId),
EventType,
ErrorMessage,
RoutePath;
SuspiciousRequests
| join kind=inner NginxBackedAssets on ResourceId
| join kind=leftouter ServiceInstability on ResourceId
| where isempty(InstabilityTime)
or InstabilityTime between (EventTime .. EventTime + 30m)
| extend Priority = case(
isnotempty(EventType) and AssetCriticality in~ ("critical","high"), "high",
RouteProfile in~ ("rewrite-heavy","authentication","api","administrative","customer-facing"), "high",
Environment =~ "production", "medium",
"triage"
)
| project
EventTime,
SubscriptionId,
ResourceGroup,
ResourceName,
ResourceType,
Location,
SourceIp,
ForwardedFor,
UserAgent,
HttpMethod,
HostHeader,
UriPath,
QueryString,
StatusCode,
BackendStatusCode,
Environment,
WorkloadOwner,
AssetCriticality,
RouteProfile,
EventType,
ErrorMessage,
Priority
Rule 2
Post-Exploitation Azure Workload, Managed Identity, and Control-Plane Activity After Suspected NGINX Exploit-Path Activity
Rule Format
· Azure Activity Logs, Microsoft Entra ID, Defender for Cloud, Defender for Endpoint, Key Vault, Storage, AKS, VM, NGINX error-log, and workload-to-managed-identity Sentinel KQL correlation pattern.
Detection Purpose
· Detect Azure workload, managed identity, service principal, metadata, or control-plane behavior that may follow successful exploitation of Azure-hosted NGINX-backed infrastructure.
· Identify cloud-side blast-radius indicators such as managed identity use, service principal activity, role assignment changes, Key Vault access, Storage access, VM Run Command execution, AKS credential or cluster access, network security group modification, disk snapshot activity, extension changes, or other control-plane activity after suspected NGINX exploit-path activity.
· Prioritize activity from managed identities, service principals, VM identities, AKS node identities, workload identities, or containerized workloads associated with exposed NGINX-backed services.
· Treat the alert as stronger when paired with suspicious NGINX request activity, NGINX service instability, workload process execution, credential access, Defender for Cloud alerts, Defender for Endpoint evidence, or unusual egress.
· This rule does not detect the exploit primitive directly.
Detection Logic
· Identify suspicious Azure API activity from managed identities, service principals, workload identities, or caller identities associated with NGINX-backed workloads.
· Prioritize Authorization, Key Vault, Storage, Compute, Network, AKS, Managed Identity, and VM Run Command activity occurring after suspected NGINX exploit-path activity, Defender alerts, suspicious metadata access, abnormal source IP, unusual user agent, or unexpected session behavior.
· Increase priority when the managed identity belongs to an internet-facing NGINX service, NGINX reverse proxy, AKS NGINX ingress workload, VM-hosted NGINX service, VMSS-hosted NGINX tier, gateway tier, or high-value production workload.
· Increase priority when the activity includes role assignment changes, Key Vault secret access, Storage key access, Storage object access, VM Run Command, VM extension changes, AKS credential access, network security group changes, disk snapshot activity, or managed identity assignment changes.
· Treat the alert as stronger when paired with host-level process execution, abnormal privilege transition, suspicious child-process behavior, file staging, credential access, outbound egress, or NGINX error-log instability.
· Do not label Azure control-plane activity as confirmed NGINX Rift exploitation without workload-side or host-side corroboration.
· Suppress approved automation, deployment systems, observability systems, backup workflows, security tooling, maintenance windows, and known administrative identity use before escalation.
Required Telemetry
· Azure Activity Logs.
· Microsoft Entra ID audit logs where available.
· Microsoft Entra ID sign-in logs where available.
· Defender for Cloud alerts where available.
· Defender for Endpoint telemetry where available.
· Key Vault diagnostic logs where enabled.
· Storage diagnostic logs where enabled.
· AKS audit logs where applicable.
· Azure Resource Graph inventory.
· VM and VMSS inventory.
· Managed identity and service principal mapping.
· NGINX-backed workload inventory.
· Azure Front Door, Application Gateway, WAF, and NGINX exploit-path context.
· Source IP.
· User agent where available.
· Caller identity.
· App ID where available.
· Service principal ID where available.
· Managed identity resource ID where available.
· Operation name.
· Resource provider.
· Resource group.
· Subscription.
· Request status.
· Key Vault, Storage, AKS, Compute, Network, Authorization, and Managed Identity event visibility.
· Approved cloud automation source IPs, user agents, managed identities, service principals, subscriptions, and maintenance context.
· Host compromise or endpoint telemetry enrichment where available.
Engineering Implementation Instructions
· Map managed identities, service principals, VM identities, VMSS identities, AKS node identities, and workload identities back to VMs, VMSS instances, AKS nodes, ingress controllers, reverse proxies, gateways, and high-value NGINX-backed services.
· Validate Azure Activity Log coverage across all relevant tenants, management groups, subscriptions, and resource groups.
· Validate Microsoft Entra ID audit and sign-in visibility for service principals and managed identities where available.
· Validate diagnostic logging for Key Vault, Storage, AKS, VM, Network, and other sensitive resources where required and operationally approved.
· Enable and aggregate Defender for Cloud alerts where available.
· Establish expected identity behavior for production NGINX workloads, ingress workloads, gateway services, AKS node pools, CI systems, deployment identities, backup identities, observability identities, and VM Run Command or VM extension usage.
· Prioritize activity from NGINX-backed workloads where unusual API behavior follows suspicious request activity, service instability, workload process execution, or unusual egress.
· Add allowlists for approved automation, deployment systems, backup jobs, observability systems, security tooling, maintenance windows, and known administrative identity use.
· Correlate with host, workload, Defender for Endpoint, or NGINX telemetry before declaring suspected NGINX Rift exploitation.
Production-Readiness Requirements
· Validate Azure Activity Log coverage, Microsoft Entra ID audit logs, sign-in logs, Defender for Cloud alerts, Defender for Endpoint telemetry, Key Vault diagnostic logs, Storage diagnostic logs, and AKS audit logs across all relevant tenants, management groups, subscriptions, and resource groups.
· Validate exact Sentinel and Log Analytics table names, OperationNameValue fields, caller fields, managed identity fields, service principal fields, app ID fields, resource ID fields, request status fields, source IP fields, user agent fields, and properties parsing.
· Validate managed identity and service-principal joins for VMs, VMSS instances, AKS nodes, workload identities, reverse proxies, ingress services, gateways, and NGINX-backed workloads.
· Validate approved automation identities, deployment identities, backup identities, observability identities, maintenance windows, security-tooling identities, and administrative identity baselines.
· Validate exploit-path correlation inputs from Front Door, Application Gateway, WAF, NGINX logs, service-instability events, Defender for Endpoint, egress telemetry, and Defender for Cloud alerts.
· Validate false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on environment size, Azure tenant and subscription coverage, Sentinel workspace design, Activity Log maturity, Entra ID visibility, managed identity mapping quality, AKS visibility, NGINX workload inventory, cloud context, Linux telemetry maturity, CI/CD exposure, and SOC operating model. Scaling must not weaken the behavioral evidence requirement for suspected NGINX Rift exploitation.
DRI Assessment
DRI
8.4 / 10
· The rule is anchored to post-exploitation cloud activity and managed-identity-use behavior rather than static exploit artifacts.
· The rule remains useful if the initial exploit request changes because it focuses on cloud-side consequences of compromised NGINX-backed workload identities.
· The score is constrained because Azure control-plane events do not directly prove the NGINX exploit path.
· The rule is strong when tied to NGINX-backed workload context, request-shape evidence, service-instability evidence, and host or workload compromise indicators.
TCR Assessment
Operational TCR
7.6 / 10
Full-Telemetry TCR
8.7 / 10
· Operational confidence depends on Azure Activity Log coverage, Microsoft Entra ID visibility, Defender coverage, managed identity mapping, workload attribution, approved automation baselines, and enrichment quality.
· Operational confidence is reduced where managed identity attribution, user-agent visibility, diagnostic logging coverage, AKS workload identity mapping, or Sentinel workspace coverage varies across tenants or subscriptions.
· Full-telemetry confidence improves when Activity Logs, Defender, Resource Graph, Entra ID, AKS, Key Vault, Storage, managed identity mapping, NGINX logs, egress telemetry, and host telemetry are centrally correlated.
Limitations
· Azure control-plane activity may follow many compromise paths and is not unique to NGINX Rift.
· Azure Activity Logs cannot directly observe local NGINX exploitation, memory corruption, local process execution, or workload compromise.
· Legitimate automation, deployment pipelines, VM Run Command activity, backup operations, observability tooling, and security tooling may generate overlapping control-plane activity.
· Managed identity and service principal mapping must be accurate to connect cloud activity to NGINX-backed workloads.
· Host or workload telemetry is required for high-confidence NGINX Rift exploitation assessment.
Detection Query Pattern
// Sentinel / Log Analytics / Azure Activity / Resource Graph KQL pattern.
// Table names and field names must be adapted to the customer workspace, connector design, diagnostic settings, and enrichment model.
let NginxWorkloadIdentities =
AzureNginxManagedIdentityMap
| where NginxRole in~ (
"internet-facing-nginx",
"reverse-proxy",
"ingress-controller",
"gateway",
"waf-adjacent-nginx"
)
| project
ManagedIdentityPrincipalId,
ServicePrincipalId,
AppId,
ResourceId = tolower(ResourceId),
SubscriptionId,
ResourceGroup,
ResourceName,
Environment,
WorkloadOwner,
AssetCriticality,
WorkloadType,
NginxRole,
LastSuspectedRequestTime,
LastServiceInstabilityTime;
let SuspiciousAzureActivity =
AzureActivity
| where OperationNameValue in~ (
"Microsoft.Authorization/roleAssignments/write",
"Microsoft.Authorization/roleDefinitions/write",
"Microsoft.Compute/virtualMachines/runCommand/action",
"Microsoft.Compute/virtualMachines/extensions/write",
"Microsoft.Network/networkSecurityGroups/securityRules/write",
"Microsoft.Compute/snapshots/write",
"Microsoft.Compute/disks/write",
"Microsoft.ContainerService/managedClusters/listClusterUserCredential/action",
"Microsoft.ContainerService/managedClusters/listClusterAdminCredential/action",
"Microsoft.KeyVault/vaults/secrets/read",
"Microsoft.Storage/storageAccounts/listKeys/action",
"Microsoft.ManagedIdentity/userAssignedIdentities/assign/action"
)
| where ActivityStatusValue in~ ("Success", "Succeeded", "Accepted")
| project
TimeGenerated,
SubscriptionId,
ResourceGroup,
ResourceId = tolower(ResourceId),
OperationNameValue,
Caller,
CallerIpAddress,
ActivityStatusValue,
CorrelationId,
Properties;
SuspiciousAzureActivity
| join kind=inner NginxWorkloadIdentities on SubscriptionId
| where Caller in~ (ManagedIdentityPrincipalId, ServicePrincipalId, AppId)
| where isnotempty(LastSuspectedRequestTime)
or isnotempty(LastServiceInstabilityTime)
| where CallerIpAddress !in~ (dynamic(["<approved_admin_ip_1>", "<approved_admin_ip_2>"]))
| extend Priority = case(
AssetCriticality in~ ("critical","high"), "high",
WorkloadType in~ ("aks-node","container-host","ci-runner"), "high",
Environment =~ "production", "medium",
"triage"
)
| project
TimeGenerated,
SubscriptionId,
ResourceGroup,
OperationNameValue,
Caller,
CallerIpAddress,
ActivityStatusValue,
ResourceId,
ResourceName,
Environment,
WorkloadOwner,
AssetCriticality,
WorkloadType,
NginxRole,
Priority,
CorrelationId,
Properties
Rule 3
Unusual Azure Egress, Backend Access, or Metadata Activity After Suspected NGINX Exploit-Path Activity
Rule Format
· Sentinel KQL, NSG Flow Logs, Azure Firewall logs, DNS logs, Defender for Cloud, NGINX, and workload-to-destination correlation pattern.
Detection Purpose
· Detect unusual egress, backend access, DNS activity, metadata access, or internal service probing from Azure-hosted NGINX-backed infrastructure after suspected exploit-path request activity or service instability.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, backend probing, internal service discovery, metadata credential access, data transfer, Key Vault access pathing, Storage access pathing, or sensitive dependency access.
· Prioritize traffic from internet-facing NGINX-backed services, AKS NGINX ingress workloads, VM-hosted reverse proxies, VMSS-hosted gateways, and WAF-adjacent NGINX systems.
· Treat the alert as stronger when paired with suspicious request activity, NGINX worker instability, suspicious workload execution, Defender alerts, Azure Activity anomalies, or sensitive backend access.
· This rule does not prove exploitation by itself.
Detection Logic
· Identify outbound, east-west, backend, metadata, or DNS activity from NGINX-backed Azure workloads.
· Prioritize traffic to rare destinations, newly observed destinations, dynamic DNS, temporary hosting, paste services, file-sharing services, tunneling services, unapproved cloud services, direct IP destinations, unusual ports, or unknown external destinations.
· Prioritize internal access to backend applications, internal APIs, databases, identity services, AKS APIs, Azure Instance Metadata Service endpoints, Key Vault endpoints, Storage endpoints, container registry endpoints, CI/CD systems, artifact repositories, management interfaces, administrative services, or regulated data paths.
· Increase priority when the activity occurs after suspicious request-shape activity, NGINX service instability, workload process execution, credential access, mounted-secret access, Defender for Cloud alerts, Defender for Endpoint alerts, or Azure Activity anomalies.
· Increase priority when similar destination activity appears across multiple NGINX-backed assets after similar exploit-path indicators.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, health checks, deployment automation, security tooling, approved Azure API use, and known operational maintenance.
· Do not classify egress, backend access, metadata access, or DNS activity as confirmed compromise without corroborating exploit-path context, process lineage, file activity, credential access, Activity Log evidence, managed identity anomalies, AKS telemetry, application anomalies, or validated data-flow evidence.
Required Telemetry
· NSG Flow Logs where available.
· Azure Firewall logs where available.
· DNS logs where enabled.
· Proxy events where available.
· Defender for Cloud alerts where available.
· Defender for Endpoint network telemetry where available.
· Azure Activity Logs.
· Key Vault diagnostic logs where enabled.
· Storage diagnostic logs where enabled.
· NGINX access logs.
· NGINX error logs.
· Azure Front Door logs where available.
· Application Gateway logs where available.
· Source IP.
· Source NIC.
· Source VM, VMSS instance, pod, namespace, node, or workload identity where available.
· Source managed identity where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Session duration.
· Byte count.
· Connection count.
· DNS query name where available.
· Destination reputation where available.
· Destination category where available.
· Destination first-seen timestamp where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, Azure API, and service-mesh destinations.
· Prior suspicious inbound request context.
· NGINX service-instability context.
· Workload process correlation where available.
· Azure Activity correlation where available.
· Change-management, testing, incident-response, service-owner, deployment, and maintenance-window context.
Engineering Implementation Instructions
· Map NSG Flow Log source IPs, NICs, VM IDs, VMSS instance IDs, AKS node IPs, pod IPs, and workload identities back to NGINX-backed workloads.
· Build Azure source groups for internet-facing NGINX VMs, VMSS NGINX services, AKS NGINX ingress workloads, reverse proxies, gateways, WAF-adjacent NGINX services, and containerized NGINX workloads.
· Build approved destination maps for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and approved Azure APIs.
· Build sensitive destination maps for backend applications, internal APIs, databases, identity services, AKS APIs, Azure Instance Metadata Service endpoints, Key Vault, Storage, container registry, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Correlate unusual egress, backend access, metadata access, and DNS activity with suspicious request activity, NGINX error logs, crash artifacts, suspicious child-process execution, file telemetry, credential access, Defender alerts, Azure Activity events, and application anomalies.
· Use shorter correlation windows for exploit-path request activity followed by immediate rare-destination egress, backend probing, metadata access, DNS activity, or suspicious outbound communication.
· Use moderate correlation windows for worker instability followed by unusual egress, backend access, metadata access, or internal service discovery.
· Use longer correlation windows for delayed callback, repeated destination contact, repeated backend probing, token reuse, cloud access, or repeated behavior across multiple NGINX-backed assets.
· Avoid broad suppression for Azure services, cloud providers, package repositories, service mesh infrastructure, observability systems, or upstream applications because attacker activity may use the same infrastructure categories.
· Validate converted query syntax, source asset mapping, NIC-to-workload mapping, managed identity mapping, destination enrichment, dependency maps, network directionality, NAT behavior, service mesh behavior, DNS visibility, timing-window behavior, and environment-specific allowlists before production deployment.
Production-Readiness Requirements
· Validate NSG Flow Log coverage, Azure Firewall logging, DNS logging, NAT architecture, service mesh behavior, proxy behavior, and network directionality for all NGINX-backed Azure workloads.
· Validate exact Sentinel and Log Analytics table names, NSG Flow Log fields, Azure Firewall fields, DNS fields, NIC fields, source IP fields, pod IP mappings, VM ID joins, VMSS instance joins, timestamp parsing, byte-count fields, packet fields, DNS query fields, and destination enrichment fields.
· Validate NIC-to-workload joins for VMs, VMSS instances, AKS nodes, pod IPs, namespaces, managed identities, resource groups, and service owners.
· Validate destination enrichment, approved destination lists, backend dependency maps, sensitive destination maps, metadata endpoint detection, approved Azure API destinations, and service-owner baselines.
· Validate exploit-path correlation inputs from Front Door, Application Gateway, WAF, NGINX logs, service-instability events, workload process telemetry, Azure Activity events, Defender for Cloud alerts, and Defender for Endpoint telemetry.
· Validate false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on NSG Flow Log coverage, DNS logging, AKS workload mapping, NIC attribution, NGINX workload inventory, NAT architecture, service mesh design, destination enrichment, cloud context, and SOC operating model. Scaling must not weaken the requirement for exploit-path or workload-side correlation before suspected NGINX Rift exploitation is declared.
DRI Assessment
DRI
8.0 / 10
· The rule is anchored to unusual egress, backend access, metadata activity, and DNS behavior after suspected NGINX exploit-path indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, backend probing, metadata access, internal service discovery, or data-transfer behavior.
· The score is supported by source workload context, destination novelty, destination sensitivity, dependency deviation, timing, prior exploit-path context, and correlation with process, file, Defender, Azure Activity, AKS, or application telemetry.
· The score is constrained by normal NGINX upstream communication, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, and limited process-to-network attribution.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
8.6 / 10
· Operational confidence depends on NSG Flow Log coverage, DNS visibility, NIC-to-workload mapping, AKS source attribution, destination enrichment, dependency baselines, sensitive-destination mapping, NGINX exploit-path correlation, and approved destination baselines.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX workloads, NICs, pods, nodes, managed identities, or service identities.
· Full-telemetry confidence improves when network events are correlated with NGINX access logs, NGINX error logs, endpoint process lineage, file telemetry, crash telemetry, Front Door events, Application Gateway events, Defender alerts, Azure Activity events, AKS telemetry, application logs, and change-management context.
Limitations
· Unusual egress, backend access, metadata access, or DNS activity is not exploitation evidence by itself.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, metadata endpoints, and Azure APIs.
· NAT, service mesh, proxy chaining, Azure networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common Azure services, or communicate through permitted service dependencies.
· Confirmation requires correlation with exploit-path context, workload process lineage, file activity, credential access, managed identity anomalies, AKS activity, Azure Activity events, application anomalies, or validated data movement.
Detection Query Pattern
// Sentinel / Log Analytics / NSG Flow / DNS / workload enrichment pattern.
// Table names and field names must be adapted to the customer workspace, connector design, diagnostic settings, and enrichment model.
let NginxSources =
AzureNginxBackedWorkloadInventory
| where NginxRole in~ (
"internet-facing-nginx",
"reverse-proxy",
"ingress-controller",
"gateway",
"waf-adjacent-nginx"
)
| project
SubscriptionId,
ResourceGroup,
WorkloadId,
VmId,
VmssInstanceId,
PodName,
Namespace,
NicId,
PrivateIp,
ManagedIdentityPrincipalId,
ServiceName,
WorkloadType,
NginxRole,
AssetCriticality,
Environment,
LastSuspectedRequestTime,
LastServiceInstabilityTime;
let NetworkActivity =
AzureNetworkAnalytics_CL
| extend
FlowTime = TimeGenerated,
SourceIp = tostring(SrcIp_s),
DestinationIp = tostring(DestIp_s),
DestinationPort = toint(DestPort_d),
Protocol = tostring(Protocol_s),
Action = tostring(FlowStatus_s),
Bytes = tolong(Bytes_d),
NicId = tostring(NIC_s),
Direction = tostring(FlowDirection_s)
| where Action in~ ("Allowed", "Allow");
let DnsActivity =
DnsEvents
| extend
QueryTime = TimeGenerated,
SourceIp = tostring(ClientIP),
QueryName = tostring(Name),
ResponseCode = tostring(ResultCode);
let DestinationContext =
AzureDestinationEnrichment
| project
DestinationIp,
DestinationDomain,
DestinationCategory,
DestinationAssetType,
ApprovedContext,
FirstSeenTime,
Sensitivity;
NetworkActivity
| join kind=inner NginxSources on $left.NicId == $right.NicId
| join kind=leftouter DnsActivity on SourceIp
| where isempty(QueryTime)
or QueryTime between (FlowTime - 5m .. FlowTime + 5m)
| join kind=leftouter DestinationContext on DestinationIp
| where isnotempty(LastSuspectedRequestTime)
or isnotempty(LastServiceInstabilityTime)
| where isempty(ApprovedContext)
or ApprovedContext !in~ (
"approved_upstream_application",
"approved_observability_destination",
"approved_log_forwarding_destination",
"approved_package_repository",
"approved_update_repository",
"approved_security_tool",
"approved_service_mesh",
"approved_management_destination",
"approved_backend_health_check",
"approved_azure_api_use"
)
| where DestinationCategory in~ (
"rare_destination",
"newly_observed_destination",
"dynamic_dns",
"temporary_hosting",
"paste_service",
"file_sharing",
"tunneling",
"unknown_external"
)
or DestinationAssetType in~ (
"database",
"identity_service",
"key_vault",
"metadata_endpoint",
"management_interface",
"regulated_data_path"
)
or DestinationPort !in (80, 443, 53, 123)
or Bytes >= 10485760
| extend Priority = case(
DestinationAssetType in~ ("database","identity_service","key_vault","metadata_endpoint","management_interface","regulated_data_path"), "high",
DestinationCategory in~ ("rare_destination","newly_observed_destination","dynamic_dns","temporary_hosting","paste_service","file_sharing","tunneling","unknown_external"), "high",
AssetCriticality in~ ("critical","high"), "medium",
"triage"
)
| project
FlowTime,
SubscriptionId,
ResourceGroup,
ServiceName,
WorkloadType,
NginxRole,
VmId,
VmssInstanceId,
PodName,
Namespace,
ManagedIdentityPrincipalId,
SourceIp,
DestinationIp,
DestinationPort,
Protocol,
Bytes,
QueryName,
DestinationDomain,
DestinationCategory,
DestinationAssetType,
Sensitivity,
Priority
GCP
Required GCP Data Sources and Field Assumptions
· Google Cloud Armor logs where GCP-exposed NGINX-backed services are protected by Cloud Armor.
· External HTTP(S) Load Balancer logs where GCP-exposed NGINX-backed services are fronted by Google Cloud load balancing.
· NGINX access logs and NGINX error logs exported to Cloud Logging, BigQuery, Cloud Storage, Chronicle, or the customer SIEM.
· Security Command Center findings where available for suspicious VM behavior, anomalous service account use, compromised resource indicators, public exposure, workload risk context, or cloud-side correlation evidence.
· VM Manager vulnerability and inventory findings where available for Compute Engine and Linux workload context.
· Cloud Asset Inventory for Compute Engine instance, instance template, managed instance group, image, service account, project, folder, organization, network, firewall, load balancer, label, exposure, ownership, and workload context.
· Compute Engine metadata and labels for workload owner, environment, internet exposure, business criticality, production status, attached service account, and NGINX role context.
· GKE inventory where applicable, including cluster name, node pool, node service account, namespace ownership, workload identity context, ingress controller context, and workload criticality.
· Cloud Audit Logs for IAM, service accounts, Compute Engine, GKE, Secret Manager, Cloud KMS, Cloud Storage, firewall, load balancing, and control-plane activity.
· Data Access logs for Secret Manager, Cloud Storage, Cloud KMS, and other sensitive services where required and operationally approved.
· VPC Flow Logs for outbound, east-west, backend, and metadata-path visibility where enabled.
· Cloud DNS logs where DNS visibility is enabled.
· Service account mapping that links service accounts, workload identities, Compute Engine instances, GKE nodes, GKE workloads, container hosts, ingress workloads, reverse proxies, gateways, CI runners, and high-value NGINX-backed services.
· Approved automation context for expected source IPs, scanners, user agents, service accounts, deployment systems, observability systems, backup workflows, security tooling, and maintenance windows.
· All query patterns must be adapted to the customer’s GCP organization structure, folder hierarchy, project model, Security Command Center tier, VM Manager coverage, Cloud Asset Inventory export schema, Cloud Armor and load-balancer logging model, GKE architecture, service account model, audit log coverage, Data Access logging posture, NGINX logging model, SIEM export format, and approved automation baseline before deployment.
Rule 1
GCP-Exposed NGINX Rewrite-Path Request and Service-Instability Prioritization
Rule Format
· BigQuery, Google Cloud Armor, External HTTP(S) Load Balancer, Cloud Asset Inventory, Cloud Logging, Security Command Center, and NGINX log enrichment query pattern for exposed NGINX-backed request-shape and instability prioritization.
Detection Purpose
· Identify GCP-exposed NGINX-backed services receiving suspicious request-shape activity consistent with rewrite-path probing, malformed request delivery, route-specific request variation, request-shape fuzzing, or exploit-path adaptation.
· Prioritize suspicious request activity where the target is internet-facing, business-critical, Cloud Armor-protected, load-balancer-exposed, GKE ingress-backed, Compute Engine-hosted, managed-instance-group-hosted, or tied to high-value application routes.
· Increase priority when suspicious request activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, route-specific 500-series spikes, load-balancer backend 5xx spikes, upstream reset behavior, GKE pod restarts, Compute Engine service instability, or NGINX-backed service degradation.
· Support triage, hunt scoping, workload owner notification, route review, patch validation, host telemetry collection, and escalation into workload or cloud-control-plane correlation.
· This rule does not detect confirmed exploitation by itself.
Detection Logic
· Identify Cloud Armor, External HTTP(S) Load Balancer, GKE ingress, or NGINX access-log events targeting GCP-exposed NGINX-backed infrastructure.
· Correlate request activity with Cloud Asset Inventory, Compute Engine, GKE, load balancer, backend service, instance group, firewall, public IP, service account, and label context to confirm that the destination service is NGINX-backed and externally reachable.
· Detect suspicious request-shape indicators such as abnormal URI length, repeated encoding, abnormal delimiter density, malformed path structure, abnormal path expansion, suspicious query structure, uncommon methods, ambiguous request parsing, or request-normalization failure.
· Increase priority when the request targets rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream application routes.
· Increase priority when the same source, ASN, hosting provider, route pattern, user agent, or request shape appears across multiple NGINX-backed assets, load balancers, projects, folders, organizations, or regions.
· Increase priority when suspicious request activity aligns with NGINX error-log instability, load-balancer backend errors, GKE pod restarts, Compute Engine service instability, or application health degradation.
· Use request-shape and instability evidence as exploitation-priority evidence only.
· Require workload telemetry, process telemetry, outbound egress, GCP control-plane activity, Security Command Center findings, endpoint evidence, or other corroborating behavior before labeling the case as suspected exploitation.
· Suppress approved vulnerability scanning, patch validation, QA testing, synthetic monitoring, load balancer probes, CDN health checks, sanctioned security testing, and documented incident-response activity before escalation.
Required Telemetry
· Google Cloud Armor logs where applicable.
· External HTTP(S) Load Balancer logs.
· GKE ingress logs where applicable.
· NGINX access logs.
· NGINX error logs.
· Cloud Asset Inventory exports.
· Compute Engine VM metadata and labels.
· Managed instance group context where applicable.
· GKE cluster, ingress, node, pod, namespace, and workload identity context where applicable.
· Load balancer forwarding rule, URL map, backend service, backend bucket, instance group, NEG, and backend target mapping.
· Public IP and DNS mapping where available.
· Route or application mapping where available.
· Source IP.
· Forwarded IP.
· ASN.
· Geolocation.
· User agent.
· Request method.
· URI.
· Query string.
· Host header.
· Status code.
· Backend status code.
· Request duration.
· Backend response latency.
· NGINX worker crash indicators.
· NGINX segmentation fault indicators.
· NGINX abnormal worker exit indicators.
· NGINX upstream reset indicators.
· Route-specific 500-series indicators.
· Service-degradation indicators.
· Approved scanner, synthetic monitoring, patch validation, load balancer probe, CDN health check, QA, testing, incident-response, and security-tooling context.
Engineering Implementation Instructions
· Confirm Cloud Armor, External HTTP(S) Load Balancer, GKE ingress, and NGINX log coverage for all internet-facing NGINX-backed services.
· Confirm Cloud Asset Inventory and workload inventory coverage across relevant organizations, folders, projects, and regions.
· Map load balancers, URL maps, backend services, network endpoint groups, instance groups, GKE ingress services, Compute Engine instances, and managed instance groups back to NGINX-backed application owners.
· Build route maps for rewrite-heavy routes, authentication paths, API paths, gateway paths, ingress paths, administrative portals, customer-facing virtual hosts, and high-dependency upstream routes.
· Normalize forwarded-IP handling so source attribution is not confused by Cloud Armor, external load balancers, proxies, NAT, CDN layers, or service mesh behavior.
· Parse NGINX error logs for worker instability, segmentation fault indicators, abnormal worker exits, reload failures, upstream resets, and route-specific service degradation.
· Join suspicious request activity to NGINX error-log and GCP workload-health indicators within a short request-to-instability correlation window.
· Add allowlists for approved scanners, synthetic monitoring, QA testing, patch validation, load balancer probes, CDN health checks, approved security testing, and incident-response activity.
· Do not generate an exploitation alert from malformed requests, NGINX exposure, vulnerable-version context, or service instability alone.
· Use this rule to drive triage priority, route review, host telemetry collection, workload owner notification, and correlation with post-request workload or cloud activity.
Production-Readiness Requirements
· Validate GCP organization, folder, project, region, and logging-sink coverage for all GCP-exposed NGINX-backed services.
· Validate Cloud Armor, External HTTP(S) Load Balancer, GKE ingress, NGINX access-log, and NGINX error-log availability.
· Validate exact BigQuery dataset and table names, Cloud Logging export schema, timestamp parsing, URI fields, forwarded-IP fields, Cloud Armor action fields, backend service fields, load balancer fields, URL map fields, NEG fields, and NGINX error-log parsing.
· Validate Cloud Asset Inventory joins for load balancers, URL maps, backend services, instance groups, network endpoint groups, GKE ingress services, Compute Engine instances, managed instance groups, hostnames, service ownership, route profiles, and internet-facing status.
· Validate approved scanner lists, synthetic monitoring sources, load balancer probe sources, CDN health checks, patch-validation sources, QA sources, and incident-response sources.
· Validate request-to-instability correlation windows, false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on GCP project coverage, Cloud Armor and load-balancer logging maturity, NGINX log availability, GKE visibility, Compute Engine and managed-instance-group visibility, route inventory quality, workload criticality, exposed-service volume, and SOC operating model. Scaling must not weaken the requirement for corroborating behavior before suspected NGINX Rift exploitation is declared.
DRI Assessment
DRI
8.0 / 10
· The rule is anchored to suspicious request-shape activity and service-instability correlation against GCP-exposed NGINX-backed infrastructure.
· The score is constrained because request-shape and instability signals do not prove successful exploitation.
· The rule is resilient to exploit modification because it does not rely on proof-of-concept strings or a single static request fragment.
· The rule remains valuable for prioritizing exposed services, hunt scoping, route review, telemetry collection, and escalation into workload or cloud-control-plane analysis.
TCR Assessment
Operational TCR
7.8 / 10
Full-Telemetry TCR
8.8 / 10
· Operational confidence depends on Cloud Armor logging, External HTTP(S) Load Balancer logging, NGINX access-log fidelity, NGINX error-log fidelity, Cloud Asset Inventory accuracy, route mapping, scanner allowlists, source attribution, and finding freshness.
· Operational confidence is reduced where Cloud Armor, load balancers, ingress, gateway, proxy, CDN layers, or service mesh layers normalize, truncate, rewrite, aggregate, or discard malformed request attributes.
· Full-telemetry confidence improves when Cloud Armor, load balancer logs, NGINX access logs, NGINX error logs, GKE, Compute Engine, Cloud Asset Inventory, route context, workload ownership, Security Command Center, and endpoint telemetry are centrally correlated.
Limitations
· Suspicious request-shape activity is not exploitation evidence by itself.
· NGINX worker instability, load-balancer backend errors, GKE pod restarts, Compute Engine service instability, and upstream resets may result from benign application bugs, deployment activity, dependency failures, resource pressure, scaling events, misconfiguration, package updates, or maintenance.
· Cloud Armor, load balancers, ingress, gateway, proxy, CDN, or service mesh normalization may obscure original request shape.
· Forwarded-IP handling may complicate source attribution.
· Missing NGINX error logs may prevent confirmation of service-instability correlation.
· Missing route inventory may prevent accurate prioritization of vulnerable or high-risk routes.
· Workload telemetry is required to assess whether exploitation likely occurred.
Detection Query Pattern
-- BigQuery / Cloud Armor / Load Balancer / Cloud Asset Inventory / NGINX enrichment pattern.
-- Table and field names must be adapted to the customer logging export and enrichment model.
WITH suspicious_requests AS (
SELECT
timestamp,
project_id,
resource_name,
source_ip,
forwarded_for,
user_agent,
http_method,
host_header,
uri_path,
query_string,
status_code,
backend_status_code,
request_latency,
backend_latency,
forwarding_rule,
url_map,
backend_service,
action
FROM gcp_edge_http_logs
WHERE (
LENGTH(uri_path) >= 1024
OR REGEXP_CONTAINS(uri_path, r'(%25|%2e|%2f|%5c|%u[0-9a-fA-F]{4})')
OR REGEXP_CONTAINS(uri_path, r'([/._-].){12,}')
OR REGEXP_CONTAINS(uri_path, r'(%2f.%2f|%252f|%255c|\.\.|//)')
OR REGEXP_CONTAINS(query_string, r'(\{|\}|\[|\]|%7b|%7d|%5b|%5d|;|\|)')
OR http_method NOT IN ('GET','POST','HEAD','OPTIONS','PUT','PATCH','DELETE')
)
AND source_ip NOT IN (
SELECT approved_source_ip
FROM approved_scanner_and_monitoring_sources
)
),
nginx_backed_assets AS (
SELECT
organization_id,
folder_id,
project_id,
resource_name,
asset_type,
instance_id,
backend_service,
url_map,
forwarding_rule,
hostname,
service_name,
workload_type,
workload_owner,
environment,
asset_criticality,
internet_facing,
route_profile,
labels
FROM gcp_nginx_backed_asset_inventory
WHERE internet_facing = true
),
service_instability AS (
SELECT
event_time,
project_id,
hostname,
service_name,
event_type,
error_message,
status_code,
route_path
FROM nginx_error_and_health_events
WHERE event_type IN (
'nginx_worker_crash',
'nginx_segmentation_fault',
'nginx_abnormal_worker_exit',
'nginx_reload_failure',
'route_specific_500_spike',
'load_balancer_backend_5xx_spike',
'upstream_reset_spike',
'gke_pod_restart',
'nginx_backed_service_degradation'
)
)
SELECT
sr.timestamp,
nba.organization_id,
nba.folder_id,
sr.project_id,
sr.source_ip,
sr.forwarded_for,
sr.user_agent,
sr.http_method,
sr.host_header,
sr.uri_path,
sr.query_string,
sr.status_code,
sr.backend_status_code,
nba.hostname,
nba.service_name,
nba.workload_type,
nba.workload_owner,
nba.environment,
nba.asset_criticality,
nba.route_profile,
si.event_type AS correlated_instability,
si.error_message AS instability_detail,
CASE
WHEN si.event_type IS NOT NULL
AND nba.asset_criticality IN ('critical','high') THEN 'high'
WHEN nba.route_profile IN ('rewrite-heavy','authentication','api','administrative','customer-facing') THEN 'high'
WHEN nba.environment = 'production' THEN 'medium'
ELSE 'triage'
END AS priority
FROM suspicious_requests sr
JOIN nginx_backed_assets nba
ON sr.project_id = nba.project_id
AND (
sr.backend_service = nba.backend_service
OR sr.url_map = nba.url_map
OR sr.forwarding_rule = nba.forwarding_rule
OR sr.host_header = nba.hostname
)
LEFT JOIN service_instability si
ON nba.project_id = si.project_id
AND nba.hostname = si.hostname
AND si.event_time BETWEEN sr.timestamp AND TIMESTAMP_ADD(sr.timestamp, INTERVAL 30 MINUTE);
Rule 2
Post-Exploitation GCP Workload, Service Account, and Control-Plane Activity After Suspected NGINX Exploit-Path Activity
Rule Format
· Cloud Audit Logs, Security Command Center, Data Access logs, Compute Engine, GKE, Secret Manager, Cloud Storage, Cloud KMS, NGINX error-log, and workload-to-service-account BigQuery correlation pattern.
Detection Purpose
· Detect GCP workload, service account, workload identity, metadata, or control-plane behavior that may follow successful exploitation of GCP-hosted NGINX-backed infrastructure.
· Identify cloud-side blast-radius indicators such as service account use, IAM policy modification, service account key creation, Secret Manager access, Cloud Storage access, Cloud KMS decrypt activity, GKE credential or cluster activity, Compute Engine metadata modification, firewall changes, disk snapshot or image activity, or other control-plane activity after suspected NGINX exploit-path activity.
· Prioritize activity from service accounts, workload identities, Compute Engine instances, GKE nodes, GKE workloads, or containerized workloads associated with exposed NGINX-backed services.
· Treat the alert as stronger when paired with suspicious NGINX request activity, NGINX service instability, workload process execution, credential access, Security Command Center findings, endpoint evidence, or unusual egress.
· This rule does not detect the exploit primitive directly.
Detection Logic
· Identify suspicious GCP API activity from service accounts, workload identities, or principal identities associated with NGINX-backed workloads.
· Prioritize IAM, service account, Secret Manager, Cloud Storage, Cloud KMS, GKE, Compute Engine, firewall, and control-plane activity occurring after suspected NGINX exploit-path activity, Security Command Center findings, suspicious metadata access, abnormal source IP, unusual user agent, or unexpected session behavior.
· Increase priority when the service account belongs to an internet-facing NGINX service, NGINX reverse proxy, GKE NGINX ingress workload, Compute Engine-hosted NGINX service, managed-instance-group-hosted NGINX tier, gateway tier, or high-value production workload.
· Increase priority when the activity includes IAM policy changes, service account key creation, Secret Manager access, Cloud Storage access, KMS decrypt, GKE credential or cluster access, Compute Engine metadata changes, firewall changes, disk snapshot activity, image creation, or service account privilege changes.
· Treat the alert as stronger when paired with host-level process execution, abnormal privilege transition, suspicious child-process behavior, file staging, credential access, outbound egress, or NGINX error-log instability.
· Do not label GCP control-plane activity as confirmed NGINX Rift exploitation without workload-side or host-side corroboration.
· Suppress approved automation, deployment systems, observability systems, backup workflows, security tooling, maintenance windows, and known administrative service account use before escalation.
Required Telemetry
· Cloud Audit Logs.
· Data Access logs for Secret Manager where enabled.
· Data Access logs for Cloud Storage where enabled.
· Data Access logs for Cloud KMS where enabled.
· Security Command Center findings where available.
· Cloud Asset Inventory exports.
· Compute Engine inventory.
· GKE inventory.
· Service account and workload identity mapping.
· NGINX-backed workload inventory.
· Cloud Armor, load-balancer, GKE ingress, and NGINX exploit-path context.
· Source IP.
· User agent where available.
· Principal email.
· Service account email.
· Authentication info.
· Method name.
· Service name.
· Resource name.
· Project ID.
· Request metadata.
· Status.
· Secret Manager, Cloud Storage, Cloud KMS, GKE, Compute Engine, IAM, service account, and firewall event visibility.
· Approved cloud automation source IPs, user agents, service accounts, projects, and maintenance context.
· Host compromise or endpoint telemetry enrichment where available.
Engineering Implementation Instructions
· Map service accounts, workload identities, Compute Engine attached service accounts, GKE node service accounts, and workload identity principals back to VMs, managed instance groups, GKE nodes, ingress controllers, reverse proxies, gateways, and high-value NGINX-backed services.
· Validate Cloud Audit Logs coverage across all relevant organizations, folders, and projects.
· Validate Data Access logs for Secret Manager, Cloud Storage, Cloud KMS, and other sensitive services where required and operationally approved.
· Enable and aggregate Security Command Center findings where available.
· Establish expected service account behavior for production NGINX workloads, ingress workloads, gateway services, GKE node pools, CI systems, deployment identities, backup identities, observability identities, and managed workloads.
· Prioritize activity from NGINX-backed workloads where unusual API behavior follows suspicious request activity, service instability, workload process execution, or unusual egress.
· Add allowlists for approved automation, deployment systems, backup jobs, observability systems, security tooling, maintenance windows, and known administrative identity use.
· Correlate with host, workload, endpoint, Security Command Center, or NGINX telemetry before declaring suspected NGINX Rift exploitation.
Production-Readiness Requirements
· Validate Cloud Audit Logs coverage, Data Access logs, Security Command Center findings, VM Manager coverage where applicable, Cloud Asset Inventory exports, GKE inventory, Secret Manager logs, Cloud Storage logs, and Cloud KMS logs across all relevant organizations, folders, and projects.
· Validate exact BigQuery dataset and table names, audit log export schema, protoPayload fields, authenticationInfo fields, principal email fields, service account fields, request metadata fields, method name fields, service name fields, resource name fields, status fields, and response parsing.
· Validate service-account and workload-identity joins for Compute Engine instances, managed instance groups, GKE nodes, GKE workloads, reverse proxies, ingress services, gateways, and NGINX-backed workloads.
· Validate approved automation service accounts, deployment service accounts, backup service accounts, observability service accounts, maintenance windows, security-tooling identities, and administrative service account baselines.
· Validate exploit-path correlation inputs from Cloud Armor, load balancer logs, NGINX logs, service-instability events, workload telemetry, egress telemetry, and Security Command Center findings.
· Validate false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on environment size, GCP organization and project coverage, Cloud Audit Logs maturity, Data Access logging posture, Security Command Center tier, service account mapping quality, GKE visibility, NGINX workload inventory, cloud context, Linux telemetry maturity, CI/CD exposure, and SOC operating model. Scaling must not weaken the behavioral evidence requirement for suspected NGINX Rift exploitation.
DRI Assessment
DRI
8.4 / 10
· The rule is anchored to post-exploitation cloud activity and service-account-use behavior rather than static exploit artifacts.
· The rule remains useful if the initial exploit request changes because it focuses on cloud-side consequences of compromised NGINX-backed workload identities.
· The score is constrained because GCP control-plane events do not directly prove the NGINX exploit path.
· The rule is strong when tied to NGINX-backed workload context, request-shape evidence, service-instability evidence, and host or workload compromise indicators.
TCR Assessment
Operational TCR
7.6 / 10
Full-Telemetry TCR
8.7 / 10
· Operational confidence depends on Cloud Audit Logs coverage, Data Access log coverage, Security Command Center coverage, service account mapping, workload attribution, approved automation baselines, and enrichment quality.
· Operational confidence is reduced where Data Access logging, user-agent visibility, service account attribution, diagnostic coverage, or GKE workload identity mapping varies across projects and organizations.
· Full-telemetry confidence improves when Cloud Audit Logs, Security Command Center, VM Manager, Cloud Asset Inventory, IAM, GKE, Secret Manager, Cloud Storage, Cloud KMS, service account mapping, NGINX logs, egress telemetry, and host telemetry are centrally correlated.
Limitations
· GCP control-plane activity may follow many compromise paths and is not unique to NGINX Rift.
· Cloud Audit Logs cannot directly observe local NGINX exploitation, memory corruption, local process execution, or workload compromise.
· Legitimate automation, deployment pipelines, backup operations, observability tooling, and security tooling may generate overlapping control-plane activity.
· Service account and workload identity mapping must be accurate to connect cloud activity to NGINX-backed workloads.
· Host or workload telemetry is required for high-confidence NGINX Rift exploitation assessment.
Detection Query Pattern
-- BigQuery / Cloud Audit Logs / Cloud Asset Inventory / workload identity correlation pattern.
-- Table names and field names must be adapted to the customer logging export and enrichment model.
WITH nginx_workload_identities AS (
SELECT
organization_id,
folder_id,
project_id,
resource_name,
instance_id,
service_account_email,
workload_identity_principal,
workload_type,
workload_owner,
environment,
asset_criticality,
internet_facing,
gke_cluster,
gke_node_pool,
nginx_role,
last_suspected_request_time,
last_service_instability_time
FROM gcp_nginx_backed_workload_service_account_map
WHERE nginx_role IN (
'internet-facing-nginx',
'reverse-proxy',
'ingress-controller',
'gateway',
'cloud-armor-adjacent-nginx'
)
),
suspicious_audit_activity AS (
SELECT
timestamp,
resource.labels.project_id AS project_id,
protoPayload.serviceName AS service_name,
protoPayload.methodName AS method_name,
protoPayload.authenticationInfo.principalEmail AS principal_email,
protoPayload.requestMetadata.callerIp AS caller_ip,
protoPayload.requestMetadata.callerSuppliedUserAgent AS user_agent,
protoPayload.resourceName AS resource_name,
protoPayload.status.code AS status_code,
protoPayload.request AS request,
protoPayload.response AS response
FROM gcp_cloud_audit_logs
WHERE protoPayload.serviceName IN (
'iam.googleapis.com',
'secretmanager.googleapis.com',
'storage.googleapis.com',
'cloudkms.googleapis.com',
'container.googleapis.com',
'compute.googleapis.com'
)
AND protoPayload.methodName IN (
'SetIamPolicy',
'google.iam.admin.v1.CreateServiceAccountKey',
'google.iam.admin.v1.SetIAMPolicy',
'google.cloud.secretmanager.v1.SecretManagerService.AccessSecretVersion',
'storage.objects.get',
'storage.objects.list',
'cloudkms.cryptoKeyVersions.useToDecrypt',
'google.container.v1.ClusterManager.GetCluster',
'google.container.v1.ClusterManager.GetServerConfig',
'v1.compute.instances.setMetadata',
'v1.compute.firewalls.insert',
'v1.compute.firewalls.patch',
'v1.compute.disks.createSnapshot',
'v1.compute.images.insert'
)
AND protoPayload.status.code = 0
)
SELECT
saa.timestamp,
nwi.organization_id,
nwi.folder_id,
saa.project_id,
saa.service_name,
saa.method_name,
saa.principal_email,
saa.caller_ip,
saa.user_agent,
saa.resource_name,
nwi.instance_id,
nwi.workload_type,
nwi.workload_owner,
nwi.environment,
nwi.asset_criticality,
nwi.internet_facing,
nwi.gke_cluster,
nwi.gke_node_pool,
nwi.nginx_role,
CASE
WHEN nwi.asset_criticality IN ('critical','high') THEN 'high'
WHEN nwi.workload_type IN ('gke-node','container-host','ci-runner') THEN 'high'
WHEN nwi.environment = 'production' THEN 'medium'
ELSE 'triage'
END AS priority
FROM suspicious_audit_activity saa
JOIN nginx_workload_identities nwi
ON saa.project_id = nwi.project_id
AND (
saa.principal_email = nwi.service_account_email
OR saa.principal_email = nwi.workload_identity_principal
)
WHERE (
nwi.last_suspected_request_time IS NOT NULL
OR nwi.last_service_instability_time IS NOT NULL
)
AND saa.caller_ip NOT IN (
SELECT approved_source_ip
FROM approved_gcp_admin_sources
)
AND saa.user_agent NOT IN (
SELECT approved_user_agent
FROM approved_gcp_automation_user_agents
);
Rule 3
Unusual GCP Egress, Backend Access, or Metadata Activity After Suspected NGINX Exploit-Path Activity
Rule Format
· BigQuery, VPC Flow Logs, Cloud DNS logs, Cloud Armor, load balancer logs, Security Command Center, NGINX, and workload-to-destination correlation pattern.
Detection Purpose
· Detect unusual egress, backend access, DNS activity, metadata access, or internal service probing from GCP-hosted NGINX-backed infrastructure after suspected exploit-path request activity or service instability.
· Identify possible callback, payload retrieval, command-and-control, tunneling, staging, backend probing, internal service discovery, metadata credential access, data transfer, Secret Manager access pathing, Cloud Storage access pathing, or sensitive dependency access.
· Prioritize traffic from internet-facing NGINX-backed services, GKE NGINX ingress workloads, Compute Engine-hosted reverse proxies, managed-instance-group-hosted gateways, and Cloud Armor-adjacent NGINX systems.
· Treat the alert as stronger when paired with suspicious request activity, NGINX worker instability, suspicious workload execution, Security Command Center findings, Cloud Audit Log anomalies, or sensitive backend access.
· This rule does not prove exploitation by itself.
Detection Logic
· Identify outbound, east-west, backend, metadata, or DNS activity from NGINX-backed GCP workloads.
· Prioritize traffic to rare destinations, newly observed destinations, dynamic DNS, temporary hosting, paste services, file-sharing services, tunneling services, unapproved cloud services, direct IP destinations, unusual ports, or unknown external destinations.
· Prioritize internal access to backend applications, internal APIs, databases, identity services, GKE APIs, Google metadata server endpoints, Secret Manager endpoints, Cloud KMS endpoints, Cloud Storage endpoints, Artifact Registry endpoints, CI/CD systems, artifact repositories, management interfaces, administrative services, or regulated data paths.
· Increase priority when the activity occurs after suspicious request-shape activity, NGINX service instability, workload process execution, credential access, mounted-secret access, Security Command Center findings, endpoint findings, or Cloud Audit Log anomalies.
· Increase priority when similar destination activity appears across multiple NGINX-backed assets after similar exploit-path indicators.
· Reduce severity for approved upstream applications, observability platforms, log forwarders, update repositories, package repositories, corporate proxies, service mesh endpoints, backend dependencies, health checks, deployment automation, security tooling, approved GCP API use, and known operational maintenance.
· Do not classify egress, backend access, metadata access, or DNS activity as confirmed compromise without corroborating exploit-path context, process lineage, file activity, credential access, Cloud Audit Log evidence, service account anomalies, GKE telemetry, application anomalies, or validated data-flow evidence.
Required Telemetry
· VPC Flow Logs where available.
· Cloud DNS logs where enabled.
· Proxy events where available.
· Firewall telemetry where available.
· Security Command Center findings where available.
· Endpoint network telemetry where available.
· Cloud Audit Logs.
· Data Access logs where relevant and enabled.
· NGINX access logs.
· NGINX error logs.
· Cloud Armor logs where available.
· External HTTP(S) Load Balancer logs where available.
· Source IP.
· Source NIC or network interface context where available.
· Source Compute Engine instance, managed instance group, GKE pod, namespace, node, or workload identity where available.
· Source service account where available.
· Destination IP.
· Destination hostname.
· Destination domain.
· Destination port.
· Protocol.
· Directionality.
· Session duration.
· Byte count.
· Connection count.
· DNS query name where available.
· Destination reputation where available.
· Destination category where available.
· Destination first-seen timestamp where available.
· Backend dependency mapping.
· Sensitive destination mapping.
· Approved NGINX egress baselines.
· Approved upstream application destinations.
· Approved observability, logging, security-tooling, update, repository, proxy, management, GCP API, and service-mesh destinations.
· Prior suspicious inbound request context.
· NGINX service-instability context.
· Workload process correlation where available.
· Cloud Audit Log correlation where available.
· Change-management, testing, incident-response, service-owner, deployment, and maintenance-window context.
Engineering Implementation Instructions
· Map VPC Flow Log source IPs, network interfaces, Compute Engine instance IDs, GKE node IPs, pod IPs, and workload identities back to NGINX-backed workloads.
· Build GCP source groups for internet-facing NGINX Compute Engine instances, managed-instance-group NGINX services, GKE NGINX ingress workloads, reverse proxies, gateways, Cloud Armor-adjacent NGINX services, and containerized NGINX workloads.
· Build approved destination maps for upstream applications, backend APIs, observability platforms, log forwarders, package repositories, update repositories, corporate proxies, security tooling, monitoring systems, service mesh endpoints, management endpoints, and approved GCP APIs.
· Build sensitive destination maps for backend applications, internal APIs, databases, identity services, GKE APIs, Google metadata server endpoints, Secret Manager, Cloud KMS, Cloud Storage, Artifact Registry, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Correlate unusual egress, backend access, metadata access, and DNS activity with suspicious request activity, NGINX error logs, crash artifacts, suspicious child-process execution, file telemetry, credential access, Security Command Center findings, Cloud Audit Log events, and application anomalies.
· Use shorter correlation windows for exploit-path request activity followed by immediate rare-destination egress, backend probing, metadata access, DNS activity, or suspicious outbound communication.
· Use moderate correlation windows for worker instability followed by unusual egress, backend access, metadata access, or internal service discovery.
· Use longer correlation windows for delayed callback, repeated destination contact, repeated backend probing, token reuse, cloud access, or repeated behavior across multiple NGINX-backed assets.
· Avoid broad suppression for GCP services, cloud providers, package repositories, service mesh infrastructure, observability systems, or upstream applications because attacker activity may use the same infrastructure categories.
· Validate converted query syntax, source asset mapping, network-interface-to-workload mapping, service account mapping, destination enrichment, dependency maps, network directionality, NAT behavior, service mesh behavior, DNS visibility, timing-window behavior, and environment-specific allowlists before production deployment.
Production-Readiness Requirements
· Validate VPC Flow Log coverage, Cloud DNS logging, NAT architecture, service mesh behavior, proxy behavior, and network directionality for all NGINX-backed GCP workloads.
· Validate exact BigQuery dataset and table names, VPC Flow Log fields, Cloud DNS fields, network interface fields, source IP fields, pod IP mappings, Compute Engine instance joins, managed instance group joins, timestamp parsing, byte-count fields, packet fields, DNS query fields, and destination enrichment fields.
· Validate network-interface-to-workload joins for Compute Engine instances, managed instance groups, GKE nodes, pod IPs, namespaces, service accounts, projects, folders, and service owners.
· Validate destination enrichment, approved destination lists, backend dependency maps, sensitive destination maps, metadata endpoint detection, approved GCP API destinations, and service-owner baselines.
· Validate exploit-path correlation inputs from Cloud Armor, load balancer logs, NGINX logs, service-instability events, workload process telemetry, Cloud Audit Logs, Security Command Center findings, and endpoint telemetry.
· Validate false-positive baselines, query performance, alert grouping, and SOC triage readiness before enabling production alerting.
Deployment Scaling Note
Deployment scope should be adjusted based on VPC Flow Log coverage, Cloud DNS logging, GKE workload mapping, network-interface attribution, NGINX workload inventory, NAT architecture, service mesh design, destination enrichment, cloud context, and SOC operating model. Scaling must not weaken the requirement for exploit-path or workload-side correlation before suspected NGINX Rift exploitation is declared.
DRI Assessment
DRI
8.0 / 10
· The rule is anchored to unusual egress, backend access, metadata activity, and DNS behavior after suspected NGINX exploit-path indicators.
· The rule remains useful if the initial exploit request changes but post-exploitation activity still produces callback, staging, tool retrieval, tunneling, backend probing, metadata access, internal service discovery, or data-transfer behavior.
· The score is supported by source workload context, destination novelty, destination sensitivity, dependency deviation, timing, prior exploit-path context, and correlation with process, file, Security Command Center, Cloud Audit Logs, GKE, or application telemetry.
· The score is constrained by normal NGINX upstream communication, NAT, service mesh abstraction, incomplete destination enrichment, missing dependency maps, and limited process-to-network attribution.
TCR Assessment
Operational TCR
7.5 / 10
Full-Telemetry TCR
8.6 / 10
· Operational confidence depends on VPC Flow Log coverage, Cloud DNS visibility, network-interface-to-workload mapping, GKE source attribution, destination enrichment, dependency baselines, sensitive-destination mapping, NGINX exploit-path correlation, and approved destination baselines.
· Operational confidence is reduced where outbound traffic is NATed, proxy-chained, service-mesh-obscured, aggregated, or not attributable to specific NGINX workloads, network interfaces, pods, nodes, service accounts, or service identities.
· Full-telemetry confidence improves when network events are correlated with NGINX access logs, NGINX error logs, endpoint process lineage, file telemetry, crash telemetry, Cloud Armor events, load-balancer events, Security Command Center findings, Cloud Audit Logs, GKE telemetry, application logs, and change-management context.
Limitations
· Unusual egress, backend access, metadata access, or DNS activity is not exploitation evidence by itself.
· NGINX infrastructure may legitimately communicate with upstream applications, backend APIs, observability platforms, security tools, service mesh endpoints, update repositories, management systems, metadata endpoints, and GCP APIs.
· NAT, service mesh, proxy chaining, GCP networking, Kubernetes networking, and container networking may obscure source workload identity.
· Missing dependency baselines may prevent accurate differentiation between legitimate upstream communication and suspicious egress or internal expansion.
· The rule may miss attacks that remain local, delay callbacks, use approved destinations, use common GCP services, or communicate through permitted service dependencies.
· Confirmation requires correlation with exploit-path context, workload process lineage, file activity, credential access, service account anomalies, GKE activity, Cloud Audit Logs, application anomalies, or validated data movement.
Detection Query Pattern
-- BigQuery / VPC Flow Logs / Cloud DNS / workload enrichment pattern.
-- Table names and field names must be adapted to the customer logging export and enrichment model.
WITH nginx_sources AS (
SELECT
organization_id,
folder_id,
project_id,
workload_id,
instance_id,
gke_cluster,
gke_node_pool,
pod_name,
namespace,
network_interface,
private_ip,
service_account_email,
service_name,
workload_type,
nginx_role,
asset_criticality,
environment,
last_suspected_request_time,
last_service_instability_time
FROM gcp_nginx_backed_workload_inventory
WHERE nginx_role IN (
'internet-facing-nginx',
'reverse-proxy',
'ingress-controller',
'gateway',
'cloud-armor-adjacent-nginx'
)
),
network_activity AS (
SELECT
start_time,
end_time,
project_id,
interface_id,
src_ip,
dest_ip,
dest_port,
protocol,
bytes_sent,
packets_sent,
connection_direction
FROM gcp_vpc_flow_logs
WHERE connection_direction IN ('OUTBOUND','EGRESS','INTERNAL')
),
dns_activity AS (
SELECT
query_time,
project_id,
source_ip,
query_name,
response_code
FROM gcp_cloud_dns_logs
),
destination_context AS (
SELECT
destination_ip,
destination_domain,
destination_category,
destination_asset_type,
approved_context,
first_seen_time,
sensitivity
FROM gcp_destination_enrichment
)
SELECT
na.start_time,
ns.organization_id,
ns.folder_id,
ns.project_id,
ns.service_name,
ns.workload_type,
ns.nginx_role,
ns.instance_id,
ns.gke_cluster,
ns.gke_node_pool,
ns.pod_name,
ns.namespace,
ns.service_account_email,
na.src_ip,
na.dest_ip,
na.dest_port,
na.protocol,
na.bytes_sent,
da.query_name,
dc.destination_domain,
dc.destination_category,
dc.destination_asset_type,
dc.sensitivity,
CASE
WHEN dc.destination_asset_type IN (
'database',
'identity_service',
'secret_manager',
'metadata_endpoint',
'management_interface',
'regulated_data_path'
) THEN 'high'
WHEN dc.destination_category IN (
'rare_destination',
'newly_observed_destination',
'dynamic_dns',
'temporary_hosting',
'paste_service',
'file_sharing',
'tunneling',
'unknown_external'
) THEN 'high'
WHEN ns.asset_criticality IN ('critical','high') THEN 'medium'
ELSE 'triage'
END AS priority
FROM network_activity na
JOIN nginx_sources ns
ON na.project_id = ns.project_id
AND (
na.interface_id = ns.network_interface
OR na.src_ip = ns.private_ip
)
LEFT JOIN dns_activity da
ON na.project_id = da.project_id
AND na.src_ip = da.source_ip
AND da.query_time BETWEEN TIMESTAMP_SUB(na.start_time, INTERVAL 5 MINUTE)
AND TIMESTAMP_ADD(na.start_time, INTERVAL 5 MINUTE)
LEFT JOIN destination_context dc
ON na.dest_ip = dc.destination_ip
OR da.query_name = dc.destination_domain
WHERE (
ns.last_suspected_request_time IS NOT NULL
OR ns.last_service_instability_time IS NOT NULL
)
AND (
dc.approved_context IS NULL
OR dc.approved_context NOT IN (
'approved_upstream_application',
'approved_observability_destination',
'approved_log_forwarding_destination',
'approved_package_repository',
'approved_update_repository',
'approved_security_tool',
'approved_service_mesh',
'approved_management_destination',
'approved_backend_health_check',
'approved_gcp_api_use'
)
)
AND (
dc.destination_category IN (
'rare_destination',
'newly_observed_destination',
'dynamic_dns',
'temporary_hosting',
'paste_service',
'file_sharing',
'tunneling',
'unknown_external'
)
OR dc.destination_asset_type IN (
'database',
'identity_service',
'secret_manager',
'metadata_endpoint',
'management_interface',
'regulated_data_path'
)
OR na.dest_port NOT IN (80, 443, 53, 123)
OR na.bytes_sent >= 10485760
);
S26 Threat-to-Rule Traceability Matrix
Traceability Purpose
This section maps the primary NGINX Rift threat behaviors to the S25 detection rule coverage. The matrix is behavior-led and is intended to show how each rule contributes to detection, triage, escalation, and confidence-building without overstating any single rule as standalone proof of successful exploitation.
Traceability Summary
· The strongest coverage exists for suspicious request-shape activity against exposed NGINX-backed infrastructure, especially when paired with service instability, route-specific degradation, endpoint process activity, unusual egress, backend access, or cloud-control-plane behavior.
· The highest-confidence escalation path requires correlation across web, NGINX error-log, endpoint, network, identity, cloud, Kubernetes, and workload telemetry.
· No single S25 rule confirms successful NGINX Rift exploitation by itself.
· S25 coverage is strongest when request-path evidence is paired with post-request process execution, file activity, workload behavior, credential access, unusual outbound communication, sensitive backend access, metadata access, cloud-control-plane activity, or validated downstream impact.
· YARA has no deployed or proposed rule coverage in this report because no stable malware, webshell, dropper, memory artifact, payload, malicious NGINX module, or file artifact has been established.
Threat Behavior
External request-shape probing against exposed NGINX-backed services.
Mapped S25 Rule Coverage
· NDR / Network Behavioral Analytics coverage for suspicious inbound request behavior, exposed NGINX-backed service targeting, source clustering, rare-source activity, request-to-service-degradation correlation, and unusual source-to-route patterns where network and web telemetry are available.
· Splunk coverage for suspicious NGINX rewrite-path request activity, NGINX error-log correlation, route-specific 500-series behavior, upstream reset behavior, and web-to-host correlation.
· Elastic coverage for suspicious NGINX rewrite-path request activity, abnormal URI patterns, webserver telemetry, NGINX error-log artifacts, and optional endpoint enrichment.
· QRadar coverage for suspicious NGINX request activity, rule-chain correlation, NGINX error-log context, and offense-building across web, host, and network data.
· SIGMA coverage through portable webserver request-shape logic under the suspicious NGINX rewrite-path request activity rule.
· AWS Rule 1 coverage for AWS-exposed NGINX request-shape and service-instability prioritization.
· Azure Rule 1 coverage for Azure-exposed NGINX request-shape and service-instability prioritization.
· GCP Rule 1 coverage for GCP-exposed NGINX request-shape and service-instability prioritization.
Detection Rationale
· This behavior is externally observable and can be detected before successful exploitation is confirmed.
· Request-shape anomalies, route targeting, source clustering, WAF or load-balancer context, and NGINX error-log instability provide durable detection anchors.
· Service instability increases confidence but should not be treated as the only viable detection path.
Required Correlation
· Web or edge telemetry.
· NGINX access logs.
· NGINX error logs.
· WAF, load balancer, ingress, gateway, CDN, or Cloud Armor telemetry where available.
· Route inventory.
· Exposed NGINX-backed asset inventory.
· Approved scanner, testing, patch-validation, synthetic monitoring, and incident-response context.
Coverage Assessment
· Coverage is strong for suspicious request delivery, route probing, malformed request patterns, request-shape fuzzing, request-normalization failures, and request-to-instability sequencing.
· Coverage is not sufficient to confirm exploitation without post-request workload, endpoint, cloud, network, identity, application, or validated impact evidence.
Residual Gap
· Low-noise requests, normalized requests, CDN or WAF rewriting, missing URI fields, missing NGINX error logs, incomplete route mapping, and fragmented edge logging may reduce visibility.
Threat Behavior
NGINX worker instability, service degradation, route-specific 500-series spikes, upstream reset behavior, or backend error amplification following suspicious request activity.
Mapped S25 Rule Coverage
· NDR / Network Behavioral Analytics coverage for service degradation, abnormal network behavior, route-specific degradation, and request-to-degradation patterns where network telemetry can observe degraded service behavior.
· Splunk, Elastic, and QRadar coverage for NGINX error-log correlation, route-specific 500-series spikes, abnormal worker exits, segmentation fault indicators, upstream reset spikes, and backend degradation.
· SIGMA coverage where backend implementations preserve service-instability components as confidence-increasing rule-chain inputs.
· AWS Rule 1 coverage for ALB target 5xx spikes, ECS task restarts, EKS pod restarts, and NGINX-backed service degradation.
· Azure Rule 1 coverage for Application Gateway backend 5xx spikes, AKS pod restarts, VM or VMSS service instability, and NGINX-backed service degradation.
· GCP Rule 1 coverage for load-balancer backend 5xx spikes, GKE pod restarts, Compute Engine service instability, and NGINX-backed service degradation.
Detection Rationale
· Service instability can be a useful post-request confidence signal when it aligns with suspicious request-shape behavior.
· The signal is durable but not unique to exploitation.
· Service instability should increase confidence, drive triage, and support escalation rather than act as standalone proof of exploitation.
Required Correlation
· NGINX error logs.
· Service health telemetry.
· Load balancer health telemetry.
· Container or pod restart telemetry where applicable.
· VM, VMSS, EC2, Compute Engine, ECS, EKS, AKS, or GKE workload health telemetry.
· Change-management, deployment, patching, package-update, scaling, and maintenance context.
Coverage Assessment
· Coverage is strong as a confidence-increasing signal.
· Coverage is weaker as a standalone detection because benign application errors, deployment changes, scaling events, package updates, misconfiguration, or resource pressure can produce overlapping symptoms.
Residual Gap
· Missing error logs, incomplete health telemetry, poor route-to-workload mapping, and weak change-management context may prevent reliable attribution.
Threat Behavior
Suspicious child-process execution, shell execution, interpreter execution, downloader use, credential utility use, service-control use, package-manager use, or administrative utility execution from NGINX-related context.
Mapped S25 Rule Coverage
· SentinelOne coverage for suspicious NGINX-associated child-process execution, process lineage, command-line behavior, file activity, service-account context, and expected-change controls.
· Splunk coverage for NGINX exploit-path activity followed by suspicious process, file, or service behavior.
· Elastic coverage for NGINX-related process creation, command-line risk patterns, sensitive path access, and process-to-request correlation.
· QRadar coverage for host-side events chained to web or NGINX exploit-path context.
· SIGMA coverage through the NGINX exploit-path activity followed by suspicious child-process execution rule.
· AWS Rule 2 coverage for suspicious workload, credential, and cloud-control-plane activity tied to AWS-hosted NGINX-backed workloads.
· Azure Rule 2 coverage for suspicious workload, managed identity, and Azure control-plane activity tied to Azure-hosted NGINX-backed workloads.
· GCP Rule 2 coverage for suspicious workload, service account, and GCP control-plane activity tied to GCP-hosted NGINX-backed workloads.
Detection Rationale
· Suspicious process activity after exploit-path request indicators is one of the strongest escalation points for suspected exploitation.
· Parent-child process lineage, service-account context, command-line behavior, workload identity, and timing relative to suspicious request activity improve confidence.
· This behavior is more valuable when correlated with NGINX error-log instability, suspicious file activity, egress, credential access, or cloud-control-plane activity.
Required Correlation
· Endpoint process telemetry.
· Parent-child process lineage.
· Command-line telemetry.
· NGINX process or service-account context.
· Web-to-host correlation.
· Expected-change and deployment context.
· EDR or workload telemetry where available.
· Container, Kubernetes, or cloud workload context where applicable.
Coverage Assessment
· Coverage is strong when process lineage, command-line capture, service-account mapping, and request-to-host timing are available.
· Coverage is moderate where only partial process telemetry or workload context exists.
Residual Gap
· Container abstraction, missing command-line capture, incomplete process ancestry, managed-service limitations, legitimate automation, and package or certificate automation may reduce confidence.
Threat Behavior
Suspicious file activity, configuration modification, service-unit modification, startup-path activity, credential-path access, mounted-secret access, or writable-path execution from NGINX-backed workloads.
Mapped S25 Rule Coverage
· SentinelOne coverage for file activity, configuration writes, service changes, credential-path access, mounted-secret access, and expected-change controls.
· Splunk coverage for host-side file, configuration, and service behavior following NGINX exploit-path indicators.
· Elastic coverage for sensitive file path events, NGINX configuration changes, service-unit changes, startup activity, credential-material access, and process-to-file correlation.
· QRadar coverage for correlated file, process, and service activity where host telemetry is normalized into offense logic.
· SIGMA coverage where host-side process, file, or service components are translated into backend-supported rule logic.
· AWS, Azure, and GCP cloud rules provide indirect coverage when file or workload activity is followed by cloud-control-plane use, egress, metadata access, identity activity, or sensitive backend access.
Detection Rationale
· File and configuration changes can indicate staging, persistence, credential access, service modification, or workload tampering after successful exploitation.
· Expected-change controls are required because deployment systems, package managers, certificate renewal, configuration management, and administrative maintenance can generate overlapping behavior.
Required Correlation
· File telemetry.
· Service manager events.
· Configuration management context.
· Package-management context.
· Certificate-renewal context.
· Endpoint or workload telemetry.
· NGINX exploit-path or service-instability context.
· Approved deployment, maintenance, patching, and incident-response context.
Coverage Assessment
· Coverage is strong where file telemetry and expected-change baselines are available.
· Coverage is limited where managed services, containers, ephemeral workloads, or minimal endpoint telemetry obscure file and configuration changes.
Residual Gap
· Memory-only behavior, approved deployment paths, legitimate automation, and missing file telemetry may reduce detection visibility.
Threat Behavior
Unusual outbound egress, callback activity, payload retrieval, tunneling, suspicious DNS activity, direct IP communication, unusual ports, or abnormal data transfer from NGINX-backed infrastructure.
Mapped S25 Rule Coverage
· NDR / Network Behavioral Analytics coverage for unusual egress, rare destinations, suspicious destination categories, direct IP communication, abnormal timing, beacon-like behavior, and request-to-egress sequencing.
· Splunk, Elastic, and QRadar coverage for egress and backend-access correlation when network, DNS, proxy, firewall, and endpoint-network telemetry are available.
· SIGMA coverage through the NGINX exploit-path activity followed by unusual egress or backend access rule.
· AWS Rule 3 coverage for unusual AWS egress, backend access, metadata activity, DNS activity, and VPC Flow Log correlation.
· Azure Rule 3 coverage for unusual Azure egress, backend access, metadata activity, DNS activity, and NSG or Firewall flow correlation.
· GCP Rule 3 coverage for unusual GCP egress, backend access, metadata activity, DNS activity, and VPC Flow Log correlation.
Detection Rationale
· Egress and DNS activity provide durable post-exploitation detection opportunities when correlated with suspicious request activity, service instability, host behavior, or workload identity.
· Destination novelty, sensitive destination identity, metadata access, and dependency-map deviation increase confidence.
Required Correlation
· Network flow telemetry.
· DNS telemetry.
· Proxy or firewall telemetry where available.
· Endpoint-network telemetry where available.
· Destination enrichment.
· Approved egress baselines.
· Backend dependency maps.
· NGINX exploit-path, service-instability, or workload context.
Coverage Assessment
· Coverage is strong for unusual destination patterns, metadata access, backend probing, and suspicious egress after request or workload indicators.
· Coverage is weaker where traffic is NATed, service-mesh-obscured, proxy-chained, encrypted, or not attributable to a specific workload.
Residual Gap
· Approved cloud services, common infrastructure providers, service mesh abstraction, NAT, and incomplete destination enrichment may reduce confidence.
Threat Behavior
Sensitive backend access, internal service discovery, metadata service access, secrets access pathing, database access, management-interface access, or regulated-data-path access after suspected NGINX exploit-path activity.
Mapped S25 Rule Coverage
· NDR / Network Behavioral Analytics coverage for internal expansion, backend access anomalies, sensitive destination access, and post-request destination sequencing.
· Splunk, Elastic, and QRadar coverage for internal service access, identity context, process-to-network correlation, and backend dependency deviation.
· SIGMA coverage through portable network-correlation logic where backend rule chaining is supported.
· AWS Rule 3 coverage for internal backend access, EC2 metadata access, Secrets Manager endpoints, SSM endpoints, KMS endpoints, S3 endpoints, EKS APIs, ECR, and sensitive AWS dependency access.
· Azure Rule 3 coverage for backend access, Azure Instance Metadata Service access, Key Vault endpoints, Storage endpoints, AKS APIs, container registry endpoints, and sensitive Azure dependency access.
· GCP Rule 3 coverage for backend access, Google metadata server access, Secret Manager endpoints, Cloud KMS endpoints, Cloud Storage endpoints, Artifact Registry endpoints, GKE APIs, and sensitive GCP dependency access.
Detection Rationale
· Sensitive backend and metadata access represent a high-value post-exploitation escalation path.
· These behaviors are stronger when they follow suspicious request activity, service instability, workload execution, credential access, or identity anomalies.
Required Correlation
· Internal flow telemetry.
· Cloud flow telemetry.
· DNS telemetry.
· Backend dependency mapping.
· Sensitive destination mapping.
· Metadata endpoint detection.
· Identity or workload context.
· Workload and cloud-control-plane context.
Coverage Assessment
· Coverage is strong when dependency maps and workload identity joins are mature.
· Coverage is moderate where internal destination ownership, service mesh routing, or cloud metadata visibility is incomplete.
Residual Gap
· Missing dependency maps, broad service accounts, permitted backend access, opaque service mesh traffic, and incomplete metadata endpoint visibility may limit precision.
Threat Behavior
Cloud-control-plane activity after suspected NGINX exploit-path activity.
Mapped S25 Rule Coverage
· AWS Rule 2 coverage for CloudTrail, GuardDuty, IAM, STS, Secrets Manager, SSM, EC2, EKS, ECS, KMS, S3, ECR, role use, task role use, instance profile use, and cloud-control-plane activity.
· Azure Rule 2 coverage for Azure Activity Logs, Microsoft Entra ID, managed identities, service principals, Key Vault, Storage, Compute, Network, AKS, role assignments, VM Run Command, and control-plane activity.
· GCP Rule 2 coverage for Cloud Audit Logs, service accounts, workload identities, IAM policy changes, service account key creation, Secret Manager, Cloud Storage, Cloud KMS, GKE, Compute Engine, firewall changes, and control-plane activity.
· Splunk, Elastic, and QRadar coverage where cloud-control-plane telemetry is centralized and correlated with NGINX request, host, network, identity, and workload evidence.
Detection Rationale
· Cloud-control-plane behavior can reveal credential use, identity abuse, secret access, workload expansion, infrastructure modification, and cloud-side blast radius after suspected workload compromise.
· Cloud-control-plane activity is not unique to NGINX Rift and must be tied back to NGINX-backed workload context.
Required Correlation
· CloudTrail or CloudTrail Lake for AWS.
· Azure Activity Logs and Microsoft Entra ID telemetry for Azure.
· Cloud Audit Logs and Data Access logs for GCP.
· Workload-to-role, managed-identity, or service-account mapping.
· NGINX exploit-path context.
· Workload telemetry or host telemetry.
· Approved automation baselines.
Coverage Assessment
· Coverage is strong for post-exploitation cloud-side blast-radius assessment.
· Coverage is not direct exploit detection because cloud APIs cannot observe the local exploit primitive.
Residual Gap
· Missing cloud data events, incomplete identity-to-workload mapping, broad automation roles, limited user-agent visibility, fragmented account or project coverage, and weak approved-automation baselines may reduce confidence.
Threat Behavior
Credential access, secret access, token use, role assumption, service-account abuse, managed-identity abuse, or cloud identity misuse after suspected NGINX-backed workload compromise.
Mapped S25 Rule Coverage
· SentinelOne coverage for credential-path access, suspicious process behavior, credential utility execution, and host-side credential activity where endpoint telemetry is available.
· Splunk, Elastic, and QRadar coverage where credential-access telemetry, cloud identity telemetry, endpoint telemetry, and workload context can be correlated.
· AWS Rule 2 coverage for STS activity, IAM role use, Secrets Manager access, SSM activity, KMS decrypt activity, S3 access, ECR activity, and role-to-workload mapping.
· Azure Rule 2 coverage for managed identity use, service principal activity, Key Vault access, role assignment changes, Storage access, VM Run Command activity, and managed identity assignment changes.
· GCP Rule 2 coverage for service account use, service account key creation, Secret Manager access, Cloud Storage access, Cloud KMS decrypt activity, IAM policy changes, and workload identity activity.
Detection Rationale
· Credential and identity use is a critical post-exploitation indicator when linked to a vulnerable, exposed, or suspicious NGINX-backed workload.
· Identity activity must be correlated with workload origin, expected automation baselines, and exploit-path context.
Required Correlation
· Endpoint credential-access telemetry.
· Cloud identity telemetry.
· Secret-management logs.
· Workload-to-identity mapping.
· Approved automation baselines.
· Suspicious NGINX request, instability, process, egress, or backend-access context.
Coverage Assessment
· Coverage is strong where endpoint and cloud identity telemetry are centralized.
· Coverage is weaker where identities are shared, mappings are incomplete, data access logging is limited, or legitimate automation overlaps heavily with suspicious behavior.
Residual Gap
· Broad permissions, shared identities, insufficient cloud data logging, weak workload-to-identity mapping, and fragmented identity telemetry may reduce attribution quality.
Threat Behavior
Multi-host, multi-route, multi-account, multi-subscription, multi-project, or multi-cloud clustering of similar suspicious activity.
Mapped S25 Rule Coverage
· NDR / Network Behavioral Analytics coverage for multiple NGINX-backed assets contacting or receiving traffic from the same source, destination, ASN, infrastructure cluster, or suspicious request pattern.
· Splunk, Elastic, and QRadar coverage for cross-host, cross-route, cross-index, cross-cloud, and rule-chain correlation.
· SIGMA coverage when translated into a backend that supports aggregation, sequence, and rule chaining.
· AWS Rule 1, Rule 2, and Rule 3 coverage across accounts and regions where AWS Organizations, Security Hub, CloudTrail Lake, Config, Athena, and centralized log exports are available.
· Azure Rule 1, Rule 2, and Rule 3 coverage across tenants, management groups, subscriptions, resource groups, and Sentinel workspaces where telemetry is centralized.
· GCP Rule 1, Rule 2, and Rule 3 coverage across organizations, folders, projects, regions, and BigQuery datasets where logging exports are centralized.
Detection Rationale
· Repeated or clustered activity across multiple exposed NGINX-backed services increases confidence and supports campaign-level triage.
· Cross-environment clustering is useful for prioritization, but it still does not prove successful exploitation without workload or cloud-side corroboration.
Required Correlation
· Centralized SIEM or cloud data lake.
· Cross-account, cross-subscription, cross-project, or cross-cloud inventory.
· Shared source, destination, user-agent, route, URI-shape, service-instability, workload, identity, or timing context.
· Alert grouping and entity resolution.
Coverage Assessment
· Coverage is strong where telemetry is centralized and normalized.
· Coverage is limited where logs remain isolated by account, subscription, project, region, workspace, tenant, organization, folder, or cloud environment.
Residual Gap
· Fragmented telemetry, inconsistent retention, weak tagging, partial asset inventory, and inconsistent correlation identifiers may reduce campaign-level correlation.
Threat Behavior
Artifact-based malware, webshell, payload, dropper, malicious NGINX module, or stable memory/file indicator.
Mapped S25 Rule Coverage
· YARA has no deployed or proposed rule coverage in this report.
· SentinelOne, Splunk, Elastic, QRadar, and cloud telemetry may provide indirect visibility if artifacts are written, executed, staged, moved, or used, but no stable artifact signature exists for YARA deployment at this stage.
Detection Rationale
· The report’s detection model is behavior-led rather than artifact-led.
· YARA should not be forced without a stable malware, webshell, dropper, malicious module, file artifact, or memory artifact.
Required Correlation
· Confirmed artifact sample.
· Stable strings, byte patterns, structural markers, or file traits.
· Malware, webshell, module, dropper, or memory artifact evidence.
· Endpoint or file telemetry for deployment validation.
Coverage Assessment
· No YARA coverage is currently appropriate.
· Artifact coverage can be added in a future amendment if stable evidence emerges.
Residual Gap
· If exploitation later produces stable artifacts, the current S25 package should be amended to add YARA or platform-specific artifact rules.
Overall Traceability Assessment
· NDR / Network Behavioral Analytics provides strong behavioral visibility for request-to-network, request-to-degradation, request-to-egress, and internal-expansion patterns.
· SentinelOne provides strong host-side visibility for suspicious process, file, credential, and workload activity after exploit-path context.
· Splunk, Elastic, and QRadar provide strong SIEM correlation coverage when web, host, network, identity, cloud, and workload telemetry are normalized.
· SIGMA provides portable detection logic that supports cross-backend implementation when translated carefully into backend-native syntax.
· AWS, Azure, and GCP provide cloud-native traceability for exposed-service prioritization, cloud-control-plane activity, identity abuse, egress, backend access, metadata-path activity, and sensitive dependency access.
· YARA remains excluded because no stable artifact anchor exists.
Traceability Confidence
Operational Traceability Confidence
High where web, NGINX error-log, endpoint, network, cloud, identity, and workload telemetry are centralized and correlated.
Full-Telemetry Traceability Confidence
Very high where SIEM rule chaining, cloud data lakes, endpoint process lineage, file telemetry, NGINX error logs, WAF or load-balancer logs, DNS, flow telemetry, cloud-control-plane logs, identity mapping, workload inventory, route mapping, dependency mapping, and approved-change context are available.
Traceability Limitations
· Successful exploitation cannot be confirmed from request telemetry alone.
· Cloud-control-plane activity cannot prove local NGINX exploitation without workload-side or host-side corroboration.
· Service instability is a useful confidence signal but may overlap with benign operational failures.
· Endpoint process and file visibility may be reduced by containerization, managed platforms, incomplete EDR deployment, minimal logging, or ephemeral workloads.
· Network visibility may be reduced by NAT, service mesh abstraction, proxy chaining, encryption, incomplete destination enrichment, or weak workload attribution.
· Cloud traceability depends on account, subscription, project, region, workspace, organization, folder, logging, and data-event coverage.
· Local production deployment still requires customer-specific validation of schemas, fields, tables, indexes, sourcetypes, joins, enrichment, allowlists, false-positive baselines, query performance, and SOC triage readiness.

Figure 4
S27 — Behavior and Log Artifacts
Artifact Objective
· This section identifies the behavioral, web, host, identity, cloud, container, Kubernetes, vulnerability, and supporting artifact evidence needed to investigate NGINX Rift exploit-path activity.
· The artifact model supports triage of suspicious activity against exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent infrastructure.
· Artifacts should be interpreted in sequence: exposed request path, suspicious request activity, service instability, workload execution, outbound communication, backend access, identity activity, and cloud or downstream blast-radius activity.
· No single artifact should be treated as confirmed exploitation without supporting behavioral context.
· Request-shape data, vulnerable-state context, cloud activity, and service-instability artifacts support prioritization and investigation, but they do not independently confirm successful exploitation.
Primary Web and Reverse Proxy Behavior Artifacts
· Malformed HTTP or HTTPS requests targeting internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, or NGINX-backed application infrastructure.
· Abnormal URI length, encoded path expansion, repeated delimiters, double encoding, excessive escape sequences, malformed path structure, or request-normalization failure.
· Suspicious requests against rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway routes, administrative portals, customer-facing virtual hosts, or high-dependency upstream routes.
· Source-clustered probing by IP address, ASN, hosting provider, cloud provider, scanner infrastructure, user-agent pattern, request shape, route target, or similar malformed path structure.
· Similar request-shape activity observed across multiple exposed NGINX-backed assets, virtual hosts, applications, ingress routes, gateway routes, accounts, subscriptions, projects, or cloud environments.
· WAF, CDN, load balancer, gateway, ingress, or reverse proxy telemetry showing blocked malformed paths, allowed suspicious requests, request-normalization failures, upstream reset behavior, gateway failure patterns, or backend degradation.
· Suspicious request activity that precedes route-specific error spikes, worker instability, container restarts, pod restarts, or NGINX-backed service degradation.
Primary NGINX Log Artifacts
· Source IP.
· Forwarded IP.
· Host header.
· Virtual host.
· Request method.
· Raw URI where available.
· Normalized URI where available.
· Query string where available.
· User agent.
· Response code.
· Upstream response code where available.
· Request duration.
· Upstream response time.
· Request size or URI length.
· Route or application mapping where available.
· NGINX worker crash indicators.
· NGINX segmentation fault indicators.
· Abnormal worker exit messages.
· Worker respawn or restart patterns.
· Reload failures.
· Upstream reset spikes.
· Route-specific backend failure messages.
· Error-log sequences where worker instability follows suspicious inbound request activity.
Service Instability Artifacts
· NGINX worker crash.
· Segmentation fault indicator.
· Abnormal worker exit.
· Repeated worker respawn.
· Service restart loop.
· Reload failure.
· Route-specific 500-series spike.
· Upstream reset spike.
· Gateway failure spike.
· Backend failure spike.
· Application latency increase.
· Health-check failure.
· Container restart.
· Pod restart.
· Crash-loop behavior.
· Load balancer backend degradation.
· Availability degradation isolated to an exposed NGINX-backed route, virtual host, application, ingress path, or gateway route.
Primary Host and Process Artifacts
· Unexpected child-process execution from NGINX master, worker, NGINX Plus, ingress-controller, reverse proxy, gateway, WAF-adjacent, or containerized NGINX process lineage.
· Shell execution from NGINX-related process lineage.
· Interpreter execution from NGINX-related process lineage.
· Downloader, file-transfer, archive, network, credential, package-management, discovery, permission-modification, or service-control utility execution from NGINX-related context.
· Command-line arguments showing remote retrieval, encoded execution, inline script execution, temporary-directory execution, credential access, metadata service access, mounted-secret access, archive extraction, output redirection, or writable-path execution.
· Process execution under NGINX service accounts, reverse proxy service accounts, ingress-controller service accounts, gateway service accounts, container service accounts, or workload identities.
· Suspicious process execution shortly after NGINX worker instability, route-specific degradation, error-log artifacts, suspicious request activity, container restart, or pod restart.
· Similar process patterns appearing across multiple NGINX-backed assets, containers, ingress nodes, gateway nodes, or cloud workloads.
Primary File and Persistence Artifacts
· New file creation under web-accessible directories, temporary directories, writable application paths, mounted volumes, container writable layers, or service directories.
· File modification under NGINX configuration paths, reverse proxy configuration paths, ingress configuration paths, gateway configuration paths, service-unit paths, startup paths, cron paths, SSH material paths, credential paths, cloud credential paths, or Kubernetes mounted-secret paths.
· Executable-bit changes, ownership changes, permission changes, symbolic link creation, archive extraction, suspicious file deletion, or suspicious log tampering.
· Creation of shell scripts, ELF binaries, web-accessible artifacts, encoded payloads, downloaded tools, archive files, service-unit files, startup scripts, or credential files.
· Access to service-account tokens, mounted secrets, environment files, application configuration files, cloud credentials, API keys, SSH material, or secrets.
· Configuration changes that occur outside approved deployment, package-management, certificate-renewal, configuration-management, or service-reload windows.
· File activity that follows suspicious request activity, worker instability, child-process execution, unusual outbound communication, credential access, cloud-control-plane activity, or Kubernetes activity.
Network and Egress Artifacts
· First-seen outbound communication from NGINX-backed hosts, containers, workloads, nodes, ingress controllers, gateways, or reverse proxy tiers after suspicious inbound request activity.
· Direct IP communication from NGINX-backed infrastructure.
· DNS queries to newly observed, rare, low-reputation, dynamic-DNS, temporary-hosting, paste-service, file-sharing, tunneling, infrastructure-like, or unknown external domains.
· Outbound traffic to destinations outside approved NGINX upstream dependency baselines.
· Unusual destination ports, abnormal protocols, abnormal session durations, beacon-like timing, repeated rare-destination contact, or high byte-count transfers.
· Outbound traffic initiated by suspicious NGINX-related child processes.
· Egress activity following NGINX worker instability, route-specific 500-series spikes, file staging, credential access, mounted-secret access, or suspicious process execution.
· Multiple NGINX-backed assets contacting the same rare destination, domain, ASN, hosting provider, tunnel provider, or infrastructure cluster after similar exploit-path indicators.
Internal Expansion Artifacts
· New or unusual communication from NGINX-backed infrastructure to backend applications, internal APIs, databases, identity services, management interfaces, administrative services, regulated data paths, CI/CD systems, artifact repositories, or secret-management systems.
· Communication from NGINX-backed workloads to cloud metadata services.
· Communication from NGINX-backed workloads to Kubernetes API servers.
· Internal service discovery, connection sweeps, port scanning, metadata probing, internal API probing, database probing, or management-interface exploration from NGINX-backed infrastructure.
· Sensitive backend access occurring after suspicious request activity, NGINX worker instability, unusual outbound communication, file activity, credential access, or process execution.
· Backend access patterns that deviate from documented dependency maps for the affected route, virtual host, workload, service owner, namespace, or network segment.
Identity and Credential Artifacts
· Credential-material access from NGINX-related process lineage.
· Access to service-account tokens, cloud credentials, Kubernetes mounted secrets, environment files, API keys, SSH keys, application secrets, or configuration files containing credentials.
· Abnormal use of service accounts, managed identities, IAM roles, instance profiles, task roles, workload identities, or service principals tied to NGINX-backed workloads.
· Role assumption, token use, service-account use, managed-identity use, or secret access following suspicious NGINX request activity or workload instability.
· Access to AWS Secrets Manager, Azure Key Vault, GCP Secret Manager, SSM Parameter Store, KMS, Cloud KMS, S3, Azure Storage, Cloud Storage, or other secret and data services from identities associated with NGINX-backed workloads.
· Identity activity inconsistent with approved deployment automation, monitoring, backup, security tooling, administrative workflows, or maintenance windows.
Container and Kubernetes Artifacts
· Pod restarts, container restarts, crash-loop behavior, readiness probe failures, or liveness probe failures involving NGINX ingress, reverse proxy, gateway, or containerized NGINX workloads.
· Abnormal process execution inside NGINX containers, ingress-controller pods, gateway pods, or reverse proxy workloads.
· Mounted-secret access from NGINX-related workloads.
· Service-account token access from NGINX-related workloads.
· Workload modification, ingress modification, role-binding changes, deployment changes, image changes, or unexpected configuration changes after suspicious request activity.
· Kubernetes API access from NGINX-backed workloads outside expected dependency baselines.
· Internal service probing from ingress, gateway, reverse proxy, or NGINX-backed namespaces.
· Container writable-layer changes, mounted-volume modifications, or persistence-like file behavior following suspicious request activity or worker instability.
Cloud-Control-Plane Artifacts
· AWS CloudTrail activity involving STS, IAM, Secrets Manager, SSM, EC2, EKS, ECS, KMS, S3, ECR, role use, task role use, instance profile use, or unusual cloud-control-plane behavior from NGINX-backed workload identities.
· Azure Activity Log or Microsoft Entra ID activity involving managed identities, service principals, Key Vault, Storage, Compute, Network, AKS, role assignments, VM Run Command, VM extensions, or control-plane behavior from NGINX-backed workload identities.
· GCP Cloud Audit Log activity involving service accounts, workload identities, IAM policy changes, service account key creation, Secret Manager, Cloud Storage, Cloud KMS, GKE, Compute Engine, firewall changes, image creation, snapshot activity, or control-plane behavior from NGINX-backed workload identities.
· Cloud-control-plane activity following suspected exploit-path request activity, NGINX service instability, suspicious process execution, credential access, metadata access, backend access, or unusual egress.
· Cloud activity that cannot be explained by approved automation, deployment systems, backup workflows, observability tooling, security tooling, maintenance windows, or administrative baselines.
System-Specific Artifact Position
NDR / Network Behavioral Analytics
· Key artifacts include suspicious inbound request behavior, source clustering, malformed request-shape patterns, unusual egress, direct IP communication, suspicious DNS activity, backend access, metadata access, and sensitive internal destination access.
· NDR artifacts support exploit-attempt triage, egress analysis, and internal expansion assessment.
· NDR artifacts require NGINX access-log, NGINX error-log, endpoint, cloud, identity, or application corroboration before being treated as probable compromise.
SentinelOne
· Key artifacts include process creation, process ancestry, command line, parent process context, service-account context, file activity, sensitive path access, process-to-network activity, endpoint asset role, and agent health.
· SentinelOne artifacts provide primary host-behavior evidence for post-request execution, file activity, credential access, and process-network behavior.
· SentinelOne artifacts require request, service-instability, cloud, identity, network, or downstream corroboration before being attributed to NGINX Rift.
Splunk
· Key artifacts include normalized web, NGINX error-log, endpoint, file, network, DNS, identity, cloud, Kubernetes, container, and application fields.
· Splunk artifacts support correlation across suspicious request activity, instability, process execution, file activity, egress, cloud activity, and backend access.
· Splunk artifact value depends on index coverage, sourcetype quality, field extraction, timestamp normalization, and lookup accuracy.
Elastic
· Key artifacts include ECS-aligned web, endpoint, process, file, network, DNS, cloud, Kubernetes, container, and vulnerability fields.
· Elastic artifacts support endpoint behavior detection and sequence-based correlation where ECS mappings and data views are validated.
· Elastic artifact value depends on ingestion fidelity, field mapping, data-view coverage, and correlation support.
QRadar
· Key artifacts include DSM-parsed web, endpoint, network, identity, and cloud properties, custom properties, reference sets, building blocks, vulnerable asset context, and approved activity context.
· QRadar artifacts support offense generation when event properties are normalized consistently.
· QRadar artifact value depends on DSM parsing, custom property extraction, reference-set accuracy, and rule-chain sequencing.
SIGMA
· Key artifacts depend on backend translation.
· Required artifacts include webserver request fields, NGINX error-log fields, process creation fields, parent process context, command line, file telemetry where available, network telemetry where available, and backend correlation context.
· SIGMA artifact value depends on backend field fidelity, sequence support, translation accuracy, and enrichment availability.
YARA
· No YARA artifact rule is deployed or proposed in this report.
· YARA would become relevant only if stable malware, webshell, dropper, malicious NGINX module, memory artifact, file artifact, payload marker, or reusable exploit artifact evidence emerges.
· YARA should remain excluded until stable artifact evidence exists.
AWS
· Key artifacts include AWS WAF logs, CloudFront logs, ALB logs, AWS Config inventory, EC2 metadata, ECS context, EKS context, IAM role mapping, CloudTrail activity, GuardDuty findings, Security Hub findings, VPC Flow Logs, Route 53 Resolver logs, Secrets Manager activity, SSM activity, KMS activity, S3 activity, and approved automation baselines.
· AWS artifacts support exposed-service prioritization, cloud-control-plane investigation, identity abuse assessment, egress analysis, metadata access review, and cloud-side blast-radius detection.
· AWS artifacts do not directly confirm local NGINX exploitation without workload-side or host-side corroboration.
Azure
· Key artifacts include Azure Front Door logs, Application Gateway logs, WAF logs, Resource Graph inventory, Azure Activity Logs, Microsoft Entra ID activity, managed identity mapping, AKS context, VM and VMSS context, Key Vault logs, Storage logs, Defender for Cloud findings, Defender for Endpoint enrichment, NSG Flow Logs, Azure Firewall logs, DNS logs, and approved automation baselines.
· Azure artifacts support exposed-service prioritization, managed identity review, control-plane investigation, egress analysis, backend access review, and cloud-side blast-radius detection.
· Azure artifacts do not directly confirm local NGINX exploitation without workload-side or host-side corroboration.
GCP
· Key artifacts include Cloud Armor logs, external HTTP load balancer logs, Security Command Center findings, VM Manager findings, Cloud Asset Inventory, Compute Engine metadata, GKE context, service account mapping, Cloud Audit Logs, Data Access logs, VPC Flow Logs, Cloud DNS logs, Secret Manager access, Cloud Storage access, Cloud KMS activity, and approved automation baselines.
· GCP artifacts support exposed-service prioritization, service account review, control-plane investigation, egress analysis, backend access review, and cloud-side blast-radius detection.
· GCP artifacts do not directly confirm local NGINX exploitation without workload-side or host-side corroboration.
Artifact Correlation Requirements
· Correlate suspicious request activity with exposed NGINX-backed asset context.
· Correlate malformed request activity with rewrite-heavy route context where available.
· Correlate request-shape anomalies with NGINX error-log artifacts.
· Correlate NGINX worker instability with immediately preceding suspicious request activity.
· Correlate child-process execution with NGINX process lineage, service-account context, and timing after exploit-path indicators.
· Correlate file, credential, mounted-secret, or persistence activity with process lineage and exploit-path context.
· Correlate outbound communication with prior suspicious request activity, service instability, process execution, file activity, or credential access.
· Correlate backend access with route dependency maps, workload identity, sensitive destination mapping, and exploit-path timing.
· Correlate cloud-control-plane activity with the role, managed identity, service principal, service account, task role, instance profile, or workload identity mapped to the affected NGINX-backed workload.
· Correlate Kubernetes and container artifacts back to the underlying node, namespace, pod, service account, ingress path, workload owner, and exposed service.
· Correlate security agent health with any telemetry gaps observed during the suspected exposure period.
Artifact Confidence Position
· High-confidence artifacts combine suspicious request activity, plausible vulnerable route or exposed asset context, NGINX service instability, and post-request process, file, egress, identity, cloud, Kubernetes, or downstream application behavior.
· Moderate-confidence artifacts include suspicious request activity with partial route context, service instability, source clustering, or limited post-request evidence.
· Low-confidence artifacts include standalone malformed requests, standalone worker crashes, standalone egress, cloud inventory alone, vulnerable-state exposure alone, or cloud-control-plane activity without workload-side corroboration.
· Cloud artifacts support prioritization and blast-radius investigation, but they do not independently confirm local NGINX exploitation.
· Artifact confidence should decrease when activity aligns with approved scanning, patch validation, synthetic monitoring, QA testing, deployment activity, package management, certificate renewal, service reloads, health checks, or approved incident-response activity.
S28 — Detection Strategy and SOC Implementation Guidance

Figure 5
SOC Implementation Objective
This section provides operational guidance for deploying, triaging, tuning, and escalating the NGINX Rift detection strategy. SOC handling must separate exposed vulnerable-state context, suspected exploit attempts, likely denial-of-service impact, probable exploitation, confirmed compromise, and cloud or workload blast-radius activity.
The SOC should not treat malformed requests, vulnerable-version exposure, cloud control-plane events, network-only activity, service instability, or NGINX presence as confirmed exploitation without behavioral corroboration. The primary SOC objective is to detect and contain the transition from suspicious request activity into service instability, workload execution, outbound communication, backend access, credential access, or cloud-side blast-radius behavior.
Operational Detection Strategy
· Deploy request-path and exposed-service detections first for internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent infrastructure.
· Use SIEM correlation to connect suspicious request activity, route context, NGINX error-log artifacts, service instability, endpoint process activity, file activity, egress, identity activity, cloud activity, Kubernetes activity, and downstream application behavior.
· Use endpoint detections to identify suspicious child-process execution, file activity, credential access, mounted-secret access, and process-to-network activity from NGINX-related context.
· Use NDR and network telemetry to identify unusual egress, direct IP communication, suspicious DNS activity, backend access, metadata access, and internal expansion after exploit-path indicators.
· Use cloud-native detections to prioritize exposed cloud-hosted NGINX workloads and detect cloud-control-plane or identity activity after suspected workload compromise.
· Use Kubernetes and container telemetry to assess pod restarts, crash-loop behavior, mounted-secret access, service-account activity, workload modification, ingress changes, and internal service probing.
· Use YARA only if future stable malware, webshell, dropper, malicious module, memory artifact, file artifact, or payload evidence emerges.
· Do not force artifact-only or network-only detections into direct exploitation confirmation.
Deployment Scaling Position
CyberDax detection guidance is designed to support scaled deployment across small, mid-size, enterprise, and cloud-native environments. Scaling should adjust deployment scope, enrichment depth, triage ownership, and operational routing based on NGINX telemetry maturity, exposed-service coverage, host criticality, cloud context, Kubernetes and container visibility, web infrastructure complexity, and SOC operating model. Scaling must not weaken the behavioral evidence required to distinguish exploit attempts, likely denial-of-service impact, probable exploitation, confirmed compromise, and post-exploitation blast-radius activity.
SOC Triage Flow
Step 1: Confirm Exposure Context
· Determine whether the affected service is internet-facing or reachable through a public CDN, WAF, load balancer, gateway, ingress controller, reverse proxy tier, public IP, public DNS name, or externally reachable route.
· Confirm whether the affected asset is NGINX-backed, NGINX Plus-backed, reverse proxy-backed, ingress-backed, gateway-backed, WAF-adjacent, or customer-facing.
· Confirm whether the affected service fronts authentication portals, customer applications, payment flows, API gateways, administrative interfaces, identity infrastructure, regulated data paths, or high-value upstream applications.
· Confirm whether the affected route uses rewrite-heavy configuration, rewrite directives, set directives, capture-based routing, complex path handling, or application paths plausibly exposed to the NGINX Rift exploit path.
· Validate whether the vulnerability finding is active, stale, suppressed, resolved, unknown, mitigated, or tied to a decommissioned asset.
Step 2: Review Suspicious Request Activity
· Review raw URI values where available.
· Review normalized URI values where available.
· Review query strings where available.
· Review request methods, host headers, forwarded headers, user agents, source IPs, ASNs, geolocation, hosting providers, and source reputation.
· Identify excessive URI length, repeated encoding, double encoding, abnormal delimiter density, malformed path structures, abnormal path expansion, suspicious query structure, uncommon methods, malformed headers, or request-normalization failures.
· Determine whether requests targeted rewrite-heavy routes, authentication paths, API paths, ingress paths, gateway paths, administrative portals, customer-facing virtual hosts, or high-dependency upstream routes.
· Determine whether approved scanners, emergency patch validation, synthetic monitoring, QA testing, load balancer probes, CDN health checks, or sanctioned testing explain the activity.
Step 3: Validate Service Instability
· Review NGINX error logs for worker crashes, segmentation fault indicators, abnormal worker exits, reload failures, request-processing failures, upstream resets, or service termination artifacts.
· Review service-health telemetry for route-specific failures, backend 5xx spikes, gateway failures, health-check failures, latency increases, or sudden availability degradation.
· Review container and Kubernetes telemetry for pod restarts, container restarts, crash-loop behavior, readiness probe failures, liveness probe failures, node pressure, or workload rescheduling.
· Determine whether instability occurred shortly after suspicious request activity and whether timing supports request-to-instability correlation.
· Determine whether instability can be explained by deployment activity, patching, package updates, certificate changes, scaling events, dependency failures, misconfiguration, resource pressure, or authorized testing.
Step 4: Review Workload Execution
· Review EDR or host telemetry for child-process execution from NGINX master, worker, ingress-controller, reverse proxy, gateway, WAF-adjacent, containerized NGINX, or service-account lineage.
· Review command-line arguments for remote retrieval, encoded execution, inline script execution, temporary-directory execution, credential access, metadata service access, mounted-secret access, archive extraction, output redirection, or writable-path execution.
· Review process user, service account, working directory, process hash, binary path, parent process, ancestor process chain, container context, workload identity, and host identity.
· Determine whether process execution followed suspicious request activity, service instability, NGINX error-log artifacts, route-specific degradation, file activity, or egress behavior.
· Exclude approved deployment automation, package updates, certificate renewal, configuration management, security testing, incident response, service reloads, and documented administrative workflows when behavior is consistent with expected context.
Step 5: Review File, Credential, and Persistence Activity
· Review file creation, file modification, permission changes, ownership changes, executable-bit changes, symbolic link creation, archive extraction, file deletion, and credential-file access.
· Review activity under web-accessible directories, temporary directories, writable application paths, mounted volumes, NGINX configuration paths, reverse proxy configuration paths, ingress configuration paths, gateway configuration paths, service-unit paths, startup paths, cron paths, SSH material paths, credential paths, cloud credential paths, Kubernetes mounted-secret paths, container writable layers, and monitoring-agent paths.
· Identify new shell scripts, ELF binaries, web-accessible artifacts, encoded payloads, downloaded tools, archive files, service-unit files, startup scripts, credential files, or suspicious configuration changes.
· Determine whether file activity followed suspicious request activity, worker instability, suspicious process execution, unusual outbound communication, credential access, cloud-control-plane activity, or Kubernetes activity.
· Exclude package-managed configuration writes, certificate-renewal writes, approved deployments, approved configuration management, approved service reloads, approved container image updates, and documented maintenance when behavior matches expected context.
Step 6: Assess Egress, Backend Access, and Metadata Access
· Review outbound connections from NGINX-backed hosts, containers, workloads, nodes, ingress controllers, gateways, reverse proxies, and cloud workloads.
· Review DNS queries from affected assets.
· Review destination IP, domain, hostname, port, protocol, TLS SNI, HTTP host, user agent, session duration, byte count, connection count, destination reputation, destination category, destination ASN, destination geolocation, and first-seen context.
· Identify rare destinations, newly observed destinations, direct IP communication, dynamic DNS, temporary hosting, paste services, file-sharing services, tunneling services, unapproved cloud services, unusual ports, abnormal session duration, high byte count, repeated rare-destination contact, or beacon-like timing.
· Review backend access to internal APIs, databases, identity services, Kubernetes APIs, metadata endpoints, secret stores, CI/CD systems, artifact repositories, management interfaces, administrative services, and regulated data paths.
· Determine whether egress or backend access followed suspicious request activity, worker instability, process execution, file activity, credential access, mounted-secret access, or cloud-control-plane activity.
Step 7: Review Cloud, Identity, Container, and Kubernetes Blast Radius
· Review cloud-control-plane events tied to workload identities, IAM roles, instance profiles, task roles, managed identities, service principals, service accounts, workload identities, and Kubernetes service accounts associated with NGINX-backed assets.
· Review AWS CloudTrail, GuardDuty, Security Hub, IAM, STS, Secrets Manager, SSM, EC2, EKS, ECS, KMS, S3, ECR, task roles, and instance profile activity where applicable.
· Review Azure Activity Logs, Microsoft Entra ID telemetry, managed identities, service principals, Key Vault, Storage, Compute, Network, AKS, role assignments, VM Run Command, and VM extension activity where applicable.
· Review GCP Cloud Audit Logs, Data Access logs, Security Command Center findings, service accounts, workload identities, IAM policy changes, service account key creation, Secret Manager, Cloud Storage, Cloud KMS, GKE, Compute Engine, firewall changes, image creation, and snapshot activity where applicable.
· Review Kubernetes audit activity, node activity, service account use, mounted secrets, role bindings, ingress modifications, workload modifications, runtime context, and namespace exposure.
· Treat cloud, Kubernetes, container, and identity activity as post-exploitation or blast-radius evidence only when workload-side or exploit-path context supports the sequence.
Escalation Criteria
Exploit Attempt Escalation
· Suspicious request-shape activity targets an exposed NGINX-backed route plausibly associated with rewrite-heavy behavior or vulnerable configuration context.
· No confirmed service instability, endpoint execution, egress, file activity, credential access, cloud-control-plane behavior, or downstream impact is observed.
· Escalation should focus on route review, source clustering, patch validation, WAF review, logging preservation, and targeted hunting.
Likely Denial-of-Service Impact Escalation
· Suspicious request-shape activity is followed by NGINX worker instability, segmentation fault indicators, abnormal worker exits, service restarts, route-specific 500-series spikes, container restarts, pod restarts, gateway failures, or service degradation.
· No endpoint execution or post-exploitation behavior is confirmed.
· Escalation should include service stabilization, evidence preservation, patch validation, route exposure review, WAF tuning, and expanded hunting across similarly configured assets.
Probable Exploitation Escalation
· Suspicious request-shape activity or service instability is followed by suspicious process execution, file activity, unusual egress, backend access, metadata access, credential access, identity activity, cloud-control-plane activity, or Kubernetes activity.
· Evidence supports a coherent request-to-workload or request-to-cloud sequence, but confirmed data impact or attacker objective is not yet validated.
· Escalation should include containment planning, affected workload isolation, credential rotation scope, forensic preservation, cloud identity review, backend access review, and broader enterprise hunting.
Confirmed Compromise Escalation
· Corroborated evidence shows exploit-path activity followed by validated post-exploitation behavior such as attacker-controlled process execution, malicious file placement, credential theft, persistence, unauthorized cloud-control-plane use, unauthorized backend access, data movement, or confirmed downstream application impact.
· Escalation should include incident response, containment, eradication, credential rotation, affected service rebuild or redeployment, upstream dependency review, customer-impact assessment where applicable, and executive escalation.
Tuning Guidance
· Tune approved vulnerability scanners, emergency patch validation, QA testing, synthetic monitoring, uptime monitoring, CDN health checks, load balancer probes, and sanctioned security testing.
· Tune approved Linux administration, package management, certificate renewal, service management, deployment automation, configuration management, monitoring agents, security tooling, and incident-response activity.
· Tune by asset role because customer-facing reverse proxies, API gateways, ingress controllers, WAF-adjacent services, cloud workloads, and Kubernetes nodes may generate different expected behavior.
· Preserve high-priority routing for internet-facing, unpatched, rewrite-heavy, authentication-facing, API-facing, administrative, payment-flow, identity-facing, regulated-data, or business-critical NGINX-backed services.
· Do not suppress suspicious request-to-instability sequences solely because scanning is common.
· Do not suppress suspicious child-process execution, credential access, or unusual egress solely because the host has administrative activity.
· Keep broad malformed-request, crash-only, egress-only, and cloud-event-only logic in hunt mode unless constrained by asset context, route context, exploit-path context, and corroborating telemetry.
Containment Guidance
· Preserve NGINX access logs, NGINX error logs, WAF logs, load balancer logs, gateway logs, ingress logs, endpoint telemetry, crash metadata, file telemetry, DNS logs, network flow logs, cloud-control-plane logs, Kubernetes logs, and application logs before disruptive remediation.
· Isolate affected NGINX hosts, containers, pods, workloads, or service tiers when probable exploitation or confirmed compromise is supported by host, cloud, network, identity, or downstream evidence.
· Rotate credentials, service-account tokens, cloud keys, API keys, managed identities, IAM roles, task roles, service principals, workload identities, Kubernetes secrets, and application secrets exposed to affected workloads.
· Review upstream application access, backend API access, database access, identity-provider access, secret-store access, CI/CD access, artifact repository access, management-interface access, and regulated-data-path access.
· Patch or rebuild affected NGINX systems and validate that rewrite-path exposure is addressed.
· Reassess WAF, CDN, load balancer, gateway, ingress, reverse proxy, route, and egress controls after remediation.
· Expand hunting to similarly configured NGINX-backed assets, reverse proxy tiers, ingress services, gateway services, WAF-adjacent services, cloud workloads, and Kubernetes namespaces.
SOC Reporting Requirements
· Report exploit attempts separately from likely denial-of-service impact.
· Report likely denial-of-service impact separately from probable exploitation.
· Report probable exploitation separately from confirmed compromise.
· Report post-exploitation cloud, Kubernetes, container, identity, backend, or downstream application activity separately from the initial request path.
· Document whether raw URI values, normalized URI values, NGINX error logs, endpoint process lineage, file telemetry, egress telemetry, cloud logs, identity logs, Kubernetes logs, and application logs were available, absent, incomplete, or not collected.
· Document telemetry gaps, agent-health issues, missing process ancestry, missing command line, missing file telemetry, missing cloud logs, missing Kubernetes logs, missing route context, missing dependency maps, or missing identity mapping.
· Document containment actions, credential rotation decisions, patch validation status, workload rebuild status, node replacement status, and recovery-confidence evidence.
Implementation Position
The SOC implementation model should prioritize behavioral correlation over static indicators. The strongest operational posture combines exposed asset context, suspicious request activity, NGINX error-log artifacts, service instability, suspicious process execution, file activity, unusual egress, identity activity, cloud-control-plane behavior, Kubernetes telemetry, backend access, and downstream application impact. This approach preserves accuracy while avoiding overstatement from malformed requests alone, cloud-only events, network-only detections, service instability alone, or artifact-only assumptions.
S29 — Detection Coverage Summary
Coverage Summary Objective
· This section summarizes detection coverage across the finalized S25 rule set.
· Coverage is assessed by observable behavior, telemetry type, and system role.
· The rule set prioritizes deployable behavioral detection over fragile artifact matching.
· The strongest coverage is achieved when web telemetry, NGINX error logs, host behavior, network behavior, identity context, workload context, and cloud-control-plane telemetry are correlated.
Overall Coverage Position
· Coverage is strong for suspicious request activity against exposed NGINX-backed infrastructure.
· Coverage is strong for request-to-instability correlation where NGINX access logs, NGINX error logs, health telemetry, and route context are available.
· Coverage is strong for post-request child-process execution where endpoint process telemetry and process ancestry are available.
· Coverage is strong for suspicious file, credential, mounted-secret, configuration, and persistence activity where file-event telemetry is available.
· Coverage is strong for unusual egress and backend access where DNS, proxy, firewall, flow, NDR, endpoint-network, or cloud flow telemetry is available.
· Coverage is moderate for cloud-control-plane and identity activity because cloud events require accurate workload identity mapping and host-side or request-side corroboration.
· Coverage is moderate for container and Kubernetes activity because pod, node, namespace, service-account, and workload identity mapping may be incomplete.
· Coverage is limited for direct memory-corruption visibility because exploit-level memory telemetry is not universally available.
· Coverage is intentionally absent for YARA because no stable artifact anchor exists.
Coverage by Threat Behavior
Suspicious Exposed Request Activity
· Coverage level: strong.
· Covered by NDR / Network Behavioral Analytics, Splunk, Elastic, QRadar, SIGMA, AWS, Azure, and GCP.
· Detection value includes exploit-attempt identification, route prioritization, source clustering, WAF review, and hunt scoping.
· Coverage depends on raw URI visibility, normalized URI visibility, source IP preservation, route mapping, exposed asset tagging, scanner allowlists, and request-field fidelity.
· Request activity alone does not confirm exploitation.
Request-to-Service Instability
· Coverage level: strong.
· Covered by NDR / Network Behavioral Analytics, Splunk, Elastic, QRadar, SIGMA, AWS, Azure, and GCP.
· Detection value includes likely denial-of-service assessment and confidence-building when suspicious request activity precedes instability.
· Coverage depends on NGINX error logs, service-health telemetry, load balancer telemetry, container restart telemetry, pod restart telemetry, and timestamp normalization.
· Service instability does not confirm exploitation without suspicious request context or follow-on behavior.
Suspicious Child-Process Execution
· Coverage level: strong.
· Covered by SentinelOne, Splunk, Elastic, QRadar, and SIGMA.
· Detection value includes identifying one of the strongest behavioral anchors for probable exploitation.
· Coverage depends on process ancestry, command-line capture, parent process context, service-account context, endpoint coverage, container context, and workload identity.
· Child-process execution requires exploit-path or service-instability correlation for NGINX Rift attribution.
Suspicious File, Credential, and Persistence Activity
· Coverage level: strong.
· Covered by SentinelOne, Splunk, Elastic, QRadar, and SIGMA.
· Detection value includes identifying file staging, credential access, mounted-secret access, configuration modification, service modification, startup modification, and persistence behavior.
· Coverage depends on file-event visibility, sensitive path inventories, process attribution, expected-change baselines, container path mapping, and workload context.
· File activity requires process, request, instability, identity, network, cloud, or downstream corroboration for exploitation confidence.
Unusual Egress and Backend Access
· Coverage level: strong.
· Covered by NDR / Network Behavioral Analytics, SentinelOne, Splunk, Elastic, QRadar, SIGMA, AWS, Azure, and GCP.
· Detection value includes identifying callback, payload retrieval, staging, tunneling, direct IP egress, suspicious DNS activity, metadata access, backend probing, and sensitive destination access.
· Coverage depends on DNS visibility, proxy visibility, firewall visibility, flow telemetry, endpoint-network telemetry, destination enrichment, dependency maps, process-to-network attribution, and workload identity.
· Egress or backend access alone does not confirm exploitation.
Cloud Credential and Control-Plane Activity
· Coverage level: moderate to strong.
· Covered by AWS, Azure, GCP, Splunk, Elastic, and QRadar as correlated escalation context.
· Detection value includes identifying cloud blast-radius behavior after suspected workload compromise.
· Coverage depends on CloudTrail, Azure Activity Logs, GCP Cloud Audit Logs, cloud Data Access logs, identity mapping, role mapping, managed identity mapping, service account mapping, approved automation baselines, and host or workload telemetry.
· Cloud-control-plane activity alone does not confirm NGINX Rift exploitation.
Container and Kubernetes Activity
· Coverage level: moderate to strong.
· Covered by SentinelOne, Splunk, Elastic, QRadar, SIGMA, AWS, Azure, and GCP where telemetry is available.
· Detection value includes identifying pod restarts, container restarts, abnormal process execution, mounted-secret access, service-account use, workload modification, ingress changes, internal probing, and node-level blast radius.
· Coverage depends on Kubernetes audit logs, container runtime telemetry, node mapping, namespace context, service account context, workload ownership, and endpoint telemetry.
· Kubernetes activity requires request, workload, identity, or host correlation for exploitation confidence.
Artifact-Based Detection
· Coverage level: not currently deployed.
· YARA rule count: 0.
· Detection value is deferred until stable artifact evidence exists.
· YARA may become useful for future malware, webshell, dropper, malicious NGINX module, memory artifact, file artifact, or payload discovery.
· Static artifact detection is not appropriate in the current report.
Direct Memory-Corruption Visibility
· Coverage level: conditional.
· No finalized S25 rule requires direct memory-corruption telemetry.
· Direct evidence may support SentinelOne, Splunk, Elastic, QRadar, or SIGMA-backed workflows if crash, coredump, EDR exploit-prevention, kernel, or runtime telemetry is available.
· Coverage depends on specialized telemetry collection and operationally safe evidence handling.
· The rule set remains useful without universal memory-level visibility.
Coverage by System
NDR / Network Behavioral Analytics
· Coverage level: strong.
· Rule count: 3.
· Coverage includes suspicious request activity, unusual outbound communication, backend access, metadata access, and internal expansion.
· Coverage depends on network-flow telemetry, DNS telemetry, proxy telemetry, firewall telemetry, HTTP metadata, exposed-service tagging, destination enrichment, dependency maps, and SIEM correlation.
· NDR does not directly confirm local worker memory corruption or host process execution.
SentinelOne
· Coverage level: strong.
· Rule count: 3.
· Coverage includes suspicious child-process execution, suspicious file or credential activity, and outbound network activity initiated by NGINX-related child processes.
· Coverage depends on endpoint telemetry, process ancestry, command-line capture, file-event visibility, process-to-network attribution, service-account context, container context, and tenant field validation.
· SentinelOne does not directly observe raw request shape unless correlated through SIEM or log enrichment.
Splunk
· Coverage level: strong.
· Rule count: 3.
· Coverage includes suspicious request activity, request-to-instability correlation, process execution, file activity, egress, backend access, and multi-source correlation.
· Coverage depends on index quality, sourcetype validation, field extraction, CIM or field normalization, lookup accuracy, timestamp normalization, and enrichment validation.
Elastic
· Coverage level: strong.
· Rule count: 3.
· Coverage includes suspicious request activity, process execution, file activity, egress, backend access, and sequence-based correlation.
· Coverage depends on ECS field quality, data view coverage, ingestion fidelity, EQL or KQL support, transform quality, and enrichment validation.
QRadar
· Coverage level: moderate to strong.
· Rule count: 3.
· Coverage includes suspicious request activity, host-side behavior, egress, backend access, and offense-building through rule-chain correlation.
· Coverage depends on DSM parsing, custom properties, reference sets, log-source coverage, building blocks, offense tuning, and vulnerability or asset enrichment.
SIGMA
· Coverage level: moderate to strong.
· Rule count: 3.
· Coverage includes portable detection logic for suspicious request activity, child-process execution, file activity, unusual egress, and backend access.
· Coverage depends on backend translation, field mapping, log-source availability, sequence support, correlation support, exception handling, and enrichment.
YARA
· Coverage level: no current coverage.
· Rule count: 0.
· Coverage is intentionally excluded because no stable artifact anchor exists.
· Future coverage depends on stable malware, webshell, dropper, malicious module, memory artifact, file artifact, or payload evidence.
AWS
· Coverage level: moderate to strong.
· Rule count: 3.
· Coverage includes AWS-exposed NGINX service prioritization, request-shape activity, service instability, IAM role activity, cloud credential activity, egress, backend access, metadata access, DNS activity, and AWS control-plane blast-radius indicators.
· Coverage depends on AWS WAF, CloudFront, ALB, CloudTrail, GuardDuty, Security Hub, Config, VPC Flow Logs, Route 53 Resolver logs, IAM role mapping, ECS inventory, EKS inventory, tagging, approved automation baselines, and workload telemetry.
· AWS coverage supports cloud-side investigation but does not replace host or workload telemetry.
Azure
· Coverage level: moderate to strong.
· Rule count: 3.
· Coverage includes Azure-exposed NGINX service prioritization, request-shape activity, service instability, managed identity activity, service principal activity, egress, backend access, metadata access, DNS activity, and Azure control-plane blast-radius indicators.
· Coverage depends on Front Door, Application Gateway, WAF, Azure Activity Logs, Microsoft Entra ID, Defender for Cloud, Defender for Endpoint, NSG Flow Logs, Azure Firewall logs, DNS logs, managed identity mapping, AKS inventory, VM and VMSS context, approved automation baselines, and workload telemetry.
· Azure coverage supports cloud-side investigation but does not replace host or workload telemetry.
GCP
· Coverage level: moderate to strong.
· Rule count: 3.
· Coverage includes GCP-exposed NGINX service prioritization, request-shape activity, service instability, service account activity, workload identity activity, egress, backend access, metadata access, DNS activity, and GCP control-plane blast-radius indicators.
· Coverage depends on Cloud Armor, external HTTP load balancer logs, Cloud Audit Logs, Data Access logs, Security Command Center, Cloud Asset Inventory, VPC Flow Logs, Cloud DNS logs, service account mapping, GKE inventory, Compute Engine context, labels, approved automation baselines, and workload telemetry.
· GCP coverage supports cloud-side investigation but does not replace host or workload telemetry.
Coverage Strengths
· The rule set emphasizes behavior that is difficult for attackers to remove from the exploitation sequence.
· Web and SIEM coverage targets suspicious request activity and request-to-instability sequencing.
· Host coverage targets suspicious process execution, file activity, credential access, and process-to-network behavior.
· NDR and cloud flow coverage target unusual egress, backend access, metadata access, and internal expansion.
· Cloud-native coverage improves exposed-service prioritization and blast-radius detection.
· YARA is appropriately excluded because no stable artifact anchor exists.
· The rule set does not depend on brittle proof-of-concept names, hashes, static strings, single request examples, or vendor alert names.
· The rule set does not require universal memory-corruption telemetry.
Coverage Gaps
· Raw URI values may be unavailable where CDN, WAF, load balancer, gateway, ingress, or reverse proxy layers normalize or truncate request data.
· NGINX error-log detail may be insufficient to prove exploit behavior without request, crash, endpoint, or workload corroboration.
· Endpoint process visibility may vary across hardened edge systems, managed deployments, appliances, containers, ingress nodes, or ephemeral workloads.
· File-event visibility may vary across endpoint, Linux audit, SIEM, and backend platforms.
· Process-to-network attribution may be incomplete.
· Container-to-host and Kubernetes node mapping may be incomplete.
· Cloud identity mapping may be incomplete for roles, managed identities, service accounts, task roles, instance profiles, and workload identities.
· Vulnerability findings may lag actual patch state.
· Approved scanner, automation, and dependency baselines may be incomplete during early deployment.
· Static artifact detection remains unavailable until stable artifact evidence emerges.
Final Coverage Assessment
· The finalized rule set provides strong practical coverage for NGINX Rift detection and triage when web, NGINX error-log, endpoint, network, identity, cloud, Kubernetes, and workload telemetry are available.
· The strongest detection path is behavioral correlation across suspicious request activity, exposed route context, NGINX service instability, post-request process execution, file activity, unusual egress, backend access, and identity or cloud-control-plane activity.
· Cloud-native coverage is valuable for prioritization and blast-radius detection, but it does not replace workload-side or host-side telemetry.
· Static artifact detection is not currently appropriate because no stable artifact anchor exists.
· The residual detection risk is highest in environments with weak request logging, missing NGINX error logs, poor endpoint telemetry, incomplete route inventory, limited egress visibility, weak identity mapping, incomplete cloud logging, or short telemetry retention.
S30 — Intelligence Maturity Assessment
Maturity Assessment Objective
· This section assesses the maturity required to detect, investigate, and respond to NGINX Rift exploit-path activity with confidence.
· Intelligence maturity is based on the organization’s ability to connect exposed service context, route-level request behavior, NGINX instability, host behavior, egress behavior, identity context, cloud workload context, Kubernetes context, and SOC response workflows.
· The maturity model separates exposed vulnerable-state awareness from exploit-attempt detection, likely denial-of-service impact, probable exploitation, confirmed compromise, and post-exploitation blast-radius response.
Overall Maturity Position
· Current maturity requirement: moderate to high.
· Baseline detection is achievable with NGINX access logs, NGINX error logs, exposed asset inventory, route context, source context, scanner allowlists, and SIEM correlation.
· High-confidence detection requires stronger endpoint process telemetry, command-line capture, file-event visibility, egress telemetry, destination enrichment, workload identity mapping, cloud-control-plane visibility, Kubernetes mapping, and sufficient telemetry retention.
· Advanced maturity requires mature cross-domain correlation across web, endpoint, file, network, identity, cloud, Kubernetes, container, and application telemetry.
· The rule set is designed to remain operationally useful even without universal memory-corruption telemetry or stable artifact signatures.
Maturity Dimension 1: Exposure and Route Intelligence
Current Requirement
· Maintain accurate visibility into internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, and NGINX-backed application infrastructure.
Maturity Indicators
· Exposed NGINX-backed assets are current and tied to active services.
· Public DNS, public IP, CDN, WAF, load balancer, gateway, ingress, and reverse proxy paths are mapped.
· Rewrite-heavy routes, authentication paths, API paths, administrative paths, customer-facing virtual hosts, and high-dependency upstream routes are identified.
· Asset criticality and workload ownership are populated.
· Patch state, compensating controls, and exposure state are validated historically.
Maturity Gaps
· Asset inventory may lag reality.
· Route mapping may be incomplete.
· Rewrite-heavy configuration inventory may be missing.
· Public exposure may be hidden behind CDN, WAF, load balancer, gateway, ingress, or shared reverse proxy infrastructure.
· Patch status may be known without route-level compensating-control validation.
Improvement Priority
· Improve exposed NGINX asset inventory.
· Preserve historical exposure and patch state.
· Strengthen route-level mapping for rewrite-heavy paths.
· Require owner, criticality, exposure, and route metadata for high-value NGINX-backed services.
Maturity Dimension 2: Web and NGINX Telemetry Intelligence
Current Requirement
· Capture NGINX access logs, NGINX error logs, WAF logs, CDN logs, load balancer logs, gateway logs, ingress logs, request metadata, response telemetry, and route-level context.
Maturity Indicators
· Raw URI values are preserved where possible.
· Normalized URI values are preserved where possible.
· Source IP and forwarded-header context are retained.
· NGINX error logs capture worker crashes, segmentation faults, abnormal exits, reload failures, upstream resets, and route-specific failures.
· Request telemetry can be correlated with service instability and route-level response behavior.
Maturity Gaps
· Request values may be normalized, truncated, rewritten, discarded, or aggregated before logging.
· NGINX error logs may lack route, virtual-host, request, upstream, or worker context.
· Source IP preservation may fail across CDN, WAF, load balancer, gateway, ingress, or proxy layers.
· High-volume scanning may create false-positive pressure.
· Timestamps may not be synchronized across web and infrastructure telemetry.
Improvement Priority
· Preserve raw and normalized request values.
· Validate NGINX error-log parsing.
· Preserve source IP and forwarded-header context.
· Align timestamps across request, error, load balancer, WAF, gateway, and ingress telemetry.
· Build scanner and validation-source allowlists without broad suppressions.
Maturity Dimension 3: Host and Workload Behavior Intelligence
Current Requirement
· Capture process creation, command line, executable path, working directory, parent process context, service-account context, file-event telemetry, and process-to-network telemetry where available.
Maturity Indicators
· Suspicious child-process execution from NGINX-related lineage can be detected.
· Command-line arguments are captured.
· Parent and ancestor process context is available.
· File activity under sensitive paths is visible.
· Process-to-network attribution is available.
· Security agent health is visible.
Maturity Gaps
· Command-line capture may be incomplete.
· Parent process fidelity may vary.
· File-event coverage may be inconsistent.
· Process-to-network attribution may be unavailable.
· Containerized or managed NGINX deployments may obscure host behavior.
· Agent coverage may be incomplete on hardened edge systems, appliances, ingress nodes, minimal Linux builds, or ephemeral workloads.
Improvement Priority
· Ensure command-line capture is enabled.
· Validate process ancestry fidelity.
· Expand sensitive file and credential-path telemetry.
· Validate process-to-network attribution.
· Monitor EDR, audit, cloud agent, container security, and telemetry-forwarding health.
Maturity Dimension 4: Network and Dependency Intelligence
Current Requirement
· Capture DNS, proxy, firewall, NetFlow, cloud flow, endpoint-network, and NDR telemetry for NGINX-backed hosts, containers, workloads, nodes, and reverse proxy tiers.
Maturity Indicators
· Outbound communication from NGINX-backed workloads can be attributed to the correct host, container, workload, node, or service identity.
· Destination reputation, category, ASN, geolocation, first-seen context, and domain age are available.
· Approved egress baselines are documented.
· Backend dependency maps are maintained.
· Sensitive destinations such as databases, identity services, secret stores, metadata endpoints, Kubernetes APIs, CI/CD systems, artifact repositories, and management interfaces are tagged.
Maturity Gaps
· NAT, service mesh, proxy chaining, cloud networking, and container networking may obscure source attribution.
· Destination enrichment may be incomplete.
· Dependency maps may be stale or missing.
· Approved egress baselines may be immature.
· Metadata endpoint and sensitive backend access may not be logged consistently.
Improvement Priority
· Build approved egress baselines for NGINX-backed services.
· Build sensitive destination maps.
· Improve workload-to-network attribution.
· Validate DNS, proxy, firewall, flow, and cloud-flow logging.
· Correlate egress and backend access with exploit-path and workload behavior before escalation.
Maturity Dimension 5: Container and Kubernetes Intelligence
Current Requirement
· Map suspicious NGINX workload activity to the underlying container, pod, namespace, node, service account, ingress route, workload owner, and cluster context.
Maturity Indicators
· Container ID, pod, namespace, service account, node, workload owner, image, and ingress context are available.
· Kubernetes node-level telemetry can be linked to workload activity.
· Pod restarts, crash-loop behavior, mounted-secret access, service-account use, workload modification, role-binding changes, and ingress changes are visible.
· GKE, EKS, and AKS workload identities can be mapped to cloud identities and NGINX-backed services.
Maturity Gaps
· Container-to-host mapping may be incomplete.
· Kubernetes audit data may not align with endpoint telemetry.
· Service-account and namespace ownership may be missing.
· HostPath, mounted-secret, and runtime socket exposure may not be tracked consistently.
· Ephemeral workload replacement may destroy evidence.
Improvement Priority
· Normalize Kubernetes node, pod, namespace, service account, workload owner, ingress, and container-host relationships.
· Track privileged workload placement, hostPath usage, mounted secrets, and runtime exposure.
· Correlate container-originated activity with host-level process, file, network, identity, and cloud telemetry.
· Preserve telemetry before pod rescheduling, container replacement, or node rebuild.
Maturity Dimension 6: Cloud Workload and Identity Intelligence
Current Requirement
· Map cloud roles, managed identities, service accounts, workload identities, instance profiles, task roles, and service principals back to NGINX-backed workloads.
Maturity Indicators
· AWS IAM roles are mapped to EC2 instances, ECS tasks, EKS nodes, container hosts, and NGINX-backed services.
· Azure managed identities and service principals are mapped to VMs, VMSS instances, AKS nodes, and NGINX-backed services.
· GCP service accounts and workload identities are mapped to Compute Engine instances, GKE nodes, container hosts, and NGINX-backed services.
· Cloud audit logs are retained and centrally searchable.
· Data Access, diagnostic, DNS, and flow logs are enabled where operationally required.
· Approved automation baselines are documented.
Maturity Gaps
· Identity-to-workload mapping may be incomplete.
· Cloud Data Access or diagnostic logging may be inconsistent.
· Approved automation baselines may not be mature.
· Cloud activity may be difficult to distinguish from legitimate deployment, backup, observability, or maintenance workflows.
· Cloud activity may be misattributed to NGINX Rift without host-side or workload-side evidence.
Improvement Priority
· Build and maintain role-to-workload, managed-identity-to-workload, service-principal-to-workload, and service-account-to-workload mapping.
· Enable required cloud audit and Data Access logging for sensitive services.
· Establish approved automation baselines.
· Correlate cloud activity with request-side, host-side, workload-side, or egress indicators before escalation.
Maturity Dimension 7: Detection Engineering and Correlation Maturity
Current Requirement
· Correlate exposed asset context, suspicious request activity, service instability, workload execution, file activity, egress, backend access, identity activity, cloud-control-plane behavior, Kubernetes activity, and downstream application evidence.
Maturity Indicators
· SIEM detections can join web telemetry with NGINX error logs, endpoint behavior, file activity, network activity, cloud activity, identity context, Kubernetes context, and application context.
· Rules avoid brittle artifact dependencies.
· Detections preserve evidence boundaries between exploit attempt, likely denial-of-service impact, probable exploitation, confirmed compromise, and blast-radius activity.
· Alert routing reflects asset role, route sensitivity, workload criticality, cloud identity risk, and downstream dependency exposure.
Maturity Gaps
· SIEM normalization may drop critical fields.
· Lookup and enrichment data may be incomplete.
· Correlation windows may be too short or too broad.
· Backend systems may not support sequence detection or rule chaining.
· Rules may require tuning for scanners, synthetic monitoring, deployment workflows, package management, certificate renewal, service reloads, and security tooling.
Improvement Priority
· Validate SIEM field mappings and enrichment paths before production deployment.
· Preserve web, process, file, network, identity, cloud, Kubernetes, vulnerability, and application context.
· Use short-window correlation for request-to-instability and request-to-execution behavior.
· Use longer-window correlation for delayed callback, cloud activity, backend access, and repeated infrastructure reuse.
· Route high-priority alerts involving authentication portals, API gateways, payment flows, administrative interfaces, identity infrastructure, regulated data paths, and cloud identities.
Maturity Dimension 8: SOC Response Maturity
Current Requirement
· SOC teams must triage NGINX Rift alerts using evidence sequence, corroboration strength, operational context, and containment impact.
Maturity Indicators
· Analysts can distinguish exploit attempts from likely denial-of-service impact.
· Analysts can distinguish probable exploitation from confirmed compromise.
· Analysts can validate request-to-instability, request-to-process, process-to-file, process-to-network, and workload-to-cloud sequences.
· Analysts can identify whether cloud identity activity maps back to an affected NGINX-backed workload.
· Incident response can preserve telemetry before rebuild, pod replacement, service restart, workload termination, or emergency patching.
· Credential rotation and cloud containment workflows are defined.
Maturity Gaps
· Web, endpoint, SIEM, cloud, Kubernetes, vulnerability, and application teams may operate with incomplete shared context.
· Analysts may over-escalate request-only findings or under-escalate post-request execution and cloud activity.
· Cloud role, managed identity, service principal, or service account ownership may be unclear.
· Ephemeral workload replacement may destroy evidence.
· Emergency patching may occur before evidence is preserved.
Improvement Priority
· Standardize triage playbooks for exploit attempt, likely denial-of-service impact, probable exploitation, confirmed compromise, and blast-radius cases.
· Preserve telemetry before terminating, rebuilding, draining, replacing, restarting, or remediating affected workloads.
· Define credential rotation and identity containment workflows.
· Establish owner notification paths for exposed high-value NGINX-backed services.
· Retain telemetry across the suspected exposure and post-exploitation window.
Maturity Dimension 9: Intelligence Confidence
High Confidence
· Suspicious request activity, exposed route context, NGINX service instability, and post-request process, file, egress, identity, cloud, Kubernetes, or downstream application behavior are correlated.
· Cloud identity activity is mapped to the affected workload and occurs after request-side or host-side exploit-path indicators.
· Web, endpoint, file, network, identity, cloud, Kubernetes, and application telemetry are complete enough to reconstruct the sequence.
Moderate Confidence
· Suspicious request activity is present with partial route context, service instability, source clustering, or limited post-request evidence.
· Cloud-control-plane activity is suspicious but host-side or request-side evidence is incomplete.
· Container or Kubernetes activity is suspicious but workload-to-route or workload-to-host mapping is incomplete.
Low Confidence
· Only malformed request activity is present.
· Only NGINX vulnerable-state exposure is present.
· Only worker instability is present.
· Only cloud inventory or cloud activity exists without workload-side or request-side corroboration.
· Only network telemetry exists without host, request, identity, or workload context.
· Only static artifact evidence exists without execution or staging evidence.
Final Intelligence Maturity Assessment
· NGINX Rift detection maturity is strongest in environments with mature web telemetry, NGINX error-log coverage, endpoint telemetry, SIEM correlation, cloud identity mapping, Kubernetes mapping, route inventory, and workload ownership data.
· The current detection model supports practical deployment because it does not depend on universal memory-corruption visibility or stable artifact signatures.
· The highest-value maturity improvements are closing telemetry gaps around raw URI preservation, NGINX error-log fidelity, command-line capture, process ancestry, file-event telemetry, process-to-network attribution, cloud identity mapping, route inventory, dependency mapping, and source IP preservation.
· Organizations with mature web, host, cloud, network, and workload correlation can detect likely exploitation paths and post-compromise blast-radius activity with strong confidence.
· Organizations relying only on malformed request telemetry, vulnerable inventory, network telemetry, cloud inventory, or static artifacts will have limited exploitation confidence and should treat those signals as prioritization or supporting evidence only.
· Mature intelligence improves confidence in suspected exploitation assessment, but no maturity level converts request-only, exposure-only, cloud-only, network-only, service-instability-only, or artifact-only evidence into confirmed NGINX Rift exploitation.
S31 — Telemetry Dependencies
Telemetry Dependency Objective
NGINX Rift detection and response depend on the organization’s ability to correlate exposed web infrastructure, malformed request activity, NGINX worker stability, route-level application behavior, endpoint execution, outbound communication, file activity, cloud context, Kubernetes context, and downstream application telemetry. No single log source should be treated as sufficient by itself. The strongest defensive posture comes from preserving enough telemetry to distinguish scan noise, exploit attempt, service instability, probable compromise, and confirmed post-exploitation.
Web and Reverse Proxy Telemetry
· NGINX access logs should preserve source IP, destination host, virtual host, request method, URI, query string, response code, bytes sent, user agent, referrer, request time, upstream response time, upstream status, request identifier, route context, and host header where available.
· NGINX error logs should preserve worker failures, abnormal worker exits, segmentation fault indicators, reload failures, upstream errors, request-processing failures, rewrite-related anomalies, and virtual-host context where available.
· Reverse proxy logs should preserve route mapping, upstream destination, backend response behavior, request transformation, source attribution, and gateway failure context.
· WAF telemetry should preserve blocked requests, allowed suspicious requests, rule matches, anomaly scoring, normalized URI values, raw URI values where available, header context, source clustering, and policy action.
· CDN telemetry should preserve source IP forwarding context, edge request metadata, normalized path behavior, request filtering, caching behavior, error codes, and origin routing context.
· Load balancer telemetry should preserve upstream reset behavior, backend health, gateway errors, route-level failures, source IP preservation, request timing, and backend service mapping.
· Ingress and gateway telemetry should preserve ingress resource, namespace, service name, route path, annotation context, controller logs, gateway policy, backend workload, and workload ownership.
Crash, Fault, and Service-Health Telemetry
· Service manager logs should capture NGINX reloads, restarts, worker exits, abnormal service stops, failed reload attempts, watchdog recovery, process supervision events, and repeated worker respawns.
· Crash telemetry should capture process name, timestamp, signal, user context, binary path, container context, host identifier, service owner, and crash or coredump metadata where operationally safe.
· Infrastructure monitoring should capture availability degradation, sudden latency changes, route-specific service instability, elevated 500-series responses, upstream failures, gateway failures, and health-check failures.
· Container telemetry should capture container exit codes, restart counts, crash-loop behavior, writable-layer context, image identity, pod association, and container-to-host mapping.
· Kubernetes telemetry should capture pod restarts, readiness probe failures, liveness probe failures, node placement, namespace context, service-account context, workload owner, ingress-controller behavior, and mounted-secret context.
· Application performance monitoring should capture route-specific degradation, backend dependency failures, authentication failures, API errors, transaction failures, upstream latency, and customer-facing access disruption.
Endpoint and Process Telemetry
· EDR telemetry should capture NGINX master process, worker process, ingress-controller process, gateway process, containerized NGINX process, and related service-account lineage.
· Process telemetry should identify unexpected child processes spawned from NGINX-related lineage, including shells, interpreters, downloaders, package managers, archive utilities, network utilities, discovery tools, credential utilities, and service-control utilities.
· Host telemetry should capture command line, executable path, working directory, parent process, child process, source user, effective user, process start time, process termination time, exit status, host identity, and service owner.
· Linux audit or equivalent host telemetry should capture sensitive file access, configuration modification, privilege-relevant execution, service changes, monitoring-agent tampering, and unusual activity by NGINX service accounts.
· Endpoint telemetry should include enough timestamp fidelity to correlate inbound request activity, NGINX instability, process creation, file writes, outbound network activity, and downstream application behavior.
File, Configuration, and Persistence Telemetry
· File telemetry should capture new file creation, file modification, deletion, permission changes, ownership changes, executable-bit changes, symbolic link creation, archive extraction, and suspicious file placement on NGINX hosts or workloads.
· Monitoring should cover web-accessible directories, temporary directories, writable application paths, NGINX configuration paths, reverse proxy configuration paths, ingress paths, gateway paths, mounted volumes, container writable layers, startup paths, service-unit paths, credential paths, cloud credential paths, and Kubernetes mounted-secret paths.
· Configuration monitoring should capture NGINX configuration changes, reverse proxy rule changes, rewrite rule changes, upstream routing changes, WAF-adjacent policy changes, ingress resource changes, gateway policy changes, service-unit changes, container entrypoint changes, deployment manifest changes, and route-level configuration changes.
· Persistence telemetry should capture scheduled task changes, service changes, startup-script modifications, SSH key additions, user-account changes, token access, credential-material access, and monitoring-agent tampering.
· File and configuration telemetry should be correlated with suspicious request activity, service instability, process execution, outbound communication, and vulnerable asset context before being treated as likely exploitation.
Outbound and Network Telemetry
· DNS telemetry should capture lookups from NGINX hosts, containers, nodes, workloads, and service accounts to newly observed domains, rare destinations, suspicious infrastructure, dynamic DNS, tunneling services, infrastructure-like domains, and destinations inconsistent with normal service behavior.
· Proxy telemetry should capture outbound HTTP and HTTPS activity from NGINX hosts, including destination, method, user agent, URI path, response code, bytes transferred, session duration, request timing, and first-seen destination context.
· Firewall telemetry should capture egress connections from NGINX infrastructure to unusual external IP addresses, unusual ports, cloud-hosted infrastructure, anonymization infrastructure, paste sites, file-sharing services, tunneling services, and destinations outside approved dependency lists.
· NetFlow and cloud flow logs should capture outbound connection timing, destination IP, destination port, protocol, byte count, session duration, connection direction, source interface, workload identity, and network boundary context.
· East-west network telemetry should capture internal communication from NGINX infrastructure to backend applications, internal APIs, databases, identity services, Kubernetes APIs, cloud metadata endpoints, secret stores, CI/CD systems, artifact repositories, management interfaces, and regulated data paths.
· Network telemetry should distinguish approved upstream communication from unusual direct internet egress, internal probing, metadata access, backend dependency deviation, and communication initiated by unexpected child processes.
Cloud, Kubernetes, and Container Telemetry
· Cloud telemetry should capture instance identity, workload identity, managed identity use, metadata-service access, security group changes, role use, secret retrieval, storage access, snapshot activity, flow logs, load balancer routing, and control-plane events tied to NGINX-backed infrastructure.
· Kubernetes telemetry should capture ingress activity, service-account use, mounted-secret access, namespace activity, role-binding changes, Kubernetes API access, workload modification, node placement, pod restart behavior, and workload ownership.
· Container runtime telemetry should capture process execution, runtime socket interaction, mounted volumes, image identity, container exit behavior, host namespace exposure, container-to-host relationships, and abnormal activity inside NGINX workloads.
· Service mesh telemetry should capture source workload, destination workload, policy decisions, route behavior, mTLS identity, retry behavior, and abnormal internal service calls where NGINX-backed services participate in mesh communication.
· Cloud and Kubernetes telemetry should be treated as post-exploitation context unless correlated to suspicious request activity, service instability, endpoint behavior, file activity, or outbound communication from the affected NGINX service.
Asset, Vulnerability, and Configuration Context
· Asset inventory must identify internet-facing NGINX services, NGINX Plus services, reverse proxy tiers, ingress controllers, gateway services, WAF-adjacent services, customer-facing applications, API gateways, authentication paths, administrative interfaces, payment workflows, and high-dependency upstream applications.
· Vulnerability-management data must identify affected NGINX versions, NGINX Plus deployments, F5-managed NGINX product status where applicable, patch state, compensating controls, and exposure status.
· Configuration-management data must identify rewrite-heavy deployments, rewrite directives, set directives, capture-based rewrites, virtual-host mappings, ingress paths, gateway routes, reverse proxy tiers, and route ownership.
· Service-owner mapping must identify application owner, business function, upstream dependencies, customer impact, regulatory sensitivity, data-path sensitivity, recovery owner, and escalation owner.
· Asset enrichment should include internet exposure, business criticality, hosted application, route sensitivity, patch state, compensating-control status, WAF/CDN coverage, load balancer context, ingress context, cloud context, Kubernetes context, and logging coverage.
Telemetry Dependency Constraints
· Missing raw URI values can prevent reliable reconstruction of exploit-path request activity.
· Missing normalized URI values can prevent analysts from understanding how CDN, WAF, load balancer, gateway, ingress, or reverse proxy layers transformed the request.
· Missing source IP preservation can prevent source clustering and attacker infrastructure analysis.
· Missing NGINX error logs can prevent correlation between malformed request activity and worker instability.
· Missing crash metadata can prevent reliable assessment of denial-of-service or service-instability outcomes.
· Missing EDR process lineage can prevent confirmation of NGINX-context execution.
· Missing egress telemetry can prevent detection of callback, staging, tool retrieval, tunneling, or data-transfer behavior.
· Missing cloud or Kubernetes telemetry can prevent reliable scoping of downstream exposure.
· Missing route ownership can delay containment, customer-impact assessment, and executive escalation.
· Missing synchronized timestamps can break correlation across request delivery, service instability, process execution, file activity, outbound communication, cloud telemetry, Kubernetes telemetry, and application behavior.
S32 — Detection Limitations
Detection Limitation Overview
NGINX Rift detection is constrained by the quality of request telemetry, NGINX error logging, route mapping, crash visibility, endpoint telemetry, outbound network visibility, asset context, and cloud or Kubernetes enrichment. The detection model should remain conservative because malformed web traffic is common on internet-facing infrastructure and because worker instability can have benign operational causes. Successful exploitation should not be asserted without corroborating telemetry.
Malformed Request Noise
· Internet-facing NGINX services receive high volumes of scanner traffic, malformed requests, bot activity, vulnerability validation, fuzzing, crawler noise, synthetic testing, and opportunistic probing.
· Broad malformed-request detections may generate significant false positives if they are not constrained by exposed asset context, route sensitivity, rewrite exposure, source clustering, response behavior, or service-instability correlation.
· Public proof-of-concept request patterns may be useful for hunting, but they should not define the full detection model.
· Attackers may alter URI structure, encoding, method, headers, source infrastructure, route targeting, user-agent values, and timing to avoid simple request-string detection.
Request Normalization and Logging Gaps
· CDN, WAF, load balancer, gateway, ingress, reverse proxy, and application layers may normalize, truncate, rewrite, aggregate, or discard malformed request attributes before logging.
· Some log pipelines may omit query strings, normalize encoded characters, drop malformed fields, truncate long URIs, or preserve only partial request metadata.
· Raw URI and normalized URI fields may differ, and both may be required to reconstruct exploit-path behavior.
· Source IP context may be obscured by CDN, proxy, NAT, load balancer, gateway, ingress, or shared security infrastructure.
· Request identifiers may not be preserved consistently across CDN, WAF, load balancer, NGINX, upstream application, and SIEM telemetry.
Crash and Instability Attribution Limits
· NGINX worker crashes, service restarts, 500-series spikes, upstream resets, gateway errors, reload failures, container restarts, and pod restarts can result from benign operational issues.
· Benign causes may include application bugs, dependency failures, resource pressure, deployment activity, patch activity, configuration errors, certificate changes, autoscaling, health-check instability, or authorized testing.
· Worker instability should not be treated as confirmed compromise without suspicious request activity, vulnerable configuration context, endpoint telemetry, file activity, egress behavior, or downstream application evidence.
· A lack of crash telemetry does not prove exploitation did not occur, especially in containerized, ephemeral, appliance-based, or managed environments.
Endpoint and Process Visibility Limits
· EDR coverage may be incomplete on hardened edge systems, minimal Linux builds, appliances, managed NGINX deployments, container hosts, Kubernetes nodes, or ephemeral workloads.
· Containerized deployments may lose process, file, crash, and writable-layer evidence during pod restart, rescheduling, image replacement, or emergency remediation.
· NGINX-context execution may be missed if process lineage, command line, user context, working directory, or container identity is unavailable.
· Approved administrative workflows, package updates, certificate renewal, deployment automation, configuration management, and incident response can resemble suspicious file or process activity.
· Successful exploitation assessment should require more than malformed request activity or service instability.
Outbound and Internal Expansion Visibility Limits
· NGINX infrastructure may legitimately communicate with upstream applications, observability platforms, logging systems, package repositories, update repositories, security tools, service mesh endpoints, internal APIs, and management endpoints.
· Missing egress baselines can make it difficult to distinguish attacker callback behavior from normal service dependencies.
· NAT, service mesh, proxy chaining, container networking, and cloud networking can obscure the true source workload or process behind outbound traffic.
· Encrypted traffic may limit confirmation of callback, payload retrieval, staging, tunneling, or data-transfer content.
· Backend access from reverse proxy infrastructure should not be treated as malicious without dependency-map deviation, timing correlation, process context, credential context, or application anomalies.
Cloud and Kubernetes Attribution Limits
· Cloud metadata access, Kubernetes API activity, mounted-secret access, service-account use, and workload changes are post-exploitation context, not direct proof of the initial NGINX Rift exploit path.
· Cloud and Kubernetes logs may not map cleanly to the affected NGINX host, pod, namespace, node, service account, or route.
· Workload identity, source identity, and destination identity may be obscured by service mesh, NAT, autoscaling, ephemeral workloads, or shared nodes.
· Kubernetes restarts, readiness probe failures, liveness probe failures, and crash-loop behavior can result from benign deployment, scaling, or dependency issues.
· Cloud-control-plane activity should be attributed to NGINX Rift only when linked to suspicious request activity, service instability, process execution, file activity, or credential exposure from the affected NGINX environment.
False-Positive Drivers
· Vulnerability scanners, penetration tests, authorized validation, patch verification, QA testing, synthetic transactions, uptime monitoring, CDN health checks, load balancer probes, and web testing tools may generate malformed request patterns.
· Deployment activity, NGINX reloads, application releases, route changes, backend instability, certificate renewal, and configuration-management workflows may produce service instability.
· Legitimate package updates, monitoring workflows, log forwarding, observability activity, security tooling, and administrative workflows may produce outbound connections or file changes.
· Normal reverse proxy behavior may include high-volume backend communication, upstream retries, health checks, route-specific errors, gateway failures, and transient latency spikes.
· Shared infrastructure may make unrelated scanner or customer traffic appear clustered.
False-Negative Drivers
· Exploit attempts may use encoded, double-encoded, fragmented, case-varied, normalized, low-volume, single-request, distributed, or route-specific request patterns.
· Exploit attempts may target obscure rewrite-heavy routes, legacy application paths, API routes, ingress paths, gateway routes, virtual hosts, or backend-facing paths that are not monitored.
· Successful exploitation may produce only instability, crash behavior, delayed callback, in-memory activity, or minimal file activity.
· Attackers may delay outbound communication, use approved destinations, rely on common cloud providers, use direct IP addresses, rotate infrastructure, or hide within allowed service dependencies.
· Attackers may delete files, tamper with logs, avoid persistence, operate from ephemeral containers, or exploit gaps in EDR and log retention.
· Short retention windows may prevent investigation after new exploit details, vendor guidance, or amendment-relevant indicators emerge.
Operational Interpretation Constraint
· Exposure is not exploitation.
· Malformed requests are not compromise evidence by themselves.
· Worker instability is not confirmed exploitation by itself.
· Outbound communication is not NGINX Rift evidence by itself.
· Backend access is not malicious by itself.
· Cloud or Kubernetes activity is not direct exploit evidence by itself.
· Confidence should increase only when multiple telemetry sources support the same exploit-path narrative.
S33 — Defensive Control & Hardening Improvements
Defensive Improvement Objective
Defensive improvements for NGINX Rift should reduce exposure of vulnerable NGINX-backed routes, improve request and crash visibility, strengthen reverse proxy resilience, limit post-exploitation blast radius, preserve evidence during emergency response, and ensure that malformed request activity can be separated from service-impact or compromise evidence.
Exposure and Patch Assurance
· Maintain an inventory of internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, WAF-adjacent, and NGINX-backed application services.
· Identify deployments using rewrite-heavy configurations, rewrite directives, set directives, capture-based rewrites, complex route transformation, ingress annotations, gateway routing, or legacy virtual-host routing.
· Prioritize remediation for exposed NGINX-backed services that front customer-facing applications, authentication flows, API gateways, payment paths, administrative interfaces, regulated data paths, Kubernetes ingress services, and high-dependency upstream applications.
· Apply vendor-supported patches, mitigations, configuration changes, or compensating controls where applicable.
· Validate that patch status applies to the active service, active image, active container, active ingress controller, active gateway, and active deployment baseline.
· Confirm that emergency changes do not break legitimate routing, authentication, API behavior, payment workflows, customer access, health checks, or upstream dependencies.
· Prevent vulnerable images, templates, configurations, or ingress definitions from being redeployed after remediation.
Rewrite and Route Hardening
· Review rewrite-heavy routes for unnecessary complexity, unsafe transformations, legacy routing behavior, ambiguous path handling, and unnecessary exposure.
· Reduce exposed rewrite behavior where feasible.
· Validate route behavior through controlled testing before and after remediation.
· Apply route-level protections for authentication paths, API paths, payment paths, administrative paths, ingress paths, gateway routes, and high-dependency upstream services.
· Use WAF, CDN, load balancer, gateway, and reverse proxy controls to block or challenge malformed request patterns where operationally safe.
· Preserve raw and normalized request values when implementing protective controls.
· Avoid broad blocking that disrupts legitimate customer traffic, API clients, health checks, or integration partners.
Web Infrastructure Visibility
· Preserve high-fidelity NGINX access logs and error logs for exposed services.
· Preserve raw URI values, normalized URI values, query strings, host headers, forwarded headers, request identifiers, response codes, upstream response timing, source IP context, and route mapping where available.
· Validate source IP preservation across CDN, WAF, load balancer, proxy, gateway, and ingress layers.
· Enable route-level service-health monitoring for exposed NGINX-backed applications.
· Monitor 500-series spikes, upstream resets, gateway errors, route-specific degradation, worker crashes, reload failures, and service restarts.
· Ensure timestamps are synchronized across web, endpoint, network, cloud, Kubernetes, and application telemetry.
· Validate that logging remains active during emergency remediation, failover, container replacement, and service rebuild activity.
Endpoint and Workload Hardening
· Deploy EDR or equivalent process telemetry on NGINX servers, reverse proxy hosts, ingress nodes, gateway nodes, container hosts, and Kubernetes nodes where feasible.
· Monitor unexpected child-process execution from NGINX master, worker, ingress-controller, gateway, reverse proxy, containerized NGINX, or service-account lineage.
· Alert on shells, interpreters, downloaders, package managers, archive tools, file-transfer utilities, network utilities, discovery utilities, credential utilities, and service-control utilities spawned from NGINX-related context.
· Monitor file creation, file modification, permission changes, symbolic link creation, executable-bit changes, archive extraction, and suspicious file placement after exploit-path indicators.
· Restrict unnecessary shell, interpreter, package manager, compiler, and file-transfer utility availability on edge-facing NGINX infrastructure where operationally feasible.
· Validate security-agent, log-forwarder, monitoring-agent, vulnerability-agent, and cloud-agent health after suspected exploitation or emergency remediation.
Egress and Backend Access Controls
· Maintain approved egress baselines for NGINX hosts, containers, workloads, nodes, ingress controllers, gateways, and reverse proxy tiers.
· Restrict direct outbound internet access from NGINX infrastructure where feasible.
· Alert on first-seen destinations, direct IP egress, unusual ports, suspicious DNS lookups, rare destinations, tunneling services, paste services, file-sharing services, and infrastructure-like domains after exploit-path indicators.
· Map approved upstream applications, backend APIs, identity services, databases, management interfaces, cloud endpoints, Kubernetes APIs, secret stores, CI/CD systems, and artifact repositories.
· Alert on dependency-map deviation from NGINX infrastructure after suspicious request activity, service instability, process execution, file activity, or unusual egress.
· Apply least privilege to service accounts, workload identities, cloud roles, Kubernetes service accounts, and backend access paths used by NGINX-backed services.
Cloud, Kubernetes, and Container Controls
· Map NGINX services to cloud account, subscription, project, VPC or VNet, load balancer, security group, managed identity, instance role, namespace, pod, service account, node, workload owner, and backend dependency context.
· Restrict cloud metadata access and managed identity permissions where feasible.
· Limit Kubernetes service-account permissions for ingress and NGINX workloads.
· Restrict mounted secrets, hostPath mounts, privileged containers, runtime socket access, and host namespace exposure.
· Monitor mounted-secret access, Kubernetes API access, role-binding changes, workload modification, ingress changes, container restarts, pod restarts, and node-level activity after suspected exploitation.
· Rebuild containers, pods, nodes, or workloads from validated patched images when integrity cannot be confirmed.
· Preserve container, Kubernetes, and cloud telemetry before terminating, replacing, rescheduling, or rebuilding affected workloads.
Credential and Secret Protection
· Reduce secrets available to NGINX hosts, containers, ingress workloads, reverse proxy tiers, and gateway services.
· Avoid long-lived credentials on edge-facing web infrastructure where feasible.
· Scope service accounts, API keys, cloud roles, managed identities, Kubernetes service accounts, and backend credentials to minimum required permissions.
· Monitor access to service-account tokens, application secrets, cloud credentials, Kubernetes secrets, configuration files, SSH material, and credential paths after suspicious request activity or process execution.
· Rotate credentials and secrets when compromise is confirmed or strongly suspected.
· Confirm rotated credentials are no longer valid from prior locations.
Response and Evidence Preservation
· Preserve NGINX access logs, error logs, WAF events, CDN telemetry, load balancer logs, gateway logs, ingress logs, crash artifacts, endpoint telemetry, file telemetry, DNS logs, proxy logs, firewall logs, cloud flow logs, Kubernetes logs, and downstream application logs before destructive remediation.
· Avoid rebuilding, terminating, rotating, or replacing affected systems before preserving evidence needed for scoping unless immediate containment requires action.
· Define response thresholds for exploit attempt, likely denial-of-service impact, probable compromise, and confirmed post-exploitation.
· Isolate affected NGINX infrastructure when suspicious request activity is followed by NGINX-context execution, unusual egress, file activity, credential access, backend probing, cloud activity, or Kubernetes activity.
· Coordinate web operations, infrastructure, application, SOC, endpoint, cloud, Kubernetes, identity, legal, customer communications, and executive teams when business-critical services are affected.
· Validate recovery through patch confirmation, route testing, service-health monitoring, egress review, credential review, backend access review, and telemetry health checks.
S34 — Defensive Control & Hardening Architecture

Figure 6
Architecture Objective
The defensive architecture for NGINX Rift should interrupt the attack path at multiple points: exposed route discovery, malformed request delivery, request-to-instability triggering, NGINX-context execution, file or configuration activity, outbound communication, backend expansion, cloud or Kubernetes exposure, persistence, and customer-facing service impact. The architecture must combine web telemetry, reverse proxy controls, WAF/CDN/load-balancer controls, endpoint telemetry, egress monitoring, cloud and Kubernetes context, asset enrichment, and response orchestration.
Layer 1: Exposed NGINX Asset and Route Management
This layer identifies where NGINX Rift matters most by combining internet exposure, NGINX service identity, NGINX Plus status, reverse proxy role, ingress role, gateway role, WAF adjacency, patch status, rewrite-route exposure, route sensitivity, upstream dependency, and business criticality.
Control Focus
· Internet-facing NGINX inventory.
· NGINX Plus and F5-managed NGINX product context where applicable.
· Reverse proxy, ingress, gateway, and WAF-adjacent service mapping.
· Rewrite-heavy route inventory.
· Virtual-host and route ownership.
· Patch and compensating-control validation.
· Business-critical application mapping.
· Customer-facing, authentication, API, payment, administrative, regulated, and high-dependency route prioritization.
Layer 2: Request Filtering and Route-Level Protection
This layer reduces exploit-attempt reachability by applying protective controls at WAF, CDN, load balancer, gateway, ingress, reverse proxy, and route layers without breaking legitimate traffic.
Control Focus
· Malformed request filtering.
· URI normalization review.
· Raw and normalized URI preservation.
· WAF and CDN policy tuning.
· Load balancer and gateway rule validation.
· Ingress policy validation.
· Rewrite-route hardening.
· Source clustering and scanner allowlisting.
· Customer-impact testing before blocking.
Layer 3: Request-to-Instability Detection
This layer identifies suspicious request activity that aligns with NGINX worker instability, route degradation, error-rate spikes, gateway failures, upstream resets, container restarts, pod restarts, or service-health degradation.
Control Focus
· NGINX access logs.
· NGINX error logs.
· Route-level response analytics.
· 500-series spike monitoring.
· Upstream reset and gateway failure monitoring.
· Worker crash and segmentation fault monitoring.
· Service manager telemetry.
· Container restart telemetry.
· Kubernetes pod restart telemetry.
· Application performance telemetry.
Layer 4: NGINX-Context Execution and File Monitoring
This layer identifies possible post-exploitation behavior from NGINX worker, reverse proxy, ingress-controller, gateway, containerized NGINX, or service-account context.
Control Focus
· Endpoint process lineage.
· Command-line capture.
· NGINX child-process monitoring.
· Service-account behavior monitoring.
· Temporary-directory execution monitoring.
· File creation and permission-change monitoring.
· Configuration change monitoring.
· Startup path and service-unit monitoring.
· Monitoring-agent and log-forwarder health.
Layer 5: Egress and Backend Expansion Monitoring
This layer detects outbound communication, callback behavior, tool retrieval, backend probing, internal expansion, cloud metadata access, Kubernetes API access, and movement toward sensitive downstream services.
Control Focus
· DNS logs.
· Proxy logs.
· Firewall logs.
· NetFlow.
· Cloud flow logs.
· East-west traffic monitoring.
· Approved egress baselines.
· Backend dependency mapping.
· Sensitive destination tagging.
· Direct IP, rare destination, and unusual port detection.
· Process-to-network attribution where available.
Layer 6: Cloud, Kubernetes, Container, and Identity Context
This layer links NGINX exploit-path evidence to workload identity, cloud identity, Kubernetes namespace, service-account material, mounted secrets, container runtime context, and downstream trust relationships.
Control Focus
· Cloud audit logs.
· Metadata-service access monitoring.
· Managed identity and instance role review.
· Kubernetes audit logs.
· Service-account and mounted-secret monitoring.
· Container runtime telemetry.
· Namespace and workload ownership mapping.
· Ingress-controller context.
· Service mesh identity where available.
· Credential and secret rotation workflows.
Layer 7: Response, Recovery, and Trust Revalidation
This layer ensures suspected exploitation leads to coordinated containment without destroying evidence and that recovery restores confidence in exposed reverse proxy infrastructure.
Control Focus
· Evidence preservation.
· Host, container, pod, or node isolation.
· Emergency patch validation.
· WAF, CDN, load balancer, gateway, and ingress change control.
· Reverse proxy rebuild or rollback.
· Credential and secret review.
· Backend application scoping.
· Cloud and Kubernetes scoping.
· Customer-impact assessment.
· Recovery validation and executive reporting.
Architecture Design Principle
The architecture should not depend on a single detection source or a single public request pattern. NGINX Rift defense requires layered correlation across exposed asset context, malformed request activity, route-specific instability, NGINX error-log artifacts, endpoint process lineage, file activity, outbound communication, backend dependency deviation, cloud activity, Kubernetes activity, and downstream application anomalies. This layered model reduces false confidence from patch inventory alone and improves response confidence when exploit behavior produces instability before confirmed execution.
S35 — Defensive Control Mapping Matrix
Mapping Purpose
The defensive control mapping identifies where controls reduce NGINX Rift exposure, detect exploit-path behavior, contain service impact, and limit downstream compromise. The mapping should be used as an implementation guide for web operations, SOC, endpoint, cloud, Kubernetes, application, identity, and infrastructure teams.
Control Area: Exposed Asset Management
Primary Risk Reduced
Unidentified internet-facing NGINX-backed services, unmanaged reverse proxy tiers, unknown ingress paths, and unprioritized business-critical exposure.
Required Controls
· Internet-facing NGINX service inventory.
· NGINX Plus and F5-managed NGINX product context where applicable.
· Reverse proxy, ingress, gateway, and WAF-adjacent asset groups.
· Virtual-host ownership.
· Route ownership.
· Upstream dependency mapping.
· Business-criticality tagging.
Detection or Response Value
Asset context allows detections to prioritize exposed services that front customer-facing, authentication, API, payment, administrative, regulated, or high-dependency application paths.
Control Area: Patch and Configuration Assurance
Primary Risk Reduced
Continued exposure of vulnerable NGINX-backed services, rewrite-heavy paths, legacy route behavior, and redeployment of unsafe images or configurations.
Required Controls
· Patch validation.
· Active service validation.
· Container image validation.
· Ingress-controller validation.
· Gateway policy validation.
· Rewrite-route inventory.
· Configuration-management review.
· Compensating-control validation.
Detection or Response Value
Patch and configuration context reduces false positives, supports prioritization, and helps distinguish vulnerable exposure from non-applicable scan noise.
Control Area: Request Filtering and Web Telemetry
Primary Risk Reduced
Malformed request delivery, exploit probing, request normalization blind spots, and incomplete exploit-path reconstruction.
Required Controls
· WAF and CDN filtering.
· Load balancer and gateway policy tuning.
· Raw URI preservation.
· Normalized URI preservation.
· Source IP preservation.
· Request identifier preservation.
· Route-level logging.
· Source clustering.
Detection or Response Value
Web telemetry enables early identification of exploit attempts and supports correlation between malformed request activity and route-specific instability.
Control Area: Service-Health and Crash Monitoring
Primary Risk Reduced
Missed denial-of-service outcomes, missed worker instability, and delayed identification of route-level degradation.
Required Controls
· NGINX error-log monitoring.
· Worker crash monitoring.
· Segmentation fault monitoring.
· Reload failure monitoring.
· 500-series spike detection.
· Upstream reset monitoring.
· Gateway failure monitoring.
· Container and pod restart monitoring.
· Application performance monitoring.
Detection or Response Value
Crash and service-health telemetry allows defenders to separate scan-only activity from likely service impact.
Control Area: Endpoint and Workload Execution Monitoring
Primary Risk Reduced
Missed NGINX-context execution, file activity, configuration change, and post-exploitation behavior.
Required Controls
· EDR coverage.
· Process lineage.
· Command-line capture.
· Service-account monitoring.
· NGINX child-process detection.
· File telemetry.
· Configuration monitoring.
· Monitoring-agent health checks.
Detection or Response Value
Endpoint telemetry supports escalation from exploit attempt or instability to probable compromise when suspicious NGINX-context execution or file activity is observed.
Control Area: Egress and Internal Expansion Monitoring
Primary Risk Reduced
Missed callback, payload retrieval, tunneling, backend probing, and movement toward sensitive internal services.
Required Controls
· DNS monitoring.
· Proxy monitoring.
· Firewall egress monitoring.
· NetFlow.
· Cloud flow logs.
· East-west traffic visibility.
· Approved egress baselines.
· Backend dependency mapping.
· Sensitive destination tagging.
Detection or Response Value
Network telemetry identifies suspicious outbound or internal communication after exploit-path indicators and supports post-exploitation scoping.
Control Area: Cloud, Kubernetes, and Container Security
Primary Risk Reduced
Unscoped workload identity exposure, mounted-secret exposure, cloud metadata abuse, Kubernetes service-account misuse, and container evidence loss.
Required Controls
· Cloud audit logging.
· Metadata access monitoring.
· Managed identity review.
· Kubernetes audit logging.
· Service-account monitoring.
· Mounted-secret monitoring.
· Container runtime telemetry.
· Pod and node context.
· Workload ownership mapping.
· Runtime socket restrictions.
Detection or Response Value
Cloud, Kubernetes, and container telemetry allows defenders to assess downstream exposure where NGINX-backed infrastructure operates in modern workload environments.
Control Area: Credential and Secret Protection
Primary Risk Reduced
Credential theft, service-account abuse, cloud identity misuse, Kubernetes token exposure, and backend application expansion.
Required Controls
· Secret minimization.
· Least-privilege service accounts.
· Scoped cloud roles.
· Restricted Kubernetes service accounts.
· Short-lived credentials where feasible.
· Credential access monitoring.
· Secret rotation triggers.
· Token invalidation workflows.
Detection or Response Value
Credential controls reduce blast radius and support recovery when NGINX-context execution, file activity, or backend probing suggests possible exposure.
Control Area: Incident Response and Recovery
Primary Risk Reduced
Evidence loss, delayed containment, incomplete scoping, customer-impact uncertainty, and unsafe restoration of exposed reverse proxy services.
Required Controls
· Evidence preservation workflow.
· Emergency patch validation.
· Reverse proxy containment workflow.
· WAF/CDN/load-balancer change workflow.
· Host, container, pod, and node isolation.
· Backend application review.
· Cloud and Kubernetes scoping.
· Credential rotation.
· Customer-impact assessment.
· Recovery validation.
Detection or Response Value
Coordinated response ensures that probable exploitation is contained without destroying evidence and that restored services are validated before normal operation resumes.
S36 — CyberDax Intelligence Maturity Assessment
Maturity Assessment Purpose
NGINX Rift exposes maturity gaps in internet-facing web infrastructure inventory, route-level visibility, reverse proxy telemetry, NGINX error-log coverage, service-health monitoring, endpoint visibility, egress baselining, cloud and Kubernetes context, and incident-response coordination. Mature programs will not only patch exposed NGINX-backed services; they will also prove whether suspicious request activity caused service instability, progressed to execution, or created downstream exposure.
Low Maturity
Organizations at low maturity rely primarily on vulnerability scans, perimeter alerts, WAF events, and basic web logs. They may know that NGINX exists in the environment but cannot reliably determine which services are internet-facing, which routes are rewrite-heavy, which upstream applications are business-critical, whether suspicious requests caused worker instability, or whether post-exploitation behavior occurred.
Common Indicators
· Incomplete NGINX and reverse proxy inventory.
· Weak virtual-host and route ownership mapping.
· Limited rewrite-configuration inventory.
· Incomplete raw URI or normalized URI retention.
· Limited NGINX error-log parsing.
· Limited worker crash or service-health monitoring.
· Limited endpoint telemetry on reverse proxy hosts or ingress nodes.
· Weak egress baselines for NGINX hosts.
· Limited cloud, Kubernetes, container, or workload context.
· Limited ability to distinguish scan noise from service-impact exploitation.
· No tested playbook for reverse proxy exploitation or emergency route-level remediation.
Operational Effect
Response may become broad, slow, and confidence-limited. Teams may overreact to malformed request traffic or underreact to worker instability because they lack the telemetry and asset context needed to distinguish exposure, attempted exploitation, service impact, probable compromise, and confirmed post-exploitation.
Moderate Maturity
Organizations at moderate maturity can identify many exposed NGINX-backed services, review patch status, collect web logs, and investigate some service-health and endpoint events. They may have WAF, CDN, load balancer, NGINX, EDR, cloud, and Kubernetes telemetry, but correlation across routes, hosts, workloads, and business-critical applications may still require manual effort.
Common Indicators
· NGINX and reverse proxy inventory exists but may not be complete.
· Patch state is tracked for many exposed services.
· Some rewrite-heavy routes and critical virtual hosts are known.
· NGINX access logs and error logs are available for major services.
· WAF, CDN, load balancer, and ingress telemetry are available but not consistently normalized.
· Process lineage exists on some NGINX hosts or nodes.
· Egress logs are available but approved destination baselines are incomplete.
· Cloud and Kubernetes logs are available but not consistently correlated to NGINX service context.
· SOC playbooks distinguish exploit attempt and compromise but require analyst judgment.
· Emergency WAF, CDN, load balancer, ingress, or route changes can be made but may create customer-impact risk.
Operational Effect
Response is viable but may be labor-intensive. Teams can reduce risk through targeted patching, route review, correlation hunting, and service-health analysis, but full confidence may require cross-team investigation and manual enrichment across web operations, endpoint, cloud, Kubernetes, application, and identity teams.
High Maturity
Organizations at high maturity can rapidly identify exposed NGINX-backed services, prioritize rewrite-heavy and business-critical routes, correlate malformed request activity with NGINX instability, identify NGINX-context execution, baseline outbound communication, scope backend exposure, and validate cloud or Kubernetes impact where applicable.
Common Indicators
· Comprehensive NGINX, reverse proxy, ingress, gateway, and WAF-adjacent inventory.
· Route-level ownership, upstream dependency, and business-criticality mapping.
· Validated patch state and compensating-control coverage for exposed services.
· High-fidelity raw URI and normalized URI retention where feasible.
· Strong NGINX access-log and error-log parsing.
· Route-level 500-series, upstream reset, gateway error, and service-health baselines.
· Strong EDR or host telemetry for NGINX worker lineage and service-account behavior.
· File, configuration, and monitoring-agent health telemetry on exposed NGINX infrastructure.
· Egress baselines for NGINX hosts, containers, workloads, nodes, ingress controllers, and gateways.
· Cloud, Kubernetes, container, and workload context enrichment.
· Response workflows for evidence preservation, isolation, emergency patching, route changes, credential review, backend scoping, and customer-impact assessment.
· Clear reporting distinctions between exposure, attempted exploitation, likely denial-of-service impact, probable compromise, and confirmed post-exploitation.
Operational Effect
Response can be targeted, fast, and evidence-driven. Teams can patch or mitigate quickly, preserve telemetry, identify request-to-instability behavior, validate whether execution occurred, scope downstream exposure, and report residual risk with confidence.
Target Maturity State
The target maturity state is high maturity for NGINX-backed infrastructure that is internet-facing, customer-facing, authentication-adjacent, API-facing, payment-supporting, administrative, regulated, ingress-facing, gateway-facing, WAF-adjacent, cloud-hosted, Kubernetes-managed, or connected to high-value backend systems. Organizations do not need perfect coverage for every low-value NGINX service, but they do need strong coverage where service instability or compromise would create material business impact.
S37 — Strategic Defensive Improvements
Strategic Improvement Objective
NGINX Rift highlights a recurring defensive challenge: organizations often operate exposed reverse proxy infrastructure without complete route-level visibility, request preservation, crash correlation, endpoint coverage, egress baselines, or downstream dependency mapping. Strategic improvement should focus on reducing exposed route risk, improving request-to-instability correlation, limiting post-exploitation blast radius, and ensuring emergency remediation does not destroy evidence or create additional customer-facing disruption.
Exposure-Aware Web Infrastructure Governance
Organizations should move from asset-level NGINX inventory to exposure-aware route governance. Priority should reflect whether an exposed NGINX-backed service fronts business-critical application paths, uses rewrite-heavy behavior, supports customer access, or connects to trusted downstream services.
Required Improvement
· Maintain internet-facing NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent asset inventory.
· Map exposed virtual hosts, route groups, rewrite-heavy paths, ingress paths, gateway routes, and upstream dependencies.
· Tie each exposed route to owner, business function, patch state, compensating controls, telemetry coverage, and customer-impact rating.
· Prioritize exposed services that front authentication, API, payment, administrative, regulated, customer-facing, or high-dependency application paths.
· Validate that remediated services, images, ingress definitions, gateway policies, and route configurations are not reintroduced in vulnerable form.
Request-to-Instability Visibility
Organizations should treat request-to-instability correlation as a core web infrastructure telemetry requirement. NGINX Rift may present as malformed request activity followed by worker crashes, route degradation, service restarts, upstream resets, or gateway errors before confirmed execution appears.
Required Improvement
· Preserve NGINX access logs and error logs with route-level context.
· Preserve raw and normalized request values where feasible.
· Monitor worker crashes, segmentation fault indicators, reload failures, service restarts, route-level 500-series spikes, upstream resets, gateway errors, container restarts, pod restarts, and health-check failures.
· Correlate suspicious request activity with service-health events inside defined temporal windows.
· Establish baselines for exposed virtual hosts, route groups, customer-facing routes, API routes, authentication paths, payment paths, administrative interfaces, ingress paths, and gateway routes.
· Ensure crash and service-health telemetry is retained long enough for retroactive hunting and amendment updates.
Post-Exploitation Correlation
Organizations should improve the ability to determine whether service instability progressed into execution, file activity, egress, backend access, cloud activity, Kubernetes activity, or credential exposure. This requires cross-domain correlation rather than web telemetry alone.
Required Improvement
· Capture NGINX worker lineage, service-account activity, command line, executable path, working directory, file changes, and process-to-network attribution where feasible.
· Baseline outbound communication from NGINX hosts, workloads, containers, nodes, ingress controllers, and gateways.
· Map approved upstream dependencies, backend applications, internal APIs, identity services, databases, cloud endpoints, Kubernetes APIs, secret stores, and management interfaces.
· Correlate suspicious NGINX activity with cloud, Kubernetes, container, identity, file, endpoint, and application telemetry.
· Define escalation thresholds for exploit attempt, likely service impact, probable compromise, and confirmed post-exploitation.
· Avoid attributing cloud or Kubernetes activity to NGINX Rift unless upstream exploit-path evidence supports the link.
Blast-Radius Reduction
NGINX-backed infrastructure can expose trusted routes into backend applications, cloud identities, Kubernetes services, mounted secrets, service accounts, and management interfaces. Reducing privilege and dependency concentration lowers the value of successful exploitation.
Required Improvement
· Restrict service accounts, cloud roles, managed identities, Kubernetes service accounts, and backend credentials used by NGINX-backed services.
· Reduce secrets available to edge-facing reverse proxy, ingress, gateway, and web infrastructure.
· Limit direct outbound internet access from NGINX infrastructure where feasible.
· Restrict runtime socket access, hostPath mounts, mounted secrets, and privileged containers in Kubernetes and containerized deployments.
· Segment NGINX infrastructure from sensitive backend systems except where documented dependencies require access.
· Rotate credentials and secrets when compromise is confirmed or strongly suspected.
· Validate that customer-facing route recovery does not restore unsafe trust paths.
Emergency Change and Evidence Preservation
NGINX Rift response may require urgent WAF, CDN, load balancer, ingress, gateway, route, configuration, patch, container, or workload changes. These changes must be coordinated so teams do not destroy evidence, break legitimate traffic, or obscure exploit-path reconstruction.
Required Improvement
· Define pre-approved emergency change workflows for exposed reverse proxy, ingress, gateway, and WAF-adjacent infrastructure.
· Preserve logs, crash artifacts, endpoint telemetry, network telemetry, cloud telemetry, Kubernetes telemetry, and application telemetry before destructive remediation where feasible.
· Validate WAF, CDN, load balancer, gateway, and ingress changes against legitimate customer traffic, API clients, health checks, and integration partners.
· Define containment thresholds for service instability, NGINX-context execution, unusual egress, file activity, credential access, backend probing, cloud activity, and Kubernetes activity.
· Coordinate web operations, SOC, endpoint, cloud, Kubernetes, application, identity, legal, communications, and executive teams during high-impact events.
· Document exposure, attempted exploitation, likely denial-of-service impact, probable compromise, confirmed post-exploitation, and residual risk separately.
Strategic Outcome
The desired end state is a web infrastructure security program that can rapidly identify exposed NGINX-backed services, prioritize vulnerable or rewrite-heavy routes, detect request-to-instability behavior, confirm or rule out NGINX-context execution, identify unusual egress or backend expansion, preserve evidence during emergency remediation, and restore customer-facing services with confidence.
Forward Outlook
NGINX Rift should remain operationally relevant because exposed reverse proxy and ingress infrastructure is continuously targeted by scanners, exploit operators, botnets, vulnerability researchers, and opportunistic attackers. Even when code execution is not confirmed, service instability against customer-facing reverse proxy infrastructure can create immediate operational and governance pressure. Future variants, public proof-of-concept changes, vendor guidance, or observed exploitation details may shift request patterns, route targeting, or post-exploitation behavior.
Expected Defensive Pressure
· Web infrastructure teams will need stronger route-level inventory and rewrite exposure mapping.
· SOC teams will need behavior-led detections that do not depend on static request strings.
· Endpoint teams will need stronger NGINX process lineage and file telemetry on exposed infrastructure.
· Network teams will need egress baselines for reverse proxy, ingress, gateway, and NGINX-backed workloads.
· Cloud and Kubernetes teams will need workload identity, mounted-secret, service-account, and metadata access visibility where NGINX operates in modern workload environments.
· Application teams will need to validate upstream dependencies, customer-facing routes, API paths, authentication paths, and payment workflows after suspected exploitation.
· Incident-response teams will need evidence preservation workflows that survive emergency remediation.
Risk Reduction Outlook
Risk decreases materially when exposed NGINX-backed services are patched or mitigated, rewrite-heavy routes are reviewed, request and crash telemetry is preserved, NGINX-context execution is monitored, outbound communication is baselined, backend dependencies are mapped, cloud and Kubernetes context is enriched, and response teams can separate scan noise from exploit-path evidence. Risk remains elevated where exposed reverse proxy infrastructure is business-critical, telemetry is incomplete, egress is not baselined, route ownership is unclear, or emergency remediation can destroy evidence before scoping is complete.
Executive Forward View
Executives should treat NGINX Rift as both a remediation issue and a web infrastructure trust issue. The durable lesson is that exposed reverse proxy and ingress services can become business-critical control points where malformed request activity may create service instability, investigation uncertainty, and conditional downstream exposure. Long-term resilience depends on exposure-aware patching, route-level visibility, request-to-instability detection, egress control, backend dependency mapping, cloud and Kubernetes enrichment, and response workflows that preserve evidence while restoring customer-facing access.
Final Residual Risk Position
Residual risk is acceptable only when exposed NGINX-backed assets are patched or mitigated, rewrite-heavy routes are reviewed, suspicious request activity is scoped, worker instability is investigated, NGINX-context execution is ruled out or contained, unusual egress is reviewed, backend dependencies are checked, credentials and secrets are rotated where needed, and cloud or Kubernetes activity is validated where applicable. Where those conditions are not met, residual risk should remain elevated until exposure, service impact, probable compromise, and downstream blast radius can be confidently ruled out.
S38 — Attack Economics & Organizational Impact Model
Attack Economics Overview
NGINX Rift creates attacker value because exposed reverse proxy, ingress, gateway, and WAF-adjacent infrastructure often sits directly in front of business-critical applications. The attacker does not need to compromise every backend system to create material impact. A small number of crafted HTTP requests against the right NGINX-backed route may produce worker instability, route degradation, reverse proxy disruption, customer-facing outage, emergency change activity, or conditional post-exploitation opportunity.
The economic model is driven by service dependency, not only by host compromise. Even when code execution is not confirmed, instability in a reverse proxy tier can force emergency patching, WAF or CDN tuning, load balancer changes, ingress policy review, customer-impact assessment, crash-artifact preservation, and executive incident coordination. If exploitation progresses into NGINX-context execution, unusual egress, credential access, backend probing, cloud metadata interaction, or Kubernetes activity, the cost profile shifts from service-continuity response to broader compromise scoping.
Attacker Cost Profile
NGINX Rift activity can be low cost at the probing stage and higher cost when exploitation requires target-specific route understanding, bypass adaptation, callback infrastructure, post-exploitation tooling, or stealth.
Low-Cost Attacker Activity
· Internet-wide scanning for exposed NGINX-backed services.
· Malformed request probing against common virtual hosts, routes, ingress paths, and gateway paths.
· Reuse of public request patterns or proof-of-concept-inspired request shapes.
· Basic source rotation across cloud, VPS, VPN, botnet, or scanner infrastructure.
· Observation of response codes, route failures, upstream resets, service degradation, or crash behavior.
Moderate-Cost Attacker Activity
· Route-specific probing against authentication paths, API paths, payment paths, administrative interfaces, or legacy application paths.
· Encoding, delimiter, method, header, and URI-shape variation to bypass simple request-string detection.
· Targeting of rewrite-heavy routes, ingress paths, gateway routes, reverse proxy paths, or high-dependency upstream services.
· Attempted retrieval of tooling or callback validation after service instability or execution is suspected.
· Use of infrastructure that blends with cloud, CDN, scanner, or legitimate hosting activity.
Higher-Cost Attacker Activity
· Exploitation chains that produce execution from NGINX worker, ingress-controller, gateway, container, or service-account context.
· Post-exploitation activity involving file staging, configuration change, credential access, mounted-secret access, backend probing, cloud metadata access, or Kubernetes service-account interaction.
· Defense evasion, log tampering, persistence, stealthy egress, dependency-aware backend access, and controlled operational impact.
· Targeting of high-value customer-facing, regulated, payment, API, authentication, administrative, cloud, or Kubernetes-backed services.
Defender Cost Profile
Defender cost is driven by the number of exposed NGINX-backed services, the importance of affected routes, the quality of request and crash telemetry, the need for emergency web-infrastructure changes, and whether post-exploitation evidence is present.
Primary Defender Cost Drivers
· Exposed NGINX, NGINX Plus, reverse proxy, ingress, gateway, and WAF-adjacent service inventory.
· Rewrite-heavy route validation and route-level exposure review.
· Emergency patching, configuration validation, reload testing, rollback planning, and compensating-control deployment.
· WAF, CDN, load balancer, gateway, and ingress rule tuning.
· NGINX access-log, error-log, crash, coredump, service-manager, container, and Kubernetes evidence preservation.
· SOC hunting across request telemetry, service instability, endpoint process lineage, file activity, egress, backend access, cloud telemetry, and Kubernetes telemetry.
· Customer-facing service restoration and application-owner validation.
· Credential, secret, service-account, managed identity, and backend dependency review when compromise is suspected.
· Legal, customer assurance, regulatory, insurance, executive, or board-level coordination when service disruption or exposure uncertainty affects critical services.
Economic Asymmetry
NGINX Rift creates unfavorable defensive economics when attackers can cheaply probe many exposed services while defenders must validate route exposure, patch state, request fidelity, crash evidence, endpoint behavior, egress activity, backend dependencies, cloud context, Kubernetes context, and customer impact. The asymmetry increases when organizations lack route ownership, raw URI preservation, NGINX error-log parsing, source IP preservation, egress baselines, or service dependency mapping.
Operational Impact Model
Attempted Exploitation
Attempted exploitation creates triage cost but does not necessarily create customer impact. The organization must determine whether malformed requests targeted relevant exposed routes and whether any service instability followed.
Likely Service Impact
Likely service impact occurs when suspicious request activity aligns with worker instability, route degradation, 500-series spikes, upstream resets, gateway failures, container restarts, pod restarts, or health-check failures. This can trigger outage response even without confirmed compromise.
Probable Compromise
Probable compromise occurs when suspicious request activity and instability are followed by NGINX-context execution, file activity, unusual egress, credential-path access, backend probing, cloud metadata interaction, Kubernetes activity, or suspicious service modification.
Confirmed Post-Exploitation
Confirmed post-exploitation requires corroborated evidence such as verified NGINX-context execution, malicious file activity, command execution, confirmed credential or secret access, unauthorized backend access, cloud-control-plane misuse, Kubernetes service-account abuse, persistence, defense evasion, or measurable operational impact.
Organizational Impact Model
Business Operations
NGINX Rift can disrupt business operations by degrading customer access, API reliability, authentication flows, payment workflows, administrative portals, or high-dependency upstream applications. Service impact may be immediate even when compromise remains unconfirmed.
Security Operations
Security teams may need to perform rapid correlation across web, endpoint, network, cloud, Kubernetes, container, application, and identity telemetry. Incomplete telemetry increases analyst workload and reduces confidence.
Infrastructure Operations
Infrastructure teams may need emergency patching, rollback planning, reverse proxy rebuilds, route validation, WAF or CDN updates, load balancer tuning, ingress changes, and service-health validation.
Application Operations
Application teams may need to validate upstream dependencies, route behavior, authentication flows, API behavior, customer transaction paths, backend errors, and application-specific anomalies after suspected exploit-path activity.
Cloud and Kubernetes Operations
Cloud and Kubernetes teams may need to review workload identity, service-account use, mounted secrets, cloud metadata access, flow logs, control-plane activity, pod restarts, ingress behavior, namespace context, and backend access.
Governance and Executive Operations
Executives may need to track business impact, customer impact, remediation progress, residual risk, regulatory exposure, cyber insurance obligations, customer assurance, and board-level reporting when affected services are business-critical or externally visible.
Intelligence Confidence Assessment
Overall confidence is High for vulnerability existence, CVE-2026-42945 attribution, affected NGINX Plus and NGINX Open Source product context, ngx_http_rewrite_module relevance, denial-of-service outcome, patch/remediation urgency, and behavior-led detection strategy. Confidence is Moderate for organization-specific exploitation, confirmed NGINX-context execution, credential exposure, backend access, cloud impact, Kubernetes impact, and financial impact without environment-specific telemetry.
This is supported by the official F5 advisory, which identifies CVE-2026-42945 as an NGINX ngx_http_rewrite_module issue affecting NGINX Plus and NGINX Open Source with DoS impact and possible code execution when ASLR is disabled, and by public reporting showing exploitation activity.
S39 — Economic Impact & Organizational Exposure

Figure 7
Estimated Economic Exposure
NGINX Rift, tracked as CVE-2026-42945, creates economic exposure by increasing the cost and urgency of response around exposed reverse proxy and web-infrastructure control points. The vulnerability affects NGINX Plus and NGINX Open Source through the ngx_http_rewrite_module and can allow denial-of-service conditions or possible code execution under specific runtime and hardening conditions. The report should therefore frame economic exposure around both service instability and conditional post-exploitation risk, rather than treating every malformed request as confirmed compromise.
The highest economic exposure occurs when suspicious request activity affects business-critical NGINX-backed services and defenders must determine whether the activity remained scan noise, caused denial-of-service impact, progressed to NGINX-context execution, or created downstream exposure. In those environments, response may require emergency patching, rewrite-route review, WAF or CDN rule changes, load balancer updates, ingress changes, reverse proxy rebuilds, crash-artifact preservation, endpoint review, egress analysis, backend scoping, credential review, cloud or Kubernetes validation, customer communications, legal review, and executive governance.
Low Impact Scenario
Low impact occurs when suspicious activity is limited to scanning, probing, authorized validation, or malformed request noise against exposed NGINX-backed services. Affected services are patched, not using relevant rewrite-heavy behavior, shielded from the vulnerable request path, or protected by validated compensating controls. No worker instability, route degradation, outage condition, suspicious execution, unusual egress, backend probing, Kubernetes activity, cloud metadata access, file activity, credential exposure, or customer-facing degradation is observed.
Estimated economic exposure is limited to exposed-service inventory review, rewrite-route validation, patch verification, WAF/CDN/load-balancer policy review, request-log triage, scanner allowlist reconciliation, targeted hunting, SIEM correlation checks, and executive tracking.
Estimated impact is $250K to $1.5M.
Moderate Impact Scenario
Moderate impact occurs when suspicious malformed request activity is observed against exposed NGINX-backed services and is paired with route-specific degradation, elevated 500-series responses, upstream resets, gateway failures, NGINX worker instability, reload failures, container restarts, pod restarts, or limited service-health impact. No confirmed host compromise, credential exposure, lateral movement, or data access is identified, but the organization must respond as if the affected reverse proxy tier may have created customer-facing disruption or incomplete investigative confidence.
Response may require emergency NGINX patching, configuration review, rewrite-route exposure analysis, WAF/CDN/load-balancer tuning, ingress-controller validation, crash-artifact preservation, SIEM correlation, service-owner coordination, endpoint review, egress baseline review, application-owner validation, limited customer assurance, and cross-team incident coordination.
Estimated impact is $2M to $12M.
High Impact Scenario
High impact occurs when confirmed or strongly suspected exploitation of CVE-2026-42945 affects business-critical NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent infrastructure and is followed by suspicious child-process execution, file activity, unusual outbound communication, backend probing, credential or secret access, Kubernetes service-account activity, cloud metadata interaction, or prolonged customer-facing service disruption.
Response may require emergency failover, reverse proxy rebuilds, configuration rollback, route restoration, WAF/CDN/load-balancer policy changes, credential and secret rotation, Kubernetes ingress or workload review, cloud identity and metadata exposure review, backend application investigation, forensic preservation, customer assurance, legal and regulatory assessment, cyber insurance coordination, executive incident governance, and board-level reporting.
Estimated impact is $15M to $75M or higher.
Annualized Risk Exposure
Annualized risk exposure is estimated at $5M to $28M or higher based on exposed NGINX-backed service footprint, CVE-2026-42945 exposure, rewrite-route exposure, customer-facing dependency, authentication or API gateway role, patch latency, WAF/CDN/load-balancer complexity, route-level telemetry completeness, service disruption potential, Kubernetes and cloud blast radius, credential or secret exposure, containment complexity, and customer or regulatory obligations.
The estimate increases where exposed NGINX-backed services support:
· Customer-facing applications.
· Authentication portals.
· API gateways.
· Payment workflows.
· Administrative interfaces.
· Regulated data paths.
· Kubernetes ingress services.
· Cloud-hosted production workloads.
· Reverse proxy tiers supporting multiple upstream applications.
· Gateway services tied to business-critical application delivery.
· Systems with access to secrets, service accounts, managed identities, backend APIs, or sensitive internal services.
Operational Dependency
Operational dependency is high where affected NGINX-backed infrastructure supports customer-facing service delivery, authentication, API routing, payment processing, administrative access, regulated application access, Kubernetes ingress, cloud workload routing, or high-dependency upstream applications.
A service-instability event can disrupt operations even when compromise is not confirmed because reverse proxy and ingress tiers often function as shared dependency layers. One affected NGINX tier may degrade access to multiple applications, trigger emergency routing changes, create customer-facing errors, and require coordinated web operations, application, infrastructure, SOC, cloud, Kubernetes, and executive response.
Operational dependency is highest when the affected reverse proxy, ingress, gateway, or NGINX service cannot be patched, isolated, rebuilt, failed over, or route-filtered without disrupting customer access or business-critical workflows.
Control Trust
Control trust is degraded when NGINX Rift activity is suspected because the affected infrastructure may sit at a trusted boundary between external users and internal applications. Trust degradation is more severe when suspicious request activity is followed by service instability, NGINX-context execution, file activity, unusual egress, backend probing, credential access, cloud activity, or Kubernetes activity.
Control trust should not be restored solely because a patch or WAF rule was applied. Trust restoration requires validation of request telemetry, error logs, crash artifacts, endpoint process lineage, file activity, outbound communication, backend access, cloud context, Kubernetes context, service health, route behavior, and telemetry integrity.
Patch completion or compensating-control deployment closes or reduces the known exposure path, but it does not prove that exploitation did not occur before remediation.
Visibility Confidence
Visibility confidence depends on whether defenders can correlate malformed request activity, exposed route context, NGINX error logs, worker instability, service-health events, endpoint process lineage, file telemetry, outbound communication, backend access, cloud context, Kubernetes context, and downstream application behavior.
High visibility confidence requires:
· Raw URI visibility.
· Normalized URI visibility.
· Source IP preservation.
· Request identifiers.
· Route-level logging.
· NGINX access logs.
· NGINX error logs.
· Worker crash and restart telemetry.
· Service-health telemetry.
· Endpoint process lineage.
· Command-line capture.
· File and configuration telemetry.
· DNS, proxy, firewall, NetFlow, or cloud flow telemetry.
· Backend dependency mapping.
· Cloud and Kubernetes workload context where applicable.
· Service-owner and business-criticality mapping.
Low visibility confidence increases economic exposure because defenders may need broader containment, expanded forensic review, more conservative credential rotation, broader backend scoping, longer customer-impact assessment, and extended monitoring due to uncertainty.
Change-Control Confidence
Change-control confidence depends on whether exposed NGINX-backed services can be patched, reconfigured, filtered, restarted, failed over, rebuilt, or protected without unacceptable customer-facing disruption.
Confidence is lower when affected services support fragile legacy routes, complex rewrite behavior, customer-facing portals, authentication flows, payment workflows, high-volume APIs, administrative access, regulated applications, Kubernetes ingress paths, gateway routing, or tightly coupled upstream dependencies.
Confidence is higher when organizations maintain tested patch procedures, validated rollback plans, WAF/CDN/load-balancer rule-testing workflows, ingress change control, route-level ownership, service-health baselines, customer-impact testing, container image validation, and emergency maintenance workflows.
Change-control confidence should be assessed separately from patch availability because available patches and protective rules do not reduce risk unless they can be deployed, verified, retained, and carried forward into active services, container images, ingress definitions, gateway policies, and deployment templates.
Downstream Dependency
Downstream dependency risk is elevated because NGINX-backed infrastructure often brokers access to internal applications, APIs, identity services, databases, Kubernetes services, cloud metadata paths, secret stores, CI/CD systems, artifact repositories, and management interfaces. If exploitation progresses beyond instability, the affected host or workload may provide a trusted path into systems that are not directly exposed to the internet.
The downstream dependency model should include:
· Upstream applications served by the affected NGINX tier.
· Authentication systems and identity-adjacent services.
· API gateways and internal API dependencies.
· Payment and transaction workflows.
· Administrative portals and management interfaces.
· Backend databases and application services.
· Cloud accounts, projects, subscriptions, roles, metadata endpoints, and managed identities.
· Kubernetes clusters, namespaces, pods, service accounts, ingress resources, mounted secrets, and node context.
· Container workloads, mounted volumes, runtime context, writable layers, and host-mounted paths.
· Secret stores, credential paths, API keys, certificates, SSH material, service tokens, and configuration files.
· CI/CD systems, artifact repositories, deployment pipelines, and release automation reachable from NGINX infrastructure.
Downstream dependency is the primary reason NGINX Rift should be treated as a web infrastructure trust issue rather than a standalone web-server event.
Customer and Regulatory Exposure
Customer and regulatory exposure depends on whether suspicious NGINX Rift activity affected customer-facing services, authentication systems, payment workflows, regulated applications, identity-adjacent infrastructure, cloud-hosted workloads, Kubernetes ingress services, backend APIs, secrets, credentials, service accounts, or telemetry needed for reliable forensic scoping.
Exposure is higher where affected NGINX-backed services support:
· Customer-facing portals.
· Authentication and session management.
· API platforms.
· Payment or transaction paths.
· Administrative access.
· Regulated applications.
· Healthcare, financial, government, education, telecom, SaaS, retail, or infrastructure services.
· Cloud-hosted production workloads.
· Kubernetes ingress environments hosting customer or regulated workloads.
· Systems tied to contractual uptime, confidentiality, security, or audit obligations.
Exposure remains moderate even without confirmed data access when telemetry gaps prevent reliable proof that credentials, secrets, service accounts, backend systems, or regulated data paths were not accessed.
Residual Economic Risk
Residual economic risk remains after patching or compensating-control deployment because remediation does not automatically prove that exposed NGINX-backed services were not abused during the exposure window. Residual risk is highest where suspicious request activity aligned with service instability, route degradation, incomplete request logging, missing error logs, missing crash metadata, missing process lineage, weak egress telemetry, unclear route ownership, or unresolved backend dependency exposure.
Residual risk should be reduced through:
· Retrospective hunting across the exposure window.
· Review of malformed request activity against exposed routes.
· Review of worker crashes, segmentation fault indicators, route-specific degradation, upstream resets, gateway errors, container restarts, and pod restarts.
· Review of suspicious child-process execution from NGINX-related lineage.
· Review of file activity, configuration changes, mounted-secret access, credential-path access, and service modifications.
· Review of unusual DNS, proxy, firewall, NetFlow, cloud flow, or direct IP egress activity from NGINX infrastructure.
· Review of backend application access, internal API access, database access, identity-service access, cloud metadata access, Kubernetes API access, and management-interface access.
· Credential and secret rotation where exposure cannot be confidently ruled out.
· Rebuild or replacement of affected hosts, containers, pods, ingress workloads, or gateway services where trust cannot be restored.
· Validation that emergency WAF, CDN, load balancer, ingress, gateway, or route changes did not disrupt legitimate customer traffic or obscure evidence.
Residual economic risk should be considered elevated until the organization can demonstrate both remediation completion and reasonable confidence that exploitation, service-impact activity, or post-exploitation behavior did not occur during the exposure period.
Proof-of-Concept Behavioral Coverage Assessment
NGINX Rift / CVE-2026-42945 should be assessed through behavior-led coverage rather than proof-of-concept-specific detection. Public request patterns, demonstration strings, sample URIs, user-agent values, exploit labels, and one-off indicators can change quickly. The durable detection value comes from the request-to-impact sequence and the post-request behaviors that follow.
The behavioral model remains centered on:
· External malformed request activity against exposed NGINX-backed services.
· Route probing and request-shape variation.
· Rewrite-heavy or high-dependency route targeting.
· Request-to-instability correlation.
· NGINX worker crashes, segmentation fault indicators, abnormal exits, reload failures, route degradation, upstream resets, or gateway failures.
· Conditional NGINX-context execution.
· Conditional file activity, configuration change, credential access, or mounted-secret access.
· Conditional outbound communication, backend probing, cloud metadata activity, Kubernetes activity, or internal expansion.
· Conditional defense evasion, persistence, or operational impact.
Detection Engineering Coverage Interpretation
The existing NGINX Rift detection model provides strong behavioral coverage for CVE-2026-42945 exploit attempts, likely service-impact outcomes, probable compromise indicators, and confirmed post-exploitation behaviors when telemetry supports correlation across web, NGINX error-log, endpoint, network, cloud, Kubernetes, identity, and application sources.
Coverage should be interpreted as behavior-led coverage, not exploit-signature coverage. The model should not claim universal detection of every malformed request, every heap-buffer-overflow condition, every worker crash, every proof-of-concept variation, or every NGINX deployment pattern.
Detection confidence depends on request visibility, route context, vulnerable-state enrichment, NGINX error-log fidelity, crash metadata, endpoint visibility, process lineage, command-line capture, file telemetry, egress visibility, backend dependency mapping, cloud context, Kubernetes context, application telemetry, and service-owner enrichment.
The correct interpretation is that the report provides strong coverage for the observable NGINX Rift exploit path and moderate coverage for exploit-specific primitive detection where the environment lacks raw request, crash, endpoint, or memory-context visibility.
Direct Coverage
Direct coverage applies to NGINX Rift / CVE-2026-42945 exploit-path behavior where the observed activity matches the report’s core model.
Directly covered behaviors include:
· Malformed request activity against exposed NGINX-backed services.
· Route probing and request variation against rewrite-heavy or high-dependency paths.
· Abnormal URI structure, encoded path expansion, delimiter manipulation, malformed headers, or request normalization failure.
· Suspicious request activity followed by worker instability, segmentation fault indicators, abnormal exits, reload failures, 500-series spikes, upstream resets, gateway errors, container restarts, or pod restarts.
· Unexpected child-process execution from NGINX worker, ingress-controller, gateway, reverse proxy, containerized NGINX, or service-account lineage.
· Suspicious file activity, configuration modification, service modification, mounted-secret access, credential-path access, or writable-path execution from NGINX-related context.
· Unusual outbound communication from NGINX infrastructure after exploit-path indicators.
· Backend access, cloud metadata access, Kubernetes API access, identity-service access, or management-interface access after exploit-path indicators.
· Defense evasion, persistence, service modification, log tampering, or operational disruption after confirmed execution or suspicious post-exploitation activity.
Direct coverage is strongest when request activity, service instability, endpoint behavior, egress activity, backend access, and asset context are correlated around the same exposed NGINX-backed service or workload boundary.
Coverage With Adaptation
Coverage with adaptation applies to related NGINX, NGINX Plus, reverse proxy, ingress, gateway, or request-handling exploit activity where the CVE differs but the observable enterprise behaviors remain consistent with the NGINX Rift model.
Recommended adaptation includes:
· Expand vulnerable-state enrichment from CVE-2026-42945-specific fields to broader NGINX request-handling or reverse proxy exploit-path fields.
· Add related vulnerability identifiers, vendor advisories, or proof-of-concept references as supporting enrichment when future amendments identify them.
· Generalize rule descriptions from NGINX Rift-only language to exposed NGINX-backed request-handling behavior where appropriate.
· Preserve CVE-2026-42945 references only where the rule or enrichment is explicitly tied to this report’s exploit path.
· Treat new proof-of-concept request strings as supporting evidence only, not the primary detection model.
· Retain core detection logic around malformed request activity, request-to-instability correlation, NGINX-context execution, unusual egress, file activity, backend access, cloud metadata interaction, and Kubernetes activity.
· Update S39 coverage notes when a new related CVE, vendor advisory, proof-of-concept, or exploitation pattern materially maps to the same behavior family.
Coverage with adaptation should be treated as meaningful because the defensive value is not dependent on a single request string. The defensive value comes from detecting the request-to-instability sequence and the post-request behaviors that distinguish scan noise from service impact or compromise.
Non-Coverage Conditions
The existing model does not provide direct coverage when exploitation produces no observable enterprise behavior and no available telemetry captures the relevant request, crash, endpoint, egress, backend, cloud, or Kubernetes signals.
Non-coverage conditions include:
· Exposed NGINX inventory without suspicious request activity.
· CVE-2026-42945 vulnerable-state exposure without route context or exploit-path behavior.
· Malformed request activity with no retained raw URI, normalized URI, route context, source identity, or request identifier.
· Worker instability with no retained NGINX error logs, crash metadata, service-manager events, container telemetry, or Kubernetes telemetry.
· Exploit behavior that produces no captured process creation, command line, parent process, user context, file activity, or process-to-network evidence.
· Post-exploitation activity that uses approved egress destinations, approved backend dependencies, or normal service-account paths without detectable deviation.
· Environments without EDR, file telemetry, egress visibility, cloud telemetry, Kubernetes telemetry, route ownership, or service dependency mapping.
· Containerized or ephemeral deployments where evidence is lost after restart, rescheduling, image replacement, node rotation, or emergency remediation.
· Proof-of-concept artifact detection where request strings, filenames, user-agent values, headers, or payload fragments are changed before detection.
· Exploitation paths that use materially different behavior from the modeled request-to-instability and post-request sequence.
These conditions should be treated as visibility and scoping limitations, not proof that exploitation did not occur.
Current Coverage Count
Current conservative coverage count:
· Directly covered: 1 CVE.
· Covered with adaptation: related NGINX-backed request-handling, reverse proxy, ingress, gateway, or route-instability exploitation patterns where observable behavior aligns with the existing model.
· Not covered: activity that does not produce the modeled request, instability, execution, file, egress, backend, cloud, Kubernetes, or impact behaviors.
Directly covered:
· NGINX Rift / CVE-2026-42945.
Covered with adaptation:
· Related NGINX, NGINX Plus, reverse proxy, ingress, gateway, or WAF-adjacent request-handling exploitation where observable behavior includes malformed request activity, route probing, service instability, NGINX-context execution, unusual egress, backend probing, cloud metadata access, Kubernetes activity, credential access, or operational impact.
Not covered:
· Request-handling exploitation methods that produce no observable malformed request evidence, no service instability, no NGINX-context execution, no file activity, no unusual egress, no backend access, no cloud or Kubernetes activity, and no downstream service impact in available telemetry.
Coverage Qualification
Coverage should be qualified as strong for behavior-led detection and moderate for exploit-specific primitive detection.
The existing detection model is strongest when telemetry can correlate:
· Exposed NGINX-backed asset context.
· Route ownership and rewrite exposure.
· Malformed request activity.
· Request-shape abnormality.
· NGINX error-log artifacts.
· Worker crash or service-instability evidence.
· Endpoint process lineage.
· File and configuration activity.
· Outbound communication.
· Backend dependency deviation.
· Cloud metadata or cloud-control-plane activity.
· Kubernetes service-account or mounted-secret activity.
· Downstream application anomalies.
Coverage is weaker when defenders rely only on:
· Vulnerability inventory.
· NGINX presence.
· Static request strings.
· Public proof-of-concept examples.
· User-agent values.
· WAF alerts without raw request context.
· 500-series spikes without route context.
· Worker crashes without request context.
· Network telemetry without host or route context.
· Cloud control-plane telemetry without workload attribution.
· Endpoint telemetry without request or crash correlation.
The final coverage position is that the existing NGINX Rift report provides direct behavioral coverage for CVE-2026-42945 and a strong behavioral foundation for related reverse proxy exploit-path coverage. Future CVE-specific or proof-of-concept-specific updates should be added as related behavioral coverage amendments rather than forcing a new standalone report unless the new activity introduces materially different exploitation behavior, telemetry requirements, or detection engineering logic.
S40 — References
Vendor / Platform Documentation
· F5 Advisory — NGINX ngx_http_rewrite_module vulnerability CVE-2026-42945 — hxxps://my[.]f5[.]com/manage/s/article/K000161019
· NVD — CVE-2026-42945 vulnerability record — hxxps://nvd[.]nist[.]gov/vuln/detail/CVE-2026-42945
· NGINX Documentation — ngx_http_rewrite_module — hxxps://nginx[.]org/en/docs/http/ngx_http_rewrite_module.html
· NGINX Documentation — Configuring Logging — hxxps://docs[.]nginx[.]com/nginx/admin-guide/monitoring/logging/
Threat Technique Framework
· MITRE ATT&CK Framework — hxxps://attack[.]mitre[.]org
Security Vendor Analysis
· SecurityWeek — Exploitation of Critical NGINX Vulnerability Begins — hxxps://www[.]securityweek[.]com/exploitation-of-critical-nginx-vulnerability-begins/
· The Register — NGINX Rift attackers waste no time targeting exposed servers — hxxps://www[.]theregister[.]com/security/2026/05/18/nginx-rift-attackers-waste-no-time-targeting-exposed-servers/5241851
Threat Tradecraft and Intrusion Patterns
· DepthFirst — NGINX Rift technical overview — hxxps://depthfirst[.]com/nginx-rift
· DepthFirstDisclosures GitHub — NGINX Rift proof-of-concept repository — hxxps://github[.]com/depthfirstdisclosures/nginx-rift
Reference Usage Note
This reference set supports the report’s focus on NGINX Rift / CVE-2026-42945, exposed NGINX-backed reverse proxy infrastructure, ngx_http_rewrite_module exposure, crafted HTTP request activity, worker instability, denial-of-service outcomes, conditional code execution, request logging, NGINX error logging, ATT&CK-aligned behavioral interpretation, and active exploitation context. Catalog and framework references are listed only at the catalog level. Aggregator sources that do not add new report data, such as OpenCVE, are intentionally excluded.